订阅我们的每日和每周新闻通讯,获取有关行业领先的 AI 报道的最新更新和独家内容。了解更多
检索增强生成 (RAG) 已成为将大型语言模型 (LLM) 扎根于外部知识的一种流行方法。RAG 系统通常使用嵌入模型对知识库中的文档进行编码,并选择与用户查询最相关的文档。
然而,标准检索方法通常无法考虑特定于上下文的细节,而这些细节可能会在特定于应用程序的数据集中产生重大影响。在一篇新论文中,康奈尔大学的研究人员介绍了“上下文文档嵌入”,这是一种通过让嵌入模型了解文档检索的上下文来提高嵌入模型性能的技术。
RAG 中文档检索最常见的方法是使用“双编码器”,其中嵌入模型为每个文档创建固定表示并将其存储在向量数据库中。在推理过程中,计算查询的嵌入并将其与存储的嵌入进行比较,以找到最相关的文档。
双编码器因其效率和可扩展性而成为 RAG 系统中文档检索的热门选择。然而,双编码器在处理细致入微的特定于应用程序的数据集时往往会遇到困难,因为它们是在通用数据上训练的。事实上,当涉及到专业知识库时,它们在某些任务中可能无法与 BM25 等经典统计方法相媲美。
“我们的项目始于对 BM25 的研究,BM25 是一种传统的文本检索算法,”康奈尔科技大学博士生、论文合著者约翰 (杰克) 莫里斯告诉 VentureBeat。“我们进行了一些分析,发现数据集越偏离领域,BM25 就越能胜过神经网络。”
BM25 通过计算知识库中每个词在上下文中的权重来实现其灵活性。例如,如果一个词在知识库中的许多文档中出现,即使它在其他上下文中是一个重要的关键词,它的权重也会降低。这使得 BM25 能够适应不同数据集的特定特征。
“传统的基于神经网络的密集检索模型无法做到这一点,因为它们只是根据训练数据设置一次权重,”莫里斯说。“我们试图设计一种能够解决这个问题的方法。”
上下文文档嵌入
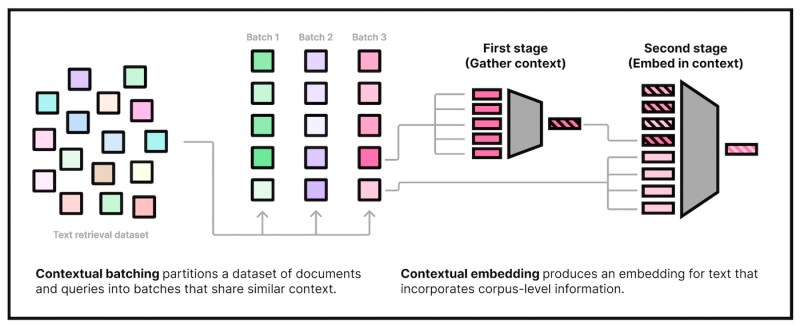
上下文文档嵌入 来源:arXiv
康奈尔大学的研究人员提出了两种互补的方法来通过将上下文概念添加到文档嵌入中来提高双编码器的性能。
“如果你将检索视为文档之间的一场‘竞争’,以确定哪个文档与给定搜索查询最相关,我们使用‘上下文’来告知编码器关于将参与竞争的其他文档的信息,”莫里斯说。
第一种方法修改了嵌入模型的训练过程。研究人员使用了一种技术,在训练嵌入模型之前对相似的文档进行分组。然后,他们使用对比学习来训练编码器区分每个集群中的文档。
对比学习是一种无监督技术,其中模型被训练来区分正例和负例。通过被迫区分相似的文档,模型变得更加敏感于特定上下文中重要的细微差异。
第二种方法修改了双编码器的架构。研究人员为编码器添加了一种机制,使其在嵌入过程中能够访问语料库。这使得编码器能够在生成嵌入时考虑文档的上下文。
增强的架构分两个阶段工作。首先,它为文档所属的集群计算一个共享嵌入。然后,它将这个共享嵌入与文档的独特特征结合起来,创建一个上下文化的嵌入。
这种方法使模型能够捕获文档集群的通用上下文和使其独特的特定细节。输出仍然是与常规双编码器相同大小的嵌入,因此不需要对检索过程进行任何更改。
上下文文档嵌入的影响
研究人员在各种基准上评估了他们的方法,发现它始终优于相同大小的标准双编码器,尤其是在训练集和测试集差异很大的域外设置中。
“我们的模型应该适用于任何与训练数据有很大不同的领域,可以被视为对微调特定于领域的嵌入模型的一种廉价替代,”莫里斯说。
上下文嵌入可用于提高 RAG 系统在不同领域中的性能。例如,如果所有文档都共享一个结构或上下文,则普通嵌入模型会在其嵌入中浪费空间,因为存储了这种冗余结构或信息。
“另一方面,上下文嵌入可以从周围的上下文中看到这种共享信息没有用,并在决定要存储在嵌入中的内容之前将其丢弃,”莫里斯说。
研究人员发布了他们上下文文档嵌入模型 (cde-small-v1) 的小型版本。它可以作为 HuggingFace 和 SentenceTransformers 等流行开源工具的直接替代品,用于为不同的应用程序创建自定义嵌入。
莫里斯说,上下文嵌入不仅限于基于文本的模型,还可以扩展到其他模态,例如文本到图像架构。还有空间使用更先进的聚类算法来改进它们,并评估该技术在更大规模上的有效性。