

大型语言模型的评估:从通用基准到定制化评估
大型语言模型(LLM)的进步降低了创建机器学习应用程序的门槛。通过简单的指令和提示工程技术,您可以让 LLM 执行原本需要训练定制机器学习模型才能完成的任务。这对没有内部机器学习人才和基础设施的公司,以及想要创建自己的 AI 产品的产品经理和软件工程师来说尤其有用。
然而,易于使用的模型并非没有权衡。如果没有系统的方法来跟踪 LLM 在其应用程序中的性能,企业最终可能会得到参差不齐且不稳定的结果。
目前评估 LLM 的流行方法是衡量它们在 MMLU、MATH 和 GPQA 等通用基准上的性能。AI 实验室经常宣传其模型在这些基准上的性能,在线排行榜根据模型的评估分数对它们进行排名。但是,虽然这些评估衡量了模型在问答和推理等任务上的通用能力,但大多数企业应用程序希望衡量模型在非常具体的任务上的性能。
“公共评估主要是基础模型创建者用来宣传其模型相对优势的一种方法,”Braintrust 的联合创始人兼首席执行官 Ankur Goyal 告诉 VentureBeat。“但是,当企业使用 AI 构建软件时,他们唯一关心的是这个 AI 系统是否真的有效。从公共基准到实际应用,几乎没有可以迁移的东西。”
企业需要根据自己的用例创建定制评估,而不是依赖公共基准。评估通常包括向模型提供一组精心设计的输入或任务,然后根据预定义的标准或人工生成的参考来衡量其输出。这些评估可以涵盖各种方面,例如特定任务的性能。
创建评估最常见的方法是捕获真实用户数据并将其格式化为测试。组织可以使用这些评估来回测其应用程序以及对应用程序所做的更改。
“使用定制评估,您不是在测试模型本身。您是在测试自己的代码,这些代码可能需要处理模型的输出并进一步处理它,”Goyal 说。“您正在测试它们的提示,这可能是人们最常调整、尝试改进和完善的东西。您还在测试设置以及将模型组合在一起的方式。”
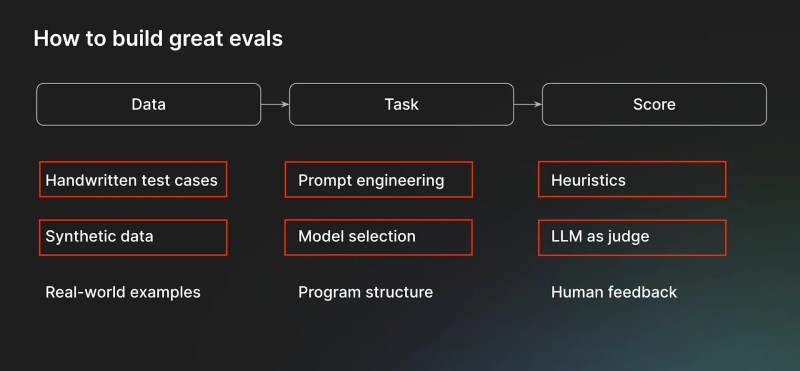
为了创建有效的评估,每个组织都必须投资三个关键组成部分。第一个是用于创建测试应用程序示例的数据。数据可以是公司员工创建的手写示例、借助模型或自动化工具创建的合成数据,或者从最终用户收集的数据,例如聊天记录和工单。
“手写示例和来自最终用户的数据比合成数据要好得多,”Goyal 说。“但是,如果您能想出生成合成数据的技巧,它也会很有效。”
第二个组成部分是任务本身。与公共基准代表的通用任务不同,企业应用程序的定制评估是更广泛的软件组件生态系统的一部分。一个任务可能由几个步骤组成,每个步骤都有自己的提示工程和模型选择技术。还可能涉及其他非 LLM 组件。例如,您可能首先将传入的请求分类为几个类别之一,然后根据类别和请求内容生成响应,最后调用外部服务的 API 来完成请求。重要的是,评估应包含整个框架。
“重要的是要构建代码,以便您可以在评估中以与生产环境中运行相同的方式调用或执行任务,”Goyal 说。
最后一个组成部分是用于对框架结果进行评分的评分函数。评分函数主要有两种类型。启发式是基于规则的函数,可以检查明确定义的标准,例如将数值结果与真实值进行比较。对于文本生成和摘要等更复杂的任务,您可以使用 LLM 作为评判方法,提示强大的语言模型来评估结果。LLM 作为评判需要高级提示工程。
“LLM 作为评判很难做到位,而且周围有很多误解,”Goyal 说。“但关键的见解是,就像数学问题一样,验证解决方案是否正确比自己解决问题更容易。”
同样的规则也适用于 LLM。对于 LLM 来说,评估产生的结果比执行原始任务要容易得多。它只需要正确的提示。
“通常,工程挑战在于迭代措辞或提示本身,以使其正常工作,”Goyal 说。
LLM 的发展速度很快,供应商不断发布新模型。企业希望在旧模型被弃用和新模型可用时升级或更改其模型。其中一个关键挑战是确保您的应用程序在底层模型发生变化时保持一致。
有了良好的评估,更改底层模型就变得像将新模型运行到您的测试中一样简单。
“如果您有良好的评估,那么切换模型感觉非常容易,实际上很有趣。如果您没有评估,那么它就很糟糕。唯一的解决方案是进行评估,”Goyal 说。
另一个问题是模型在现实世界中遇到的数据变化。随着客户行为的变化,公司需要更新其评估。Goyal 建议实施一个“在线评分”系统,该系统会持续对真实客户数据进行评估。这种方法允许公司自动评估其模型在最新数据上的性能,并将新的相关示例纳入其评估集中,确保其 LLM 应用程序的持续相关性和有效性。
随着语言模型继续重塑软件开发格局,采用新的习惯和方法变得至关重要。实施定制评估不仅仅是一种技术实践;它是一种思维方式的转变,转向 AI 时代严谨、数据驱动的开发。能够系统地评估和改进 AI 驱动的解决方案将成为成功企业的关键差异化因素。




