

大型推理模型的新纪元:阿里巴巴Marco-o1的突破
近年来,随着OpenAI o1的发布,大型推理模型(LRMs)成为了人工智能领域炙手可热的焦点。这些模型旨在解决传统语言模型难以处理的复杂问题,为人工智能应用开辟了新的可能性。阿里巴巴的研究人员紧随其后,推出了Marco-o1,进一步提升了推理能力,并着力解决那些缺乏明确标准和可量化奖励的开放式问题。
OpenAI o1通过“推理时间扩展”技术,赋予模型“思考时间”,从而提升推理能力。简单来说,模型在推理过程中会使用更多计算资源,生成更多词元并反复审视其响应,从而在需要推理的任务中取得更好的表现。o1在数学、物理和编码等具有标准答案的任务中表现出色,其强大的推理能力令人印象深刻。
然而,许多实际应用中存在着开放式问题,这些问题缺乏明确的解决方案和可量化的奖励。阿里巴巴的研究人员表示:“我们希望进一步突破LLMs的界限,增强其推理能力,以应对现实世界中复杂的挑战。”
Marco-o1是阿里巴巴Qwen2-7B-Instruct模型的微调版本,它集成了链式思维(CoT)微调、蒙特卡洛树搜索(MCTS)和推理行动策略等先进技术。
研究人员使用多个数据集训练Marco-o1,包括Open-O1 CoT数据集、Marco-o1 CoT数据集(使用MCTS生成的合成数据集)以及Marco-o1指令数据集(针对推理任务的自定义指令遵循数据集合)。
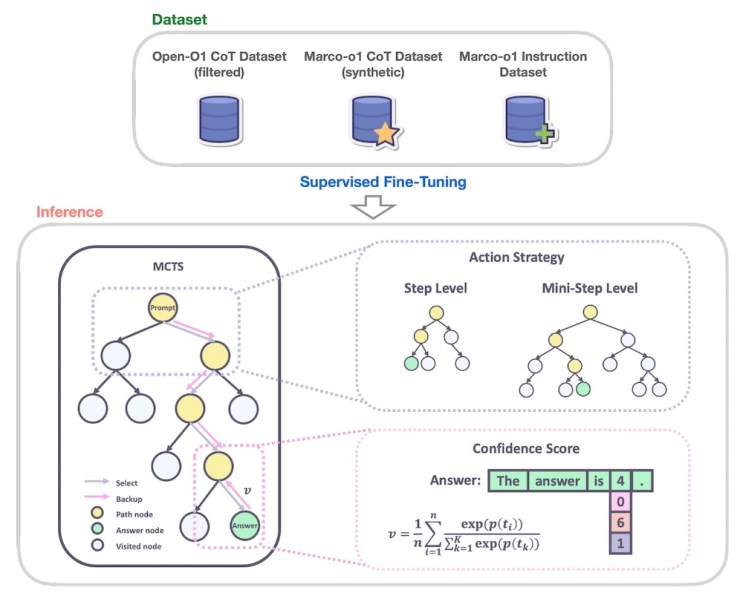
Marco-o1利用CoT和MCTS进行任务推理(来源:arXiv)
MCTS是一种搜索算法,在解决复杂问题方面表现出色。它通过反复采样可能性、模拟结果并逐步构建决策树,智能地探索不同的解决方案路径。MCTS在复杂的AI问题中(例如战胜围棋游戏)已被证明非常有效。
Marco-o1利用MCTS在生成响应词元时探索多个推理路径。模型使用候选响应词元的置信度分数来构建其决策树并探索不同的分支。这使模型能够考虑更广泛的可能性,并得出更明智、更细致入微的结论,尤其是在存在开放式解决方案的情况下。研究人员还引入了一种灵活的推理行动策略,允许他们通过定义树中每个节点生成的词元数量来调整MCTS步骤的粒度。这在准确性和计算成本之间取得了平衡,使用户能够灵活地平衡性能和效率。
Marco-o1的另一个关键创新是引入了反思机制。在推理过程中,模型会定期提示自己:“等等!我可能犯了一些错误!我需要从头开始重新思考。”这会导致模型重新评估其推理步骤,识别潜在的错误并改进其思维过程。
研究人员写道:“这种方法使模型能够充当自己的批评者,识别其推理中的潜在错误。通过明确地提示模型质疑其最初的结论,我们鼓励它重新表达和改进其思维过程。”
为了评估Marco-o1的性能,研究人员在多个任务上进行了实验,包括MGSM基准(用于多语言小学数学问题的数据集)。Marco-o1显著优于基础Qwen2-7B模型,尤其是在MCTS组件针对单词元粒度进行调整时。
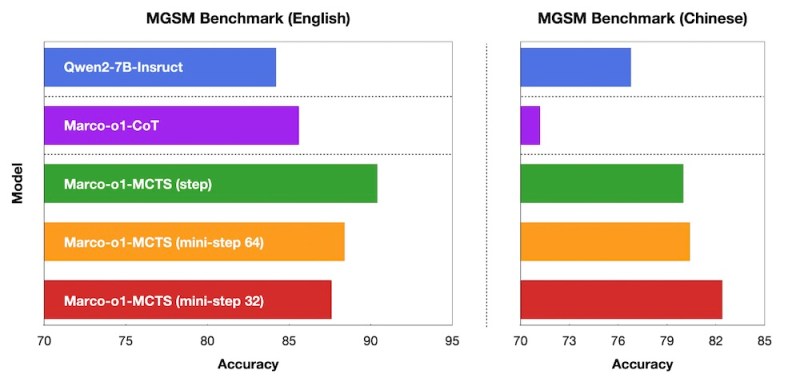
不同版本的Marco-o1与基础模型的比较(来源:arXiv)
然而,Marco-o1的主要目标是解决开放式场景中推理的挑战。为此,研究人员在翻译口语和俚语表达方面测试了该模型,这是一项需要理解语言、文化和语境微妙差异的任务。实验表明,Marco-o1能够比传统的翻译工具更有效地捕捉和翻译这些表达。例如,该模型正确地将中文口语表达(字面意思是“这双鞋有一种踩到屎的感觉”)翻译成英文等效表达“这双鞋的鞋底很舒服”。模型的推理链显示了它是如何评估不同的潜在含义并得出正确翻译的。
这种范式可以证明对产品设计和战略等任务非常有用,这些任务需要深入的上下文理解,并且没有明确定义的基准和指标。
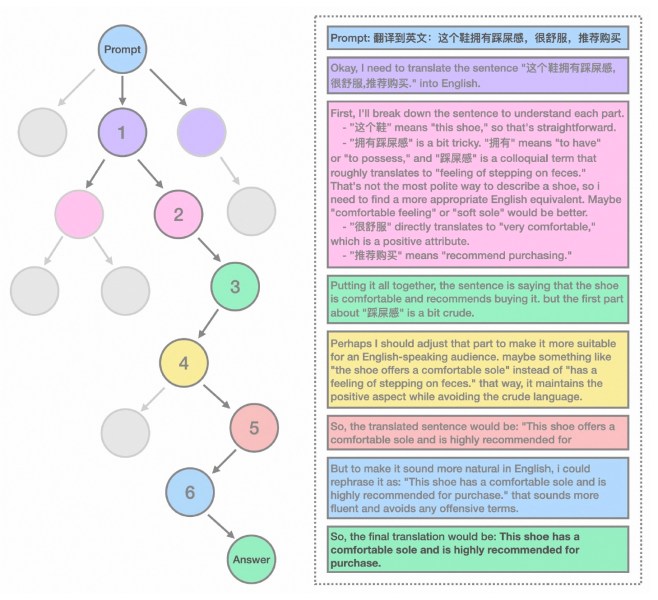
翻译任务的推理链示例(来源:arXiv)
自o1发布以来,人工智能实验室竞相发布推理模型。上周,中国人工智能实验室DeepSeek发布了其o1竞争对手R1-Lite-Preview,目前该模型仅通过公司的在线聊天界面提供。据报道,R1-Lite-Preview在几个关键基准测试中击败了o1。
开源社区也在追赶私有模型市场,发布了利用推理时间扩展定律的模型和数据集。阿里巴巴团队在Hugging Face上发布了Marco-o1,以及研究人员可以用来训练自己的推理模型的部分推理数据集。另一个最近发布的模型是LLaVA-o1,由中国多所大学的研究人员开发,它将推理时间推理范式引入开源视觉语言模型(VLMs)。
这些模型的发布正值模型扩展定律的未来充满不确定性之际。各种报告表明,训练更大模型的回报正在递减,可能正在达到瓶颈。但可以肯定的是,我们才刚刚开始探索推理时间扩展的可能性。





