Meta 发布 Llama 3.3:更强大的开源多语言大模型,成本更低
Meta 的生成式 AI 副总裁 Ahmad Al-Dahle 在 X 平台上宣布了 Llama 3.3 的发布,这是 Facebook、Instagram、WhatsApp 和 Quest VR 母公司推出的最新开源多语言大型语言模型 (LLM)。
Llama 3.3 在保持与 Llama 3.1 相当的性能水平下,将参数数量缩减至 700 亿,同时显著降低了成本,使其更易于开源社区使用。Al-Dahle 表示:“Llama 3.3 在核心性能方面取得了提升,同时成本大幅降低,使其更易于整个开源社区使用。”
Llama 3.3 采用 Llama 3.3 社区许可协议,允许非独占性、免版税地使用、复制、分发和修改模型及其输出。将 Llama 3.3 集成到产品或服务中的开发者必须包含适当的归属,例如“使用 Llama 构建”,并遵守禁止生成有害内容、违反法律或启用网络攻击等行为的可接受使用政策。虽然该许可证通常是免费的,但拥有超过 7 亿月活跃用户的组织必须直接从 Meta 获得商业许可证。
Meta AI 团队在一份声明中强调了这一愿景:“Llama 3.3 在文本相关用例中提供了领先的性能和质量,同时推理成本仅为一小部分。”
根据 Substratus 博客,Llama 3.1-405B 需要 243 GB 到 1944 GB 的 GPU 内存。而根据同一博客,旧版本的 Llama 2-70B 需要 42-168 GB 的 GPU 内存,尽管有些人声称低至 4 GB,或者像 Exo Labs 所示,几台配备 M4 芯片且没有独立 GPU 的 Mac 电脑即可运行。
因此,如果低参数模型的 GPU 节省在这种情况中仍然有效,那么那些希望部署 Meta 最强大的开源 Llama 模型的人可以预期节省高达近 1940 GB 的 GPU 内存,或者对于标准的 80 GB Nvidia H100 GPU,GPU 负载可能降低 24 倍。
以每块 H100 GPU 25,000 美元的价格计算,这可能意味着高达 600,000 美元的 GPU 预先成本节省,更不用说持续的电力成本了。
根据 Meta AI 在 X 上发布的信息,Llama 3.3 模型在多语言对话、推理和其他高级自然语言处理 (NLP) 任务(例如 MGSM)等多个基准测试中,明显优于同等规模的 Llama 3.1-70B 以及亚马逊的新 Nova Pro 模型(Nova 在 HumanEval 编码任务中表现更出色)。
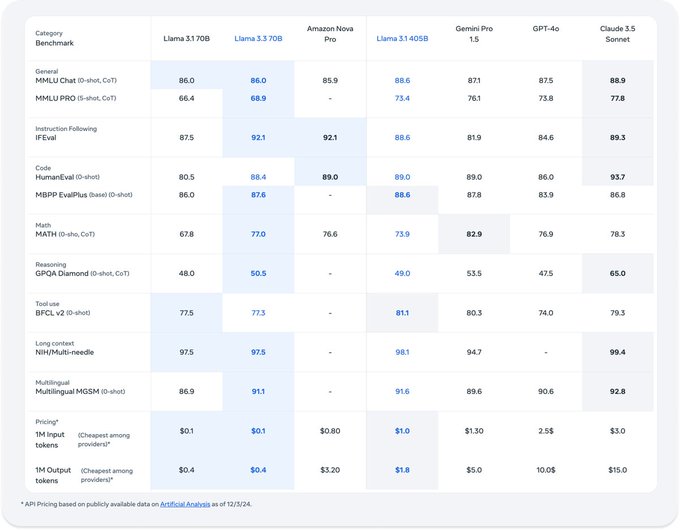
根据 Meta 在其网站上发布的“模型卡”信息,Llama 3.3 已在来自“公开可用”数据的 15 万亿个词元上进行了预训练,并在超过 2500 万个合成生成的示例上进行了微调。
该模型的开发利用了 H100-80GB 硬件上的 3930 万个 GPU 小时,突显了 Meta 对能源效率和可持续性的承诺。
Llama 3.3 在多语言推理任务中处于领先地位,在 MGSM 上的准确率达到 91.1%,证明了其在支持德语、法语、意大利语、印地语、葡萄牙语、西班牙语和泰语等语言方面的有效性,除了英语之外。
Llama 3.3 专门针对经济高效的推理进行了优化,每百万个词元的生成成本低至 0.01 美元。
这使得该模型在与 GPT-4 和 Claude 3.5 等行业同类产品竞争中具有高度竞争力,为寻求部署复杂 AI 解决方案的开发者提供了更高的可负担性。
Meta 还强调了此次发布的环境责任。尽管训练过程非常密集,但该公司利用可再生能源抵消了温室气体排放,使训练阶段的排放量达到净零。基于位置的排放总计 11,390 吨二氧化碳当量,但 Meta 的可再生能源计划确保了可持续性。
该模型引入了多项增强功能,包括更长的上下文窗口,为 128k 个词元(与 GPT-4o 相当,约 400 页的书籍文本),使其适用于长篇内容生成和其他高级用例。
其架构包含分组查询注意力 (GQA),在推理过程中提高了可扩展性和性能。
Llama 3.3 旨在与用户对安全性和有用性的偏好保持一致,使用人类反馈强化学习 (RLHF) 和监督微调 (SFT)。这种一致性确保了对不适当提示的强有力拒绝,以及针对现实世界应用优化的助手式行为。
Llama 3.3 现已可以通过 Meta、Hugging Face、GitHub 和其他平台下载,并提供用于研究人员和开发人员的集成选项。Meta 还提供 Llama Guard 3 和 Prompt Guard 等资源,帮助用户安全、负责任地部署该模型。