谷歌Veo 2视频生成模型强势来袭,与OpenAI Sora正面交锋
在人工智能领域,视频生成技术一直是巨头们争夺的焦点。近日,谷歌推出了其视频生成模型Veo 2的最新版本,并宣称其能够生成更加逼真的视频,直接挑战OpenAI的Sora。与此同时,谷歌还更新了其图像生成模型Imagen 3,使其能够生成更丰富、更精细的照片。
谷歌表示,Veo 2对现实世界物理规律以及人类动作和表情的细微差别有了更深入的理解。目前,Veo 2已在谷歌实验室的VideoFX平台上开放,但仅限于等待名单上的用户使用。用户需要通过谷歌表单进行注册,并等待谷歌在他们选择的时间内授予访问权限。
谷歌在博客文章中表示:“Veo 2还理解电影语言:你可以要求它生成特定类型的视频,指定镜头,建议电影效果,Veo 2都能满足你的要求,并且可以生成高达4K分辨率的视频。”
使用Veo 2生成的视频
虽然Veo 2目前仅对部分用户开放,但原始的Veo模型仍然可以在Vertex AI上使用。使用Veo 2生成的视频将包含谷歌的元数据水印SynthID,以便识别这些视频是由人工智能生成的。
谷歌承认,Veo 2仍然可能会出现一些幻觉,例如多出几根手指等,但他们承诺新模型产生的幻觉会更少。
Veo 2将与OpenAI最近发布的Sora视频生成模型竞争,以吸引电影制作人和内容创作者。Sora在公开发布之前已经进行了长时间的预览,目前已向付费订阅用户开放。
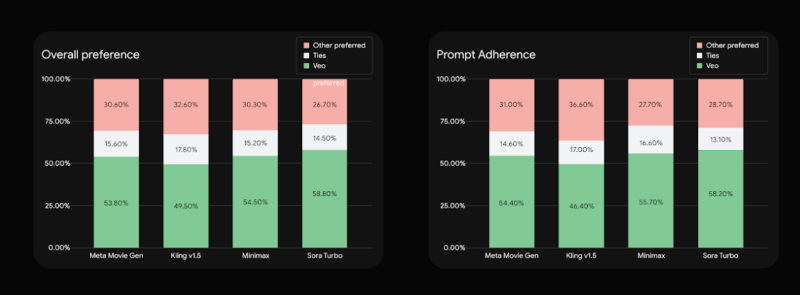
令人印象深刻的是,谷歌表示,在他们内部测试中,Veo在“整体偏好”(即观众更喜欢哪个视频)和“提示遵循”(视频与人类创作者给出的指令匹配程度)方面,都获得了人类评估者的认可,优于Sora和其他竞争对手的人工智能模型。
谷歌在今年5月的Google I/O开发者大会上宣布了Veo,并发布了一段与演员兼音乐家唐纳德·格洛弗(又名Childish Gambino)合作制作的视频。
人工智能视频生成一直是生成式人工智能领域的一个重要方向,谷歌和OpenAI等大型模型开发者一直在与相对较小的公司竞争,并不断追赶。
AI视频生成技术仍然需要说服创作者和观众。Sora发布后,人们对其能力仍然持怀疑态度,因为它仍然会生成违反物理和解剖学规律的人物。用户认为它给出的结果不一致。
最近的游戏大奖颁奖典礼上的一段预告片也显示了人们对他们认为的“人工智能垃圾”的不信任。
然而,一些电影制作人已经开始拥抱人工智能视频生成器所能提供的可能性。著名导演詹姆斯·卡梅隆加入了Stability AI的董事会,而演员安迪·瑟金斯宣布他正在建立一家以人工智能为中心的制作公司。
谷歌表示,他们看到了许多用户的兴趣。该公司表示,YouTube创作者一直在使用VideoFX制作YouTube Shorts的背景,以节省时间。
谷歌还更新了其图像模型Imagen 3,该模型最近通过其Gemini聊天机器人发布在网络上,使其更加逼真,并提供更明亮的图像。
Imagen 3现在可以更准确地渲染更多艺术风格,“从写实主义到印象派,从抽象派到动漫”。谷歌表示,该模型还将更忠实地遵循提示。
人们可以通过ImageFX访问Imagen 3。