“`html
Meta Llama 4:喧嚣背后的隐忧
Meta悄然发布了其旗舰AI语言模型Llama 4,并非一个,而是三个版本,均基于“专家混合”(Mixture-of-Experts)架构和MetaP(一种采用固定超参数的新训练方法)进行了升级,性能大幅提升,并拥有巨大的上下文窗口。
然而,周末Llama 4 Scout和Llama 4 Maverick两个版本的惊喜发布,并未赢得AI社区的一致好评。相反,社交媒体上充斥着质疑之声。
一个未经证实的帖子在1point3acres论坛和Reddit的r/LocalLlama子版块流传,声称来自Meta GenAI部门的研究人员爆料,Llama 4在内部第三方基准测试中表现不佳,公司领导层甚至“建议在训练后过程中混合来自不同基准测试的数据集,以达到各种指标的目标,并产生‘体面’的结果”。
该帖子的真实性受到质疑,VentureBeat向Meta发言人发出的邮件也未得到回复。但即使撇开帖子的真伪,Llama 4的基准测试结果也引发了广泛的担忧。
X平台用户@cto_junior指出,Llama 4 Maverick在aider polyglot基准测试(包含225个编码任务)中的表现仅为16%,远低于DeepSeek V3和Claude 3.7 Sonnet等同规模的旧模型,直言Meta应该“裁掉所有参与此项目的人,然后收购Nous”。
AI博士兼作家Andriy Burkov则质疑Meta宣称的Llama 4 Scout拥有1000万token的上下文窗口,认为这只是“虚拟”的,因为模型从未在超过256k token的提示符上进行训练。超过此长度的输入,输出质量通常会很低。
r/LocalLlama子版块用户Dr_Karminski也表达了失望之情,并展示了Llama 4在编码任务(例如模拟球在七边形内反弹)上的糟糕表现,远逊于DeepSeek的非推理V3模型。
前Meta研究员、现任AI2高级研究科学家Nathan Lambert在其Interconnects Substack博客中指出,Meta在其Llama下载网站上发布的Llama 4 Maverick与其他模型的基准比较(基于第三方对比工具LMArena ELO),使用了与公开发布版本不同的“针对对话优化的”版本,暗指Meta使用了“障眼法”。
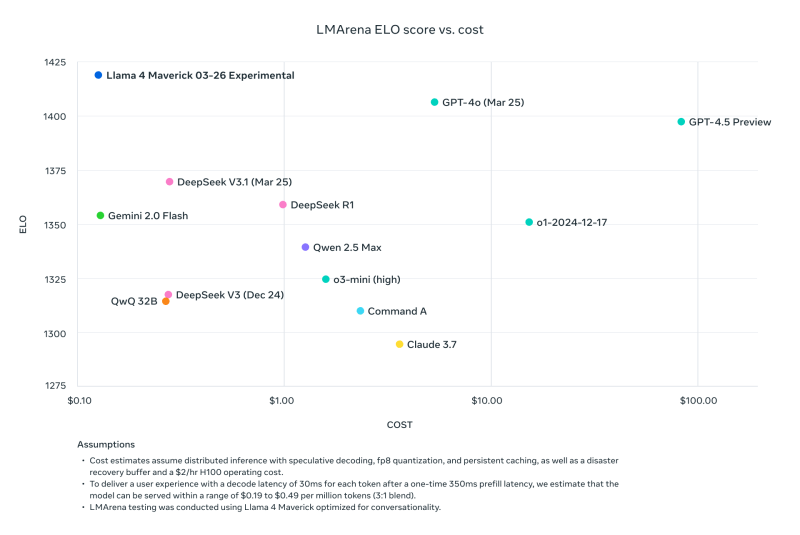
Lambert批评道:“这种做法非常不厚道,结果是虚假的。Meta没有发布用于主要营销宣传的模型,是对社区的重大轻视。”
面对铺天盖地的批评和操纵基准测试的指控,Meta GenAI副总裁Ahmad Al-Dahle在X平台上回应称,模型发布仓促,一些问题是由于需要稳定实现造成的,并否认了在测试集上进行训练的说法。
然而,这一回应并未平息质疑,许多人仍然抱怨性能不佳,并要求提供更多技术文档和解释。
巧合的是,Meta副总裁兼研究负责人Joelle Pineau上周宣布离开Meta,而她也在周末参与了Llama 4的发布宣传。
Llama 4正在陆续部署到其他推理提供商,结果好坏参半。此次发布显然未能达到预期,即将到来的Meta LlamaCon(4月29日)将成为各方讨论的焦点。
“`