您是否曾幻想过,作为一名数据科学家,能够“偷懒”地完成时间序列预测,却依然能获得卓越的成果?这并非白日做梦。在瞬息万变的商业世界中,时间序列预测无处不在,无论是预测下一季度的销售额、估算库存需求,还是规划财务预算,准确的预测能力都可能决定战略决策的成败。
然而,传统的时序分析方法,比如耗时费力的 ARIMA 参数调优,往往复杂且耗时。这让许多数据科学家、分析师和商业智能(BI)专业人士面临一个两难境地:追求精确还是注重实用?
“懒惰”数据科学家的思维方式应运而生。当现代 Python 预测库和 AutoML 工具能在短短一分钟内提供足够令人满意的解决方案时,为什么还要花费数周时间去精细调整模型呢?
本指南将教您如何采纳一种自动化的预测方法,它能以极快的速度提供合理的准确性,而且无需感到任何愧疚。
时间序列预测是指根据一系列历史数据来预测未来值的过程。常见的应用包括销售预测、能源需求预测、金融市场分析以及天气预报等。
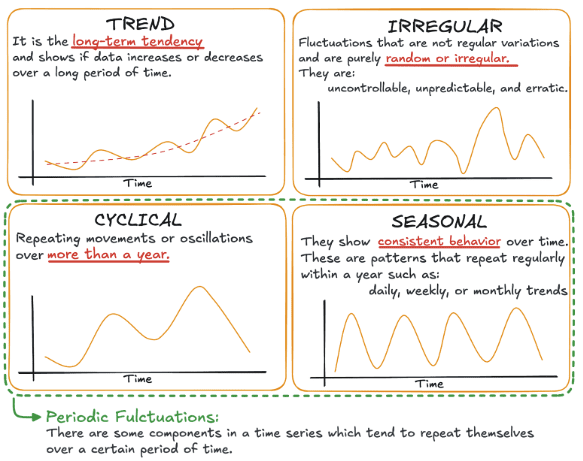
驱动时间序列的四大核心概念是:
- 趋势 (Trend):长期性的走向,表现为在较长时期内的增长或下降。
- 季节性 (Seasonality):在一年内(如每日、每周、每月)有规律重复出现的模式,通常与日历相关。
- 周期性 (Cyclical):重复性的波动或震荡,持续时间超过一年,常受宏观经济条件驱动。
- 不规则性或噪声 (Irregular or Noise):无法解释的随机波动。
要进一步了解时间序列,请参阅这份Pandas 时间序列入门指南。
#“懒惰”的预测方法
“懒惰”的方法很简单:停止重复造轮子。相反,应该依赖自动化和预构建模型来节省时间。
这种方法优先考虑速度和实用性,而非完美的精细调优。您可以将其想象成使用谷歌地图:您能够顺利到达目的地,而无需担心系统是如何计算每一条道路和交通状况的。
#“懒惰”预测的必备工具
既然我们已经明确了“懒惰”方法的核心理念,现在就将其付诸实践。与其从零开始开发模型,不如利用经过充分测试的 Python 库和 AutoML 框架,它们能为您完成大部分工作。
有些库,例如 Prophet 和 Auto ARIMA,非常适合即插即用的预测,只需极少的调优;而另一些库,如 sktime 和 Darts,则提供了一个功能强大的生态系统,您可以在其中实现从经典统计方法到深度学习的各种任务。
让我们逐一分解这些工具:
//Facebook Prophet
Prophet 是由 Facebook(Meta)开发的一个即插即用型库,尤其擅长捕捉商业数据中的趋势和季节性。只需几行代码,您就能生成包含不确定性区间的预测结果,且无需进行繁重的参数调优。
以下是一个代码示例:
from prophet import Prophet
import pandas as pd
# 加载数据 (列: ds = 日期, y = 值)
df = pd.read_csv("sales.csv", parse_dates=["ds"])
# 拟合一个简单的Prophet模型
model = Prophet()
model.fit(df)
# 进行未来预测
future = model.make_future_dataframe(periods=30)
forecast = model.predict(future)
# 绘制预测结果
model.plot(forecast)
//Auto ARIMA (pmdarima)
ARIMA 模型是时间序列预测的传统方法;然而,调整其参数 (p, d, q) 却非常耗时。pmdarima 库中的 Auto ARIMA 能够自动化这一选择过程,让您无需猜测即可获得可靠的基线预测。
以下是一些入门代码:
import pmdarima as pm
import pandas as pd
# 加载时间序列 (单列数值)
df = pd.read_csv("sales.csv")
y = df["y"]
# 拟合Auto ARIMA (月度季节性示例)
model = pm.auto_arima(y, seasonal=True, m=12)
# 预测未来30步
forecast = model.predict(n_periods=30)
print(forecast)
//Sktime 和 Darts
如果您想超越传统的统计方法,像 sktime 和 Darts 这样的库为您提供了一个实验平台,可以测试数十种模型:从简单的 ARIMA 到先进的深度学习预测器。
它们非常适合在时间序列任务中尝试机器学习,而无需从头开始编写所有代码。
以下是一个简单的入门代码示例:
from darts.datasets import AirPassengersDataset
from darts.models import ExponentialSmoothing
# 加载示例数据集
series = AirPassengersDataset().load()
# 拟合一个简单模型
model = ExponentialSmoothing()
model.fit(series)
# 预测未来12个值
forecast = model.predict(12)
series.plot(label="实际值")
forecast.plot(label="预测值")
//AutoML 平台 (H2O, AutoGluon, Azure AutoML)
在企业环境中,有时您希望在不编写代码的情况下,尽可能自动化地获得预测结果。
AutoML 平台,如 H2O AutoML、AutoGluon 或 Azure AutoML,能够摄取原始时间序列数据,测试多种模型,并交付性能最佳的模型。
以下是一个使用 AutoGluon 的快速示例:
from autogluon.timeseries import TimeSeriesPredictor
import pandas as pd
# 加载数据集 (必须包含列: item_id, timestamp, target)
train_data = pd.read_csv("sales_multiseries.csv")
# 拟合AutoGluon时间序列预测器
predictor = TimeSeriesPredictor(
prediction_length=12,
path="autogluon_forecasts"
).fit(train_data)
# 为相同序列生成预测结果
forecasts = predictor.predict(train_data)
print(forecasts)
#何时“偷懒”不够用
自动化预测在大多数情况下都表现良好。但是,您应始终记住以下情况:
- 领域复杂性:当存在促销活动、节假日或定价变化时,您可能需要自定义特征。
- 异常情况:疫情、供应链冲击和其他罕见事件。
- 任务关键型精度:对于高风险场景(金融、医疗等),您需要一丝不苟。
“懒惰”并不意味着粗心大意。在使用预测结果进行商业决策之前,务必进行合理性检查。
#“懒惰”预测的最佳实践
即使您选择了“懒惰”的方式,也请遵循以下提示:
- 始终可视化预测结果和置信区间。
- 与简单的基线(最新值、移动平均)进行比较。
- 通过管道(Airflow、Prefect)实现再训练自动化。
- 保存模型和报告以确保可复现性。
#总结
时间序列预测不必令人望而生畏,也不必耗尽心力。
借助像 Prophet 或 Auto ARIMA 这样的 Python 预测库以及 AutoML 框架,您可以在几分钟内获得准确且易于解释的预测结果。
所以请记住:“懒惰”的数据科学家并非粗心,而是效率的体现。