

传统的“文本输入,文本输出”范式已难以满足现代应用的需求。
真正能创造实际价值的应用程序,应具备审视视觉信息、推演复杂问题,并生成可供其他系统直接利用的结构化输出的能力。
本文将深入探讨如何通过融合三项强大能力来构建这类应用:多模态输入、智能推理以及结构化输出。
为具体阐释这一概念,文章将通过一个实践案例进行讲解:利用OpenAI的o3模型,构建一个针对电商订单数据的时序异常检测系统。特别是,内容将展示如何将o3模型的推理能力与图像输入相结合,并输出经过验证的JSON格式数据,以便下游系统能够便捷地进行消费与处理。
最终,所构建的应用将具备以下核心能力:
- “能看”:分析电商订单量时序图表
- “能思”:识别异常模式
- “能整合”:输出结构化的异常报告
读者将获得可复用的功能代码,这些代码不仅适用于异常检测,还能扩展到多种其他应用场景。
接下来,让我们深入探索。
对更广泛的LLM在异常检测领域的应用感兴趣的读者,可查阅相关文章:《利用LLM提升异常检测能力》,该文总结了七种不容错过的新兴应用模式。
1. 案例研究
本文旨在构建一个异常检测解决方案,用于识别电商订单时序数据中的异常模式。
为此案例研究,生成了三组合成的日订单数据。这些数据集代表了大约一个月内日订单量的三种不同形态。为使季节性特征更为明显,周末时段已用阴影标注。X轴表示一周中的日期。
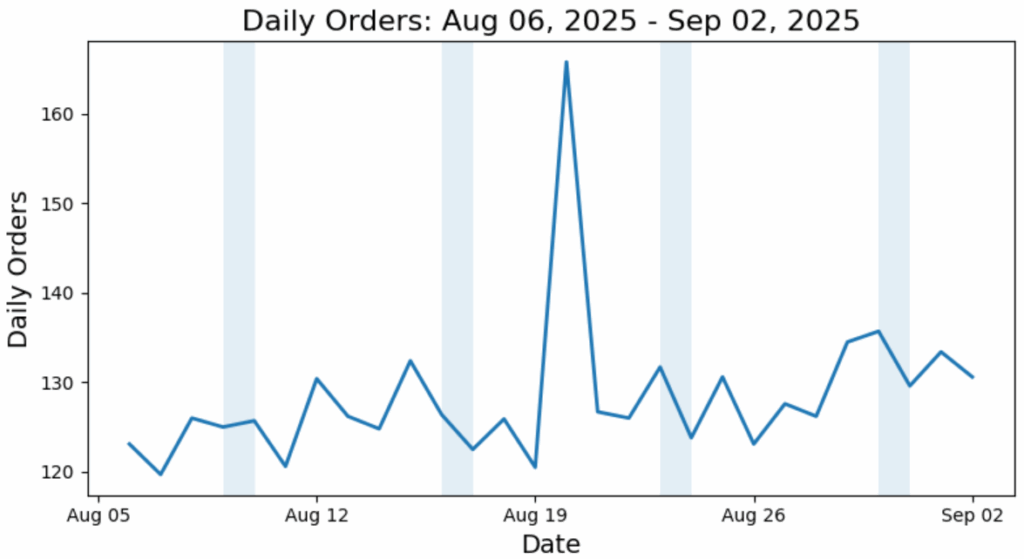
图1. 数据集1,阴影区域表示周末。(图片由作者提供)

图2. 数据集2,阴影区域表示周末。(图片由作者提供)
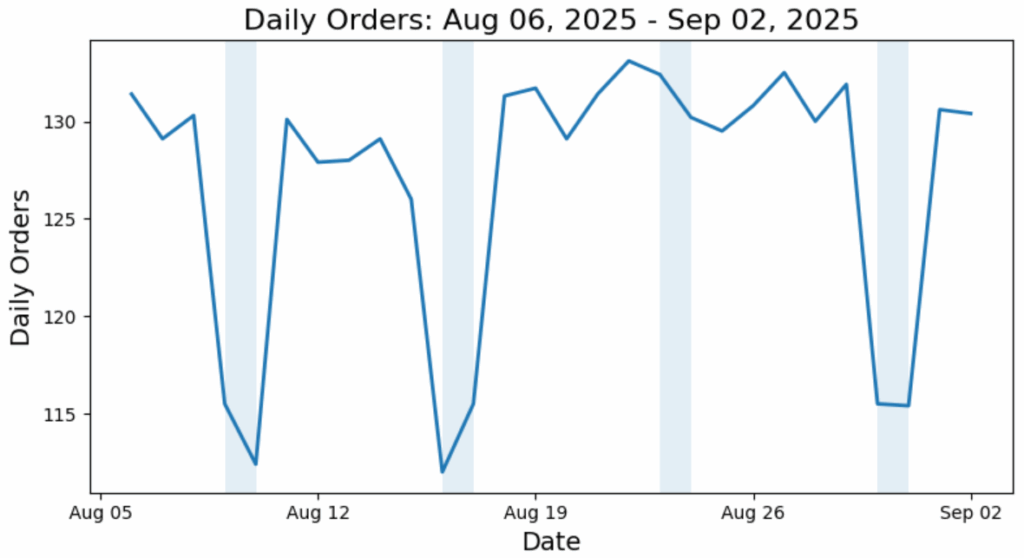
图3. 数据集3,阴影区域表示周末。(图片由作者提供)
每张图都包含一种特定类型的异常(读者能否找出?)。后续将利用这些图来测试异常检测方案,以验证其能否准确识别这些异常。
2. 解决方案
2.1 概述
与传统机器学习方法中繁琐的特征工程和模型训练不同,本方案采取了一种更为简洁的路径。其工作流程包括以下步骤:
- 首先,准备用于可视化电商订单时序数据的图表。
- 然后,向推理模型o3发送提示,要求其仔细审查输入的时序图像,并判断是否存在异常模式。
- 接着,o3模型将按照预定义的JSON格式输出其发现结果。
仅此而已,过程简洁明了。
当然,为了实现这一解决方案,需要确保o3模型能够接收图像输入并生成结构化输出。后续内容将详细阐述如何达成此目标。
2.2 推理模型的设置
如前所述,本文将采用o3模型,这是OpenAI的旗舰级推理模型,能够以领先的性能处理复杂的多步骤问题。具体来说,将使用Azure OpenAI终端点调用该模型。
确保已将终端点、API密钥和部署名称配置到.env文件中,之后即可着手设置LLM客户端:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from openai import AzureOpenAI
from dotenv import load_dotenv
import os
load_dotenv()
# Setup LLM client
endpoint = os.getenv("api_base")
api_key = os.getenv("o3_API_KEY")
api_version = "2025-04-01-preview"
model_name = "o3"
deployment = os.getenv("deployment_name")
LLM_client = AzureOpenAI(
api_key=api_key,
api_version=api_version,
azure_endpoint=endpoint
)
以下指令作为o3模型的系统消息(经GPT-5优化调整):
instruction = f"""
[Role]
您是一位严谨细致的数据分析师。
[Task]
您将获得一张关于每日电商订单的折线图。
您的任务是识别数据中显著的异常。
[Rules]
异常类型可以是尖峰(spike)、骤降(drop)、水平偏移(level_shift)或季节性异常(seasonal_outlier)。
水平偏移是指持续的基线变化(≥ 5个连续天数),而非单个点。
季节性异常发生在周末/工作日的行为与其同类不符时。
例如,周末订单量通常低于工作日。
从坐标轴读取日期/数值;如果无法精确读取,则取最近的刻度值,并在解释中注明不确定性。
图中的阴影区域表示周末。
"""
上述指令明确界定了LLM的角色、需完成的任务以及应遵循的规则。
为降低案例研究的复杂度,文章特意限定了LLM需识别的异常类型为四种。同时,也提供了这些异常类型的清晰定义,以消除潜在歧义。
最后,文章融入了部分关于电商模式的领域知识,例如,周末订单量通常低于工作日。融合领域知识普遍被认为是引导模型分析过程的良好实践。
模型设置完成后,接下来讨论如何为o3模型准备图像输入。
2.3 图像准备
为启用o3模型的多模态能力,需以特定格式提供图表,即公开可访问的网页URL或Base64编码的数据URL。由于图表是本地生成的,因此将采用第二种方法。
什么是Base64编码? Base64是一种将二进制数据(如图像文件)转换为仅包含文本字符的方式,使其能在互联网上安全传输。它将二进制图像数据转换为由字母、数字和少量符号组成的字符串。
那数据URL又是什么? 数据URL是一种特殊的URL,它直接在URL字符串中嵌入文件内容,而不是指向文件位置。
可使用以下函数自动完成此转换:
import io
import base64
def fig_to_data_url(fig, fmt="png"):
"""
将Matplotlib图转换为Base64数据URL,不保存到磁盘。
参数:
-----
fig (matplotlib.figure.Figure): 待转换的图。
fmt (str): 图像格式("png", "jpeg"等)。
返回:
--------
str: 代表该图的数据URL。
"""
buf = io.BytesIO()
fig.savefig(buf, format=fmt, bbox_inches="tight")
buf.seek(0)
base64_encoded_data = base64.b64encode(buf.read()).decode("utf-8")
mime_type = f"image/{fmt.lower()}"
return f"data:{mime_type};base64,{base64_encoded_data}"
实质上,该函数首先将Matplotlib图保存到内存缓冲区,然后将二进制PNG数据编码为Base64文本,并将其封装成所需的数据URL格式。
假设已获得合成的日订单数据,可使用以下函数一步到位地生成图表并将其转换为合适的数据URL格式:
def create_fig(df):
"""
创建Matplotlib图并将其转换为Base64数据URL。
周末(周六至周日)用阴影标注。
参数:
-----
df: 包含日订单时序数据的一个形态的数据框。
数据框包含“date”和“orders”列。
返回:
--------
image_url: 代表该图的数据URL。
"""
df = df.copy()
df['date'] = pd.to_datetime(df['date'])
fig, ax = plt.subplots(figsize=(8, 4.5))
ax.plot(df["date"], df["orders"], linewidth=2)
ax.set_xlabel('日期', fontsize=14)
ax.set_ylabel('每日订单量', fontsize=14)
# Weekend shading
start = df["date"].min().normalize()
end = df["date"].max().normalize()
cur = start
while cur <= end:
if cur.weekday() == 5: # Saturday 00:00
span_start = cur # Sat 00:00
span_end = cur + pd.Timedelta(days=1) # Mon 00:00
ax.axvspan(span_start, span_end, alpha=0.12, zorder=0)
cur += pd.Timedelta(days=2) # skip Sunday
else:
cur += pd.Timedelta(days=1)
# Title
title = f'每日订单量: {df["date"].min():%b %d, %Y} - {df["date"].max():%b %d, %Y}'
ax.set_title(title, fontsize=16)
# Format x-axis dates
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b %d'))
ax.xaxis.set_major_locator(mdates.WeekdayLocator(interval=1))
plt.tight_layout()
# Obtain url
image_url = fig_to_data_url(fig)
return image_url
图1-3均由上述绘图程序生成。
2.4 结构化输出
本节将探讨如何确保o3模型输出一致的JSON格式,而非自由文本。这就是所谓的“结构化输出”,它是将LLM集成到现有自动化工作流中的关键促成因素之一。
为实现此目标,首先需定义管理预期输出结构的Schema。本文将采用Pydantic模型:
from pydantic import BaseModel, Field
from typing import Literal
from datetime import date
AnomalyKind = Literal["spike", "drop", "level_shift", "seasonal_outlier"]
class DateWindow(BaseModel):
start: date = Field(description="异常开始的最早可能日期(ISO YYYY-MM-DD格式)")
end: date = Field(description="异常结束的最晚可能日期,包含当日(ISO YYYY-MM-DD格式)")
class AnomalyReport(BaseModel):
when: DateWindow = Field(
description=(
"包含异常的最小时间窗口。 "
"对于单点异常,如果刻度标签不清晰,请使用涵盖读取不确定性的时间间隔"
)
)
y: int = Field(description="异常最具代表性日期(峰值/最低点)的大致值,已四舍五入")
kind: AnomalyKind = Field(description="异常的类型")
why: str = Field(description="解释此时间窗口为何异常的一句话原因")
date_confidence: Literal["low","medium","high"] = Field(
default="medium", description="时间窗口定位的置信度"
)
所设计的Pydantic Schema旨在捕捉检测到的异常的定量和定性方面。对于每个字段,都指定了其数据类型(例如,数值的int,固定选项集的Literal等)。
此外,还利用Field函数为每个键提供了详细描述。这些描述尤为重要,因为它们有效地充当了o3模型的内联指令,使其能够理解每个组件的语义含义。
至此,已涵盖多模态输入和结构化输出的准备工作,接下来是时候将它们整合到一次LLM调用中。
2.5 o3模型调用
为了通过多模态输入和结构化输出来与o3模型交互,采用LLM_client.beta.chat.completions.parse() API。其中一些关键参数包括:
model:部署名称;messages:发送给o3模型的消息对象;max_completion_token:模型在最终响应中可以生成的最大token数量。请注意,对于像o3这样的推理模型,它们会在内部生成reasoning_tokens来“思考”问题。当前的max_completion_token仅限制用户接收到的可见输出token;response_format:定义预期JSON Schema结构的Pydantic模型;reasoning_effort:一个控制旋钮,用于指示o3应投入多少计算资源进行推理。可用选项包括低(low)、中(medium)和高(high)。
可以定义一个辅助函数来与o3模型进行交互:
def anomaly_detection(instruction, fig_path,
response_format, prompt=None,
deployment="o3", reasoning_effort="high"):
# Compose messages
messages=[
{ "role": "system", "content": instruction},
{ "role": "user", "content": [
{
"type": "image_url",
"image_url": {
"url": fig_path,
"detail": "high"
}
},
]}
]
# Add prompt if it is given
if prompt is not None:
messages[1]["content"].append({"type": "text", "text": prompt})
# Invoke LLM API
response = LLM_client.beta.chat.completions.parse(
model=deployment,
messages=messages,
max_completion_tokens=4000,
reasoning_effort=reasoning_effort,
response_format=response_format
)
return response.choices[0].message.parsed.model_dump()
请注意,messages对象同时接受文本和图像内容。由于主要使用图表来提示模型,文本提示在此处是可选的。
将"detail": "high"设置为高,以启用高分辨率图像处理。对于本案例研究,这很可能是必要的,因为模型需要更好地读取轴刻度标签、数据点值和细微视觉模式等细节。然而,需注意高细节处理会消耗更多token并导致更高的API成本。
最后,通过使用.parsed.model_dump(),将JSON输出转换为常见的Python字典格式。
至此,实现部分已完成。接下来,让我们看一些结果。
3. 结果
本节将把之前生成的图表输入o3模型,并要求其识别潜在异常。
3.1 尖峰异常
# df_spike_anomaly 是第一组合成数据的数据框 (图1)
spike_anomaly_url = create_fig(df_spike_anomaly)
# Anomaly detection
result = anomaly_detection(instruction,
spike_anomaly_url,
response_format=AnomalyReport,
reasoning_effort="medium")
print(result)
上述调用中,spike_anomaly_url是图1的数据URL。结果输出如下所示:
{
'when': {'start': datetime.date(2025, 8, 19), 'end': datetime.date(2025, 8, 21)},
'y': 166,
'kind': 'spike',
'why': '单日订单量跃升至约166,远高于相邻几天约120-130的水平。',
'date_confidence': 'medium'
}
可以看到,o3模型忠实地以设计好的格式返回了输出结果。现在,可以获取此结果并以编程方式生成可视化图表:
# Create image
fig, ax = plt.subplots(figsize=(8, 4.5))
df_spike_anomaly['date'] = pd.to_datetime(df_spike_anomaly['date'])
ax.plot(df_spike_anomaly["date"], df_spike_anomaly["orders"], linewidth=2)
ax.set_xlabel('日期', fontsize=14)
ax.set_ylabel('每日订单量', fontsize=14)
# Format x-axis dates
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b %d'))
ax.xaxis.set_major_locator(mdates.WeekdayLocator(interval=1))
# Add anomaly overlay
start_date = pd.to_datetime(result['when']['start'])
end_date = pd.to_datetime(result['when']['end'])
# Add shaded region
ax.axvspan(start_date, end_date, alpha=0.3, color='red', label=f"异常 ({result['kind']})")
# Add text annotation
mid_date = start_date + (end_date - start_date) / 2 # Middle of anomaly window
ax.annotate(
result['why'],
xy=(mid_date, result['y']),
xytext=(10, 20), # Offset from the point
textcoords='offset points',
bbox=dict(boxstyle='round,pad=0.5', fc='yellow', alpha=0.7),
arrowprops=dict(arrowstyle='->', connectionstyle='arc3,rad=0.1'),
fontsize=10,
wrap=True
)
# Add legend
ax.legend()
plt.xticks(rotation=0)
plt.tight_layout()
生成的可视化图表如下所示:
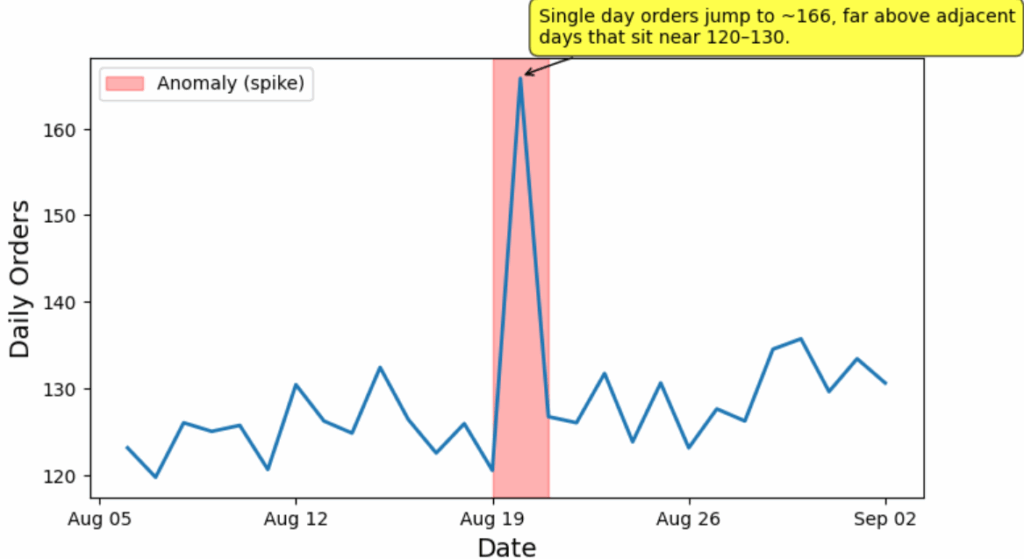
图4. 图1的异常检测结果。(图片由作者提供)
可以看出,o3模型正确识别了这第一组合成数据中呈现的尖峰异常。
表现不俗,尤其考虑到没有进行任何传统的模型训练,仅仅通过提示LLM就达到了这一效果。
3.2 水平偏移异常
# df_level_shift_anomaly 是第二组合成数据的数据框 (图2)
level_shift_anomaly_url = create_fig(df_level_shift_anomaly)
# Anomaly detection
result = anomaly_detection(instruction,
level_shift_anomaly_url,
response_format=AnomalyReport,
reasoning_effort="medium")
print(result)
结果输出如下所示:
{
'when': {'start': datetime.date(2025, 8, 26), 'end': datetime.date(2025, 9, 2)},
'y': 150,
'kind': 'level_shift',
'why': '订单量在8月26日突然从120-135的区间跃升至约150,并在随后的所有日子里保持高位,表明基线发生了持续性变化。',
'date_confidence': 'high'
}
同样,可以看到模型准确识别出图中存在一个“水平偏移”异常:
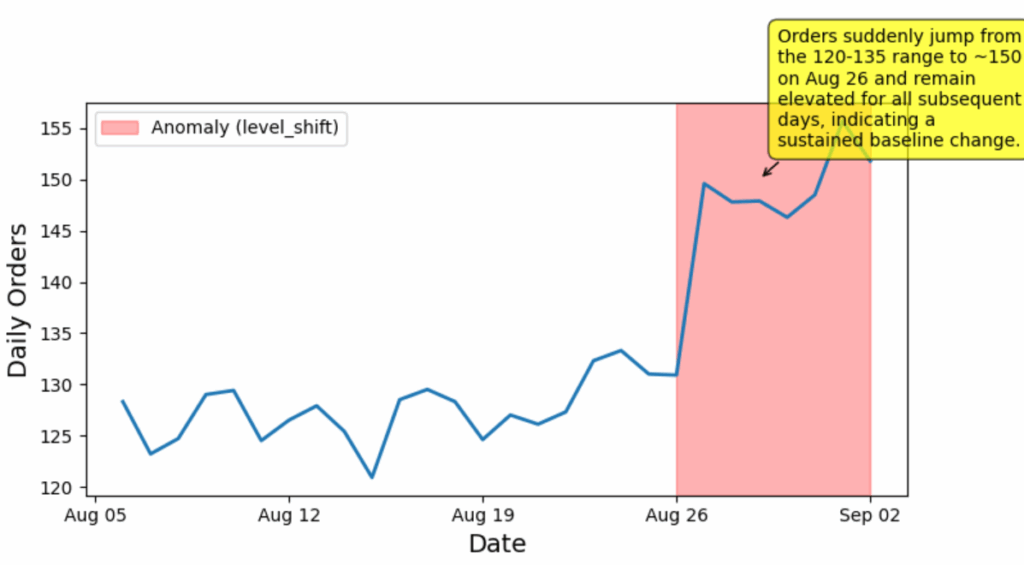
图5. 图2的异常检测结果。(图片由作者提供)
3.3 季节性异常
# df_seasonality_anomaly 是第三组合成数据的数据框 (图3)
seasonality_anomaly_url = create_fig(df_seasonality_anomaly)
# Anomaly detection
result = anomaly_detection(instruction,
seasonality_anomaly_url,
response_format=AnomalyReport,
reasoning_effort="medium")
print(result)
结果输出如下所示:
{
'when': {'start': datetime.date(2025, 8, 23), 'end': datetime.date(2025, 8, 24)},
'y': 132,
'kind': 'seasonal_outlier',
'why': '8月23-24日的周末订单量(约130+)与周围工作日持平,而其他周末订单量普遍降至约115,使其成为一个反季节的尖峰。',
'date_confidence': 'high'
}
这是一个颇具挑战性的案例。然而,o3模型仍然妥善地解决了它,实现了准确的异常定位和清晰的推理路径,令人印象深刻:

图6. 图3的异常检测结果。(图片由作者提供)
4. 总结
恭喜!已成功构建了一个完全通过可视化和提示机制运行的时序数据异常检测解决方案。
通过将日订单图表输入o3推理模型,并将其输出约束为JSON schema,LLM成功识别了三种不同类型的异常,且定位准确。所有这些都未经过任何ML模型训练。其效果令人赞叹!
回顾所构建的解决方案,可以看出它展示了结合以下三种能力的更广泛模式:
- “能看”:多模态输入,使模型能够直接消费图表。
- “能思”:逐步推理能力,以解决复杂问题。
- “能整合”:结构化输出,下游系统能够轻松消费(例如,生成可视化)。
多模态输入 + 推理 + 结构化输出的组合,确实为构建有用的LLM应用奠定了多功能的基础。




