对于数据科学家而言,首次体验n8n工作流时,其便捷性可能令人感到惊喜。该平台无需查阅冗长的API文档,即可轻松连接各类API,还能通过Gmail或Google Sheets触发工作流,数分钟内便可部署实用功能。
然而,一个显著的局限在于,n8n的云实例并未原生优化以支持Python环境,这对于习惯使用Python进行数据分析的用户来说,可能构成挑战。
与许多数据科学家一样,日常数据分析工具箱主要基于NumPy和Pandas构建。为了保持在熟悉的领域内工作,文章常常将计算任务外包给外部API,而非直接使用n8n的JavaScript代码节点。

例如,一个生产计划优化工具的实现就是通过一个工作流来编排的,该工作流包含一个调用FastAPI微服务的Agent节点。这种方法虽然有效,但有客户提出希望在n8n用户界面上完全可见数据分析任务的执行过程。
文章作者意识到有必要学习足够的JavaScript,以便利用n8n的原生代码节点执行数据处理任务。

本文将探讨如何在n8n代码节点内部使用小型JavaScript代码片段,来执行日常数据分析任务。为演示目的,文章将使用一个销售交易数据集,并逐步进行ABC和帕累托分析,这两种分析在供应链管理中应用广泛。

文章将提供Pandas与n8n JavaScript代码节点的对比示例,以便将熟悉的Python数据分析步骤直接转换为自动化的n8n工作流。

核心思想是在云企业级n8n实例的能力范围内(即不使用社区节点),为小型数据集或快速原型设计实现这些解决方案。

本次实验将以快速比较研究作为总结,对比其与FastAPI调用的性能表现。读者可以根据文章中分享的Google Sheet和工作流模板,复现整个工作流。
在n8n中使用JavaScript构建数据分析工作流
在开始构建节点之前,文章将介绍本次分析的背景。
供应链管理中的ABC与帕累托图表
本教程建议读者构建一个简单的工作流,该工作流从Google Sheets获取销售交易数据,并将其转换为全面的ABC和帕累托图表。这将复现作者初创公司LogiGreen开发的LogiGreen Apps中的ABC和帕累托分析模块。

其目标是为超市连锁店的库存团队生成一套可视化图表,帮助他们理解销售在各门店间的分布情况。文章将重点生成两个可视化图表。
第一个图表展示了销售商品的ABC-XYZ分析:

- X轴 (销售额百分比 %):各商品对总收入的贡献。
- Y轴 (变异系数):各商品的需求变异性。
- 垂直红线根据销售额份额将商品分为A、B和C类。
- 水平蓝线标记了稳定需求与变动需求(CV=1)。
这些指标共同突出了哪些商品是高价值且稳定 (A类,低CV),哪些是低价值或高度变动的,从而指导库存管理中的优先级排序。
第二个可视化图表是销售额的帕累托分析:

- X轴:SKU百分比(按销售额排名)。
- Y轴:年度销售额累计百分比。
- 曲线说明了少量商品如何贡献大部分收入。
简而言之,这突出(或未突出)了经典的帕累托法则,即80%的销售额可能来自20%的SKU。
这些图表是如何生成的?简单来说,就是通过Python实现。
在一个YouTube频道上,有提供完整的教程,展示了如何使用Pandas和Matplotlib完成此操作。本教程的目标是利用n8n的原生JavaScript节点,在Google Sheet中准备销售交易数据并生成这些图表。
在n8n中构建数据分析工作流
建议构建一个手动触发的工作流,以方便开发过程中的调试。

读者若要跟随本教程,需要完成以下步骤:
- 复制此链接提供的电子表格:Google Sheet
- 从n8n作者资料下载模板
现在,可以使用第二个节点(将从工作表Input Data中提取数据集)连接已复制的Google Sheet。

该数据集包含每日粒度的零售销售交易:
ITEM: 可以在多个门店销售的商品SKU: 在特定门店销售的SKUFAMILY: 商品组CATEGORY: 产品类别,可包含多个商品组STORE: 代表销售地点的代码DAY: 交易日期QTY: 销售数量(单位)TO: 销售额(欧元)
输出是JSON格式的表格内容,可供其他节点使用。
Python 代码
import pandas as pd
df = pd.read_csv("sales.csv")
接下来,可以开始处理数据集以构建两个可视化图表。
步骤 1: 过滤掉销量为零的交易
首先,从过滤掉销量QTY等于零的交易这一简单操作开始。
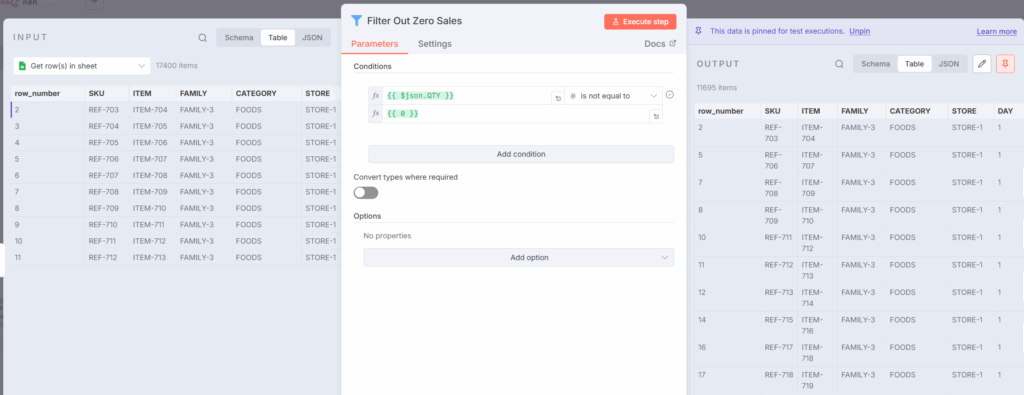
无需JavaScript;一个简单的Filter节点即可完成任务。
Python 代码
df = df[df["QTY"] != 0]
步骤 2: 为帕累托分析准备数据
首先需要按ITEM聚合销售数据并按销售额排名产品。
Python 代码
sku_agg = (df.groupby("ITEM", as_index=False)
.agg(TO=("TO","sum"), QTY=("QTY","sum"))
.sort_values("TO", ascending=False))
在工作流中,这一步骤将在JavaScript节点TO, QTY GroupBY ITEM中完成:
const agg = {};
for (const {json} of items) {
const ITEM = json.ITEM;
const TO = Number(json.TO);
const QTY = Number(json.QTY);
if (!agg[ITEM]) agg[ITEM] = { ITEM, TO: 0, QTY: 0 };
agg[ITEM].TO += TO;
agg[ITEM].QTY += QTY;
}
const rows = Object.values(agg).sort((a,b)=> b.TO - a.TO);
return rows.map(r => ({ json: r }));
此节点返回按ITEM分类的销售额(TO)和数量(QTY)的排名表:
- 初始化agg为一个以ITEM为键的字典。
- 遍历n8n的行数据。
- 将TO和QTY转换为数字。
- 将QTY和TO值添加到每个ITEM的累计总额中。
- 最终将字典转换为按TO降序排列的数组并返回数据。

现在数据已准备好,可以对销售数量(QTY)或销售额(TO)进行帕累托分析。为此,需要计算累计销售额并对SKU进行排名,从最高贡献者到最低贡献者。
Python 代码
abc = sku_agg.copy() # from Step 2, already sorted by TO desc
total = abc["TO"].sum() or 1.0
abc["cum_turnover"] = abc["TO"].cumsum()
abc["cum_share"] = abc["cum_turnover"] / total
abc["sku_rank"] = range(1, len(abc) + 1)
abc["cum_skus"] = abc["sku_rank"] / len(abc)
abc["cum_skus_pct"] = abc["cum_skus"] * 100
这一步骤将在代码节点Pareto Analysis中完成:
const rows = items
.map(i => ({
...i.json,
TO: Number(i.json.TO || 0),
QTY: Number(i.json.QTY || 0),
}))
.sort((a, b) => b.TO - a.TO);
const n = rows.length; // number of ITEM
const totalTO = rows.reduce((s, r) => s + r.TO, 0) || 1;
从上一个节点收集数据集items:
- 对于每一行,清理字段
TO和QTY(以防有缺失值)。 - 按销售额降序排序所有SKU。
- 将商品总数和总销售额存储在变量中。
let cumTO = 0;
rows.forEach((r, idx) => {
cumTO += r.TO;
r.cum_turnover = cumTO;
r.cum_share = +(cumTO / totalTO).toFixed(6);
r.sku_rank = idx + 1;
r.cum_skus = +((idx + 1) / n).toFixed(6);
r.cum_skus_pct = +(r.cum_skus * 100).toFixed(2);
});
return rows.map(r => ({ json: r }));
然后遍历所有已排序的商品:
- 使用变量
cumTO计算累计贡献。 - 向每一行添加多个帕累托指标:
cum_turnover: 截至当前商品的累计销售额。cum_share: 销售额累计份额。sku_rank: 商品排名。cum_skus: SKU累计数量占总SKU的比例。cum_skus_pct: 与cum_skus相同,但以百分比表示。
至此,帕累托图表的数据准备工作完成。

该数据集将由节点Update Pareto Sheet存储到Pareto工作表中。通过一些巧妙的操作,可以在第一个工作表中生成此图表:

现在可以继续进行ABC XYZ图表的创建。
步骤 3: 计算需求变异性和销售贡献
虽然可以复用帕累托图表的输出来计算销售贡献,但为清晰起见,文章将每个图表视为独立处理。为清晰起见,‘需求变异性’与‘销售额百分比’节点中的代码将被拆分为多个片段。
代码块 1: 定义均值和标准差函数
function mean(a){ return a.reduce((s,x)=>s + x, 0) / (a.length || 1); }
function stdev_samp(a){
if (a.length <= 1) return 0;
const m = mean(a);
const v = a.reduce((s,x)=> s + (x - m) ** 2, 0) / (a.length - 1);
return Math.sqrt(v);
}
这两个函数将用于计算变异系数(Cov):
mean(a): 计算数组的平均值。stdev_samp(a): 计算样本标准差。
它们接收作为输入的数据是我们在第二个代码块中构建的每个ITEM的每日销售分布。
代码块 2: 创建每个ITEM的每日销售分布
const series = {}; // ITEM -> { day -> qty_sum }
let totalQty = 0;
for (const { json } of items) {
const item = String(json.ITEM);
const day = String(json.DAY);
const qty = Number(json.QTY || 0);
if (!series[item]) series[item] = {};
series[item][day] = (series[item][day] || 0) + qty;
totalQty += qty;
}
Python 代码
import pandas as pd
import numpy as np
df['QTY'] = pd.to_numeric(df['QTY'], errors='coerce').fillna(0)
daily_series = df.groupby(['ITEM', 'DAY'])['QTY'].sum().reset_index()
现在可以计算应用于每日销售分布的指标。
const out = [];
for (const [item, dayMap] of Object.entries(series)) {
const daily = Object.values(dayMap); // daily sales quantities
const qty_total = daily.reduce((s,x)=>s+x, 0);
const m = mean(daily); // average daily sales
const sd = stdev_samp(daily); // variability of sales
const cv = m ? sd / m : null; // coefficient of variation
const share_qty_pct = totalQty ? (qty_total / totalQty) * 100 : 0;
out.push({
ITEM: item,
qty_total,
share_qty_pct: Number(share_qty_pct.toFixed(2)),
mean_qty: Number(m.toFixed(3)),
std_qty: Number(sd.toFixed(3)),
cv_qty: cv == null ? null : Number(cv.toFixed(3)),
});
}
对于每个ITEM,计算以下指标:
qty_total: 总销售额。mean_qty: 日均销售额。std_qty: 日销售额标准差。cv_qty: 变异系数(用于XYZ分类的变异性衡量指标)。share_qty_pct: 对总销售额的贡献百分比(用于ABC分类)。
以下是Python版本,以防读者在阅读过程中迷失:
summary = daily_series.groupby('ITEM').agg(
qty_total=('QTY', 'sum'),
mean_qty=('QTY', 'mean'),
std_qty=('QTY', 'std')
).reset_index()
summary['std_qty'] = summary['std_qty'].fillna(0)
total_qty = summary['qty_total'].sum()
summary['cv_qty'] = summary['std_qty'] / summary['mean_qty'].replace(0, np.nan)
summary['share_qty_pct'] = 100 * summary['qty_total'] / total_qty
工作已接近完成。只需按贡献降序排序,为ABC分类映射做准备:
out.sort((a,b) => b.share_qty_pct - a.share_qty_pct);
return out.map(r => ({ json: r }));
现在,对于每个ITEM,都拥有了创建散点图所需的关键指标。

在此步骤中,仅缺少ABC分类。
步骤 4: 添加ABC分类
将上一个节点的输出作为输入。
let rows = items.map(i => i.json);
rows.sort((a, b) => b.share_qty_pct - a.share_qty_pct);
为确保万无一失,按销售额份额(%)降序排列商品 → 最重要的SKU排在前面。(此步骤通常已在上一代码节点结束时完成,可选择省略。)
然后可以根据预设条件进行分类:
- A: 合计占前5%销售额的SKU。
- B: 合计占接下来15%销售额的SKU。
- C: 20%之后的所有SKU。
let cum = 0;
for (let r of rows) {
cum += r.share_qty_pct;
// 3) 根据累计百分比分配类别
if (cum <= 5) {
r.ABC = 'A'; // 前 5%
} else if (cum <= 20) {
r.ABC = 'B'; // 接下来 15%
} else {
r.ABC = 'C'; // 剩余部分
}
r.cum_share = Number(cum.toFixed(2));
}
return rows.map(r => ({ json: r }));
通过Python代码可以这样实现:
df = df.sort_values('share_qty_pct', ascending=False).reset_index(drop=True)
df['cum_share'] = df['share_qty_pct'].cumsum()
def classify(cum):
if cum <= 5:
return 'A'
elif cum <= 20:
return 'B'
else:
return 'C'
df['ABC'] = df['cum_share'].apply(classify)
现在,结果可用于生成此图表,该图表可在Google Sheet的第一个工作表中找到:

由于对Google Sheets的知识有限,文章作者难以找到一种“手动”解决方案来创建具有正确颜色映射的散点图。因此,文章使用了Google Sheets中提供的Google Apps Script来创建它。
作为附加内容,n8n模板中还添加了更多节点,用于执行相同类型的分组操作,以计算按门店或按ITEM-门店对的销售额。
这些节点可用于创建类似这样的可视化图表:

总结本教程,可以确信任务已圆满完成。若要观看工作流的实时演示,可以查阅这个简短的教程。
在n8n云实例上运行此工作流的客户,现在可以清晰地看到数据处理的每一步。
但这是否意味着性能有所损失?
这正是下一节将要探讨的问题。
性能对比研究:n8n JavaScript节点 vs. FastAPI中的Python
为回答这个问题,文章准备了一个直接的实验。使用两种不同的方法在n8n内部处理相同的数据集和转换:
- 纯JavaScript节点:所有功能直接在n8n内部实现。
- 外包给FastAPI微服务:将JavaScript逻辑替换为对Python端点的HTTP请求。

这两个端点连接到直接从托管微服务的VPS实例加载数据的函数。
@router.post("/launch_pareto")
async def launch_speedtest(request: Request):
try:
session_id = request.headers.get('session_id', 'session')
folder_in = f'data/session/speed_test/input'
if not path.exists(folder_in):
makedirs(folder_in)
file_path = folder_in + '/sales.csv'
logger.info(f"[SpeedTest]: Loading data from session file: {file_path}")
df = pd.read_csv(file_path, sep=";")
logger.info(f"[SpeedTest]: Data loaded successfully: {df.head()}")
speed_tester = SpeedAnalysis(df)
output = await speed_tester.process_pareto()
result = output.to_dict(orient="records")
result = speed_tester.convert_numpy(result)
logger.info(f"[SpeedTest]: /launch_pareto completed successfully for {session_id}")
return result
except Exception as e:
logger.error(f"[SpeedTest]: Error /launch_pareto: {str(e)}
{traceback.format_exc()}")
raise HTTPException(status_code=500, detail=f"Failed to process Speed Test Analysis: {str(e)}")
@router.post("/launch_abc_xyz")
async def launch_abc_xyz(request: Request):
try:
session_id = request.headers.get('session_id', 'session')
folder_in = f'data/session/speed_test/input'
if not path.exists(folder_in):
makedirs(folder_in)
file_path = folder_in + '/sales.csv'
logger.info(f"[SpeedTest]: Loading data from session file: {file_path}")
df = pd.read_csv(file_path, sep=";")
logger.info(f"[SpeedTest]: Data loaded successfully: {df.head()}")
speed_tester = SpeedAnalysis(df)
output = await speed_tester.process_abcxyz()
result = output.to_dict(orient="records")
result = speed_tester.convert_numpy(result)
logger.info(f"[SpeedTest]: /launch_abc_xyz completed successfully for {session_id}")
return result
except Exception as e:
logger.error(f"[SpeedTest]: Error /launch_abc_xyz: {str(e)}
{traceback.format_exc()}")
raise HTTPException(status_code=500, detail=f"Failed to process Speed Test Analysis: {str(e)}")
本次测试将仅关注数据处理性能。
SpeedAnalysis类包含了上一节中列出的所有数据处理步骤:
- 按
ITEM分组销售额 - 按降序排列
ITEM并计算累计销售额 - 计算按
ITEM分类的销售分布的标准差和均值
class SpeedAnalysis:
def __init__(self, df: pd.DataFrame):
config = load_config()
self.df = df
def processing(self):
try:
sales = self.df.copy()
sales = sales[sales['QTY']>0].copy()
self.sales = sales
except Exception as e:
logger.error(f'[SpeedTest] Error for processing : {e}
{traceback.format_exc()}')
def prepare_pareto(self):
try:
sku_agg = self.sales.copy()
sku_agg = (sku_agg.groupby("ITEM", as_index=False)
.agg(TO=("TO","sum"), QTY=("QTY","sum"))
.sort_values("TO", ascending=False))
pareto = sku_agg.copy()
total = pareto["TO"].sum() or 1.0
pareto["cum_turnover"] = pareto["TO"].cumsum()
pareto["cum_share"] = pareto["cum_turnover"] / total
pareto["sku_rank"] = range(1, len(pareto) + 1)
pareto["cum_skus"] = pareto["sku_rank"] / len(pareto)
pareto["cum_skus_pct"] = pareto["cum_skus"] * 100
return pareto
except Exception as e:
logger.error(f'[SpeedTest]Error for prepare_pareto: {e}
{traceback.format_exc()}')
def abc_xyz(self):
daily = self.sales.groupby(["ITEM", "DAY"], as_index=False)["QTY"].sum()
stats = (
daily.groupby("ITEM")["QTY"]
.agg(
qty_total="sum",
mean_qty="mean",
std_qty="std"
)
.reset_index()
)
stats["cv_qty"] = stats["std_qty"] / stats["mean_qty"].replace(0, np.nan)
total_qty = stats["qty_total"].sum()
stats["share_qty_pct"] = (stats["qty_total"] / total_qty * 100).round(2)
stats = stats.sort_values("share_qty_pct", ascending=False).reset_index(drop=True)
stats["cum_share"] = stats["share_qty_pct"].cumsum().round(2)
def classify(cum):
if cum <= 5:
return "A"
elif cum <= 20:
return "B"
else:
return "C"
stats["ABC"] = stats["cum_share"].apply(classify)
return stats
def convert_numpy(self, obj):
if isinstance(obj, dict):
return {k: self.convert_numpy(v) for k, v in obj.items()}
elif isinstance(obj, list):
return [self.convert_numpy(v) for v in obj]
elif isinstance(obj, (np.integer, int)):
return int(obj)
elif isinstance(obj, (np.floating, float)):
return float(obj)
else:
return obj
async def process_pareto(self):
"""Main processing function that calls all other methods in order."""
self.processing()
outputs = self.prepare_pareto()
return outputs
async def process_abcxyz(self):
"""Main processing function that calls all other methods in order."""
self.processing()
outputs = self.abc_xyz().fillna(0)
logger.info(f"[SpeedTest]: ABC-XYZ analysis completed {outputs}.")
return outputs
这些端点准备就绪后,即可开始测试。

结果如上所示:
- 纯JavaScript工作流:整个过程在略多于11.7秒内完成。
大部分时间花费在更新工作表和在n8n节点内执行迭代计算。
- FastAPI支持的工作流:等效的“外包”过程在约11.0秒内完成。
繁重的计算任务被卸载到Python微服务,其处理速度比原生JavaScript节点更快。
换句话说,将复杂计算外包给Python实际上可以提高性能。原因是FastAPI端点直接执行优化后的Python函数,而n8n内部的JavaScript节点必须通过循环进行迭代。对于大型数据集,性能差异可能会更大,不容忽视。
结论
这表明,通过使用小段JavaScript代码,可以在n8n中进行简单的数据处理。然而,供应链分析产品可能需要更高级的处理,涉及优化和高级统计库。

为此,客户可以接受“黑盒”方法,正如这篇Towards Data Science文章中介绍的生产计划工作流所示。
但对于轻量级处理任务,可以将其集成到工作流中,为非代码用户提供可见性。
在另一个项目中,n8n被用于连接供应链IT系统以进行采购订单的电子数据交换(EDI)。

这个为一家小型物流公司部署的工作流,完全使用JavaScript节点解析EDI消息。

如本教程所示,电子数据交换消息的解析完全通过JavaScript节点完成。这有助于提高解决方案的健壮性,并通过将维护工作移交给客户来减轻工作量。
那么,最佳方法是什么?
n8n应作为核心分析产品的编排与集成工具。这些分析产品需要特定的输入格式,可能与客户的数据不完全匹配。因此,建议使用JavaScript代码节点来执行这种预处理。

例如,上述工作流将Google Sheet(包含输入数据)连接到运行配送计划优化算法的FastAPI微服务。其目的是将优化算法集成到配送规划人员用于组织门店配送的Google Sheet中。

JavaScript代码节点用于将从Google Sheet收集的数据转换为算法所需的输入格式。通过在工作流内部完成这些工作,它仍然受控于在自己实例中运行工作流的客户。而优化部分可以保留在托管于服务商实例上的微服务中。
为了更好地理解此设置,可以观看这个简短的演示。希望本教程及上述示例能让读者对n8n在数据分析方面的应用有所了解。欢迎分享对这种方法的评论,以及对如何改进工作流性能的看法。