计算机视觉是人工智能的一个重要子领域,其广泛应用集中于图像处理与理解。传统上,这一领域主要通过卷积神经网络(CNNs)来解决,但随着Transformer架构的出现,计算机视觉领域正经历一场革命。尽管Transformer以其在自然语言处理中的应用而闻名,但它已被成功改造,成为许多视觉模型的核心骨干。本文将深入探讨一系列前沿的视觉模型和多模态模型,例如ViT(视觉Transformer)、DETR(检测Transformer)、BLIP(自举语言-图像预训练)和ViLT(视觉语言Transformer),这些模型专注于多种计算机视觉任务,包括图像分类、图像分割、图像到文本转换(图像描述)和视觉问答。这些任务在现实世界中拥有多样化的应用,从大规模图像标注、医学图像异常检测,到从文档中提取文本以及根据视觉数据生成文本响应,都发挥着关键作用。
与CNNs的比较
在基础模型广泛应用之前,卷积神经网络(CNNs)一直是大多数计算机视觉任务的主导解决方案。简而言之,CNNs 构成了一种分层的深度学习架构,包含特征图、池化层、线性层和全连接层。相比之下,视觉Transformer模型利用自注意力机制,允许图像块之间相互关注。它们还具有较少的归纳偏置,这意味着它们不像CNN那样受特定模型假设的严格约束,但因此需要在通用任务上取得强大性能时,消耗显著更多的训练数据。
与LLMs的比较
基于Transformer的视觉模型借鉴了大型语言模型(LLMs)所使用的架构,并额外添加了将图像数据转换为数值嵌入的层。在自然语言处理任务中,文本序列在被Transformer编码器处理之前,会经历分词和嵌入的过程。类似地,图像/视觉数据在送入视觉Transformer编码器之前,也需要经过分块(patching)、位置编码和图像嵌入等步骤。在本文中,读者将进一步了解视觉Transformer及其变体如何建立在Transformer骨干架构之上,并将语言处理的能力扩展到图像理解和图像生成领域。
向多模态模型的扩展
视觉模型的进步推动了开发能够同时处理图像和文本数据的多模态模型的兴趣。视觉模型通常侧重于将图像数据单向转换为数值表示,并通常为分类或目标检测(即图像分类和图像分割任务)生成基于分数的输出;而多模态模型则需要不同数据类型之间的双向处理和整合。例如,一个图像-文本多模态模型能够从图像输入生成连贯的文本序列,以完成图像描述和视觉问答等任务。
四大核心计算机视觉任务类型
0. 项目概览
本文将详细探讨这四种核心计算机视觉任务以及专门用于每项任务的相应Transformer模型。这些模型主要在其编码器和解码器架构上有所不同,这赋予了它们在解释、处理和跨不同文本或视觉模态进行转换的独特能力。
为增强本指南的互动性,特设计了一个Streamlit网络应用,用于演示和比较这些计算机视觉任务及模型的输出。本文末尾将介绍这个端到端应用的开发过程。
下方是基于上传图像的输出预览,通过运行Hugging Face管道中的默认模型,展示了任务名称、输出、运行时间、模型名称和模型类型。

1. 图像分类
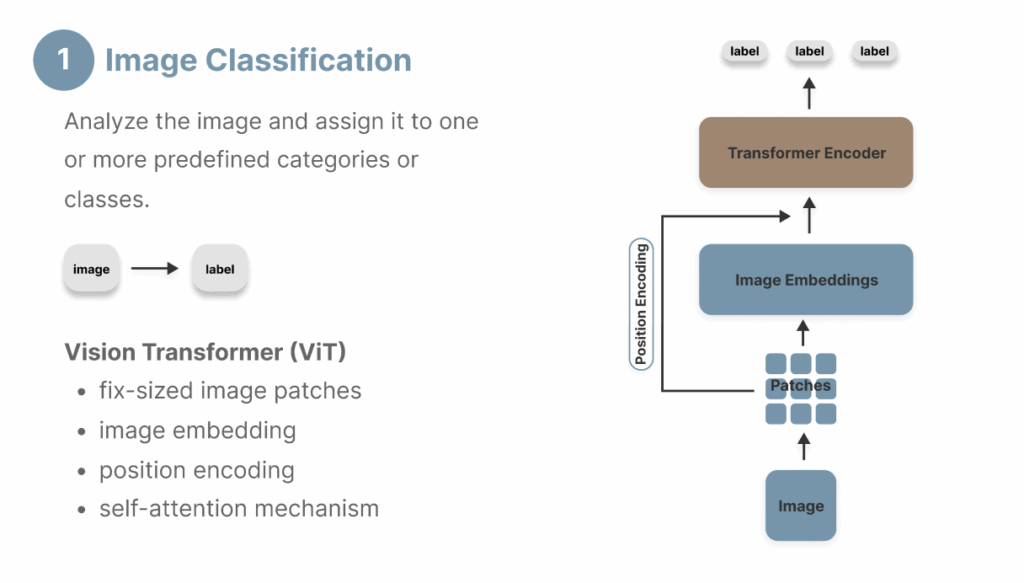 首先,本文介绍图像分类——这是一项基础的计算机视觉任务,旨在将图像分配到一组预定义的标签中,通过基础的视觉Transformer即可实现。
首先,本文介绍图像分类——这是一项基础的计算机视觉任务,旨在将图像分配到一组预定义的标签中,通过基础的视觉Transformer即可实现。
ViT(视觉Transformer)
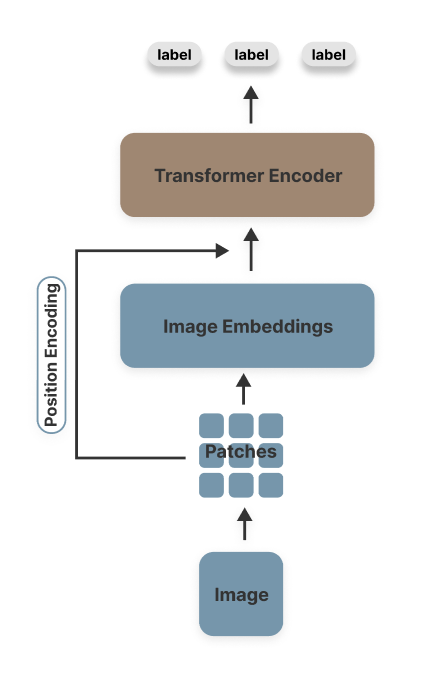 视觉Transformer(ViT)是本文后续介绍的许多计算机视觉模型的基石。通过其仅编码器的Transformer架构,ViT在图像分类任务上持续超越了CNN。它处理图像输入并为候选标签输出概率分数。由于图像分类纯粹是图像理解任务,不涉及生成要求,因此ViT的仅编码器架构非常适合此目的。
视觉Transformer(ViT)是本文后续介绍的许多计算机视觉模型的基石。通过其仅编码器的Transformer架构,ViT在图像分类任务上持续超越了CNN。它处理图像输入并为候选标签输出概率分数。由于图像分类纯粹是图像理解任务,不涉及生成要求,因此ViT的仅编码器架构非常适合此目的。
ViT架构由以下组件构成:
- 分块(Patching):将输入图像分解为固定大小的小块像素(通常每个块16×16像素),以保留局部特征供后续处理。
- 嵌入(Embedding):将图像块转换为数值表示,也称为向量嵌入,使得具有相似特征的图像在向量空间中被映射为距离更近的嵌入。
- 分类令牌(Classification Token, CLS):从所有图像块中提取和聚合信息,形成一个单一的数值表示,使其在分类任务中特别有效。
- 位置编码(Position Encoding):保留原始图像像素的相对位置。CLS令牌始终位于位置0。
- Transformer编码器(Transformer Encoder):通过多头注意力层和前馈网络处理嵌入。
ViT背后的机制使其能够高效捕捉全局依赖性,而CNN主要通过卷积核依赖局部处理。另一方面,ViT的缺点在于需要大量的训练数据(通常是数百万张图像),才能迭代调整注意力层中的模型参数,从而在任务中达到强大的性能。
实现
Hugging Face的pipeline极大地简化了图像分类任务的实现,它抽象了底层图像处理步骤。
from transformers import pipeline
from PIL import Image
image = Image.open(image_url)
pipe = pipeline(task="image-classification", model=model_id)
output = pipe(image=image)
-
输入参数:
model:可以选择自定义模型,或者在未指定model参数时使用默认模型(例如“google/vit-base-patch16-224”)。task:提供任务名称(例如“image-classification”,“image-segmentation”)。image:通过URL或图像文件路径提供图像对象。
-
输出:模型为候选标签生成分数。
通过提供两张构图相似但背景不同的图像,比较了默认图像分类模型“google/vit-base-patch16-224”的结果。可以看出,尽管两张图像都包含相同的主体物体,但这个基线模型很容易混淆,产生了显著不同的输出(“espresso”与“microwave”)。
“咖啡杯”图像输出

[
{ "label": "espresso", "score": 0.40687331557273865 },
{ "label": "cup", "score": 0.2804579734802246 },
{ "label": "coffee mug", "score": 0.17347976565361023 },
{ "label": "desk", "score": 0.01198530849069357 },
{ "label": "eggnog", "score": 0.00782513152807951 }
]
“带背景的咖啡杯”图像输出

[
{ "label": "microwave, microwave oven", "score": 0.20218633115291595 },
{ "label": "dining table, board", "score": 0.14855517446994781 },
{ "label": "stove", "score": 0.1345038264989853 },
{ "label": "sliding door", "score": 0.10262308269739151 },
{ "label": "shoji", "score": 0.07306522130966187 }
]
读者可以使用Streamlit网络应用尝试不同的模型,看看是否能生成更好的结果。
2. 图像分割
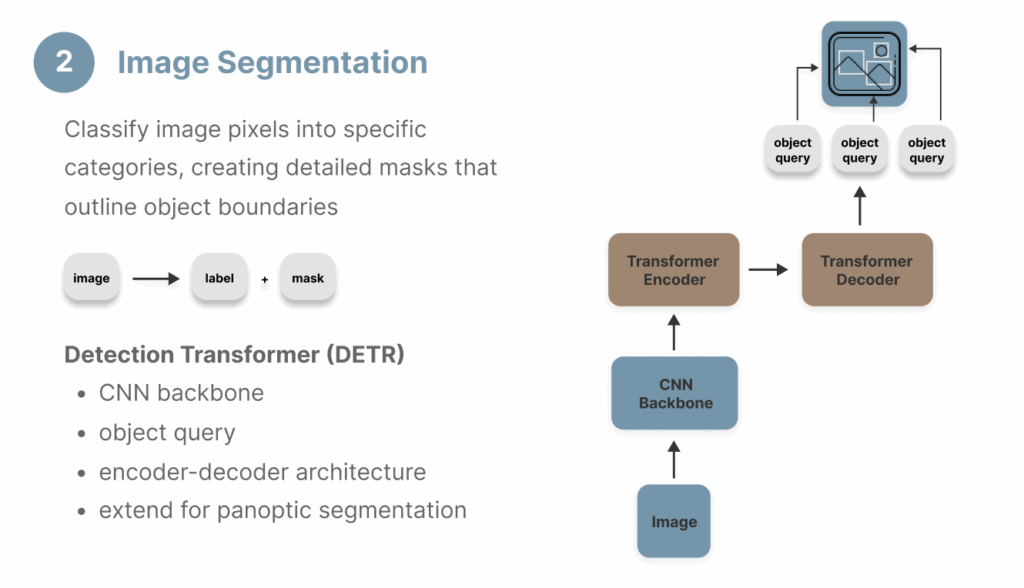 图像分割是另一种常见的计算机视觉任务,通常需要纯视觉模型。其目标与目标检测相似,但在像素级别上要求更高的精度,生成对象边界的掩码,而非目标检测所需的边界框。
图像分割是另一种常见的计算机视觉任务,通常需要纯视觉模型。其目标与目标检测相似,但在像素级别上要求更高的精度,生成对象边界的掩码,而非目标检测所需的边界框。
图像分割主要有三种类型:
- 语义分割(Semantic segmentation):为每个对象类别预测一个掩码。
- 实例分割(Instance segmentation):为每个对象实例预测一个掩码。
- 全景分割(Panoptic segmentation):结合实例分割和语义分割,为每个像素分配一个对象类别和该类别的一个实例。
DETR(检测Transformer)
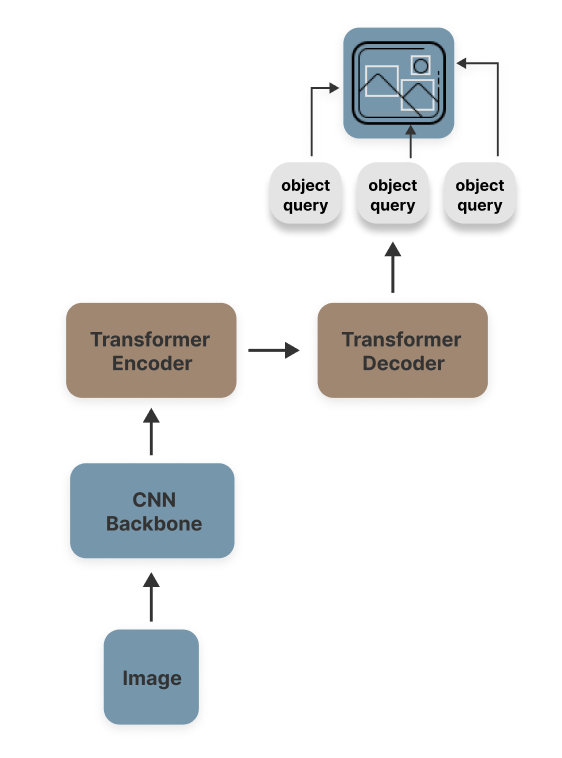 尽管DETR广泛应用于目标检测,但通过添加一个分割掩码头,它可被扩展以执行全景分割任务。如图所示,DETR利用编码器-解码器Transformer架构,并以CNN作为特征图提取的骨干网络。DETR模型学习一组对象查询,并训练其预测这些查询的边界框,随后通过一个掩码预测头执行精确的像素级分割。
尽管DETR广泛应用于目标检测,但通过添加一个分割掩码头,它可被扩展以执行全景分割任务。如图所示,DETR利用编码器-解码器Transformer架构,并以CNN作为特征图提取的骨干网络。DETR模型学习一组对象查询,并训练其预测这些查询的边界框,随后通过一个掩码预测头执行精确的像素级分割。
Mask2Former
Mask2Former也是图像分割任务的常见选择。由Facebook AI Research开发,Mask2Former通常在精度和计算效率上优于DETR模型。这得益于其采用了掩码注意力机制(masked attention mechanism),而非全局交叉注意力,从而使其能够更专注于图像中的前景信息和主要对象。
实现
图像分割的实现与图像分类类似,只需将task参数替换为“image-segmentation”即可。为了处理输出,代码会提取对象标签和掩码,然后使用st.image()显示带有掩码的图像。
from transformers import pipeline
from PIL import Image
import streamlit as st
image = Image.open(image_url)
pipe = pipeline(task="image-segmentation", model=model_id)
output = pipe(image=image)
output_labels = [i['label'] for i in output]
output_masks = [i['mask'] for i in output]
for m in output_masks:
st.image(m)
本文比较了在全景分割上进行微调的DETR(“facebook/detr-resnet-50-panoptic”)和Mask2Former(“facebook/mask2former-swin-base-coco-panoptic”)的性能。在分割输出中显示,DETR和Mask2Former都成功识别并提取了“杯子”和“餐桌”。Mask2Former以更快的速度(2.47秒,而DETR为6.3秒)进行推理,并且还成功从背景中识别出“窗户-其他”物体。
DETR “facebook/detr-resnet-50-panoptic”输出
[
{
'score': 0.994395,
'label': 'dining table',
'mask': <PIL.Image.Image image mode=L size=996x886 at 0x7FAEA068D130>
},
{
'score': 0.999692,
'label': 'cup',
'mask': <PIL.Image.Image image mode=L size=996x886 at 0x7FAEA0657290>
}
]

Mask2Former “facebook/mask2former-swin-base-coco-panoptic”输出
[
{
'score': 0.999554,
'label': 'cup',
'mask': <PIL.Image.Image image mode=L size=996x886 at 0x7FAEAC25BF80>
},
{
'score': 0.971946,
'label': 'dining table',
'mask': <PIL.Image.Image image mode=L size=996x886 at 0x7FAEA6907EF0>
},
{
'score': 0.983782,
'label': 'window-other',
'mask': <PIL.Image.Image image mode=L size=996x886 at 0x7FAF22942B40>
}
]

3. 图像描述(Image Captioning)
 图像描述,也称为图像到文本(image-to-text)转换,旨在将图像内容翻译成相应的文本序列。这项任务需要同时具备图像理解和文本生成的能力,因此非常适合能够同时处理图像和文本数据的多模态模型。
图像描述,也称为图像到文本(image-to-text)转换,旨在将图像内容翻译成相应的文本序列。这项任务需要同时具备图像理解和文本生成的能力,因此非常适合能够同时处理图像和文本数据的多模态模型。
视觉编码器-解码器(Visual Encoder-Decoder)
视觉编码器-解码器是一种多模态架构,它结合了用于图像理解的视觉模型和用于文本生成的预训练语言模型。一个常见的例子是ViT-GPT2,它将视觉Transformer(在第一节“图像分类”中介绍)作为视觉编码器,将GPT-2模型作为解码器,以执行自回归文本生成任务。
BLIP(自举语言-图像预训练)
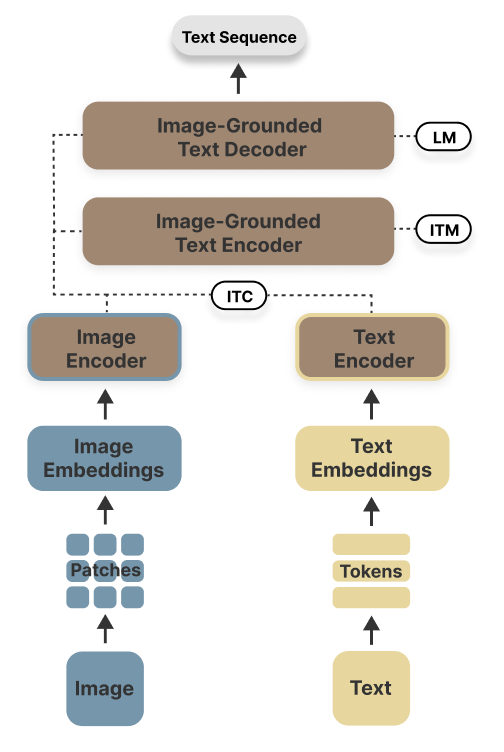 由Salesforce Research开发的BLIP,利用了四个核心模块:一个图像编码器、一个文本编码器,随后是一个通过注意力机制融合视觉和文本特征的图像-文本融合编码器,以及一个用于文本序列生成的图像-文本解码器。其预训练过程涉及最小化图像-文本对比损失、图像-文本匹配损失和语言建模损失,旨在对齐视觉信息与文本序列之间的语义关系。BLIP在应用中提供了更高的灵活性,可用于视觉问答(VQA)等任务,但同时也在架构设计上增加了更多复杂性。
由Salesforce Research开发的BLIP,利用了四个核心模块:一个图像编码器、一个文本编码器,随后是一个通过注意力机制融合视觉和文本特征的图像-文本融合编码器,以及一个用于文本序列生成的图像-文本解码器。其预训练过程涉及最小化图像-文本对比损失、图像-文本匹配损失和语言建模损失,旨在对齐视觉信息与文本序列之间的语义关系。BLIP在应用中提供了更高的灵活性,可用于视觉问答(VQA)等任务,但同时也在架构设计上增加了更多复杂性。
实现
通过以下代码片段,可以从图像描述管道生成输出。
from transformers import pipeline
from PIL import Image
image = Image.open(image_url)
pipe = pipeline(task="image-to-text", model=model_id)
output = pipe(image=image)
本文尝试了以下三个不同的模型,它们都生成了相当准确的图像描述,其中较大的模型性能优于基础模型。
视觉编码器-解码器 “ydshieh/vit-gpt2-coco-en”输出
[{'generated_text': 'a cup of coffee sitting on a wooden table'}]
BLIP “Salesforce/blip-image-captioning-base”输出
[{'generated_text': 'a cup of coffee on a table'}]
BLIP “Salesforce/blip-image-captioning-large”输出
[{'generated_text': 'there is a cup of coffee on a saucer on a table'}]
4. 视觉问答(Visual Question Answering, VQA)
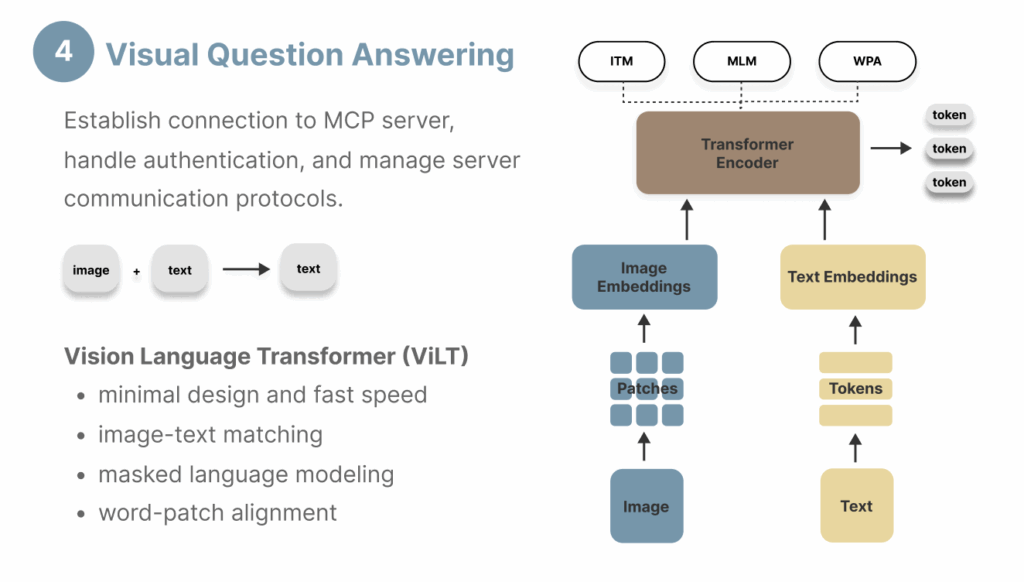 视觉问答(VQA)因其允许用户对图像提问并获得连贯的文本响应而日益普及。这项任务同样需要一个多模态模型,该模型必须能够提取视觉数据中的关键信息,并同时具备生成文本响应的能力。VQA与图像描述任务的区别在于,除了图像之外,它还接受用户提供的文本提示作为输入,因此需要一个能够同时解释两种模态的编码器。
视觉问答(VQA)因其允许用户对图像提问并获得连贯的文本响应而日益普及。这项任务同样需要一个多模态模型,该模型必须能够提取视觉数据中的关键信息,并同时具备生成文本响应的能力。VQA与图像描述任务的区别在于,除了图像之外,它还接受用户提供的文本提示作为输入,因此需要一个能够同时解释两种模态的编码器。
ViLT(视觉语言Transformer)
 ViLT是一种用于执行视觉问答任务的计算高效模型架构。ViLT将图像块嵌入(image patch embeddings)和文本嵌入整合到一个统一的Transformer编码器中,该编码器经过以下三个目标进行预训练:
ViLT是一种用于执行视觉问答任务的计算高效模型架构。ViLT将图像块嵌入(image patch embeddings)和文本嵌入整合到一个统一的Transformer编码器中,该编码器经过以下三个目标进行预训练:
- 图像-文本匹配:学习图像与文本对之间的语义关系。
- 掩码语言建模:根据文本和图像输入,学习预测词汇表中被掩码的词语或令牌。
- 词块对齐:学习词语与图像块之间的关联。
ViLT采用仅编码器的架构,并配有任务特定的头部(例如分类头、VQA头),这种极简设计比依赖区域监督进行目标检测和卷积架构进行特征提取的VLP(视觉-语言预训练)模型速度快十倍。然而,这种简化的架构在复杂任务上可能导致次优性能,并且需要大量的训练数据才能实现通用功能。正如后面所演示,一个缺点是ViLT模型为VQA生成的是基于令牌的输出,而不是连贯的句子,这非常类似于具有大量候选标签的图像分类任务。
BLIP
正如“3. 图像描述”一节所介绍的,BLIP是一个更全面的模型,也可以通过微调来执行视觉问答任务。由于其编码器-解码器架构,它能够生成完整的文本序列而非仅仅是令牌。
实现
VQA的实现使用了以下代码片段,将图像和文本提示都作为模型输入。
from transformers import pipeline
from PIL import Image
import streamlit as st
image = Image.open(image_url)
question='describe this image'
pipe = pipeline(task="image-to-text", model=model_id, question=question)
output = pipe(image=image)
当比较ViLT和BLIP模型对于问题“describe this image”的回答时,由于其独特的模型架构,输出结果存在显著差异。ViLT从其现有词汇表中预测得分最高的令牌,而BLIP则生成更连贯、更合理的答案。
ViLT “dandelin/vilt-b32-finetuned-vqa”输出
[
{ "score": 0.044245753437280655, "answer": "kitchen" },
{ "score": 0.03294338658452034, "answer": "tea" },
{ "score": 0.030773703008890152, "answer": "table" },
{ "score": 0.024886665865778923, "answer": "office" },
{ "score": 0.019653357565402985, "answer": "cup" }
]
BLIP “Salesforce/blip-vqa-capfilt-large”输出
[{'answer': 'coffee cup on saucer'}]
端到端计算机视觉应用开发
将网络应用开发分解为6个易于遵循的步骤,以构建自己的交互式Streamlit应用或根据需要进行定制。读者可在GitHub仓库中查看完整的实现代码。
- 初始化网络应用并配置页面布局。
def initialize_page():
"""初始化Streamlit页面配置和布局"""
st.set_page_config(
page_title="Computer Vision",
page_icon="",
layout="centered"
)
st.title("Computer Vision Tasks")
content_block = st.columns(1)[0]
return content_block
- 提示用户上传图像。
def get_uploaded_image():
uploaded_file = st.file_uploader(
"上传您的图像",
accept_multiple_files=False,
type=["jpg", "jpeg", "png"]
)
if uploaded_file:
image = Image.open(uploaded_file)
st.image(image, caption='预览', use_container_width=False)
else:
image = None
return image
- 使用多选下拉列表选择一个或多个计算机视觉任务(也接受用户输入的选项,例如“document-question-answering”)。如果选择了“visual-question-answering”或“document-question-answering”,将提示用户输入问题,因为这两个任务需要“question”作为额外的输入参数。
def get_selected_task():
options = st.multiselect(
"您希望执行哪些任务?",
[
"visual-question-answering",
"image-to-text",
"image-classification",
"image-segmentation",
],
max_selections=4,
accept_new_options=True,
)
#如果任务是'VQA'和'DocVQA',则提示输入问题 - 参数"question"
if 'visual-question-answering' in options or 'document-question-answering' in options:
question = st.text_input(
"请输入您的问题:"
)
elif "其他(请指定任务名称)" in options:
task = st.text_input(
"请输入任务名称:"
)
options = task
question = ""
else:
question = ""
return options, question
- 提示用户选择使用Hugging Face管道内置的默认模型,或输入自定义模型。
def get_selected_model():
options = ["使用默认模型", "使用您选择的HuggingFace模型"]
selected_option = st.selectbox("选择一个选项:", options)
if selected_option == "使用您选择的HuggingFace模型":
model = st.text_input(
"请输入您选择的HuggingFace模型ID:"
)
else:
model = None
return model
- 根据用户输入的参数创建任务管道,然后收集模型输出和处理时间。结果将以表格形式使用
st.dataframe()显示,以比较不同的任务名称、输出、运行时间、模型名称和模型类型。对于图像分割任务,分割掩码也会使用st.image()显示。
def display_results(image, task_list, user_question, model):
results = []
for task in task_list:
if task in ['visual-question-answering', 'document-question-answering']:
params = {'question': user_question}
else:
params = {}
row = {
'task': task,
}
try:
# 注:原文这里有i['model'],但i未定义,推测原意是model变量
# 为了代码可运行,这里直接使用传入的model变量或让pipeline自动选择
pipe = pipeline(task, model=model if model else None)
row['model'] = model if model else pipe.model.name_or_path
except Exception as e:
pipe = pipeline(task)
row['model'] = pipe.model.name_or_path
start_time = time.time()
output = pipe(
image,
**params
)
execution_time = time.time() - start_time
row['model_type'] = pipe.model.config.model_type
row['time'] = execution_time
# 显示图像分割视觉输出
if task == 'image-segmentation':
output_masks = [i['mask'] for i in output]
row['output'] = str(output)
results.append(row)
results_df = pd.DataFrame(results)
st.write('模型响应')
st.dataframe(results_df)
if 'image-segmentation' in task_list:
st.write('分割掩码输出')
if 'output_masks' in locals(): # 确保output_masks已定义
for m in output_masks:
st.image(m)
return results_df
- 最后,使用主函数将这些功能串联起来。使用“生成响应”按钮触发这些功能并在应用程序中显示结果。
def main():
initialize_page()
image = get_uploaded_image()
task_list, user_question = get_selected_task()
model = get_selected_model()
# 生成响应加载动画
if st.button("生成响应", key="generate_button"):
import time # 确保time模块在此处被导入
import pandas as pd # 确保pandas模块在此处被导入
display_results(image, task_list, user_question, model)
# 运行应用程序
if __name__ == "__main__":
main()
总结
本文介绍了从传统的基于CNN的方法到Transformer架构的演变,并比较了视觉模型与语言模型以及多模态模型。此外,还探讨了四种核心计算机视觉任务及其相应的技术,并提供了一个实用的Streamlit实现指南,以帮助读者构建自己的计算机视觉网络应用程序进行进一步探索。
核心计算机视觉任务及模型包括: