快速原型开发(Rapid Prototyping)是指构建产品简易版本并持续收集用户反馈的过程,旨在快速验证重要的假设,评估关键风险。这种方法与敏捷软件开发实践、“精益创业”(Lean Startup)方法论中的“构建-测量-学习”循环紧密结合,能够显著降低开发成本并缩短产品上市时间。鉴于人工智能相关技术、用例和用户期望仍处于早期阶段,快速原型开发对于成功交付AI产品尤为重要。
为此,Streamlit于2019年发布,作为一个Python框架,它简化了需要用户界面(UI)的AI应用原型开发过程。数据科学家和工程师可以专注于后端部分(例如,训练机器学习模型并通过API暴露预测接口),而Streamlit仅需几行Python代码即可生成一个用户友好且可定制的UI。Chainlit同样是一个Python框架,于2023年发布,专门用于解决会话式AI应用(即聊天机器人)原型开发中的痛点。虽然Streamlit和Chainlit在某些方面相似,但它们之间也存在重要的差异。本文将通过构建端到端的聊天机器人演示应用,探讨这两个框架的优缺点,并提供实用的建议。
注意:以下各节中的所有图表均为示意图。
端到端聊天机器人演示
本地环境设置
为了简化起见,演示应用程序的构建旨在便于在本地环境中测试,采用通过Ollama访问的开源大型语言模型(LLM)。Ollama是一个用户友好的工具,用于在本地机器上下载、管理和交互开源LLM。
当然,这些演示后期可以修改以用于生产环境,例如,通过利用OpenAI或Google等公司提供的最新LLM,并将聊天机器人部署在AWS、Azure或GCP等常用超大规模云平台上。以下所有实现步骤均已在macOS Sequoia 15.6.1上测试通过,在Linux和Windows上的操作应大致相似。
请点击此处下载并安装Ollama。通过在终端中运行以下命令检查安装是否成功:
ollama --version
本文将使用谷歌轻量级Gemma 2模型,该模型具有2B参数,可通过以下命令下载:
ollama pull gemma:2b
模型文件大小约为1.7 GB,因此下载可能需要几分钟,具体取决于网络连接速度。使用以下命令验证模型是否已下载:
ollama list
此命令将显示通过Ollama已下载的所有模型。
接下来,将使用uv来设置项目目录,uv是一个快速且用户友好的Python项目管理工具。请按照此处的说明安装uv,并通过以下命令验证安装:
uv --version
在本地机器上的合适位置初始化一个名为chatbot-demos的项目目录,操作如下:
uv init --bare chatbot-demos
如果未指定--bare选项,uv会在初始化期间创建一些标准文件,例如main.py、README.md和一个Python版本锁定文件,但这些文件在本次演示中并不需要。最小化过程仅创建一个pyproject.toml文件。
在chatbot-demos项目目录中,创建一个requirements.txt文件,包含以下依赖项:
chainlit==2.7.2
ollama==0.5.3
streamlit==1.49.1
现在,在项目目录内创建一个Python 3.12虚拟环境,激活该环境并安装依赖项:
uv venv --python=3.12
source .venv/bin/activate
uv add -r requirements.txt
检查依赖项是否已安装:
uv pip list
将实现一个名为LLMClient的类,用于处理后端功能,该功能可以与以UI为中心的功能解耦,这是Streamlit和Chainlit等框架的关键区别所在。例如,LLMClient可以负责选择LLM提供商、执行LLM调用、与外部数据库交互以实现检索增强生成(RAG),以及记录对话历史以供后续分析。以下是LLMClient的一个示例实现,保存在名为llm_client.py的文件中:
import logging
import time
from datetime import datetime, timezone
from typing import List, Dict, Optional, Callable, Any, Generator
import os
import ollama
LOG_FILE = os.path.join(os.path.dirname(__file__), "conversation_history.log")
logger = logging.getLogger("conversation_logger")
logger.setLevel(logging.INFO)
if not logger.handlers:
fh = logging.FileHandler(LOG_FILE, encoding="utf-8")
fmt = logging.Formatter("%(asctime)s - %(message)s")
fh.setFormatter(fmt)
logger.addHandler(fh)
class LLMClient:
def __init__(
self,
provider: str = "ollama",
model: str = "gemma:2b",
temperature: float = 0.2,
retriever: Optional[Callable[[str], List[str]]] = None,
feedback_handler: Optional[Callable[[Dict[str, Any]], None]] = None,
logger: Optional[Callable[[Dict[str, Any]], None]] = None
):
self.provider = provider
self.model = model
self.temperature = temperature
self.retriever = retriever
self.feedback_handler = feedback_handler
self.logger = logger or self.default_logger
def default_logger(self, data: Dict[str, Any]):
logging.info(f"[LLMClient] {data}")
def _format_messages(self, messages: List[Dict[str, str]]) -> str:
return "
".join(f"{m['role'].capitalize()}: {m['content']}" for m in messages)
def _stream_provider(self, prompt: str, temperature: float) -> Generator[str, None, None]:
if self.provider == "ollama":
for chunk in ollama.generate(
model=self.model,
prompt=prompt,
stream=True,
options={"temperature": temperature}
):
yield chunk.get("response", "")
else:
raise ValueError(f"Streaming not implemented for provider: {self.provider}")
def stream_generate(
self,
messages: List[Dict[str, str]],
on_token: Callable[[str], None],
temperature: Optional[float] = None
) -> Dict[str, Any]:
start_time = time.time()
if self.retriever:
query = messages[-1]["content"]
docs = self.retriever(query)
if docs:
context_str = "
".join(docs)
messages = [{"role": "system", "content": f"Use this context:
{context_str}"}] + messages
prompt = self._format_messages(messages)
assembled_text = ""
temp_to_use = temperature if temperature is not None else self.temperature
try:
for token in self._stream_provider(prompt, temp_to_use):
assembled_text += token
on_token(token)
except Exception as e:
assembled_text = f"Error: {e}"
latency = time.time() - start_time
result = {
"text": assembled_text,
"timestamp": datetime.now(timezone.utc),
"latency": latency,
"provider": self.provider,
"model": self.model,
"temperature": temp_to_use,
"messages": messages
}
self.logger({
"event": "llm_stream_call",
"provider": self.provider,
"model": self.model,
"temperature": temp_to_use,
"latency": latency,
"prompt": prompt,
"response": assembled_text
})
return result
def record_feedback(self, feedback: Dict[str, Any]):
if self.feedback_handler:
self.feedback_handler(feedback)
else:
self.logger({"event": "feedback", **feedback})
def log_interaction(self, role: str, content: str):
logger.info(f"{role.upper()}: {content}")
Streamlit基础演示
在项目目录中创建一个名为st_app_basic.py的文件,并粘贴以下代码:
import streamlit as st
from llm_client import LLMClient
MAX_HISTORY = 5
llm_client = LLMClient(provider="ollama", model="gemma:2b")
st.set_page_config(page_title="Streamlit Basic Chatbot", layout="centered")
st.title("Streamlit Basic Chatbot")
if "messages" not in st.session_state:
st.session_state.messages = []
# Display chat history
for msg in st.session_state.messages:
with st.chat_message(msg["role"]):
st.markdown(msg["content"])
# User input
if prompt := st.chat_input("Type your message..."):
st.session_state.messages.append({"role": "user", "content": prompt})
st.session_state.messages = st.session_state.messages[-MAX_HISTORY:]
llm_client.log_interaction("user", prompt)
with st.chat_message("assistant"):
response_container = st.empty()
state = {"full_response": ""}
def on_token(token):
state["full_response"] += token
response_container.markdown(state["full_response"])
result = llm_client.stream_generate(st.session_state.messages, on_token)
st.session_state.messages.append({"role": "assistant", "content": result["text"]})
llm_client.log_interaction("assistant", result["text"])
通过以下命令在localhost:8501启动应用程序:
streamlit run st_app_basic.py
如果应用程序未自动在默认浏览器中打开,请手动导航至该URL(http://localhost:8501)。读者将看到一个基础的聊天界面。在输入框中输入以下问题并按回车键:
如何将摄氏度转换为华氏度?
图1显示了结果:

图1:Streamlit初始问答界面
现在,提出以下追问:
你能用Python实现这个公式吗?
由于演示实现会跟踪最多5条之前的对话历史,聊天机器人能够将“这个公式”与前一个提示中的公式关联起来,如下图2所示:
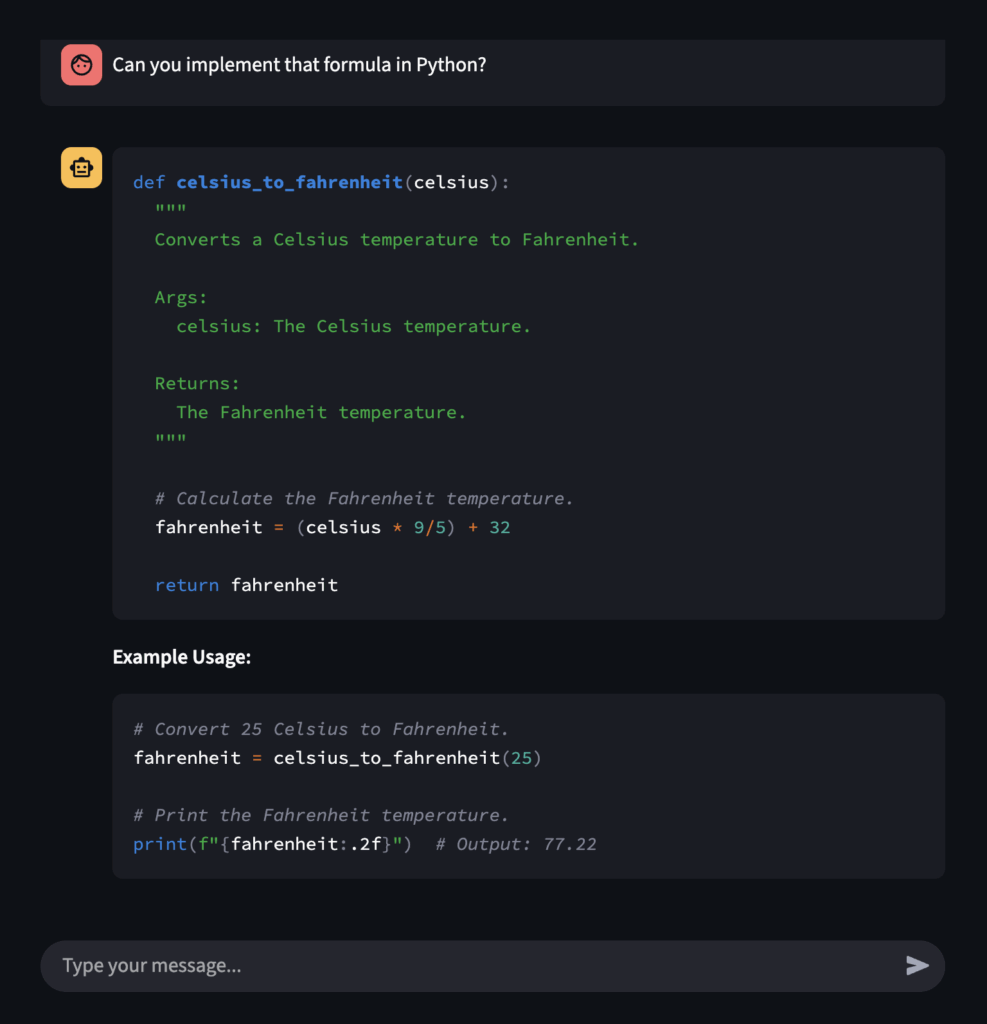
图2:Streamlit后续问答界面
读者可以随意尝试更多提示。要关闭应用程序,请在终端中执行Control + c。
Chainlit基础演示
在项目目录中创建一个名为cl_app_basic.py的文件,并粘贴以下代码:
import chainlit as cl
from llm_client import LLMClient
MAX_HISTORY = 5
llm_client = LLMClient(provider="ollama", model="gemma:2b")
@cl.on_chat_start
async def start():
await cl.Message(content="Welcome! Ask me anything.").send()
cl.user_session.set("messages", [])
@cl.on_message
async def main(message: cl.Message):
messages = cl.user_session.get("messages")
messages.append({"role": "user", "content": message.content})
messages[:] = messages[-MAX_HISTORY:]
llm_client.log_interaction("user", message.content)
state = {"full_response": ""}
def on_token(token):
state["full_response"] += token
result = llm_client.stream_generate(messages, on_token)
messages.append({"role": "assistant", "content": result["text"]})
llm_client.log_interaction("assistant", result["text"])
await cl.Message(content=result["text"]).send()
通过以下命令在localhost:8000(注意端口不同)启动应用程序:
chainlit run cl_app_basic.py
为了进行比较,将运行与之前相同的两个提示。结果如下图3和图4所示:
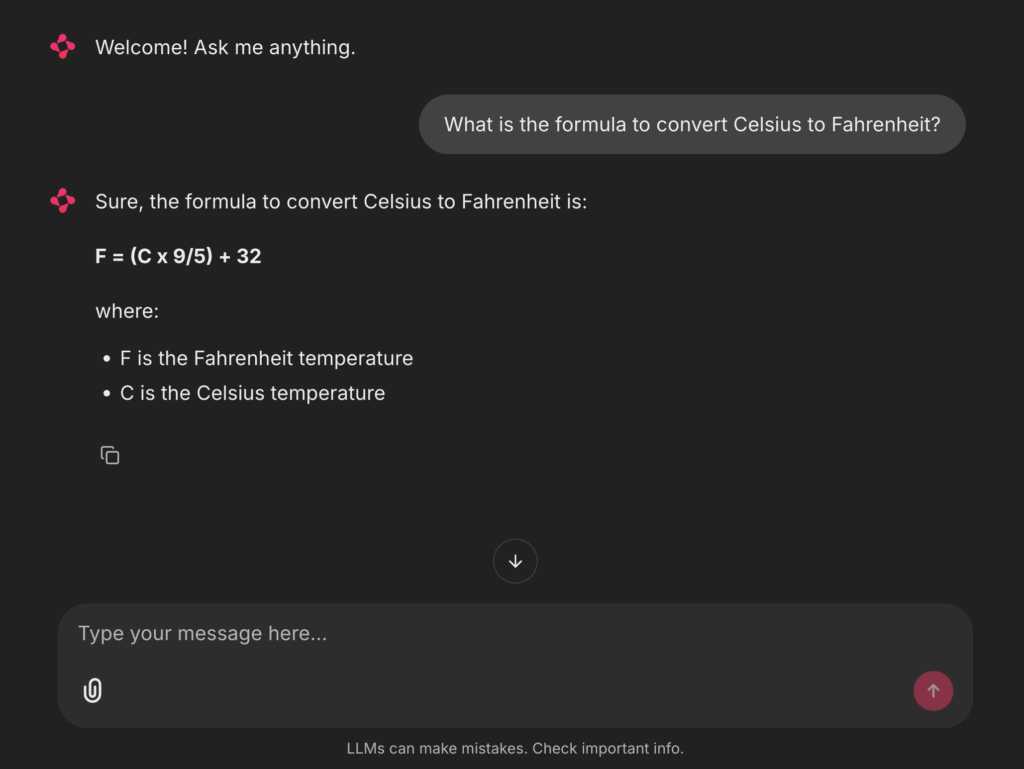
图3:Chainlit初始问答界面
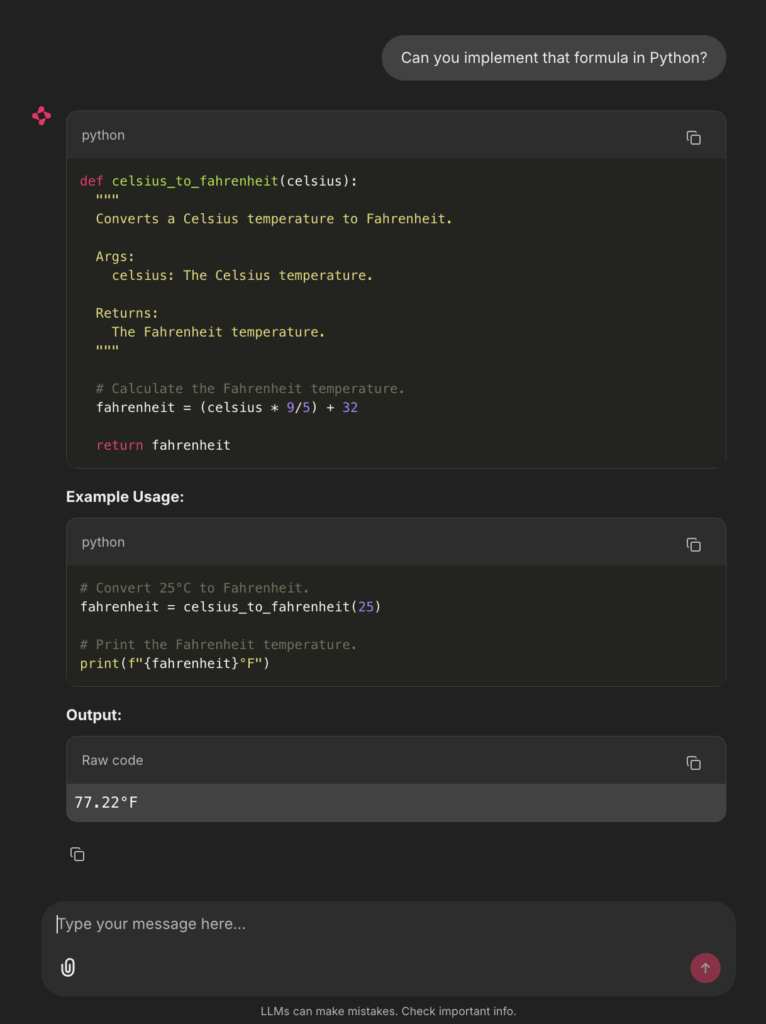
图4:Chainlit后续问答界面
与之前一样,在尝试更多提示后,通过在终端中执行Control + c来关闭应用程序。
Streamlit高级演示
现在,将扩展基础Streamlit演示,增加一个左侧的持久侧边栏,其中包含一个用于切换LLM温度参数的滑块小部件、一个用于下载聊天历史的按钮,以及每个聊天机器人回复下方的反馈按钮(“有帮助”、“无帮助”)。在Streamlit中,自定义应用程序布局和添加全局小部件相对容易,但在Chainlit中复制这些功能可能较为繁琐——感兴趣的读者可以尝试复现,亲身体验其中的挑战。
以下是扩展后的Streamlit应用程序,保存在名为st_app_advanced.py的文件中:
import streamlit as st
from llm_client import LLMClient
import json
MAX_HISTORY = 5
llm_client = LLMClient(provider="ollama", model="gemma:2b")
st.set_page_config(page_title="Streamlit Advanced Chatbot", layout="wide")
st.title("Streamlit Advanced Chatbot")
# Sidebar controls
st.sidebar.header("Model Settings")
temperature = st.sidebar.slider("Temperature", 0.0, 1.0, 0.2, 0.1) # min, max, default, increment size
st.sidebar.download_button(
"Download Chat History",
data=json.dumps(st.session_state.get("messages", []), indent=2),
file_name="chat_history.json",
mime="application/json"
)
if "messages" not in st.session_state:
st.session_state.messages = []
# Display chat history
for msg in st.session_state.messages:
with st.chat_message(msg["role"]):
st.markdown(msg["content"])
# User input
if prompt := st.chat_input("Type your message..."):
st.session_state.messages.append({"role": "user", "content": prompt})
st.session_state.messages = st.session_state.messages[-MAX_HISTORY:]
llm_client.log_interaction("user", prompt)
with st.chat_message("assistant"):
response_container = st.empty()
state = {"full_response": ""}
def on_token(token):
state["full_response"] += token
response_container.markdown(state["full_response"])
result = llm_client.stream_generate(
st.session_state.messages,
on_token,
temperature=temperature
)
llm_client.log_interaction("assistant", result["text"])
st.session_state.messages.append({"role": "assistant", "content": result["text"]})
# Feedback buttons
col1, col2 = st.columns(2)
if col1.button("Helpful"):
llm_client.record_feedback({"rating": "up", "comment": "User liked the answer"})
if col2.button("Not Helpful"):
llm_client.record_feedback({"rating": "down", "comment": "User disliked the answer"})
图5显示了一个示例截图:
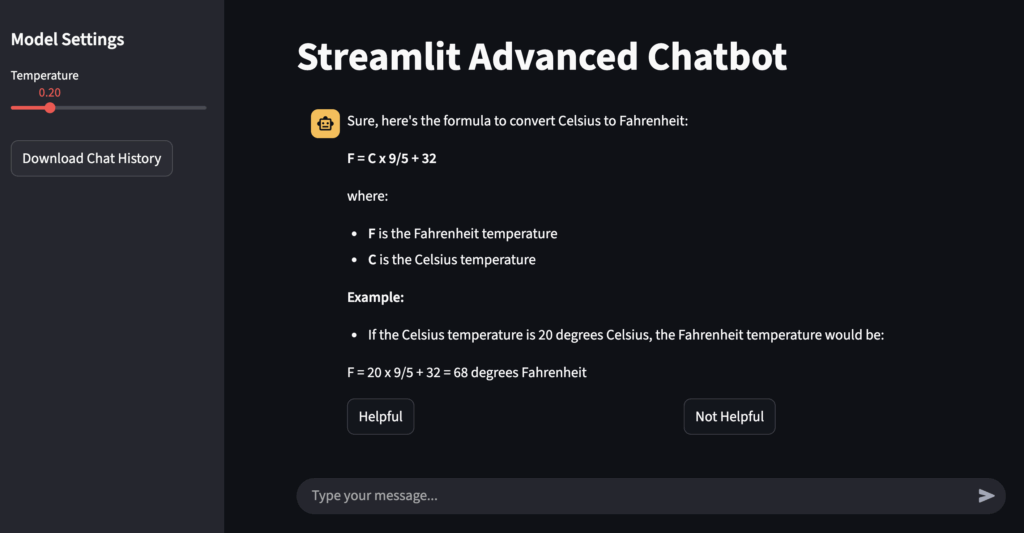
图5:Streamlit高级功能演示
Chainlit高级演示
接下来,将扩展基础Chainlit演示,增加每个消息的交互式操作和多模态输入处理(本文中为文本和图像)。Chainlit框架的“聊天原生”原语使得实现这些类型的功能比在Streamlit中更容易。同样,鼓励感兴趣的读者尝试使用Streamlit复制这些功能,以体验其中的差异。
以下是扩展后的Chainlit应用程序,保存在名为cl_app_advanced.py的文件中:
import os
import json
from typing import List, Dict
import chainlit as cl
from llm_client import LLMClient
MAX_HISTORY = 5
DEFAULT_TEMPERATURE = 0.2
SESSIONS_DIR = os.path.join(os.path.dirname(__file__), "sessions")
os.makedirs(SESSIONS_DIR, exist_ok=True)
llm_client = LLMClient(provider="ollama", model="gemma:2b", temperature=DEFAULT_TEMPERATURE)
def _session_file(session_name: str) -> str:
safe = "".join(c for c in session_name if c.isalnum() or c in ("-", "_"))
return os.path.join(SESSIONS_DIR, f"{safe or 'default'}.json")
def _save_session(session_name: str, messages: List[Dict]):
with open(_session_file(session_name), "w", encoding="utf-8") as f:
json.dump(messages, f, ensure_ascii=False, indent=2)
def _load_session(session_name: str) -> List[Dict]:
path = _session_file(session_name)
if os.path.exists(path):
with open(path, "r", encoding="utf-8") as f:
return json.load(f)
return []
@cl.on_chat_start
async def start():
cl.user_session.set("messages", [])
cl.user_session.set("session_name", "default")
cl.user_session.set("last_assistant_idx", None)
await cl.Message(
content=(
"欢迎!有任何问题都可以问我。"
),
actions=[
cl.Action(name="set_session_name", label="设置会话名称", payload={"turn": None}),
cl.Action(name="save_session", label="保存会话", payload={"turn": "save"}),
cl.Action(name="load_session", label="加载会话", payload={"turn": "load"}),
],
).send()
@cl.action_callback("set_session_name")
async def set_session_name(action):
await cl.Message(content="请键入:/name 您的会话名称").send()
@cl.action_callback("save_session")
async def save_session(action):
session_name = cl.user_session.get("session_name")
_save_session(session_name, cl.user_session.get("messages", []))
await cl.Message(content=f"会话已保存为 '{session_name}'。").send()
@cl.action_callback("load_session")
async def load_session(action):
session_name = cl.user_session.get("session_name")
loaded = _load_session(session_name)
cl.user_session.set("messages", loaded[-MAX_HISTORY:])
await cl.Message(content=f"已加载会话 '{session_name}',包含 {len(loaded)} 轮对话。 ").send()
@cl.on_message
async def main(message: cl.Message):
if message.content.strip().startswith("/name "):
new_name = message.content.strip()[6:].strip() or "default"
cl.user_session.set("session_name", new_name)
await cl.Message(content=f"会话名称已设置为 '{new_name}'。").send()
return
messages = cl.user_session.get("messages")
user_text = message.content or ""
if message.elements:
for element in message.elements:
if getattr(element, "mime", "").startswith("image/"):
user_text += f" [图片:{element.name}]"
messages.append({"role": "user", "content": user_text})
messages[:] = messages[-MAX_HISTORY:]
llm_client.log_interaction("user", user_text)
state = {"full_response": ""}
msg = cl.Message(content="")
def on_token(token: str):
state["full_response"] += token
cl.run_sync(msg.stream_token(token))
result = llm_client.stream_generate(messages, on_token, temperature=DEFAULT_TEMPERATURE)
messages.append({"role": "assistant", "content": result["text"]})
llm_client.log_interaction("assistant", result["text"])
msg.content = state["full_response"]
await msg.send()
turn_idx = len(messages) - 1
cl.user_session.set("last_assistant_idx", turn_idx)
await cl.Message(
content="这有帮助吗?",
actions=[
cl.Action(name="thumbs_up", label="是", payload={"turn": turn_idx}),
cl.Action(name="thumbs_down", label="否", payload={"turn": turn_idx}),
cl.Action(name="save_session", label="保存会话", payload={"turn": "save"}),
],
).send()
@cl.action_callback("thumbs_up")
async def thumbs_up(action):
turn = action.payload.get("turn")
llm_client.record_feedback({"rating": "up", "turn": turn})
await cl.Message(content="感谢您的反馈!").send()
@cl.action_callback("thumbs_down")
async def thumbs_down(action):
turn = action.payload.get("turn")
llm_client.record_feedback({"rating": "down", "turn": turn})
await cl.Message(content="感谢您的反馈。").send()
图6显示了一个示例截图:
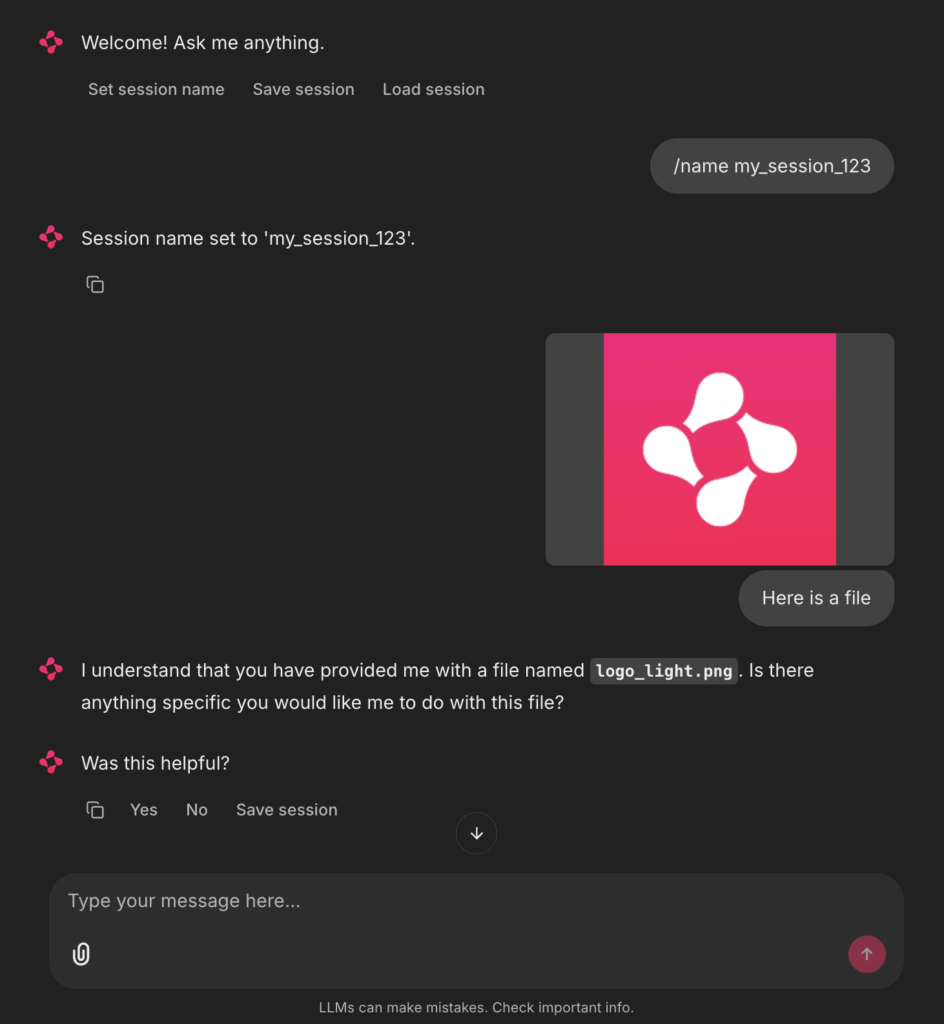
图6:Chainlit高级功能演示
实用指南
正如前文所示,Streamlit和Chainlit都可以快速构建简单的聊天机器人应用程序。在实现的基础演示中,存在一些架构上的相似之处:对Ollama的调用和对话日志记录通过LLMClient类进行了抽象,上下文大小通过一个名为MAX_HISTORY的常量变量进行限制,并且历史记录被序列化为纯文本聊天格式。然而,高级演示表明,每个框架的范围有所不同,这根据用例带来了特定的优缺点以及相关的实用建议。
Streamlit是一个用于以数据为中心的交互式Web应用程序的通用框架,而Chainlit则专注于构建和部署会话式AI应用程序。因此,如果聊天机器人在原型中是核心组件,使用Chainlit可能更具意义;正如上述代码示例所示,Chainlit处理了多个样板操作细节(例如,内置的聊天功能支持原生打字指示器、消息流式传输和Markdown/代码渲染)。但如果聊天机器人嵌入在更大的AI产品中,Streamlit可能能更好地应对更大的应用程序范围(例如,将聊天界面与数据可视化、仪表板、全局小部件和自定义布局相结合)。
此外,AI应用程序中的对话元素可能需要以异步方式处理,以确保良好的用户体验(UX),因为消息可以随时到达,并且需要在其他任务(例如,调用另一个API或流式传输模型输出)可能正在进行时快速处理。Chainlit利用Python的async和await关键字,可以轻松地进行异步聊天逻辑原型开发,确保应用程序能够处理并发操作而不会阻塞UI。该框架处理了管理WebSocket连接和自定义轮询的底层细节,因此每当触发事件(例如,消息发送、令牌流式传输、状态改变)时,Chainlit的事件处理逻辑会自动触发所需的UI更新。相比之下,Streamlit使用同步通信,这导致应用程序脚本在每次用户交互时重新运行;对于需要处理多个并发进程的复杂应用程序,Chainlit可能比Streamlit提供更流畅的用户体验。