

构建于知识库之上的检索式聊天机器人,以其可靠性、事实准确性以及规避生成式模型幻觉的优势,在处理直接、独立的查询时表现出色。然而,一旦用户尝试进行自然、对话式的追问,例如“我该怎么做?”,“在德国呢?”,这类系统便会力不从心。
症结何在?在于典型的检索机制将每个查询都视为独立的个体,在搜索语义匹配时完全忽略了对话的上下文。尽管这种方法在单轮交互中表现卓越,但当用户期望现代对话式AI所具备的流畅、连贯的上下文对话时,它便会失效。
如果能赋予机器人“记忆”功能,又会如何?本文是探讨赋能虚拟智能聊天助手(VICA)的生成式AI创新系列文章的第二部分。VICA是一个对话式AI平台,旨在帮助政府机构快速响应公民查询,同时通过内容护栏和定制响应严格控制内容,最大限度地减少幻觉。在第一篇文章中,深入探讨了LLM代理如何支持聊天机器人中的对话式事务。现在,将焦点转向另一项关键创新:在无状态问答系统中实现自然的多轮对话。
目录
检索式问答机器人的结构剖析
从核心来看,检索式问答聊天机器人基于一个精妙而简单的前提:将用户问题与预定义答案进行匹配。这种方法巧妙地规避了生成式AI的不可预测性,能够提供基于验证内容的快速、准确响应。以下是其组成部分的详细剖析:
知识库。一切都始于一个精心策划的问题与答案对(Q&A)集合,它构成了系统的知识库。每个问题及其对应的答案都由人类专家撰写和审核,确保其准确性、语气和合规性。这种“人工参与”的方法意味着机器人始终只引用可信、预批准的脚本,从而消除了其偏离主题或提供不正确信息的风险。
语义理解层。当这些问题和答案被转化为向量嵌入时,奇迹便随之发生。向量嵌入是高维空间中捕捉语义密度的数值表示。这种转换至关重要,因为它使系统能够理解“我如何获得补贴资格?”和“申请补贴的标准是什么?”这两个问题,尽管措辞不同,但本质上是在询问同一件事。
检索引擎。这些嵌入随后会被索引到经过相似性搜索优化的向量数据库中(例如 Pinecone)。当用户提问时,系统会将查询转换为向量,并执行最近邻搜索,利用余弦相似度或点积等指标找到语义上最相似的匹配项,对潜在匹配进行排名并选择最相关的一个。
响应交付。找到匹配项后,系统便会简单地检索相应的预编写答案。其中不涉及生成、不依赖创造力,也没有编造信息的风险,只是提供经过验证的、人工撰写的内容。
其优势引人注目:保证准确性、闪电般的响应速度以及完全的内容控制。然而,当用户尝试进行实际对话时,一个显而易见的弊端便会浮现。
对话中断:上下文丢失的症结
正是在这一点上,检索系统遭遇了瓶颈。当用户期望进行自然对话时,其无状态架构便暴露了致命弱点:它将每个查询都视为首次提出,完全不顾之前的交流。

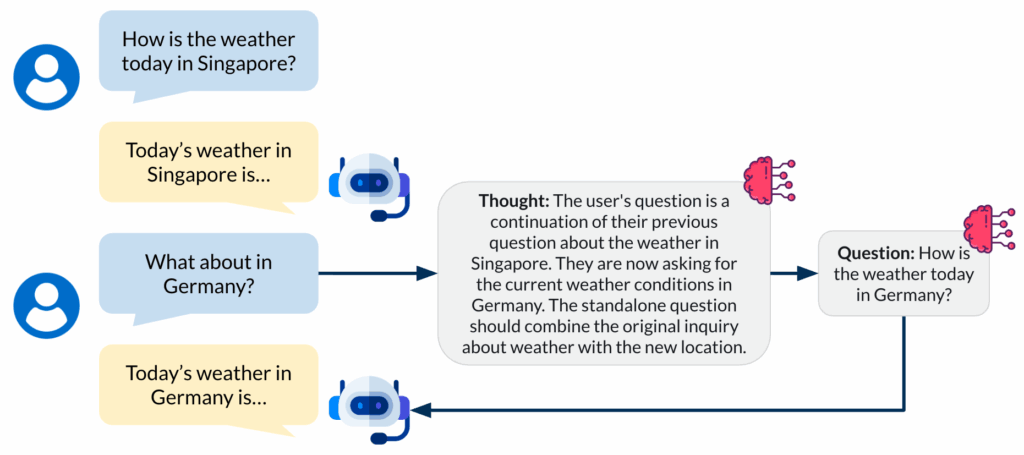
上图示例清晰地展示了这种局限性。机器人完美地处理了最初的问题,检索到今天天气情况的准确信息。然而,当用户提出一个自然的追问“在德国呢?”时,系统便彻底崩溃了。
追问“在德国呢?”在知识库中无法找到任何有意义的匹配项,因为它缺乏前一次对话中“今天天气”的上下文。这是无状态设计的必然结果。
结果是,用户被迫放弃自然的对话模式,转而在每个问题中重复完整的上下文,例如,不得不问“今天德国的天气怎么样?”而不是更直观的“在德国呢?”。这种摩擦将本应是一次有益的对话,变成了一场令人沮丧的“二十问”游戏,每次都必须从头开始。
解决方案:利用LLM进行查询重写
解决方案是引入一个独立的、轻量级LLM(大型语言模型)作为查询重写器。该LLM会拦截用户查询,并在必要时,将模糊的、对话式的追问重写成检索系统能够理解的具体、独立的查询。
这在用户输入和向量搜索之间引入了一个预处理层。其工作原理如下:
对话记忆。系统现在会维护一个包含最近对话轮次的滚动窗口,通常是最近3-5次交流,以在上下文丰富性和处理效率之间取得平衡。
分析并酌情重写。当收到新的查询时,LLM会同时审查当前问题和对话历史,以判断是否需要重写。像“今天新加坡的天气怎么样?”这样的独立问题会直接通过,而“在德国呢?”之类的追问则会触发重写过程。随后,经过重写且富含上下文的查询,例如“今天德国的天气怎么样?”,会照常传递给向量数据库。
回退(可选)。如果重写的查询未能找到良好的匹配项,系统可以选择回退,使用原始用户查询进行搜索,从而确保系统的健壮性。
结论
从“失忆”到“智能”的转变,并不需要彻底重建整个聊天机器人架构。通过引入基于LLM的查询重写技术,赋予了检索式聊天机器人一直缺失的关键要素:对话记忆。这种将LLM作为智能查询重写器嵌入的混合方法,使聊天机器人能够处理自然的多轮对话,同时保留了检索式聊天机器人所具备的内容控制优势。最终呈现的聊天机器人,不仅能为用户带来真实的对话体验,而且依然基于经过验证的人工撰写响应。有时,最强大的解决方案并非颠覆性的全面改革,而是针对关键缺失环节进行的深思熟虑的增强,从而实现整体的蜕变。





