

商店的商品组合是向顾客销售的完整多样的产品系列。它会根据各种因素进行演变,例如:经济状况、消费趋势、盈利能力、质量或合规问题、某些产品系列的更新、库存水平、季节性变化等。当某一商品不再上架时,其部分销售额可能会转移到其他商品上。对于像家乐福这样的大型食品零售商而言,准确估算这种销量转移至关重要,这有助于管理因商品缺货造成的损失风险,并初步估算实际损失。
这项衡量指标可以作为评估商品缺货后果的有效参考。此外,它还能逐步建立起一份宝贵的销量转移影响估算历史数据。
然而,估算销量转移是复杂的。顾客行为(受难以预测的情绪因素影响)、某些商品的季节性,以及新产品的引入,都可能影响销量转移。此外,许多商品会同时在所有门店缺货,这使得建立一个对照组变得不可能。
由谷歌团队开发的 Causal Impact 合成控制方法,恰好适用于本分析框架的特殊性。它能将商品缺货对销量的影响从其他影响因素中分离出来,适用于准实验研究和观察性研究。Causal Impact 基于贝叶斯结构时间序列模型,通过反事实分析,计算商品缺货后的销量与通过合成控制预测的、假设商品持续有货情况下的销量之间的差异,从而得出对销量的影响。
本文将介绍 Causal Impact 方法在估算商品缺货后销量转移影响方面的应用,以及选择对照组时间序列的启发式方法。
出于保密考虑,图表中的定量数值已进行编辑。请注意,x 轴上的每个区块代表一个月,y 轴代表一个可变数量,其数值可能相当大。
一) 明确用例
商品缺货主要有两种形式:
- 完全缺货:该商品不再属于全国商品组合,影响所有门店。
- 部分缺货:该商品在部分门店缺货,但在其他门店仍有货。
可靠的销量转移影响估算应能准确评估丢失的销售额和转移到其他产品的销售额比例。然而,要确切了解这些数值是不可能的,这使得这项挑战异常复杂。
本研究主要分析完全缺货的情况,因为这些情况对销售额的影响最为显著。
请注意,因果推断并非未来事件的预测框架:它旨在识别过去事件中的因果关系,而非预测未来。
二) 为何选择谷歌的 Causal Impact 模型?
因果方法旨在理解变量之间的因果关系,通过将所要分析的影响从所有其他现有影响中分离出来,解释一个变量如何影响另一个变量。
在这些工具中,Causal Impact 是一个易于使用的库,它在完全贝叶斯框架下运行,允许整合先验信息,同时在其结果中提供固有的可信区间。它的预测结果代表了如果干预没有发生时预期会发生的情况,以分布函数而非单一数值的形式表达。
Causal Impact 通过将内生成分(如季节性和局部水平)与用户选择的外部时间序列(协变量)相结合来生成预测。这些协变量必须不受干预影响,并且应能捕捉可能影响主要时间序列的趋势或因素。协变量的选择将在后续讨论。

图 1:Causal Impact 工作原理的简化示例。顶部图表显示了两条时间序列:橙色线代表实际观测数据,蓝色线是模型使用协变量和内生成分创建的预测。每个区块代表一个月。此预测估算了如果目标事件(由垂直虚线标记)未发生时会发生什么。蓝色阴影区域表示预测的不确定性。第二个图表显示了预测与观测数据之间的逐点差异,底部图表显示了累积影响。
三) 数据中异常值和异常情况的处理
为确保分析准确性,销售数据异常处理遵循了两个关键步骤:
- 从分析中排除了负销售额或大量零销售额的时间序列。
- 对于偶尔出现零销售额的时间序列,这些数值被替换为前一周和后一周销售额的平均值。
四) 模型设计
协变量的选择显著影响反事实预测的准确性。这些时间序列必须捕捉可能影响目标时间序列的趋势或外部因素,且不受干预影响。
此外,考虑估算的销量转移效应相对于所研究时间序列的大小至关重要:如果预期干预只会对目标序列产生百分之几的影响,该序列可能不适用,因为微小的效应很难与随机噪声区分开来(特别是库的设计者已表明小于 1% 的效应很难证明与干预相关)。因此,仅当理论最大销量转移率超过其子家族销售额的 5% 时,才进行销量转移分析。计算方法为 S/(1-S),其中 S 代表该商品在缺货前在其子家族中产生的销售额百分比。
基于这些初步考量,Causal Impact 模型设计如下:
目标
目标时间序列选择为该商品子家族的销售总额,不包括已缺货的商品。
协变量
首先排除了以下类型的时间序列:
- 与停产商品属于同一子家族的产品,以避免其缺货产生任何影响。
- 与停产商品不属于同一家族的产品,因为协变量应保持业务相关性。
- 显示相关性但与目标序列没有协整关系的时间序列,以避免虚假关系。
使用这些筛选条件,选择了 60 个协变量:
- 其中 20 个协变量是根据其在干预前一年与目标序列的最高协整关系选出的。
- 另外 40 个协变量是从前 200 个协整序列中,根据其在干预前一年与目标序列最强的相关性选出的。
请注意,这些数字(20、40 和 60)是根据先前的模型拟合经验得出的经验法则。
这种经验方法结合了通过协整捕捉长期趋势和通过相关性捕捉短期波动的时间序列。之所以选择大量协变量,是因为 Causal Impact 采用了“尖峰和平板”(spike and slab)方法,该方法会自动通过赋予不重要序列接近零的回归系数来降低其影响,同时赋予重要序列更大的权重。
五) 模型验证
为验证协变量选择策略,参考了 Causal Impact 设计者采用的方法。通过以下方式对部分商品缺货情况进行了研究:
- 检查了商品部分缺货的案例,并使用差中差法进行了初步的传统统计分析。
- 应用 Causal Impact,将商品在有货门店的子家族销售额(不包括缺货商品)作为协变量构成对照组。这些协变量提供了最佳的反事实情况,因为这些门店未受干预影响。
- 最后,在没有对照组的情况下应用 Causal Impact,转而使用“模型设计”部分概述的基于协整和相关性的选择过程。
在多个报告(涵盖不同产品、数量和类别)中获得一致的估算结果,将证明该方法可以更广泛地可靠应用。
此外,还开发了两个指标来评估合成控制的质量:一个拟合度指标和一个预测能力指标。
- 拟合度指标(分数介于 0 到 1 之间)评估合成控制在干预前时期对目标的建模效果。
- 预测能力指标是一种回溯测试形式,用于评估合成控制在过去模拟虚假干预期间的质量。
一个实际验证案例
为通过一个实际案例验证上述过程,分析了某品牌酸奶在部分门店缺货的情况。通过匹配每个商品缺货的门店与一个仍有该商品的类似门店,根据销售业绩、顾客特征和地理位置等标准,建立了处理组和对照组。
该商品的理论最大销量转移率为 9.5%,而之前的分析显示乳制品家族的销量转移率非常高。因此,预期会获得一个接近理论最大值的估算结果。
遵循三步验证方法,获得了以下结果:
- 差中差分析估算的因果效应为 8.7%,概率为 98.7%。
- 如图 2 所示,使用对照组的 Causal Impact 分析估算的因果效应为 9.0%,置信区间为 [3.7%, 14.4%],概率为 99.9%。模型虽然有效追踪了时间序列的波动,但也显示出一些微小偏差。

图 2:乳制品缺货后因果效应估算,使用对照组构建合成控制。
此外,当使用基于协整和相关性选择的协变量而非对照组时,Causal Impact 分析估算的因果效应为 8.5%,置信区间为 [2.4%, 15.1%],概率为 99.9%,如图 3 所示。同样,模型有效追踪了时间序列的波动,但也显示出一些微小偏差。
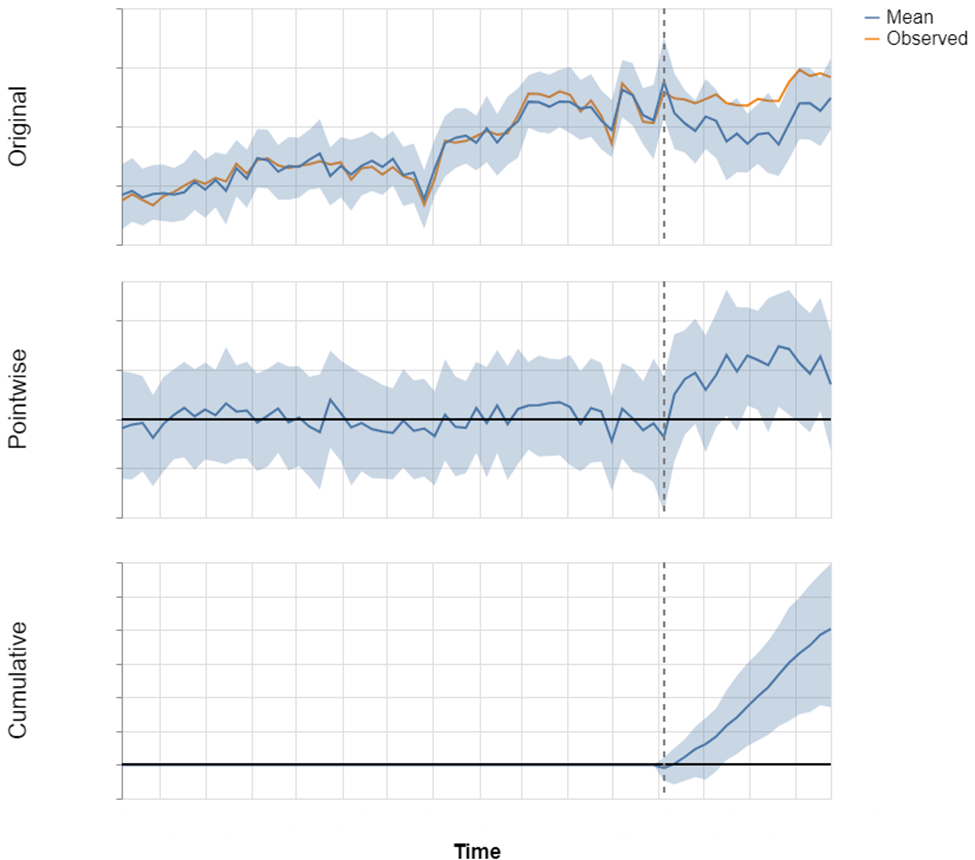
图 3:乳制品缺货后因果效应估算,使用代理数据(仅来自处理组门店的数据构成合成控制)。
以下是三种不同分析方法获得估算结果的汇总:
分析效应估算因果效应概率
差中差 8.7% 98.7% (显著)
带对照组的 Causal Impact 9.0% CI: [3.7%, 14.4%] 99.9% (显著)
不带对照组信息的 Causal Impact 8.5% CI: [2.4, 15.1%] 99.1% (显著)
这表明,无论是否使用对照组,估算结果在量级上保持一致,从而验证了在没有对照组可用时协变量的选择过程。
六) 完全缺货:某品牌大米不再可用
分析了一个全国性的案例,某品牌袋装大米缺货。为了避免捕获在较长时间内可能出现的无关效应,分析范围仅限于产品缺货后的几个月。该产品的理论最大销量转移率为 31.2%。应用了前面描述的协变量选择方法来估算潜在的销量转移效应。
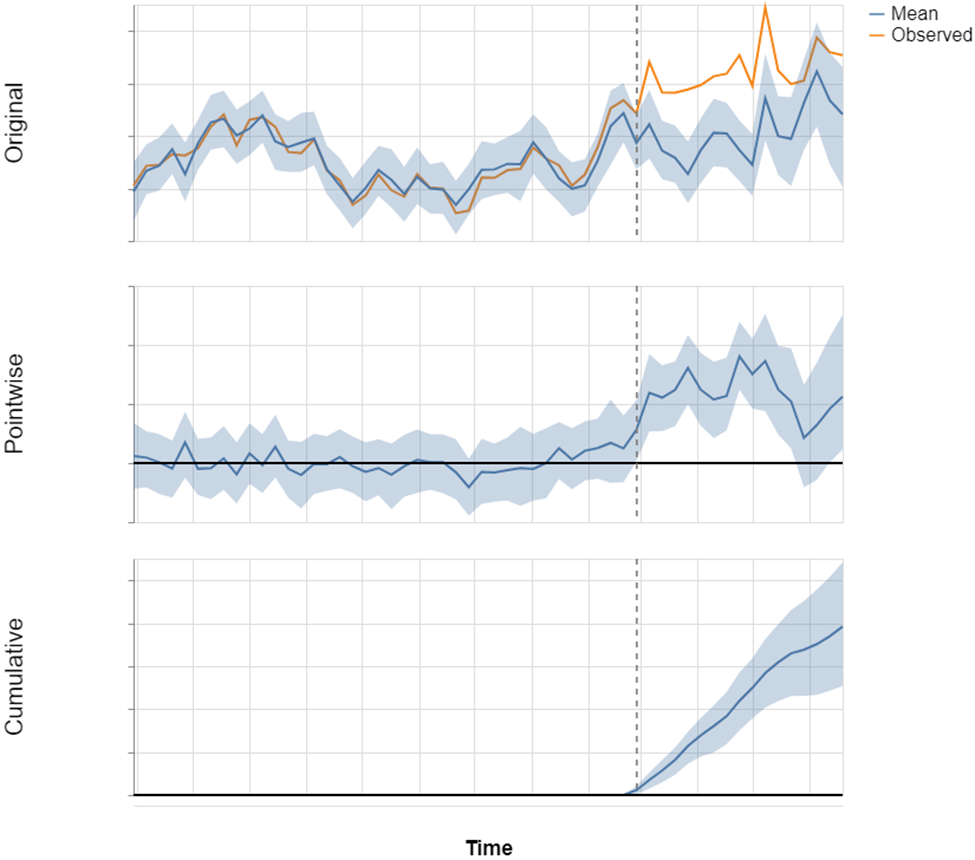
图 4:某品牌袋装大米缺货后因果效应估算,使用代理数据(仅来自处理组门店的数据构成合成控制)。
如图 4 所示,合成控制在干预前很好地模拟了目标。预测准确捕捉了干预后的季节性趋势。可信区间在估算值附近非常窄。
获得了统计上显著的估算结果,即在产品缺货后的几个月内,销售额增长了 22%,概率超过 99.9%。这个数量大约占该品牌大米缺货前总销售额的 70%,这意味着该品牌大米有 30% 的销售额未能转移。
七) 使用建议与经验报告
Causal Impact 是一种强大且易于使用的因果推断工具。然而,在投入大量时间指定模型并提高其准确性之后,在将其微调以获得可工业化解决方案时,也遇到了一些挑战。
- 首先要强调的是“垃圾进,垃圾出”原则的重要性,这在使用 Causal Impact 时尤为相关。无论使用何种协变量,Causal Impact 总是会产生一个结果,有时概率很高,即使在结果不切实际或不可能的情况下也是如此。
- 仅基于协整标准选择的时间序列有时在模型特征重要性中会超越其他序列,这在调整控制不当时会大幅降低估算准确性。
- 选择 20 个协整序列和 40 个相关序列是一个经验法则。尽管在遇到的大多数案例中都有效,但它可能还需要进一步完善。
结论
本文提出了一种使用 Causal Impact 估算产品缺货时销量转移效应的因果方法。概述了选择可分析产品和协变量的方法。
尽管这种方法在大多数情况下功能强大且稳健,但它仍存在局限性和改进空间。其中一些是结构性的,另一些则需要花费更多时间进行模型调整。





