

在混淆矩阵的讨论中,曾使用逻辑回归算法对威斯康星乳腺癌数据集进行分类,以判断肿瘤是恶性还是良性。
当时,分类模型是利用准确率、精确率等多种指标进行评估的。
对于二分类模型,存在另一种重要的模型评估方法,即 ROC AUC。
本文将深入探讨为何需要引入这一额外指标,以及何时应优先采用它。
为详细解析 ROC AUC,将以 IBM HR Analytics 数据集为例进行分析。
该数据集包含了 1470 名员工的详细信息,例如年龄、职位、性别、月收入、工作满意度等。
共有 34 个特征用于描述每位员工。
此外,数据集中还包含一个目标列 “Attrition”(员工流失),其中 “Yes” 表示员工已离职,而 “No” 则表示员工仍在职。
接下来,审视一下目标列的类别分布情况。
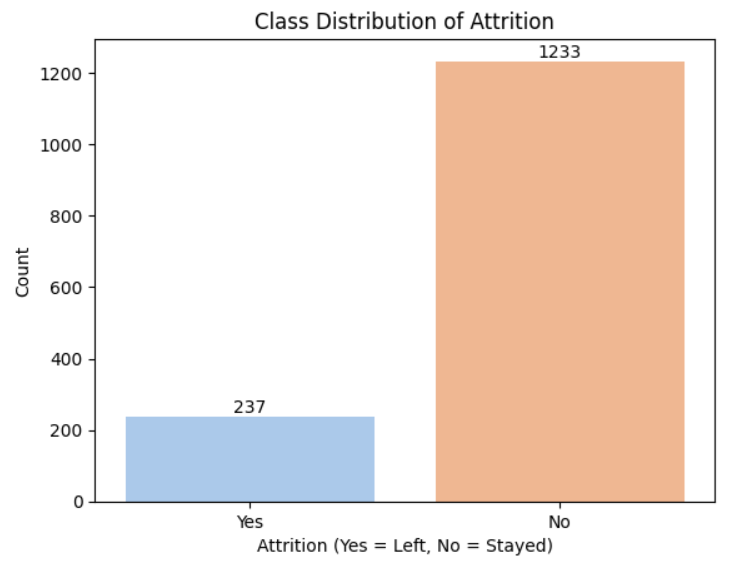
图片来源:作者
从上述类别分布图中可以明显看出,该数据集存在严重的类别不平衡问题。
基于这些数据,需要构建一个模型,用于预测员工是否会留在公司。
由于这是一项二分类(是/否)任务,此处将选用逻辑回归算法对数据进行处理。
代码示例:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, classification_report
# Load the dataset
df = pd.read_csv("C:/HR-Employee-Attrition.csv")
# Drop non-informative columns
df.drop(['EmployeeNumber', 'Over18', 'EmployeeCount', 'StandardHours'], axis=1, inplace=True)
# Encode the target column
df['Attrition'] = df['Attrition'].map({'Yes': 1, 'No': 0})
# One-hot encode categorical features
df = pd.get_dummies(df, drop_first=True)
# Split features and target
X = df.drop('Attrition', axis=1)
y = df['Attrition']
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
# Feature scaling
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Train logistic regression model
model = LogisticRegression(max_iter=1000)
model.fit(X_train_scaled, y_train)
# Predict on test data
y_pred = model.predict(X_test_scaled)
# Predict probabilities for the positive class
y_prob = model.predict_proba(X_test_scaled)[:, 1]
# Confusion matrix and classification report
conf_matrix = confusion_matrix(y_test, y_pred)
report = classification_report(y_test, y_pred)
# Display results
print("Confusion Matrix:
", conf_matrix)
print("
Classification Report:
", report)
混淆矩阵与分类报告
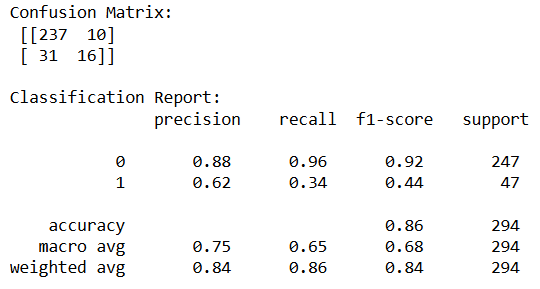
图片来源:作者
从上述分类报告中可以看出,模型的准确率为 86%。然而,对于类别 “1”(表示员工离职,即 Attrition = Yes)的召回率却仅为 0.34,这意味着模型只正确识别出了 34% 的离职员工。
相反,对于类别 “0”(表示员工在职,即 Attrition = No)的召回率高达 0.96,表明模型能够正确识别 96% 的在职员工。
这种现象正是由数据集不平衡所导致的。在这种情况下,仅仅依靠准确率进行评估可能具有误导性。
这是否意味着需要更换模型算法呢?答案是否定的。
真正需要改变的是模型评估的方式,而评估不平衡数据集上的分类模型时,最佳方法正是采用 ROC AUC。
既然已知 ROC AUC 是评估分类模型的另一种有效方法,那么在深入探讨 ROC AUC 之前,有必要回顾一下目前为止所进行的操作。
在 IBM HR 数据集上应用逻辑回归后,模型为每位员工生成了一个概率分数,该分数表示员工离职的可能性。
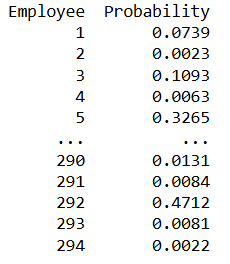
图片来源:作者
在生成混淆矩阵和分类报告时,它们通常基于一个默认阈值,即 0.5。
如果预测概率大于 0.5,员工则被判定为离职;反之,如果概率小于 0.5,则被判定为仍在职。
基于此,模型取得了 86% 的准确率,但召回率仅为 34%。可见,准确率在这里具有误导性,因此决定采用 ROC AUC 来评估模型性能。
ROC AUC 详解
首先,深入探讨接收者操作特征(Receiver Operating Characteristic, ROC)曲线。
ROC 曲线是通过绘制真阳性率(True Positive Rate, TPR)与假阳性率(False Positive Rate, FPR)之间的关系而得到的。
分类报告是基于单一阈值生成的,这一点已有所了解。然而,ROC 曲线的生成原理则不同:它通过计算所有可能阈值下的真阳性率(TPR)和假阳性率(FPR),然后将这些点绘制出来。
接下来,通过一个示例数据集,了解如何从中生成 ROC 曲线。
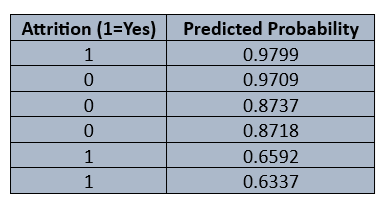
图片来源:作者
对于上述数据,将计算在所有可能阈值下的 TPR 和 FPR,然后绘制出相应的曲线。
什么是“可能阈值”?
为了生成 ROC 曲线,并非需要在 0 到 1 之间的每个数值点上都计算 TPR 和 FPR。
相反地,通常会使用数据集中所有独特的预测概率值作为阈值,并在最大预测概率之上额外添加一个值(此时所有预测都为负,曲线从 (0,0) 开始),在最小预测概率之下再添加一个值(此时所有预测都为正,曲线终止于 (1,1))。
为何不将 0 到 1 之间的每个数值都作为阈值?
以示例数据为例,其中有一个预测概率为 0.6592。如果将其作为阈值来计算 TPR 和 FPR。
在 0.6592 和 0.8718 之间,TPR 和 FPR 的值将保持不变,它们只会在阈值跨越某个预测概率值时发生变化。
这正是为何采用独特的预测概率值作为阈值来生成 ROC 曲线的原因。
基于示例数据,接下来生成 ROC 曲线,并观察其呈现出的特征。
为了生成 ROC 曲线,需要计算 TPR 和 FPR。
真阳性率 (TPR) = 真阳性 (TP) / (真阳性 (TP) + 假阴性 (FN))
真阳性率(TPR)也常被称为召回率(Recall)。
假阳性率 (FPR) = 假阳性 (FP) / (假阳性 (FP) + 真阴性 (TN))
对于此示例数据,用于计算 TPR 和 FPR 的阈值集合为 {1, 0.9799, 0.9709, 0.8737, 0.8718, 0.6592, 0.6337, 0}。
接下来,计算每个阈值下的 TPR 和 FPR。
在阈值 0.9799 处:
真阳性 (TP) = 1,假阴性 (FN) = 2
假阳性 (FP) = 0,真阴性 (TN) = 3
TPR = TP / (TP + FN) = 1 / (1 + 2) = 1 / 3 ≈ 0.33
FPR = FP / (FP + TN) = 0 / (0 + 3) = 0
⇒ (FPR, TPR) = (0, 0.33)
按照这种方式,可以计算出每个阈值下的 TPR 和 FPR。
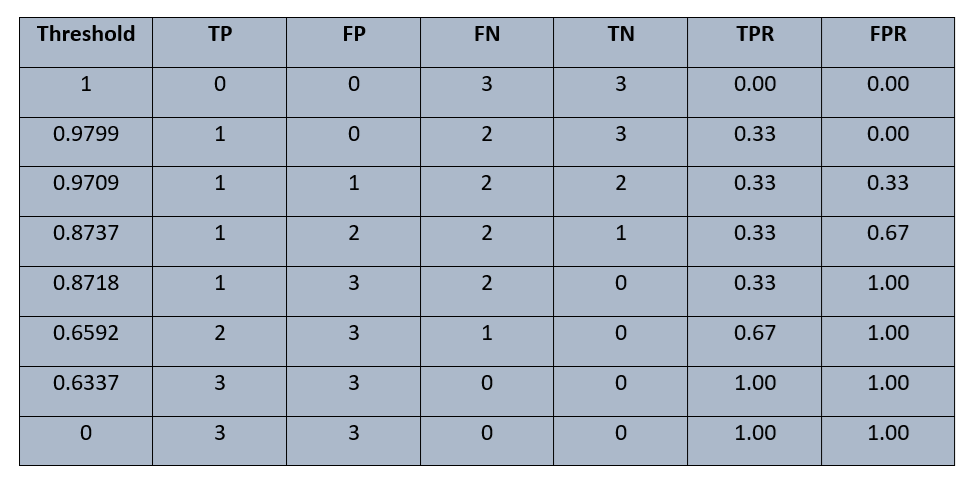
图片来源:作者
接着,绘制 TPR 与 FPR 的关系图,从而得到 ROC 曲线。
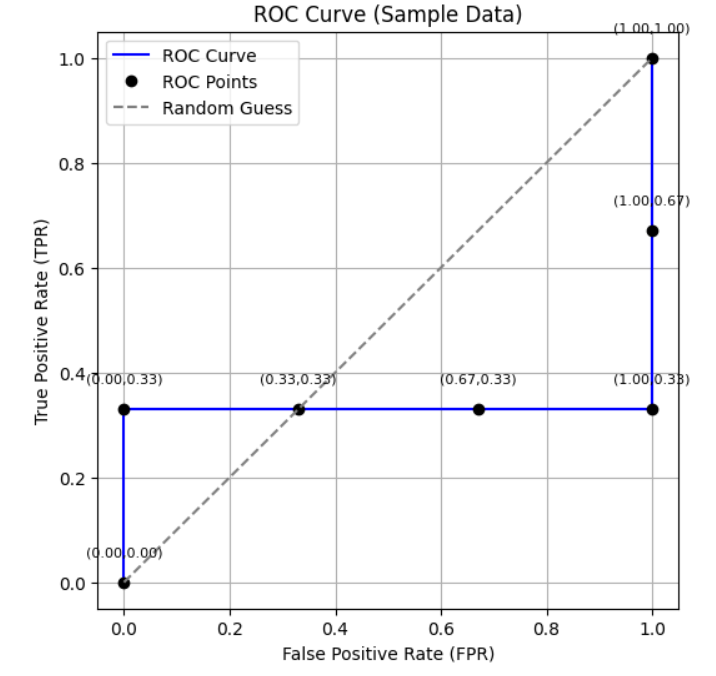
图片来源:作者
这就是 ROC 曲线的生成过程。由于仅使用了 6 个点的样本数据,曲线的观察和解释可能不够直观。这里的核心目标是理解 ROC 曲线的生成机制。
接下来需要解读 ROC 曲线,为此将使用 Python 在实际数据集上生成 ROC 曲线。
代码示例:
# Compute ROC curve and AUC
fpr, tpr, thresholds = roc_curve(y_test, y_prob)
roc_auc = auc(fpr, tpr)
# Print AUC
print(f"AUC: {roc_auc:.2f}")
# Plot ROC curve
plt.figure(figsize=(6,6))
plt.plot(fpr, tpr, label=f"ROC curve (AUC = {roc_auc:.2f})", linewidth=2)
plt.plot([0,1], [0,1], 'k--', label="Random guess (AUC = 0.5)")
plt.xlim([0,1])
plt.ylim([0,1.05])
plt.xlabel("False Positive Rate (FPR)")
plt.ylabel("True Positive Rate (TPR)")
plt.title("ROC Curve - Logistic Regression (HR Dataset)")
plt.legend(loc="lower right")
plt.grid(True)
plt.show()
图示:
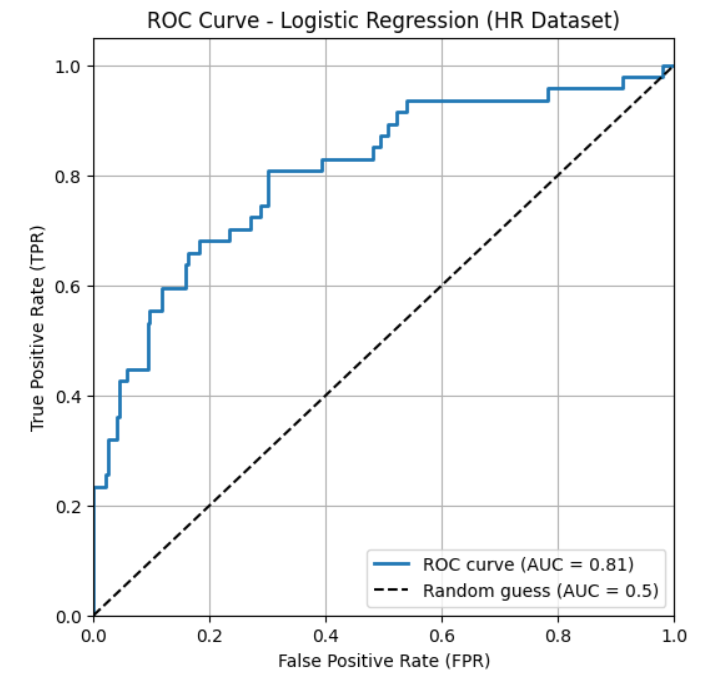
图片来源:作者
暂且不论 AUC(将在稍后讨论),仅从 ROC 曲线本身可以解读出什么信息?
在上图中,Y 轴代表真阳性率(TPR),即模型正确识别出的实际正例数量;X 轴代表假阳性率(FPR),即模型错误地将多少负例识别为正例。
通过 ROC 曲线,可以观察模型在不同阈值下的表现。理想情况下,期望真阳性率尽可能高,同时假阳性率尽可能低,这意味着 ROC 曲线应尽可能地向图表的左上方弯曲。
如果曲线接近或沿着对角线,则表明模型基本上是在进行随机猜测,其性能无法令人满意。
如果曲线位于对角线下方,则说明模型的性能非常糟糕。
通过这种方式,可以对模型在不同阈值下的性能有一个全面的了解。
接下来,讨论 曲线下面积(Area Under the Curve, AUC)。
此前已观察到,对于本文所使用的数据,AUC 值约为 0.81。
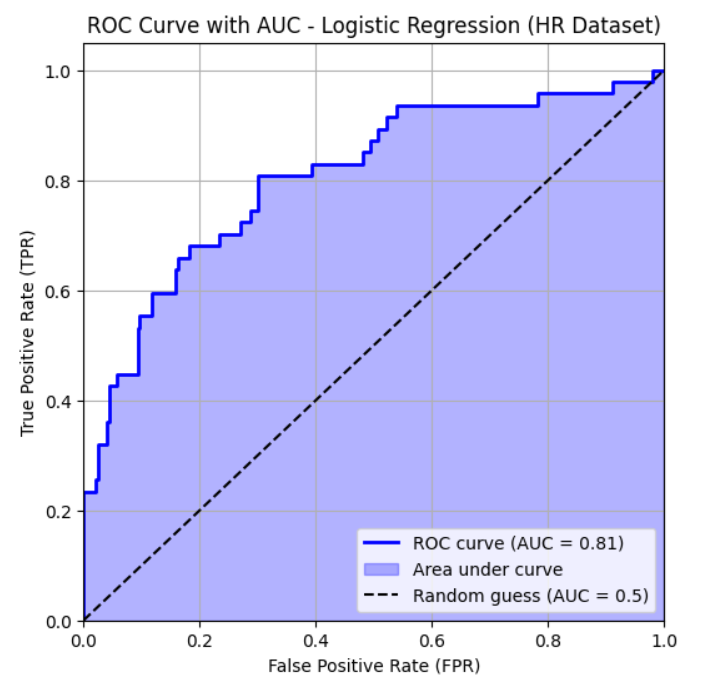
图片来源:作者
AUC 值为 0.81 意味着,如果随机选择一名离职员工和一名在职员工,模型有 81% 的概率会给离职员工分配一个更高的预测概率。
现在,利用示例数据集来理解 AUC 的计算方法。
再次回到之前使用示例数据生成的 ROC 曲线。
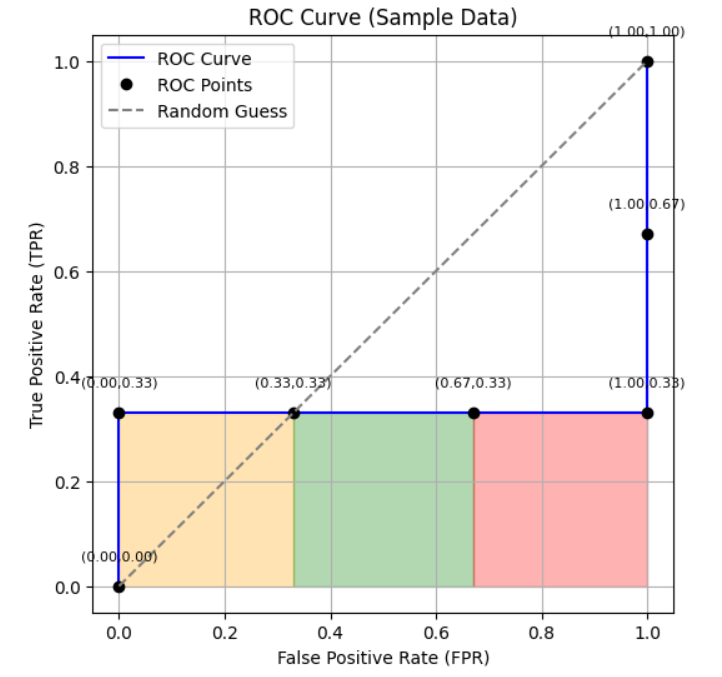
图片来源:作者
上图中阴影区域即代表 AUC。
接下来,进行 AUC 的计算。
从点 (0.00, 0.33) 到 (0.33, 0.33),曲线下方区域由橙色矩形表示。
从点 (0.33, 0.33) 到 (0.67, 0.33),曲线下方区域由绿色矩形表示。
从点 (0.67, 0.33) 到 (1.00, 0.33),曲线下方区域由红色矩形表示。
要计算 AUC,需要计算这些矩形的面积并将它们相加。
橙色矩形面积:长 × 宽 = 0.33 × 0.33 = 0.11
绿色矩形面积:长 × 宽 = 0.34 × 0.33 = 0.11
红色矩形面积:长 × 宽 = 0.33 × 0.33 = 0.11
总 AUC = 0.11 + 0.11 + 0.11 = 0.33
这就是 AUC 的计算方式。
在上述示例中,也可以不将区域细分为逐点分段来计算面积。但在实际应用中,很少会遇到如此简单的 ROC 曲线。
接下来,考虑一个更接近真实情况的 ROC 曲线示例,并计算其 AUC。
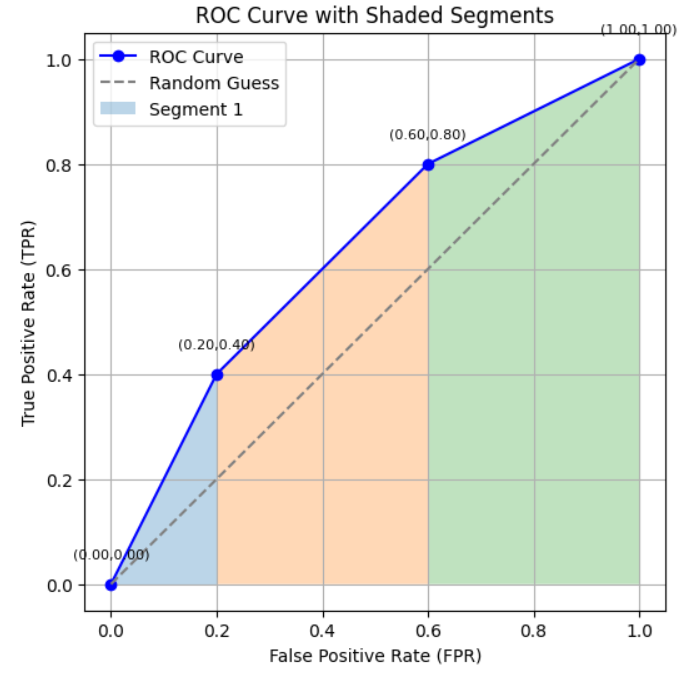
图片来源:作者
现在,计算这条 ROC 曲线的 AUC。
这条曲线包含三个线段。其中两个是梯形,一个看似三角形。然而,通常不会为每种形状使用单独的公式,因为在实际情况中,很少会形成完美的矩形或三角形。
只需统一使用梯形面积公式进行计算。
面积 = 1/2 × (y₁ + y₂) × (x₂ – x₁)
接着,利用此公式计算 AUC。
线段 1: (0.0, 0.0) → (0.2, 0.4) 面积 = 1/2 × (0.0 + 0.4) × (0.2 – 0.0) = 0.04
在此情况下,梯形公式会自动简化为三角形面积公式。
线段 2: (0.2, 0.4) → (0.6, 0.8) 面积 = 1/2 × (0.4 + 0.8) × (0.6 – 0.2) = 0.24
线段 3: (0.6, 0.8) → (1.0, 1.0) 面积 = 1/2 × (0.8 + 1.0) × (1.0 – 0.6) = 0.36
总 AUC = 0.04 + 0.24 + 0.36 = 0.64
这就是 AUC 的计算方法。至此,已经理解了 HR 数据集为何能得到 0.81 的 AUC 值。
AUC 的第二种计算方法
再次回到示例数据集。
图片来源:作者
正例 (1): [0.9799, 0.6592, 0.6337]
负例 (0): [0.9709, 0.8737, 0.8718]
这里共有 9 对正负样本对。
现在,将每个正例与每个负例进行比较,以判断哪个被模型赋予了更高的排名(即预测概率)。
0.9799 (正例) > 0.9709 (负例) ⇒ 正例排名更高
0.9799 (正例) > 0.8737 (负例) ⇒ 正例排名更高
0.9799 (正例) > 0.8718 (负例) ⇒ 正例排名更高
0.6592 (正例) < 0.9709 (负例) ⇒ 正例排名更低
0.6592 (正例) < 0.8737 (负例) ⇒ 正例排名更低
0.6592 (正例) < 0.8718 (负例) ⇒ 正例排名更低
0.6337 (正例) < 0.9709 (负例) ⇒ 正例排名更低
0.6337 (正例) < 0.8737 (负例) ⇒ 正例排名更低
0.6337 (正例) < 0.8718 (负例) ⇒ 正例排名更低
正确排序对数 = 3,总对数 = 9,AUC = 3 / 9 = 0.33
这被称为 AUC 的排序法。
通过两种方法,对示例数据都得到了 0.33 的相同 AUC 值。
可以理解为:
AUC = 正确排序的样本对数 / 总样本对数
因此,AUC 可以被解释为:随机选择一个正例和一个负例,模型将正例的预测概率排序高于负例的概率。
既然已经了解了如何生成 ROC 曲线并计算 AUC,接下来深入探讨 ROC AUC 的重要意义。
在发现准确率具有误导性时,便转向使用 ROC AUC。但可能会有人提出疑问:为何不遍历所有可能的阈值,计算准确率和其他指标,然后直接选择最佳阈值呢?
这种方法确实可行。然而,在比较两个模型时,不能简单地依据各自的最佳阈值进行比较,因为不同模型可能拥有不同的“最佳”阈值。
ROC AUC 提供了一个单一的数值,能够全面概括模型的性能,从而使得不同模型之间能够进行公正、统一的比较。
另一个关键点是,所谓的“最佳阈值”往往取决于所选择的评估指标。
最佳阈值会根据是优化准确率、精确率、召回率还是 F1 分数而变化。相比之下,ROC AUC 是一个与阈值无关的指标,这使其成为衡量模型质量更具通用性的度量标准。
最后,ROC AUC 能够有效捕捉模型的排序能力,这使其在处理不平衡数据集时尤其有用。
数据集来源
本文所使用的 IBM HR Analytics 员工流失数据集 来源于 Kaggle 平台,并采用 CC0(公共领域)许可协议发布,确保了其在分析和发布中的安全使用。
希望本文能为您带来帮助。
欢迎分享您的见解。





