

作曲家们常在不同作品中重复使用特定的音乐主题(即具有鲜明特征的音符进行或旋律片段)。例如,像约翰·威廉姆斯(《超人》、《星球大战》、《哈利·波特》)和汉斯·季默(《盗梦空间》、《星际穿越》、《蝙蝠侠:黑暗骑士》)这样的好莱坞著名作曲家,都会巧妙地重复利用音乐主题,创作出辨识度极高的标志性配乐。
本文将展示如何利用数据科学实现类似的效果。具体而言,将借鉴图论中的欧拉路径概念,通过组装随机生成的音乐主题,创作出悦耳的旋律。在概述理论概念并提供一个经典用例以巩固对基础知识的理解后,文章将详细介绍算法音乐创作过程的端到端Python实现。
注意:以下各节中的所有插图均由本文作者创建。
欧拉路径初探
假设存在一个由节点和边构成的图。在无向图中,节点的度数指的是连接到该节点的边数量。而在有向图中,节点的入度(in-degree)和出度(out-degree)则分别指进入和离开该节点的边数量。欧拉路径被定义为沿着图的节点和边行走,从某个节点开始并在某个节点结束,且每条边都恰好访问一次的路径;如果起始节点和结束节点相同,则称之为欧拉回路。
在无向图中,当且仅当零个或两个节点具有奇数度数,并且所有具有非零度数的节点都属于图中的一个单一连通分量时,欧拉路径才存在。而在有向图中,欧拉路径存在的条件是:至多一个节点(起始节点)的出度比入度多一条边,至多一个节点(结束节点)的入度比出度多一条边,所有其他节点的入度和出度相等,并且所有具有非零入度或出度的节点都属于一个单一连通分量。这些与单一连通分量相关的约束条件确保了图中的所有边都是可达的。
下面的图1和图2分别展示了哥尼斯堡七桥问题和圣诞老人之家谜题的图形表示。这两个都是涉及寻找欧拉路径的著名谜题。
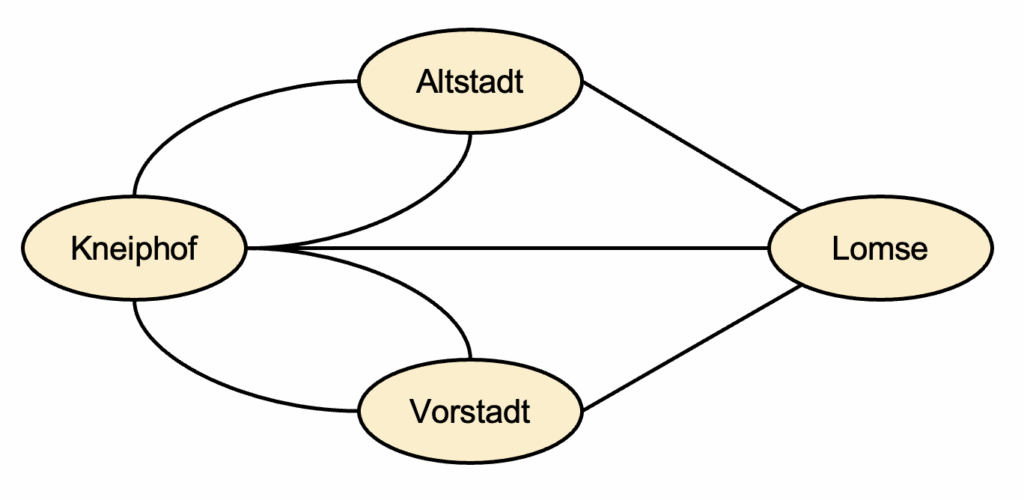
图1:哥尼斯堡问题
在图1中,普鲁士哥尼斯堡市的两座岛屿(克奈普霍夫岛和洛姆泽岛)通过七座桥梁与两块大陆部分(老城和前城)相连。问题是是否存在一种方式,能够访问城市的所有四个部分,并且每座桥都只经过一次;换句话说,需要了解图1所示的无向图是否存在欧拉路径。1736年,著名数学家莱昂哈德·欧拉(欧拉路径和回路因此得名)证明了这个问题不存在这样的路径。根据前面概述的定义,可以理解原因:哥尼斯堡市的所有四个部分(节点)都有奇数数量的桥梁(边),即不满足零个或两个节点具有奇数度数的条件。
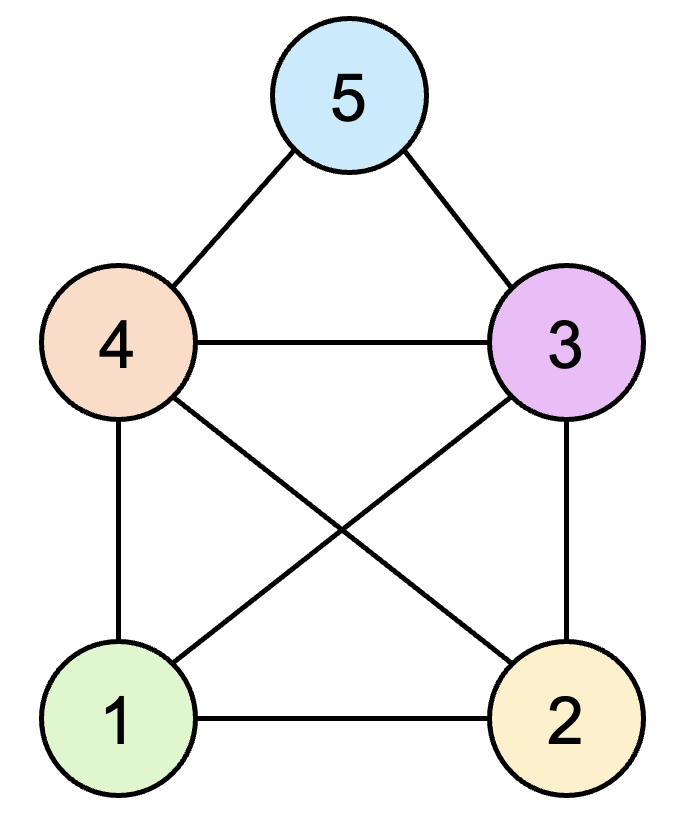
图2:圣诞老人之家谜题
在图2中,目标是从五个角(标记为1-5的节点)中的任意一个开始绘制圣诞老人之家,并且每条线(边)都只描绘一次。在此,可以看到有两个节点的度数为四,两个节点的度数为三,一个节点的度数为二,因此欧拉路径必然存在。事实上,正如以下动画所示,据称可以为这个谜题构建44条不同的欧拉路径:
Video Player
来源:维基百科 (CC0 1.0 Universal)
欧拉路径可以使用Hierholzer算法通过编程方式推导,具体解释可参见以下视频:
Hierholzer算法采用了一种称为回溯的搜索技术,这篇文章对此有更详细的介绍。
欧拉路径在片段组装中的应用
给定一组代表信息片段的节点,可以利用欧拉路径的概念将这些片段有意义地拼接起来。
为了理解其工作原理,可以从一个不需要太多领域知识的问题开始:给定一个两位正整数列表,是否有可能将这些整数排列成一个序列 x 1, x 2, …, x n,使得整数 _x i_ 的十位数与整数 _x i+1_ 的个位数匹配?假设有以下列表:[22, 23, 25, 34, 42, 55, 56, 57, 67, 75, 78, 85]。通过观察发现,例如,如果 x i = 22(个位数为2),那么 x i+1 可以是23或25(十位数为2),而如果 x i = 78,那么 x i+1 只能是85。现在,如果将整数列表转换为一个有向图,其中每个数字是一个节点,每个两位整数被建模为从其十位数到其个位数的有向边,那么在这个有向图中找到一条欧拉路径将给出问题的一个可能解决方案。这种方法的Python实现如下所示:
from collections import defaultdict
def find_eulerian_path(numbers):
# 初始化图
graph = defaultdict(list)
indeg = defaultdict(int)
outdeg = defaultdict(int)
for num in numbers:
a, b = divmod(num, 10) # a = 十位数, b = 个位数
graph[a].append(b)
outdeg[a] += 1
indeg[b] += 1
# 寻找起始节点
start = None
start_nodes = end_nodes = 0
for v in set(indeg) | set(outdeg):
outd = outdeg[v]
ind = indeg[v]
if outd - ind == 1:
start_nodes += 1
start = v
elif ind - outd == 1:
end_nodes += 1
elif ind == outd:
continue
else:
return None # 不可能存在欧拉路径
if not start:
start = numbers[0] // 10 # 如果是欧拉回路,则任意选择一个起始点
if not ( (start_nodes == 1 and end_nodes == 1) or (start_nodes == 0 and end_nodes == 0) ):
return None # 不存在欧拉路径
# 使用Hierholzer算法
path = []
stack = [start]
local_graph = {u: list(vs) for u, vs in graph.items()}
while stack:
u = stack[-1]
if local_graph.get(u):
v = local_graph[u].pop()
stack.append(v)
else:
path.append(stack.pop())
path.reverse() # 由于回溯,路径是逆序的
# 将路径转换为包含原始数字的解决方案序列
result = []
for i in range(len(path) - 1):
result.append(path[i] * 10 + path[i+1])
return result if len(result) == len(numbers) else None
given_integer_list = [22, 23, 25, 34, 42, 55, 56, 57, 67, 75, 78, 85]
solution_sequence = find_eulerian_path(given_integer_list)
print(solution_sequence)
结果:
[23, 34, 42, 22, 25, 57, 78, 85, 56, 67, 75, 55]
DNA片段组装是生物信息学领域中上述过程的一个典型应用案例。本质上,在DNA测序过程中,科学家们会获得许多短的DNA片段,必须将这些片段拼接起来以获得完整的DNA序列的有效候选序列,这可以利用欧拉路径的概念相对高效地完成(更多细节请参阅这篇论文)。每个DNA片段,称为k-mer,由从集合{ A, C, G, T }中提取的k个字母组成,这些字母代表构成DNA分子的核苷酸碱基;例如,ACT和CTG将是3-mers。现在可以构建一个所谓的de Bruijn图,其中节点代表(k-1)-mer前缀(例如,ACT的AC和CTG的CT),有向边表示源节点和目标节点之间的重叠(例如,由于字母C的重叠,将存在从AC到CT的边)。推导完整的DNA序列的有效候选序列,相当于在de Bruijn图中寻找一条欧拉路径。以下视频展示了一个工作示例:
生成旋律的算法
如果拥有一组代表音乐主题的片段,可以利用上一节概述的方法,通过将它们转换为de Bruijn图并识别欧拉路径,从而将这些主题以合理的方式排列成序列。接下来,将详细介绍其在Python中的端到端实现。代码已在macOS Sequoia 15.6.1上测试通过。
第一部分:安装与项目设置
首先,需要安装FFmpeg和FluidSynth,这两个工具对于处理音频数据非常有用。以下是在Mac上使用Homebrew安装它们的方法:
brew install ffmpeg
brew install fluid-synth
此外,还将使用uv进行Python项目管理。安装说明可以在此处找到。
现在将创建一个名为eulerian-melody-generator的项目文件夹,一个用于存放旋律生成逻辑的main.py文件,以及一个基于Python 3.12的虚拟环境:
mkdir eulerian-melody-generator
cd eulerian-melody-generator
uv init --bare
touch main.py
uv venv --python 3.12
source .venv/bin/activate
接下来,需要创建一个包含以下依赖项的requirements.txt文件,并将其放置在eulerian-melody-generator目录中:
matplotlib==3.10.5
midi2audio==0.1.1
midiutil==1.2.1
networkx==3.5
midi2audio和midiutil包是音频处理所必需的,而matplotlib和networkx将用于可视化de Bruijn图。现在可以在虚拟环境中安装这些包:
uv add -r requirements.txt
执行uv pip list以验证包是否已安装。
最后,还需要一个SoundFont文件来根据MIDI数据渲染音频输出。为了本文的目的,将使用文件TimGM6mb.sf2,该文件可在这个MuseScore网站上找到,或直接从此处下载。将把该文件放置在eulerian-melody-generator目录中main.py的旁边。
第二部分:旋律生成逻辑
现在,将在main.py中实现旋律生成逻辑。首先添加相关的导入语句并定义一些有用的查找变量:
import os
import random
import subprocess
from collections import defaultdict
from midiutil import MIDIFile
from midi2audio import FluidSynth
import networkx as nx
import matplotlib.pyplot as plt
# 解析SoundFont路径(假设与工作目录相同)
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
SOUNDFONT_PATH = os.path.abspath(os.path.join(BASE_DIR, ".", "TimGM6mb.sf2"))
# 12音高半音参考
NOTE_TO_OFFSET = {
"C": 0, "C#":1, "D":2, "D#":3, "E":4,
"F":5, "F#":6, "G":7, "G#":8, "A":9,
"A#":10, "B":11
}
# 流行友好的音程模式(相对于根音的半音数)
MAJOR = [0, 2, 4, 5, 7, 9, 11]
NAT_MINOR = [0, 2, 3, 5, 7, 8, 10]
MAJOR_PENTA = [0, 2, 4, 7, 9]
MINOR_PENTA = [0, 3, 5, 7, 10]
MIXOLYDIAN = [0, 2, 4, 5, 7, 9, 10]
DORIAN = [0, 2, 3, 5, 7, 9, 10]
还将定义几个辅助函数来创建所有十二个调的音阶字典:
def generate_scales_all_keys(scale_name, intervals):
"""
在所有12个键中构建给定音阶。
"""
scales = {}
chromatic = [*NOTE_TO_OFFSET] # 获取字典键
for i, root in enumerate(chromatic):
notes = [chromatic[(i + step) % 12] for step in intervals]
key_name = f"{root}-{scale_name}"
scales[key_name] = notes
return scales
def generate_scale_dict():
"""
构建所有键的主字典。
"""
scale_dict = {}
scale_dict.update(generate_scales_all_keys("Major", MAJOR))
scale_dict.update(generate_scales_all_keys("Natural-Minor", NAT_MINOR))
scale_dict.update(generate_scales_all_keys("Major-Pentatonic", MAJOR_PENTA))
scale_dict.update(generate_scales_all_keys("Minor-Pentatonic", MINOR_PENTA))
scale_dict.update(generate_scales_all_keys("Mixolydian", MIXOLYDIAN))
scale_dict.update(generate_scales_all_keys("Dorian", DORIAN))
return scale_dict
接下来,将实现用于生成k-mer及其对应de Bruijn图的函数。请注意,k-mer的生成受到限制,以保证de Bruijn图中存在欧拉路径。在k-mer生成过程中还使用了随机种子以确保结果的可复现性:
def generate_eulerian_kmers(k, count, scale_notes, seed=42):
"""
在给定音阶上生成k-mer,形成具有保证欧拉路径的连接De Bruijn图。
"""
random.seed(seed)
if count < 1:
return []
# 随机选择一个起始 (k-1)-元组
start_node = tuple(random.choice(scale_notes) for _ in range(k-1))
nodes = {start_node}
edges = []
out_deg = defaultdict(int)
in_deg = defaultdict(int)
current = start_node
for _ in range(count):
# 从音阶中选择下一个音符
next_note = random.choice(scale_notes)
next_node = tuple(list(current[1:]) + [next_note])
# 添加k-mer边
edges.append(current + (next_note,))
nodes.add(next_node)
out_deg[current] += 1
in_deg[next_node] += 1
current = next_node # 继续遍历
# 检查度数不平衡并重试以满足欧拉路径的度数条件
start_candidates = [n for n in nodes if out_deg[n] - in_deg[n] > 0]
end_candidates = [n for n in nodes if in_deg[n] - out_deg[n] > 0]
if len(start_candidates) > 1 or len(end_candidates) > 1:
# 为简化起见:重新生成直到满足条件
return generate_eulerian_kmers(k, count, scale_notes, seed+1)
return edges
def build_debruijn_graph(kmers):
"""
构建一个De Bruijn风格的图。
"""
adj = defaultdict(list)
in_deg = defaultdict(int)
out_deg = defaultdict(int)
for kmer in kmers:
prefix = tuple(kmer[:-1])
suffix = tuple(kmer[1:])
adj[prefix].append(suffix)
out_deg[prefix] += 1
in_deg[suffix] += 1
return adj, in_deg, out_deg
将实现一个函数来可视化de Bruijn图并将其保存以供后续使用:
def generate_and_save_graph(graph_dict, output_file="debruijn_graph.png", seed=100, k=1):
"""
可视化图并将其保存为PNG文件。
"""
# 创建一个有向图
G = nx.DiGraph()
# 从邻接字典添加边
for prefix, suffixes in graph_dict.items():
for suffix in suffixes:
G.add_edge(prefix, suffix)
# 节点布局(k值越大,节点间距越大)
pos = nx.spring_layout(G, seed=seed, k=k)
# 绘制节点和边
plt.figure(figsize=(10, 8))
nx.draw_networkx_nodes(G, pos, node_size=1600, node_color="skyblue", edgecolors="black")
nx.draw_networkx_edges(
G, pos,
arrowstyle="-|>",
arrowsize=20,
edge_color="black",
connectionstyle="arc3,rad=0.1",
min_source_margin=20,
min_target_margin=20
)
nx.draw_networkx_labels(G, pos, labels={node: " ".join(node) for node in G.nodes()}, font_size=10)
# 边标签
edge_labels = { (u,v): "" for u,v in G.edges() }
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels, font_color="red", font_size=8)
plt.axis("off")
plt.tight_layout()
plt.savefig(output_file, format="PNG", dpi=300)
plt.close()
print(f"图已保存到 {output_file}")
接下来,将实现函数来推导de Bruijn图中的欧拉路径,并将路径展平为音符序列。与前面讨论的DNA片段组装方法不同,在展平过程中不会对k-mer的重叠部分进行去重,以允许产生更具美感的旋律:
def find_eulerian_path(adj, in_deg, out_deg):
"""
在De Bruijn图中寻找欧拉路径。
"""
start = None
for node in set(list(adj) + list(in_deg)):
if out_deg[node] - in_deg[node] == 1:
start = node
break
if start is None:
start = next(n for n in adj if adj[n])
stack = [start]
path = []
local_adj = {u: vs[:] for u, vs in adj.items()}
while stack:
v = stack[-1]
if local_adj.get(v):
u = local_adj[v].pop()
stack.append(u)
else:
path.append(stack.pop())
return path[::-1]
def flatten_path(path_nodes):
"""
将音符元组列表展平为单个列表。
"""
flattened = []
for kmer in path_nodes:
flattened.extend(kmer)
return flattened
现在,将编写一些函数来创作旋律并将其导出为MP3文件。关键函数是compose_and_export,它为构成欧拉路径的音符渲染添加了变化(例如,不同的音符长度和八度),以确保生成的旋律不会过于单调。同时,还抑制/重定向了FFmpeg和FluidSynth的详细输出:
import contextlib
def note_with_octave_to_midi(note, octave):
"""
辅助函数,用于将像“C#”这样的音高在某个八度音阶中转换为其数字MIDI音符编号。
"""
return 12 * (octave + 1) + NOTE_TO_OFFSET[note]
@contextlib.contextmanager
def suppress_fd_output():
"""
在操作系统文件描述符级别重定向stdout和stderr。
这可以捕获来自C库(如FluidSynth)的输出。
"""
with open(os.devnull, 'w') as devnull:
# 复制原始文件描述符
old_stdout_fd = os.dup(1)
old_stderr_fd = os.dup(2)
try:
# 重定向到 /dev/null
os.dup2(devnull.fileno(), 1)
os.dup2(devnull.fileno(), 2)
yield
finally:
# 恢复原始文件描述符
os.dup2(old_stdout_fd, 1)
os.dup2(old_stderr_fd, 2)
os.close(old_stdout_fd)
os.close(old_stderr_fd)
def compose_and_export(final_notes,
bpm=120,
midi_file="output.mid",
wav_file="temp.wav",
mp3_file="output.mp3",
soundfont_path=SOUNDFONT_PATH):
# 古典风格的节奏模式
rhythmic_patterns = [
[1.0, 1.0, 2.0], # 四分音符,四分音符,二分音符
[0.5, 0.5, 1.0, 2.0], # 八分音符,八分音符,四分音符,二分音符
[1.5, 0.5, 1.0, 1.0], # 附点四分音符,八分音符,四分音符,四分音符
[0.5, 0.5, 0.5, 0.5, 2.0] # 一连串八分音符,然后是二分音符
]
# 构建八度音程轮廓:先上升后下降
base_octave = 4
peak_octave = 5
contour = []
half_len = len(final_notes) // 2
for i in range(len(final_notes)):
if i < half_len:
# 逐渐上升
contour.append(base_octave if i < half_len // 2 else peak_octave)
else:
# 下降
contour.append(peak_octave if i < (half_len + half_len // 2) else base_octave)
# 根据节奏模式和轮廓分配事件
events = []
note_index = 0
while note_index < len(final_notes):
pattern = random.choice(rhythmic_patterns)
for dur in pattern:
if note_index >= len(final_notes):
break
octave = contour[note_index]
events.append((final_notes[note_index], octave, dur))
note_index += 1
# 写入MIDI文件
mf = MIDIFile(1)
track = 0
mf.addTempo(track, 0, bpm)
time = 0
for note, octv, dur in events:
pitch = note_with_octave_to_midi(note, octv)
mf.addNote(track, channel=0, pitch=pitch,
time=time, duration=dur, volume=100)
time += dur
with open(midi_file, "wb") as out_f:
mf.writeFile(out_f)
# 渲染为WAV文件
with suppress_fd_output():
fs = FluidSynth(sound_font=soundfont_path)
fs.midi_to_audio(midi_file, wav_file)
# 转换为MP3文件
subprocess.run(
[
"ffmpeg", "-y", "-hide_banner", "-loglevel", "quiet", "-i",
wav_file, mp3_file
],
check=True
)
print(f"已生成 {mp3_file}")
最后,将在if name == "main"部分演示如何使用旋律生成器。可以改变几个参数——音阶、BPM(每分钟拍数)、k-mer长度、k-mer数量、欧拉路径的重复次数(或循环次数)以及随机种子——以生成不同的旋律:
if __name__ == "__main__":
SCALE = "C-Major-Pentatonic" # 设置"键-音阶",例如 "C-Mixolydian"
BPM = 200 # 每分钟拍数(音乐节奏)
KMER_LENGTH = 4 # 每个k-mer的长度
NUM_KMERS = 8 # 生成的k-mer数量
NUM_REPEATS = 8 # 最终音符序列重复的次数
RANDOM_SEED = 2 # 用于重现结果的种子值
scale_dict = generate_scale_dict()
chosen_scale = scale_dict[SCALE]
print("选择的音阶:", chosen_scale)
kmers = generate_eulerian_kmers(k=KMER_LENGTH, count=NUM_KMERS, scale_notes=chosen_scale, seed=RANDOM_SEED)
adj, in_deg, out_deg = build_debruijn_graph(kmers)
generate_and_save_graph(graph_dict=adj, output_file="debruijn_graph.png", seed=20, k=2)
path_nodes = find_eulerian_path(adj, in_deg, out_deg)
print("欧拉路径:", path_nodes)
final_notes = flatten_path(path_nodes) * NUM_REPEATS # 欧拉路径的多次循环
mp3_file = f"{SCALE}_v{RANDOM_SEED}.mp3" # 构建可搜索的文件名
compose_and_export(final_notes=final_notes, bpm=BPM, mp3_file=mp3_file)
执行uv run main.py会产生以下输出:
选择的音阶: ['C', 'D', 'E', 'G', 'A']
图已保存到 debruijn_graph.png
欧拉路径: [('C', 'C', 'C'), ('C', 'C', 'E'), ('C', 'E', 'D'), ('E', 'D', 'E'), ('D', 'E', 'E'), ('E', 'E', 'A'), ('E', 'A', 'D'), ('A', 'D', 'A'), ('D', 'A', 'C')]
已生成 C-Major-Pentatonic_v2.mp3
作为上述步骤的简化替代方案,本文作者创建了一个名为emg的Python库来实现相同的结果,前提是FFmpeg和FluidSynth已经安装(详情请参阅此处)。使用pip install emg或uv add emg安装该库,并按如下所示使用:
from emg.generator import EulerianMelodyGenerator
# SoundFont文件路径
sf2_path = "TimGM6mb.sf2"
# 创建生成器实例
generator = EulerianMelodyGenerator(
soundfont_path=sf2_path,
scale="C-Major-Pentatonic",
bpm=200,
kmer_length=4,
num_kmers=8,
num_repeats=8,
random_seed=2
)
# 运行完整的生成流程
generator.run_generation_pipeline(
graph_png_path="debruijn_graph.png",
mp3_output_path="C-Major-Pentatonic_v2.mp3"
)
(可选)第三部分:将MP3转换为MP4
可以使用FFmpeg将MP3文件转换为MP4文件(将de Bruijn图的PNG导出作为封面艺术),然后可以上传到YouTube等平台。选项-loop 1使PNG图像在整个音频长度内重复,-tune stillimage优化静态图像的编码,-shortest确保视频在大致音频结束时停止,而-pix_fmt yuv420p则确保输出的像素格式与大多数播放器兼容:
ffmpeg -loop 1 -i debruijn_graph.png -i C-Major-Pentatonic_v2.mp3
-c:v libx264 -tune stillimage -c:a aac -b:a 192k
-pix_fmt yuv420p -shortest C-Major-Pentatonic_v2.mp4
以下是上传到YouTube的最终结果:
总结
本文展示了图论这样一个抽象的主题,如何在看似不相关的算法音乐创作领域中找到实际应用。有趣的是,利用随机生成的音乐片段构建欧拉路径,以及音符长度和八度音高的随机变化,与偶然音乐(alea在拉丁语中意为“骰子”)的创作实践不谋而合,其中作品的某些方面及其演奏被留给了偶然性。





