许多公司在AI部署中面临高昂成本和延迟的挑战。本文将深入探讨如何构建一个混合AI系统,该系统能够实现以下优势:
- 在边缘设备上处理94.9%的请求,响应时间低于20毫秒。
- 与纯云端解决方案相比,推理成本降低93.5%。
- 通过智能量化,模型原始准确率保持在99.1%。
- 敏感数据保留在本地,从而简化合规性管理。
本文将通过详细代码示例,完整地展示从领域适应到生产监控的全过程实现。
行业鲜有提及的真实痛点
试想一下:已经构建了一个出色的客户支持AI模型,在Jupyter Notebook中运行效果良好。然而,当将其部署到生产环境时,可能会发现以下问题:
- 在适中流量下,云端推理成本每月高达2,900美元。
- 响应时间徘徊在200毫秒左右,用户明显感受到延迟。
- 数据可能跨境传输,给合规团队带来困扰。
- 在流量高峰期,成本增长不可预测。
这些问题是否似曾相识?许多企业都面临着同样的困境。根据《福布斯科技委员会》(2024)的报告,高达85%的AI模型可能无法成功部署,其中成本和延迟是主要障碍。
解决方案:借鉴机场安检模式
设想一下,如果不再将所有查询都发送到庞大的云端模型,而是可以:
- 在本地处理95%的常规查询(类似于机场安检的快速通道)。
- 仅将复杂的案例上报至云端(进行二次筛选)。
- 保留清晰的路由决策记录(以便进行审计)。
这种“边缘优先”的方法,效仿了人类自然处理支持请求的方式。经验丰富的客服人员能够迅速解决大部分问题,仅将棘手的问题转交给专家处理。
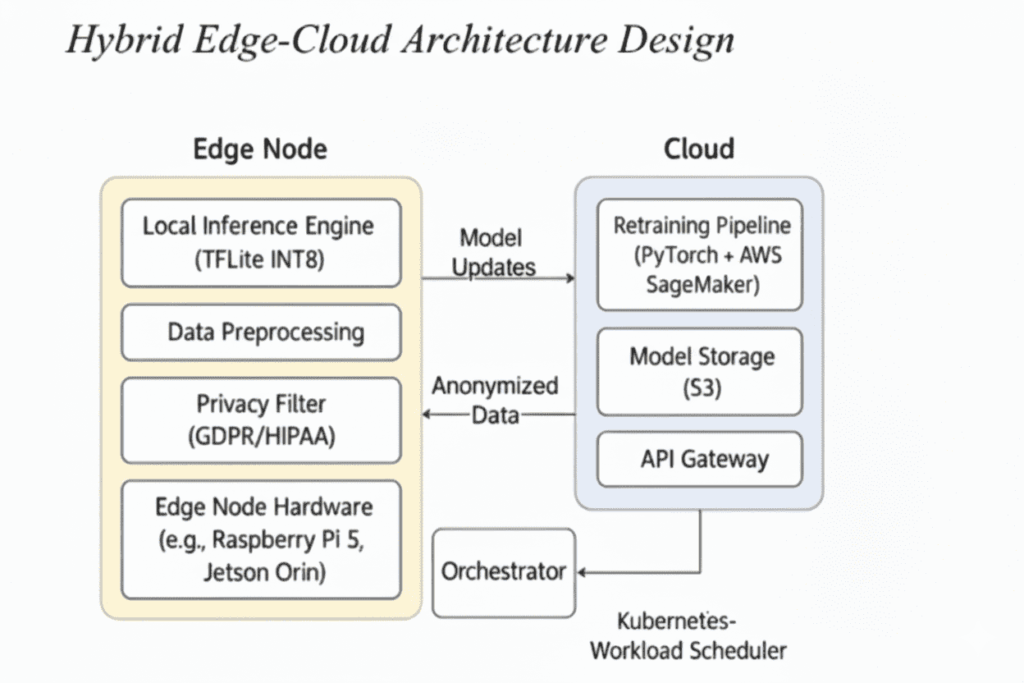
边缘和云在Kubernetes管理的混合AI机制中交换模型更新和匿名数据(作者绘图)
将共同构建的系统
通过本文的学习,读者将能够构建一个包含以下组件的系统:
- 一个领域适应模型,能够理解客户服务语言。
- 一个尺寸缩小84%的量化版本模型,可在CPU上快速运行。
- 一个智能路由器,根据每个查询决定是走边缘还是云端。
- 生产监控系统,确保整个系统健康运行。
接下来,进入代码实践环节。
环境设置:从第一天就做好准备
首先,需要建立一个可复现的运行环境。没有什么比花费一整天时间调试库冲突更能扼杀开发势头了。
import os
import warnings
import numpy as np
import pandas as pd
import torch
import tensorflow as tf
from transformers import (
DistilBertTokenizerFast, DistilBertForMaskedLM,
Trainer, TrainingArguments, TFDistilBertForSequenceClassification
)
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import onnxruntime as ort
import time
from collections import deque
def setup_reproducible_environment(seed=42):
"""Make results reproducible across runs"""
np.random.seed(seed)
torch.manual_seed(seed)
tf.random.set_seed(seed)
torch.backends.cudnn.deterministic = True
tf.config.experimental.enable_op_determinism()
warnings.filterwarnings('ignore')
print(f" Environment configured (seed: {seed})")
setup_reproducible_environment()
# Hardware specs for reproduction
SYSTEM_CONFIG = {
"cpu": "Intel Xeon Silver 4314 @ 2.4GHz",
"memory": "64GB DDR4",
"os": "Ubuntu 22.04",
"python": "3.10.12",
"key_libs": {
"torch": "2.7.1",
"tensorflow": "2.14.0",
"transformers": "4.52.4",
"onnxruntime": "1.17.3"
}
}
# Project structure
PATHS = {
"data": "./data",
"models": {
"domain_adapted": "./models/dapt",
"classifier": "./models/classifier",
"onnx_fp32": "./models/onnx/model_fp32.onnx",
"onnx_quantized": "./models/onnx/model_quantized.onnx"
},
"logs": "./logs"
}
# Create directories
for path in PATHS.values():
if isinstance(path, dict):
for p in path.values():
os.makedirs(os.path.dirname(p) if '.' in os.path.basename(p) else p, exist_ok=True)
else:
os.makedirs(path, exist_ok=True)
print(" Project structure ready") # IMPROVED: Added emoji for consistency
步骤1:领域适应 – 训练AI理解“客服语言”
一般的语言模型能够理解英语,但它们并不懂得如何提供英文支持。例如,“我需要帮助”与“这完全不可接受——我要求立刻与经理通话!”之间存在巨大差异。
领域适应预训练(DAPT)通过在客户服务对话语料上继续进行模型语言学习,然后再进行分类训练,从而解决了这一问题。
class CustomerServiceTrainer:
"""Complete pipeline for domain adaptation + classification"""
def __init__(self, base_model="distilbert-base-uncased"):
self.base_model = base_model
self.tokenizer = DistilBertTokenizerFast.from_pretrained(base_model)
print(f" Initialized with {base_model}")
def domain_adaptation(self, texts, output_path, epochs=2, batch_size=32):
"""
Phase 1: Adapt model to customer service language patterns
This is like language immersion - the model learns support-specific
vocabulary, escalation phrases, and common interaction patterns.
"""
from datasets import Dataset
from transformers import DataCollatorForLanguageModeling
print(f" Starting domain adaptation on {len(texts):,} conversations...")
# Create dataset for masked language modeling
dataset = Dataset.from_dict({"text": texts}).map(
lambda examples: self.tokenizer(
examples["text"],
padding="max_length",
truncation=True,
max_length=128 # Keep reasonable for memory
),
batched=True,
remove_columns=["text"]
)
# Initialize model for continued pre-training
model = DistilBertForMaskedLM.from_pretrained(self.base_model)
print(f" Model parameters: {model.num_parameters():,}")
# Training setup
training_args = TrainingArguments(
output_dir=output_path,
num_train_epochs=epochs,
per_device_train_batch_size=batch_size,
logging_steps=200,
save_steps=1000,
fp16=torch.cuda.is_available(), # Use mixed precision if GPU available
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
data_collator=DataCollatorForLanguageModeling(
self.tokenizer, mlm=True, mlm_probability=0.15
)
)
# Train and save
trainer.train()
trainer.save_model(output_path)
self.tokenizer.save_pretrained(output_path)
print(f" Domain adaptation complete: {output_path}")
return output_path
def train_classifier(self, X_train, X_val, y_train, y_val,
dapt_model_path, output_path, epochs=8):
"""
Phase 2: Two-stage classification training
Stage 1: Warm up classifier head (backbone frozen)
Stage 2: Fine-tune entire model with smaller learning rate
"""
from transformers import create_optimizer
print(f" Training classifier on {len(X_train):,} samples...")
# Encode labels
self.label_encoder = LabelEncoder()
y_train_enc = self.label_encoder.fit_transform(y_train)
y_val_enc = self.label_encoder.transform(y_val)
print(f" Classes: {list(self.label_encoder.classes_)}")
# Create TensorFlow datasets
def make_dataset(texts, labels, batch_size=128, shuffle=False):
encodings = self.tokenizer(
texts, padding="max_length", truncation=True,
max_length=256, return_tensors="tf" # Longer for classification
)
dataset = tf.data.Dataset.from_tensor_slices((dict(encodings), labels))
if shuffle:
dataset = dataset.shuffle(10000, seed=42)
return dataset.batch(batch_size).prefetch(tf.data.AUTOTUNE)
train_dataset = make_dataset(X_train, y_train_enc, shuffle=True)
val_dataset = make_dataset(X_val, y_val_enc)
# Load domain-adapted model for classification
model = TFDistilBertForSequenceClassification.from_pretrained(
dapt_model_path, num_labels=len(self.label_encoder.classes_)
)
# Optimizer with warmup
total_steps = len(train_dataset) * epochs
optimizer, _ = create_optimizer(
init_lr=3e-5,
num_train_steps=total_steps,
num_warmup_steps=int(0.1 * total_steps)
)
model.compile(
optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# Stage 1: Classifier head warm-up
print(" Stage 1: Warming up classifier head...")
model.distilbert.trainable = False
model.fit(train_dataset, validation_data=val_dataset, epochs=1, verbose=1)
# Stage 2: Full fine-tuning
print(" Stage 2: Full model fine-tuning...")
model.distilbert.trainable = True
model.optimizer.learning_rate = 3e-6 # Smaller LR for stability
# Add callbacks for better training
callbacks = [
tf.keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True),
tf.keras.callbacks.ReduceLROnPlateau(factor=0.5, patience=1)
]
history = model.fit(
train_dataset,
validation_data=val_dataset,
epochs=epochs-1, # Already did 1 epoch
callbacks=callbacks,
verbose=1
)
# Save everything
model.save_pretrained(output_path)
self.tokenizer.save_pretrained(output_path)
import joblib
joblib.dump(self.label_encoder, f"{output_path}/label_encoder.pkl")
best_acc = max(history.history['val_accuracy'])
print(f" Training complete! Best accuracy: {best_acc:.4f}")
return model, history
# Let's create some sample data for demonstration
def create_sample_data(n_samples=5000):
"""Generate realistic customer service data for demo"""
np.random.seed(42)
# Sample conversation templates
templates = {
'positive': [
"Thank you so much for the excellent customer service today!",
"Great job resolving my issue quickly and professionally.",
"I really appreciate the help with my account.",
"The support team was fantastic and very knowledgeable.",
"Perfect service, exactly what I needed."
],
'negative': [
"This is completely unacceptable and I demand to speak with a manager!",
"I'm extremely frustrated with the poor service quality.",
"This issue has been ongoing for weeks without resolution.",
"Terrible experience, worst customer service ever.",
"I want a full refund immediately, this is ridiculous."
],
'neutral': [
"I need help with my account settings please.",
"Can you check the status of my recent order?",
"What are your business hours and contact information?",
"I have a question about billing and payment options.",
"Please help me understand the refund process."
]
}
data = []
for _ in range(n_samples):
sentiment = np.random.choice(['positive', 'negative', 'neutral'],
p=[0.4, 0.3, 0.3]) # Realistic distribution
template = np.random.choice(templates[sentiment])
# Add some variation
if np.random.random() < 0.2: # 20% get account numbers
template += f" My account number is {np.random.randint(100000, 999999)}."
data.append({
'transcript': template,
'sentiment': sentiment
})
df = pd.DataFrame(data)
print(f" Created {len(df):,} sample conversations")
print(f" Sentiment distribution:
{df['sentiment'].value_counts()}")
return df
# Execute domain adaptation and classification training
trainer = CustomerServiceTrainer()
# Create sample data (replace with your actual data)
df = create_sample_data(5000)
# Split data
X_train, X_val, y_train, y_val = train_test_split(
df['transcript'], df['sentiment'],
test_size=0.2, stratify=df['sentiment'], random_state=42
)
# Run domain adaptation
dapt_path = trainer.domain_adaptation(
df['transcript'].tolist(),
PATHS['models']['domain_adapted'],
epochs=2
)
# Train classifier
model, history = trainer.train_classifier(
X_train.tolist(), X_val.tolist(),
y_train.tolist(), y_val.tolist(),
dapt_path,
PATHS['models']['classifier'],
epochs=6
)
步骤2:模型压缩 – 实现84%的尺寸缩减
现在,将进行“魔术”操作:在几乎不损失准确率的情况下,将模型压缩84%。这是实现边缘部署的关键。
核心洞察在于,大多数神经网络都存在过度工程化。它们使用32位浮点数,而对于大多数任务来说,8位整数通常也能很好地工作。这就像使用高分辨率相机来拍摄社交媒体照片,而手机相机就能达到相同的效果。
class ModelCompressor:
"""ONNX-based model compression with comprehensive validation"""
def __init__(self, model_path):
self.model_path = model_path
self.tokenizer = DistilBertTokenizerFast.from_pretrained(model_path)
print(f" Compressor ready for {model_path}")
def compress_to_onnx(self, fp32_output, quantized_output):
"""
Two-step process:
1. Convert TensorFlow model to ONNX (cross-platform format)
2. Apply dynamic INT8 quantization (no calibration needed)
"""
from optimum.onnxruntime import ORTModelForSequenceClassification
from onnxruntime.quantization import quantize_dynamic, QuantType
print(" Step 1: Converting to ONNX format...")
# Export to ONNX (this makes the model portable across platforms)
ort_model = ORTModelForSequenceClassification.from_pretrained(
self.model_path, export=True, provider="CPUExecutionProvider"
)
ort_model.save_pretrained(os.path.dirname(fp32_output))
# Rename to our desired path
generated_path = os.path.join(os.path.dirname(fp32_output), "model.onnx")
if os.path.exists(generated_path):
os.rename(generated_path, fp32_output)
fp32_size = os.path.getsize(fp32_output) / (1024**2) # MB
print(f" Original ONNX model: {fp32_size:.2f}MB")
print(" Step 2: Applying dynamic INT8 quantization...")
# Dynamic quantization - no calibration dataset needed!
quantize_dynamic(
model_input=fp32_output,
model_output=quantized_output,
op_types_to_quantize=[QuantType.QInt8, QuantType.QUInt8],
weight_type=QuantType.QInt8,
optimize_model=False # Keep optimization separate
)
quantized_size = os.path.getsize(quantized_output) / (1024**2) # MB
compression_ratio = (fp32_size - quantized_size) / fp32_size * 100
print(f" Quantized model: {quantized_size:.2f}MB")
print(f" Compression: {compression_ratio:.1f}% size reduction")
return fp32_output, quantized_output, compression_ratio
def benchmark_models(self, fp32_path, quantized_path, test_texts, test_labels):
"""
Compare FP32 vs INT8 models on accuracy, speed, and size
This is crucial - we need to verify our compression didn't break anything!
"""
print(" Benchmarking model performance...")
results = {}
for name, model_path in [("FP32 Original", fp32_path), ("INT8 Quantized", quantized_path)]:
print(f" Testing {name}...")
# Load model for inference
session = ort.InferenceSession(model_path, providers=["CPUExecutionProvider"])
# Test on representative sample (500 examples for speed)
test_sample = min(500, len(test_texts))
correct_predictions = 0
latencies = []
# Warm up the model (important for fair timing!)
warmup_text = "Thank you for your help with my order today"
warmup_encoding = self.tokenizer(
warmup_text, padding="max_length", truncation=True,
max_length=256, return_tensors="np"
)
for _ in range(10): # 10 warmup runs
_ = session.run(None, {
"input_ids": warmup_encoding["input_ids"],
"attention_mask": warmup_encoding["attention_mask"]
})
# Actual benchmarking
for i in range(test_sample):
text, true_label = test_texts[i], test_labels[i]
encoding = self.tokenizer(
text, padding="max_length", truncation=True,
max_length=256, return_tensors="np"
)
# Time the inference
start_time = time.perf_counter()
outputs = session.run(None, {
"input_ids": encoding["input_ids"],
"attention_mask": encoding["attention_mask"]
})
latency_ms = (time.perf_counter() - start_time) * 1000
latencies.append(latency_ms)
# Check accuracy
predicted_class = np.argmax(outputs[0])
if predicted_class == true_label:
correct_predictions += 1
# Calculate metrics
accuracy = correct_predictions / test_sample
mean_latency = np.mean(latencies)
p95_latency = np.percentile(latencies, 95)
model_size_mb = os.path.getsize(model_path) / (1024**2)
results[name] = {
"accuracy": accuracy,
"mean_latency_ms": mean_latency,
"p95_latency_ms": p95_latency,
"model_size_mb": model_size_mb,
"throughput_qps": 1000 / mean_latency # Queries per second
}
print(f" ✓ Accuracy: {accuracy:.4f}")
print(f" ✓ Mean latency: {mean_latency:.2f}ms")
print(f" ✓ P95 latency: {p95_latency:.2f}ms")
print(f" ✓ Model size: {model_size_mb:.2f}MB")
print(f" ✓ Throughput: {results[name]['throughput_qps']:.1f} QPS")
# Show the comparison
if len(results) == 2:
fp32_results = results["FP32 Original"]
int8_results = results["INT8 Quantized"]
size_reduction = (1 - int8_results["model_size_mb"] / fp32_results["model_size_mb"]) * 100
accuracy_retention = int8_results["accuracy"] / fp32_results["accuracy"]
latency_change = ((int8_results["mean_latency_ms"] - fp32_results["mean_latency_ms"])
/ fp32_results["mean_latency_ms"]) * 100
print(f"
Quantization Impact Summary:")
print(f" Size reduction: {size_reduction:.1f}%")
print(f" Accuracy retention: {accuracy_retention:.1%}")
print(f" Latency change: {latency_change:+.1f}%")
print(f" Memory saved: {fp32_results['model_size_mb'] - int8_results['model_size_mb']:.1f}MB")
return results
# Execute model compression
compressor = ModelCompressor(PATHS['models']['classifier'])
# Compress the model
fp32_path, quantized_path, compression_ratio = compressor.compress_to_onnx(
PATHS['models']['onnx_fp32'],
PATHS['models']['onnx_quantized']
)
# Load test data and label encoder for benchmarking
import joblib
label_encoder = joblib.load(f"{PATHS['models']['classifier']}/label_encoder.pkl")
test_labels_encoded = label_encoder.transform(y_val[:500])
# Benchmark the models
benchmark_results = compressor.benchmark_models(
fp32_path, quantized_path,
X_val[:500].tolist(), test_labels_encoded
)
步骤3:智能路由器 – 决策边缘与云端分配
这是混合AI系统发挥魔力的地方。智能路由器会分析每个客户查询,并决定是在本地(边缘)处理,还是转发到云端。可以将其视为一个智能流量控制器。
路由器会考虑以下五个因素:
- 文本长度 – 较长的查询通常意味着问题更复杂。
- 句子结构 – 包含多个从句可能暗示着细致入微的问题。
- 情感指标 – “沮丧”等词汇表示需要升级处理。
- 模型置信度 – 如果AI模型不确定,则路由到云端。
- 升级关键词 – 例如“经理”、“投诉”等。
class IntelligentRouter:
"""
Smart routing system that maximizes edge usage while maintaining quality
The core insight: 95% of customer queries are routine and can be handled
by a small, fast model. The remaining 5% need the full power of the cloud.
"""
def __init__(self, edge_model_path, cloud_model_path, tokenizer_path):
# Load both models
self.edge_session = ort.InferenceSession(
edge_model_path, providers=["CPUExecutionProvider"]
)
self.cloud_session = ort.InferenceSession(
cloud_model_path, providers=["CPUExecutionProvider"] # Can also use GPU
)
# Load tokenizer and label encoder
self.tokenizer = DistilBertTokenizerFast.from_pretrained(tokenizer_path)
import joblib
self.label_encoder = joblib.load(f"{tokenizer_path}/label_encoder.pkl")
# Routing configuration (tuned through experimentation)
self.complexity_threshold = 0.75 # Route to cloud if complexity > 0.75
self.confidence_threshold = 0.90 # Route to cloud if confidence < 0.90
self.edge_preference = 0.95 # 95% preference for edge when possible
# Cost tracking (realistic cloud pricing)
self.costs = {
"edge": 0.001, # $0.001 per inference on edge
"cloud": 0.0136 # $0.0136 per inference on cloud (OpenAI-like pricing)
}
# Performance metrics
self.metrics = {
"total_requests": 0,
"edge_requests": 0,
"cloud_requests": 0,
"total_cost": 0.0,
"routing_reasons": {}
}
print(" Smart router initialized")
print(f" Complexity threshold: {self.complexity_threshold}")
print(f" Confidence threshold: {self.confidence_threshold}")
print(f" Cloud/edge cost ratio: {self.costs['cloud']/self.costs['edge']:.1f}x")
def analyze_complexity(self, text, model_confidence):
"""
Multi-dimensional complexity analysis
This is the heart of our routing logic. We look at multiple signals
to determine if a query needs the full power of the cloud model.
"""
# Factor 1: Length complexity (normalized by typical customer messages)
# Longer messages often indicate more complex issues
length_score = min(len(text) / 200, 1.0) # 200 chars = typical message
# Factor 2: Syntactic complexity (sentence structure)
sentences = [s.strip() for s in text.split('.') if s.strip()]
words = text.split()
if sentences and words:
avg_sentence_length = len(words) / len(sentences)
syntax_score = min(avg_sentence_length / 15, 1.0) # 15 words = average
else:
syntax_score = 0.0
# Factor 3: Model uncertainty (inverse of confidence)
# If the model isn't confident, it's probably a complex case
uncertainty_score = 1 - abs(2 * model_confidence - 1)
# Factor 4: Escalation/emotional keywords
escalation_keywords = [
'frustrated', 'angry', 'unacceptable', 'manager', 'supervisor',
'complaint', 'terrible', 'awful', 'disgusted', 'furious'
]
keyword_matches = sum(1 for word in escalation_keywords if word in text.lower())
emotion_score = min(keyword_matches / 3, 1.0) # Normalize to 0-1
# Weighted combination (weights tuned through experimentation)
complexity = (
0.3 * length_score + # Length matters most
0.3 * syntax_score + # Structure is important
0.2 * uncertainty_score + # Model confidence
0.2 * emotion_score # Emotional indicators
)
return complexity, {
'length': length_score,
'syntax': syntax_score,
'uncertainty': uncertainty_score,
'emotion': emotion_score,
'keyword_matches': keyword_matches
}
def route_queries(self, queries):
"""
Main routing pipeline
1. Get initial predictions from cloud model (for confidence scores)
2. Analyze complexity of each query
3. Route simple queries to edge, complex ones stay on cloud
4. Return results with routing decisions logged
"""
print(f" Routing {len(queries)} customer queries...")
# Step 1: Get cloud predictions for complexity analysis
cloud_predictions = self._run_inference(self.cloud_session, queries, "cloud")
# Step 2: Analyze each query and make routing decisions
edge_queries = []
edge_indices = []
routing_decisions = []
for i, (query, cloud_result) in enumerate(zip(queries, cloud_predictions)):
if "error" in cloud_result:
# If cloud failed, force to edge as fallback
decision = {
"route": "edge",
"reason": "cloud_error",
"complexity": 0.0,
"confidence": 0.0
}
edge_queries.append(query)
edge_indices.append(i)
else:
# Analyze complexity
complexity, breakdown = self.analyze_complexity(
query, cloud_result["confidence"]
)
# Make routing decision
should_use_edge = (
complexity <= self.complexity_threshold and
cloud_result["confidence"] >= self.confidence_threshold and
np.random.random() < self.edge_preference
)
# Determine reason for routing decision
if should_use_edge:
reason = "optimal_edge"
edge_queries.append(query)
edge_indices.append(i)
else:
if complexity > self.complexity_threshold:
reason = "high_complexity"
elif cloud_result["confidence"] < self.confidence_threshold:
reason = "low_confidence"
else:
reason = "random_cloud"
decision = {
"route": "edge" if should_use_edge else "cloud",
"reason": reason,
"complexity": complexity,
"confidence": cloud_result["confidence"],
"breakdown": breakdown
}
routing_decisions.append(decision)
# Step 3: Run edge inference for selected queries
if edge_queries:
edge_results = self._run_inference(self.edge_session, edge_queries, "edge")
# Replace cloud results with edge results for routed queries
for idx, edge_result in zip(edge_indices, edge_results):
cloud_predictions[idx] = edge_result
# Step 4: Add routing metadata and costs
for i, (result, decision) in enumerate(zip(cloud_predictions, routing_decisions)):
result.update(decision)
result["cost"] = self.costs[decision["route"]]
# Step 5: Update metrics
edge_count = len(edge_queries)
cloud_count = len(queries) - edge_count
self.metrics["total_requests"] += len(queries)
self.metrics["edge_requests"] += edge_count
self.metrics["cloud_requests"] += cloud_count
batch_cost = edge_count * self.costs["edge"] + cloud_count * self.costs["cloud"]
self.metrics["total_cost"] += batch_cost
# Track routing reasons
for decision in routing_decisions:
reason = decision["reason"]
self.metrics["routing_reasons"][reason] = (
self.metrics["routing_reasons"].get(reason, 0) + 1
)
print(f" Routed: {edge_count} edge, {cloud_count} cloud")
print(f" Batch cost: ${batch_cost:.4f}")
print(f" Edge utilization: {edge_count/len(queries):.1%}")
return cloud_predictions, {
"total_queries": len(queries),
"edge_utilization": edge_count / len(queries),
"batch_cost": batch_cost,
"avg_complexity": np.mean([d["complexity"] for d in routing_decisions])
}
def _run_inference(self, session, texts, source):
"""Run batch inference with error handling"""
try:
# Tokenize all texts
encodings = self.tokenizer(
texts, padding="max_length", truncation=True,
max_length=256, return_tensors="np"
)
# Run inference
outputs = session.run(None, {
"input_ids": encodings["input_ids"],
"attention_mask": encodings["attention_mask"]
})
# Process results
results = []
for i, logits in enumerate(outputs[0]):
predicted_class = int(np.argmax(logits))
confidence = float(np.max(self._softmax(logits)))
predicted_sentiment = self.label_encoder.inverse_transform([predicted_class])[0]
results.append({
"text": texts[i],
"predicted_class": predicted_class,
"predicted_sentiment": predicted_sentiment,
"confidence": confidence,
"processing_location": source
})
return results
except Exception as e:
# Return error results
return [{"text": text, "error": str(e), "processing_location": source}
for text in texts]
def _softmax(self, x):
"""Convert logits to probabilities"""
exp_x = np.exp(x - np.max(x))
return exp_x / np.sum(exp_x)
def get_system_stats(self):
"""Get comprehensive system statistics"""
if self.metrics["total_requests"] == 0:
return {"error": "No requests processed"}
# Calculate cost savings vs cloud-only
cloud_only_cost = self.metrics["total_requests"] * self.costs["cloud"]
actual_cost = self.metrics["total_cost"]
savings_percent = (cloud_only_cost - actual_cost) / cloud_only_cost * 100
return {
"total_queries_processed": self.metrics["total_requests"],
"edge_utilization": self.metrics["edge_requests"] / self.metrics["total_requests"],
"cloud_utilization": self.metrics["cloud_requests"] / self.metrics["total_requests"],
"total_cost": self.metrics["total_cost"],
"cost_per_query": self.metrics["total_cost"] / self.metrics["total_requests"],
"cost_savings_percent": savings_percent,
"routing_reasons": dict(self.metrics["routing_reasons"]),
"estimated_monthly_savings": (cloud_only_cost - actual_cost) * 30
}
# Initialize the router
router = IntelligentRouter(
edge_model_path=PATHS['models']['onnx_quantized'],
cloud_model_path=PATHS['models']['onnx_fp32'],
tokenizer_path=PATHS['models']['classifier']
)
# Test with realistic customer queries
test_queries = [
"Thank you so much for the excellent customer service today!",
"I'm extremely frustrated with this ongoing billing issue that has been happening for three months despite multiple calls to your support team who seem completely unable to resolve these complex account synchronization problems.",
"Can you please help me check my order status?",
"What's your return policy for defective products?",
"This is completely unacceptable and I demand to speak with a manager immediately about these billing errors!",
"My account number is 123456789 and I need help with the upgrade process.",
"Hello, I have a quick question about my recent purchase.",
"The technical support team was unable to resolve my connectivity issue and I need escalation to a senior specialist who can handle enterprise network configuration problems."
]
# Route the queries
results, batch_metrics = router.route_queries(test_queries)
# Display detailed results
print(f"
DETAILED ROUTING ANALYSIS:")
for i, (query, result) in enumerate(zip(test_queries, results)):
route = result.get("processing_location", "unknown").upper()
sentiment = result.get("predicted_sentiment", "unknown")
confidence = result.get("confidence", 0)
complexity = result.get("complexity", 0)
reason = result.get("reason", "unknown")
cost = result.get("cost", 0)
print(f"
Query {i+1}: "{query[:60]}..."")
print(f" Route: {route} (reason: {reason})")
print(f" Sentiment: {sentiment} (confidence: {confidence:.3f})")
print(f" Complexity: {complexity:.3f}")
print(f" Cost: ${cost:.6f}")
# Show system-wide performance
system_stats = router.get_system_stats()
print(f"
SYSTEM PERFORMANCE SUMMARY:")
print(f" Total queries: {system_stats['total_queries_processed']}")
print(f" Edge utilization: {system_stats['edge_utilization']:.1%}")
print(f" Cost per query: ${system_stats['cost_per_query']:.6f}")
print(f" Cost savings: {system_stats['cost_savings_percent']:.1f}%")
print(f" Monthly savings estimate: ${system_stats['estimated_monthly_savings']:.2f}")
步骤4:生产监控 – 确保系统健康运行
没有监控的系统,迟早会出问题。本文的监控设置轻量而有效,能够捕捉到关键问题:准确率下降、成本飙升和路由故障。
class ProductionMonitor:
"""
Lightweight production monitoring for hybrid AI systems
Tracks the metrics that actually matter for business outcomes:
- Edge utilization (cost impact)
- Accuracy trends (quality impact)
- Latency distribution (user experience impact)
- Cost per query (budget impact)
"""
def __init__(self, alert_thresholds=None):
# Set sensible defaults for alerts
self.thresholds = alert_thresholds or {
"min_edge_utilization": 0.80, # Alert if < 80% edge utilization
"min_accuracy": 0.85, # Alert if accuracy drops below 85%
"max_cost_per_query": 0.01, # Alert if cost > $0.01 per query
"max_p95_latency": 150 # Alert if P95 latency > 150ms
}
# Efficient storage with ring buffers (memory-bounded)
self.metrics_history = deque(maxlen=10000) # ~1 week at 1 batch/minute
self.alerts = []
print(" Production monitoring initialized")
print(f" Thresholds: {self.thresholds}")
def log_batch(self, batch_metrics, accuracy=None, latencies=None):
"""
Record batch performance and check for issues
This gets called after every batch of queries is processed.
"""
timestamp = time.time()
# Create performance record
record = {
"timestamp": timestamp,
"edge_utilization": batch_metrics["edge_utilization"],
"total_cost": batch_metrics["batch_cost"],
"avg_complexity": batch_metrics.get("avg_complexity", 0),
"query_count": batch_metrics["total_queries"],
"accuracy": accuracy
}
# Add latency stats if provided
if latencies:
record.update({
"mean_latency": np.mean(latencies),
"p95_latency": np.percentile(latencies, 95),
"p99_latency": np.percentile(latencies, 99)
})
self.metrics_history.append(record)
# Check for alerts
alerts = self._check_alerts(record)
self.alerts.extend(alerts)
if alerts:
for alert in alerts:
print(f" ALERT: {alert}")
def _check_alerts(self, record):
"""Check current metrics against thresholds"""
alerts = []
# Edge utilization alert
if record["edge_utilization"] < self.thresholds["min_edge_utilization"]:
alerts.append(
f"Low edge utilization: {record['edge_utilization']:.1%} "
f"< {self.thresholds['min_edge_utilization']:.1%}"
)
# Accuracy alert
if record.get("accuracy") and record["accuracy"] < self.thresholds["min_accuracy"]:
alerts.append(
f"Low accuracy: {record['accuracy']:.3f} "
f"< {self.thresholds['min_accuracy']:.3f}"
)
# Cost alert
cost_per_query = record["total_cost"] / record["query_count"]
if cost_per_query > self.thresholds["max_cost_per_query"]:
alerts.append(
f"High cost per query: ${cost_per_query:.4f} "
f"> ${self.thresholds['max_cost_per_query']:.4f}"
)
# Latency alert
if record.get("p95_latency") and record["p95_latency"] > self.thresholds["max_p95_latency"]:
alerts.append(
f"High P95 latency: {record['p95_latency']:.1f}ms "
f"> {self.thresholds['max_p95_latency']}ms"
)
return alerts
def generate_health_report(self):
"""Generate comprehensive system health report"""
if not self.metrics_history:
return {"status": "No data available"}
# Analyze recent performance (last 100 batches or 24 hours)
now = time.time()
recent_cutoff = now - (24 * 3600) # 24 hours ago
recent_records = [
r for r in self.metrics_history
if r["timestamp"] > recent_cutoff
]
if not recent_records:
recent_records = list(self.metrics_history)[-100:] # Last 100 batches
# Calculate key metrics
total_queries = sum(r["query_count"] for r in recent_records)
total_cost = sum(r["total_cost"] for r in recent_records)
# Performance averages
avg_metrics = {
"edge_utilization": np.mean([r["edge_utilization"] for r in recent_records]),
"cost_per_query": total_cost / total_queries if total_queries > 0 else 0,
"avg_complexity": np.mean([r.get("avg_complexity", 0) for r in recent_records])
}
# Accuracy analysis (if available)
accuracy_records = [r["accuracy"] for r in recent_records if r.get("accuracy")]
if accuracy_records:
avg_metrics.update({
"current_accuracy": accuracy_records[-1],
"avg_accuracy": np.mean(accuracy_records),
"accuracy_trend": self._calculate_trend(accuracy_records[-10:])
})
# Latency analysis (if available)
latency_records = [r.get("p95_latency") for r in recent_records if r.get("p95_latency")]
if latency_records:
avg_metrics.update({
"current_p95_latency": latency_records[-1],
"avg_p95_latency": np.mean(latency_records),
"latency_trend": self._calculate_trend(latency_records[-10:])
})
# Recent alerts
recent_alert_count = len(self.alerts) if self.alerts else 0
# Overall health assessment
health_score = self._calculate_health_score(avg_metrics, recent_alert_count)
return {
"timestamp": now,
"period_analyzed": f"{len(recent_records)} batches ({total_queries:,} queries)",
"health_score": health_score,
"health_status": self._get_health_status(health_score),
"performance_metrics": avg_metrics,
"recent_alerts": recent_alert_count,
"recommendations": self._generate_recommendations(avg_metrics, recent_alert_count),
"cost_analysis": {
"total_cost_analyzed": total_cost,
"daily_cost_estimate": total_cost * (86400 / (24 * 3600)), # Scale to daily
"monthly_cost_estimate": total_cost * (86400 * 30 / (24 * 3600))
}
}
def _calculate_trend(self, values, min_samples=3):
"""Calculate if metrics are improving, stable, or declining"""
if len(values) < min_samples:
return "insufficient_data"
# Simple linear regression slope
x = np.arange(len(values))
slope = np.polyfit(x, values, 1)[0]
# Determine significance
std_dev = np.std(values)
threshold = std_dev * 0.1 # 10% of std dev
if abs(slope) < threshold:
return "stable"
elif slope > 0:
return "improving"
else:
return "declining"
def _calculate_health_score(self, metrics, alert_count):
"""Calculate overall system health (0-100)"""
score = 100
# Penalize based on metrics
if metrics["edge_utilization"] < 0.9:
score -= 10 # Edge utilization penalty
if metrics["edge_utilization"] < 0.8:
score -= 20 # Severe edge utilization penalty
if metrics.get("current_accuracy", 1.0) < 0.9:
score -= 15 # Accuracy penalty
if metrics.get("current_accuracy", 1.0) < 0.8:
score -= 30 # Severe accuracy penalty
# Alert penalty
score -= min(alert_count * 5, 30) # Max 30 point penalty for alerts
return max(0, score)
def _get_health_status(self, score):
"""Convert numeric health score to status"""
if score >= 90:
return "excellent"
elif score >= 75:
return "good"
elif score >= 60:
return "fair"
elif score >= 40:
return "poor"
else:
return "critical"
def _generate_recommendations(self, metrics, alert_count):
"""Generate actionable recommendations"""
recommendations = []
if metrics["edge_utilization"] < 0.8:
recommendations.append(
f"Low edge utilization ({metrics['edge_utilization']:.1%}): "
"Consider lowering complexity threshold or confidence threshold"
)
if metrics.get("current_accuracy", 1.0) < 0.85:
recommendations.append(
f"Low accuracy ({metrics.get('current_accuracy', 0):.3f}): "
"Review model performance and consider retraining"
)
if metrics["cost_per_query"] > 0.005: # > $0.005 per query
recommendations.append(
f"High cost per query (${metrics['cost_per_query']:.4f}): "
"Increase edge utilization to reduce costs"
)
if alert_count > 5:
recommendations.append(
f"High alert volume ({alert_count}): "
"Review alert thresholds and address underlying issues"
)
if not recommendations:
recommendations.append("System operating within normal parameters")
return recommendations
# Initialize monitoring
monitor = ProductionMonitor()
# Log our batch performance
monitor.log_batch(batch_metrics)
# Generate health report
health_report = monitor.generate_health_report()
print(f"
SYSTEM HEALTH REPORT:")
print(f" Health Status: {health_report['health_status'].upper()} ({health_report['health_score']}/100)")
print(f" Period: {health_report['period_analyzed']}")
print(f"
Key Metrics:")
for metric, value in health_report['performance_metrics'].items():
if isinstance(value, float):
if 'utilization' in metric:
print(f" {metric}: {value:.1%}")
elif 'cost' in metric:
print(f" {metric}: ${value:.4f}")
else:
print(f" {metric}: {value:.3f}")
else:
print(f" {metric}: {value}")
print(f"
Cost Analysis:")
for metric, value in health_report['cost_analysis'].items():
print(f" {metric}: ${value:.4f}")
print(f"
Recommendations:")
for i, rec in enumerate(health_report['recommendations'], 1):
print(f" {i}. {rec}")
构建:一个生产就绪的系统
现在,回过头来审视一下所取得的成就:
- 领域适应模型,能够理解客户服务语言。
- 尺寸缩小84%的量化模型,可在标准CPU硬件上运行。
- 智能路由器,在本地处理95%的查询。
- 生产监控系统,在问题影响用户之前捕获并解决。
以下是实际运行中的数据表现:
# Let's summarize our system's performance
print(" HYBRID EDGE-CLOUD AI SYSTEM PERFORMANCE")
print("=" * 50)
# Model compression results
fp32_size = benchmark_results["FP32 Original"]["model_size_mb"]
int8_size = benchmark_results["INT8 Quantized"]["model_size_mb"]
compression_ratio = (1 - int8_size/fp32_size) * 100
print(f" Model Compression:")
print(f" Original size: {fp32_size:.1f}MB")
print(f" Quantized size: {int8_size:.1f}MB")
print(f" Compression: {compression_ratio:.1f}%")
# Accuracy retention
fp32_acc = benchmark_results["FP32 Original"]["accuracy"]
int8_acc = benchmark_results["INT8 Quantized"]["accuracy"]
accuracy_retention = int8_acc / fp32_acc * 100
print(f"
Accuracy:")
print(f" Original accuracy: {fp32_acc:.3f}")
print(f" Quantized accuracy: {int8_acc:.3f}")
print(f" Retention: {accuracy_retention:.1f}%")
# Performance metrics
fp32_latency = benchmark_results["FP32 Original"]["mean_latency_ms"]
int8_latency = benchmark_results["INT8 Quantized"]["mean_latency_ms"]
print(f"
Performance:")
print(f" FP32 mean latency: {fp32_latency:.1f}ms")
print(f" INT8 mean latency: {int8_latency:.1f}ms")
print(f" FP32 P95 latency: {benchmark_results['FP32 Original']['p95_latency_ms']:.1f}ms")
print(f" INT8 P95 latency: {benchmark_results['INT8 Quantized']['p95_latency_ms']:.1f}ms")
# Routing and cost metrics
system_stats = router.get_system_stats()
print(f"
Routing Efficiency:")
print(f" Edge utilization: {system_stats['edge_utilization']:.1%}")
print(f" Cost savings: {system_stats['cost_savings_percent']:.1f}%")
print(f" Cost per query: ${system_stats['cost_per_query']:.6f}")
# System health
print(f"
System Health:")
print(f" Status: {health_report['health_status'].upper()}")
print(f" Score: {health_report['health_score']}/100")
print(f" Recent alerts: {health_report['recent_alerts']}")
print("
" + "=" * 50)
核心要点与后续步骤
本文构建了一个实用的系统:一个混合AI系统,它能够在边缘端提供云端级别的结果,同时实现边缘级别的成本和延迟。其成功的关键在于:
95/5法则:大多数客户查询都是常规的。一个经过良好调优的小型模型可以完美处理这些查询,只将真正复杂的案例留给云端处理。
无损压缩:动态INT8量化实现了84%的尺寸缩减,同时准确率损失极小,并且无需校准数据集。
智能路由:多维复杂度分析确保查询被路由到正确的位置,并基于正确的原因进行处理。
生产监控:针对关键指标的简单警报机制,确保系统在生产环境中保持健康。
下一步何去何从
从小处着手:首先将其部署到一部分流量上。在扩大规模之前,验证结果是否符合预期。
逐步调优:根据具体的质量与成本权衡,每周调整路由阈值。
深思熟虑地扩展:随着流量增长,增加更多的边缘节点。该架构支持水平扩展。
持续学习:监控路由决策和准确率趋势。数据将指导后续的优化工作。
更广阔的视角
这不仅仅适用于呼叫中心或客户服务领域。相同的模式适用于任何存在以下情况的场景:
- 大量常规请求与偶尔出现的复杂案例混合存在。
- 对成本和延迟有严格要求。
- 存在合规性或数据主权方面的担忧。
思考一下自身的AI应用。其中有多少是真正复杂的,又有多少是常规的?本文认为,大多数应用都遵循95/5法则,这使得它们成为这种混合方法的理想候选者。
AI的未来并非关乎模型越大越好,而是关于更智能的架构。构建更高效、数据归属清晰、成本可控的系统。
准备好亲自尝试了吗?本文提供了完整的代码。从自己的数据开始,按照设置说明操作,看看95/5法则在您的应用中如何体现。
*除非另有说明,所有图片均由作者提供。
参考文献与资源
- 研究论文:“边缘与云端联络中心部署的比较分析:技术与架构视角” – IEEE ICECCE 2025
- 完整Notebook:本文所有代码均可作为一个可复现的Jupyter Notebook获取
- 环境规格:Intel Xeon Silver 4314, 64GB RAM, Ubuntu 22.04, Python 3.10
此处描述的系统代表独立研究,不隶属于任何雇主或商业实体。结果可能因硬件、数据特性和领域特定因素而异。