

作者: Antoni Olbrysz, Karol Struniawski, Tomasz Wierzbicki
目录
1. 引言
花粉分类是视觉图像识别领域一个引人入胜的课题,在生态学和生物技术等多个领域具有广泛的应用价值,例如植物种群研究、气候变化分析以及花粉结构探索。然而,尽管其重要性,该领域仍相对未被充分探索。目前用于花粉图像的公开数据集数量稀少,且现有数据往往存在不足或质量欠佳,难以有效支持成熟的视觉分类器或目标检测器的训练,尤其对于包含多种花粉混合物的图像更是如此。除了提供一个先进的视觉识别模型,本项目还旨在通过构建一个定制数据集来弥补这一空白。在没有机器视觉辅助的情况下,花粉的视觉分类常常难以解决,因为现代生物学家仅凭图像通常难以区分不同植物种类的花粉。这使得在花粉颗粒来源未知的情况下,快速高效地识别采集到的花粉成为一项极其具有挑战性的任务。
1.1 现有花粉图像数据集
本节将重点介绍几个免费可用数据集的参数,并将其与定制数据集的特性进行比较。
数据集 1
链接:https://www.kaggle.com/datasets/emresebatiyolal/pollen-image-dataset
类别数量: 193
每类图像数量: 1-16
图像质量: 分离清晰的图像,有时带有标注
图像颜色: 多样
备注: 该数据集似乎由来自多个来源的不一致图像组成。虽然类别广泛,但每个类别仅包含少量照片,不足以训练任何图像检测模型。
数据集 2
链接:https://www.kaggle.com/datasets/andrewmvd/pollen-grain-image-classification
类别数量: 23
每类图像数量: 35,其中一个类别为20
图像质量: 分离良好,略模糊,图像上无文字
图像颜色: 未着色,一致
备注: 这是一个针对巴西稀树草原花粉分类的局部化、精心准备的数据集。图像来源一致,但每类图像数量可能在追求高精度时带来挑战。
数据集 3
链接:https://www.kaggle.com/datasets/nataliakhanzhina/pollen20ldet
类别数量: 20
每类图像数量: 极多
图像质量: 自解释图像,包含分离和连接的花粉图像
图像颜色: 染色,一致
备注: 数量庞大、标注良好、一致且高质量的图像使该数据集质量极高。然而,图像中存在的染色可能在特定应用中成为问题。此外,花粉的放大倍数和相互交叉的能力可能在混合花粉场景中造成困难。
2. 新花粉图像数据集
本项目所创建的数据集收集了四种常见水果植物花粉的高质量显微镜图像,包括欧洲醋栗、忍冬莓、黑加仑和唐棣。这些植物种类此前并未包含在任何数据集中,因此本项目的数据集为视觉花粉分类贡献了新的数据。
每个类别包含约200张多粒花粉图像,且所有图像均未染色。这些数据是与位于波兰斯基埃尔涅维采的国家园艺研究所合作获得的。
- 类别数量: 5 (4种花粉 + 混合花粉)
- 每类图像数量: 约200张
- 图像质量: 图像清晰,包含多个花粉片段,存在混合图像
- 图像颜色: 未染色,一致
本项目数据集侧重于本地可获得的花粉、类别平衡以及充足的训练图像数量,且未添加可能导致分类器不适用于某些任务的染料。此外,所提出的解决方案包含不同花粉类型混合的图像,有助于训练用于野外采集应用的目标检测模型。数据集中的示例图像如图1至图4所示。
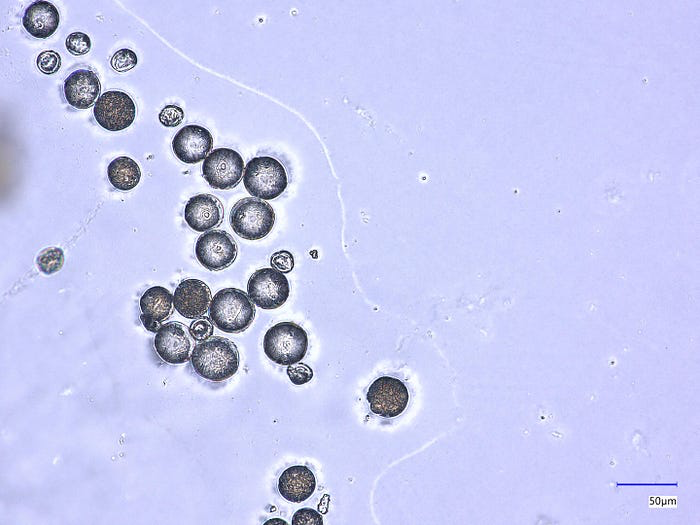
图1 — 数据集中的一个示例图像——欧洲醋栗类别。
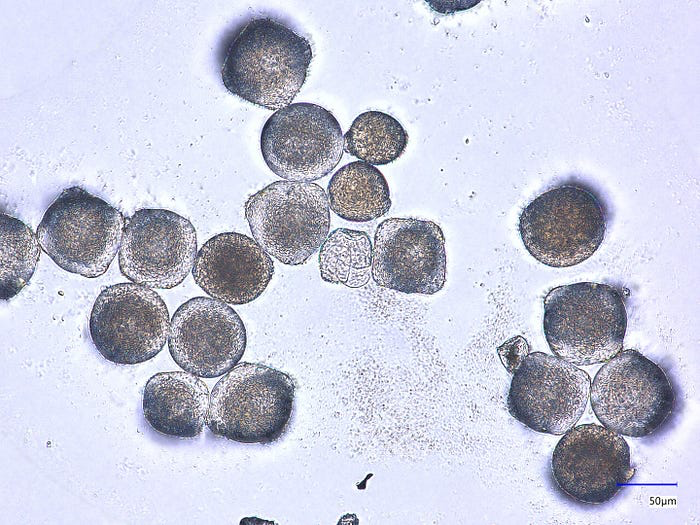
图2 — 数据集中的一个示例图像——忍冬莓类别。
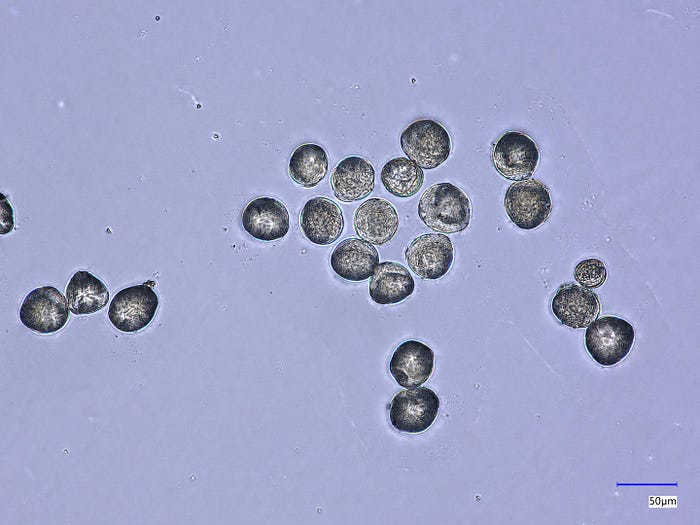
图3 — 数据集中的一个示例图像——黑加仑类别。
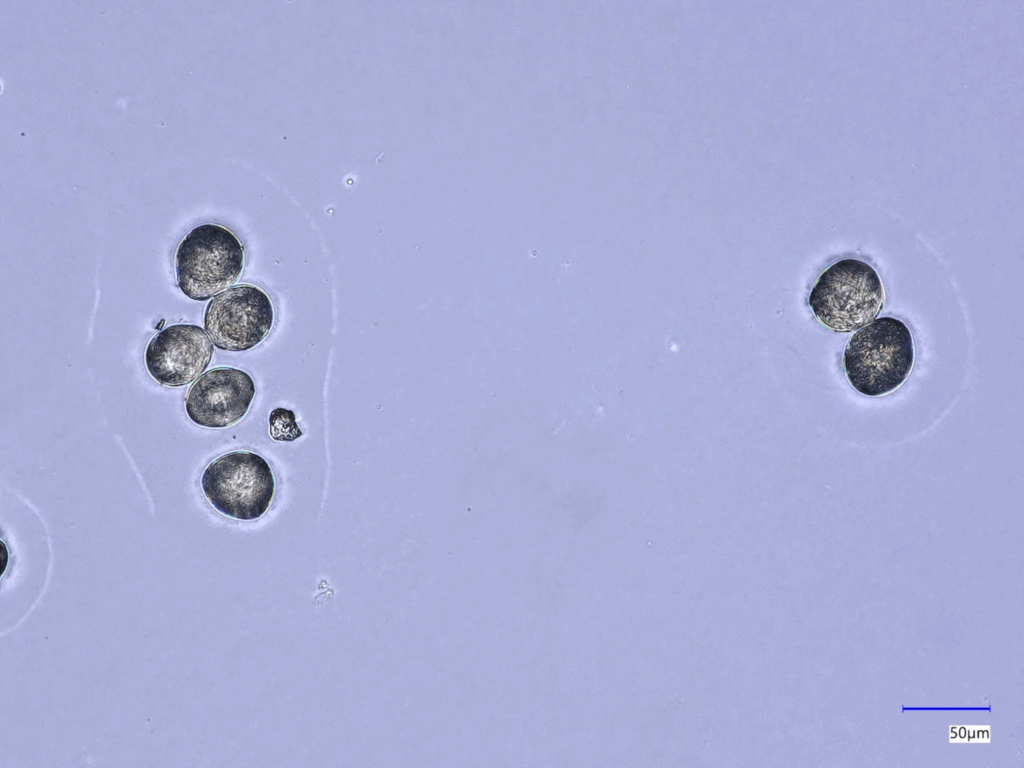
图4 — 数据集中的一个示例图像——唐棣类别。
完整的花粉数据集可根据合理请求从通讯作者处获取。数据采集步骤包括样本制备和显微图像拍摄,这些工作由国家园艺研究所应用生物学系的Agnieszka Marasek-Ciołakowska教授和Aleksandra Machlańska女士完成,对此表示由衷感谢。她们的努力对本项目取得成功至关重要。
为了训练各种模型识别花粉,研究人员首先从数据集中的照片中提取了单个花粉图像。每张照片都包含多粒花粉以及其他生物和污染物,这使得识别花粉种类变得更加困难。研究人员采用了YOLOv12模型,这是一种由Ultralytics开发的尖端、注重注意力的实时目标检测模型。
3.1 YOLOv12微调
得益于YOLOv12的创新特性,即使在小型数据集上也能进行训练。为了准备自己的数据集,研究人员使用CVAT工具,手动标注了数据集中四个类别中每类十张图像上的花粉位置,随后将这些标注导出为与单个图像对应的.txt文件。接着,将数据整理成YOLOv12适用的格式:将数据划分为训练集(每类7对图像-标注,共28对)和验证集(每类3对图像-标注,共12对)。此外,还添加了一个指向数据集的.yaml文件。值得注意的是,该数据集确实非常小。在预测模式下,模型检测到的单个花粉及其置信度叠加结果如图5所示。研究人员还从YOLOv12官网下载了模型(YOLO12s),随后开始了训练。

该模型被证明能以非常高的精度检测花粉,但还有一个因素需要考虑:模型的置信度。对于每个检测到的花粉,模型还会输出一个表示其预测特异性的值。研究人员必须决定是使用较低的置信度阈值(图像更多,但畸形或非花粉照片的风险更高)还是较高的阈值(图像更少,但非花粉的几率更低)。最终,研究人员决定尝试0.8和0.9两个阈值,以评估哪个在训练分类模型时效果更好。
3.2 导出单花粉数据集
为了导出单花粉数据集,研究人员对数据集中的所有特定类别图像运行了模型的预测。这一过程非常顺利,但在导出后,研究人员遇到了另一个问题——即使在较高的阈值下,一些照片仍然被裁剪。因此,在导出单个花粉图像之前,研究人员增加了一个步骤:消除了宽高比不协调的图像(如图6所示的示例)。具体来说,当较短边除以较长边的比值低于0.8时,这些图像会被剔除。

随后,研究人员将所有图像调整为224×224像素,这是深度学习模型输入图像的标准尺寸。
3.3 单花粉数据集 — 简要分析
最终得到了两个数据集,一个使用0.8置信度阈值生成,另一个使用0.9阈值生成:
- 0.8 阈值数据集:
- 欧洲醋栗 — 7788 张图像
- 忍冬莓 — 3582 张图像
- 黑加仑 — 4637 张图像
- 唐棣 — 4140 张图像
总计 — 20147 张图像
- 0.9 阈值数据集:
- 欧洲醋栗 — 2301 张图像
- 忍冬莓 — 2912 张图像
- 黑加仑 — 2438 张图像
- 唐棣 — 1432 张图像
总计 — 9083 张图像
从这些数字可以迅速看出,0.9阈值数据集的大小是0.8阈值数据集的两倍以上。两个数据集都不平衡——0.8阈值数据集主要是由于欧洲醋栗的数量,而0.9阈值数据集则主要是由于唐棣的数量。
YOLOv12被证明是有效工具,尽管遇到了一些困难,仍能将图像分割成两个单花粉图像数据集。新创建的数据集可能存在不平衡,但其规模应该能够弥补这一缺点,特别是每个类别都有广泛的代表。这些数据集在未来训练分类模型方面具有巨大潜力,具体效果仍需进一步验证。
4. 单花粉图像分类
4.1 模型评估指标概述
为了正确地训练模型,无论是基于统计特征的传统模型,还是卷积神经网络或Vision Transformer等更复杂的方法,都必须设计相应的性能评估指标。多年来,人们已经开发了许多方法来完成这些任务——从F1分数、精确率或召回率等统计度量,到GradCAM等更具视觉性的指标,它们能够更深入地洞察模型的内部工作原理。本文将探讨模型所使用的评估方法,但不会深入不必要的细节。
召回率
召回率被描述为某一类别正确预测数量与该类别总预测数量之比(参见公式1)。它衡量的是被标记为某一类别的图像中,实际属于该类别的百分比。由于其针对单个类别进行计算,因此在平衡和不平衡数据集中均能发挥作用。

公式1— 召回率公式。
精确率
与召回率不同,精确率是所有属于该类别的项目中,正确标记的项目所占的百分比(参见公式2)。它衡量的是一个类别中被正确预测的项目百分比。这个指标的表现与召回率相似。

公式2 — 精确率公式。
F1 分数
F1分数简单来说就是精确率和召回率的调和平均值(参见公式3)。它有助于将精确率和召回率结合成一个简洁的度量。因此,即使在不平衡的数据集上,它的表现依然出色。

公式3 — F1分数公式。
混淆矩阵
混淆矩阵是一种视觉度量,用于比较某一类别所做的预测数量与该类别实际图像数量之间的关系。它有助于说明模型所犯的错误,特别是在模型可能只对特定类别存在困难时(参见图7)。
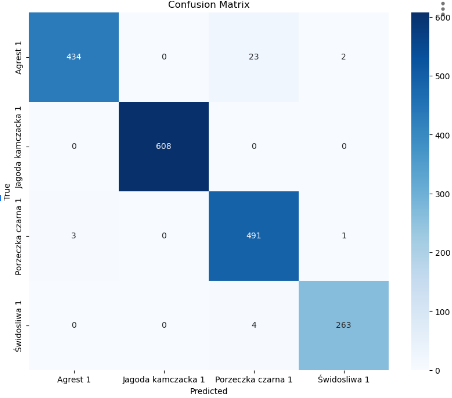
图7 — 混淆矩阵的示例。
GradCAM
GradCAM是一种评估CNN性能的方法,它将图像中影响预测的区域可视化。为此,该方法计算一个卷积层的梯度,并确定一个激活图,该激活图会视觉上叠加在图像之上。它极大地有助于理解和解释模型将特定图像标记为特定类别的“原因”(参见图8中的示例)。

图8 — 显示狗图像的GradCAM示例。
这些指标仅仅是机器学习中众多测量和可视化方法中的一小部分。然而,它们已被证明足以衡量模型性能。在后续文章中,将根据所使用和引入的新分类器相应地提及其他指标。
4.2 使用标准模型进行单花粉分类
在图像预处理完成后,研究人员可以进入下一阶段:将单个花粉分类到其物种。研究人员尝试了三种方法——基于图像提取特征的标准简单分类器、卷积神经网络和Vision Transformer。本文概述了在标准模型方面的工作,包括kNN分类器、SVM、MLP和随机森林。
特征提取
为了使分类器发挥作用,研究人员首先必须获取它们可以作为预测基础的特征。研究人员选择了两种主要类型的特征。第一种是基于特定图像中具有特定颜色(RGB模型中的一种)像素存在情况的统计度量,例如均值、标准差、中位数、分位数、偏度和峰度——研究人员为每个颜色层提取了这些特征。另一种是GLCM(灰度共生矩阵)特征:对比度、相异性、同质性、能量和相关性。这些特征是从灰度转换后的图像中获得的,并在不同角度下提取。每张图像有21个统计特征和20个基于GLCM的特征,总计每张图像有41个特征。
k-近邻 (kNN)
kNN是一种使用数据空间表示来通过检测特征的k个最近邻居来分类数据的分类器。该分类器速度快,但其他方法在性能上优于它。
kNN指标:
0.8阈值数据集:
F1: 0.6454
精确率: 0.6734
召回率: 0.6441
0.9阈值数据集:
F1: 0.6961
精确率: 0.7197
召回率: 0.7151
支持向量机 (SVM)
与kNN类似,SVM也将数据表示为多维空间中的点。但它不是寻找最近邻居,而是尝试通过算法用超平面分离数据。这比kNN产生了更好的结果,但引入了随机性,并且仍然被其他解决方案超越。
SVM指标:
0.8阈值数据集:
F1: 0.6952
精确率: 0.7601
召回率: 0.7025
0.9阈值数据集:
F1: 0.8556
精确率: 0.8687
召回率: 0.8597
多层感知机 (MLP)
多层感知机是一种受人脑及其神经元启发的模型。它将输入通过一个由具有自身独立权重的神经元层组成的网络,这些权重在训练过程中会发生改变。当经过良好优化时,这种模型有时可以作为标准分类器取得出色的结果。然而,花粉识别并非其中之一——它与其他解决方案相比表现不佳且不稳定。
MLP指标:
0.8阈值数据集:
F1: 0.8131
精确率: 0.8171
召回率: 0.8173
0.9阈值数据集:
F1: 0.7841
精确率: 0.8095
召回率: 0.7940
随机森林
随机森林模型以其可解释性而闻名——它基于决策树,通过阈值对数据进行分类,这使得人类比分析神经网络中的权重更容易理解。随机森林表现相当不错且稳定——研究人员发现200棵树是最佳配置。然而,它仍然被更复杂的分类器超越。
随机森林指标:
0.8阈值数据集:
F1: 0.8211
精确率: 0.8210
召回率: 0.8233
0.9阈值数据集:
F1: 0.8150
精确率: 0.8202
召回率: 0.8216
经典模型表现出不同的性能水平——一些模型的表现低于预期,而另一些则提供了相当不错的指标。然而,这并非终点。研究人员仍有先进的深度学习模型需要尝试,例如卷积神经网络和Vision Transformer。预计它们将表现出显著更好的性能。
4.3 使用卷积神经网络进行单花粉分类
在单花粉分类中,MLP、随机森林或SVM等经典模型产生了平庸到相当不错的结果。然而,研究人员决定尝试的下一个方法是卷积神经网络(CNNs)。这些模型通过处理图像生成特征,并以其有效性而闻名。
研究人员没有从头开始训练CNNs,而是使用了迁移学习技术——采用预训练模型,特别是ResNet50和ResNet152,并对其进行了微调以适应本项目的数据集。这种方法显著加快了训练速度,降低了资源需求。由于模型已经在大型数据集上进行了专业训练,它还能实现更有效的分类。在训练之前,还需要对图像进行归一化处理。
在评估指标方面,除了F1分数、精确率和召回率等标准指标外,研究人员还使用了Grad-CAM,这是一种试图突出图像中对模型预测影响最大的区域的方法。此外,还加入了混淆矩阵,以观察CNN是否在任何特定类别上存在困难。
ResNet50
ResNet50是由微软亚洲研究院于2015年开发的一种CNN架构,是创建更深、更高效神经网络的重要一步。它是一种残差网络(因此得名ResNet),利用跳跃连接实现数据流的直接传输。这反过来又缓解了梯度消失问题。
研究人员曾预计该模型的性能会低于ResNet152,但实际结果却出乎意料。该模型在两个数据集上的预测水平与ResNet152不相上下,如以下列出的指标和混淆矩阵(参见图9和图10),以及Grad-Cam可视化(参见图11)所示。
ResNet50指标:
0.8阈值数据集:
F1: 0.98
精确率: 0.98
召回率: 0.98
0.9阈值数据集:
F1: 0.99
精确率: 0.99
召回率: 0.99
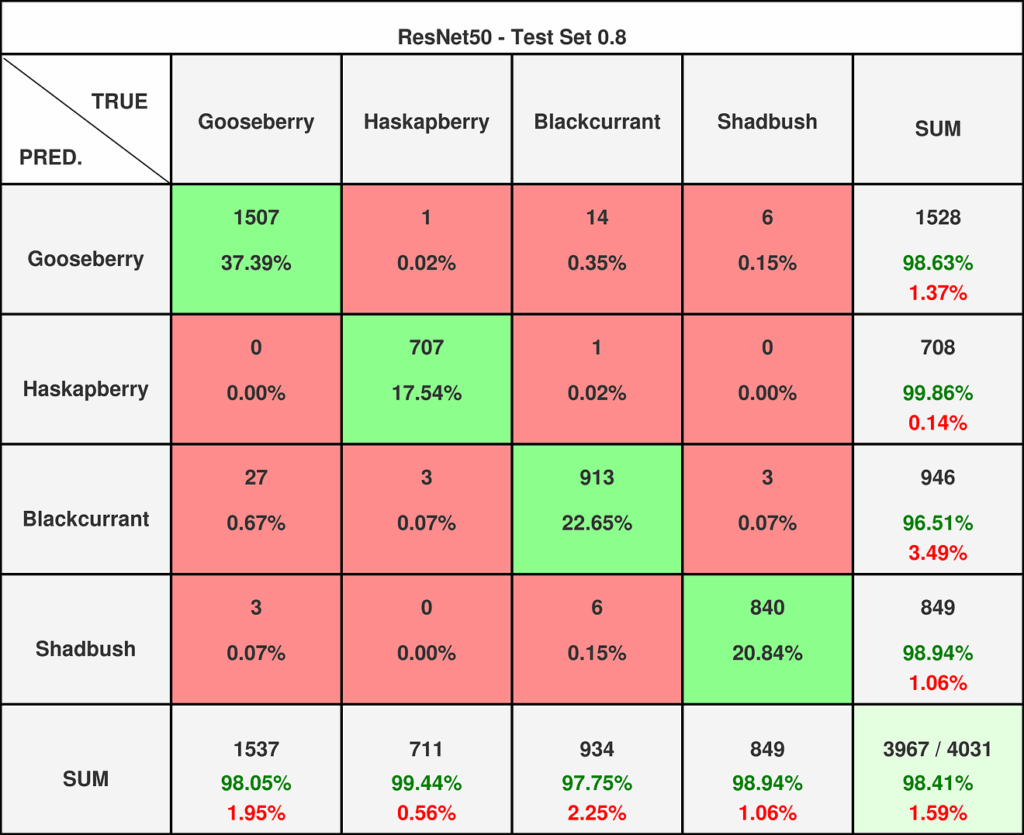
图9 — ResNet50在0.8阈值数据集上的混淆矩阵。
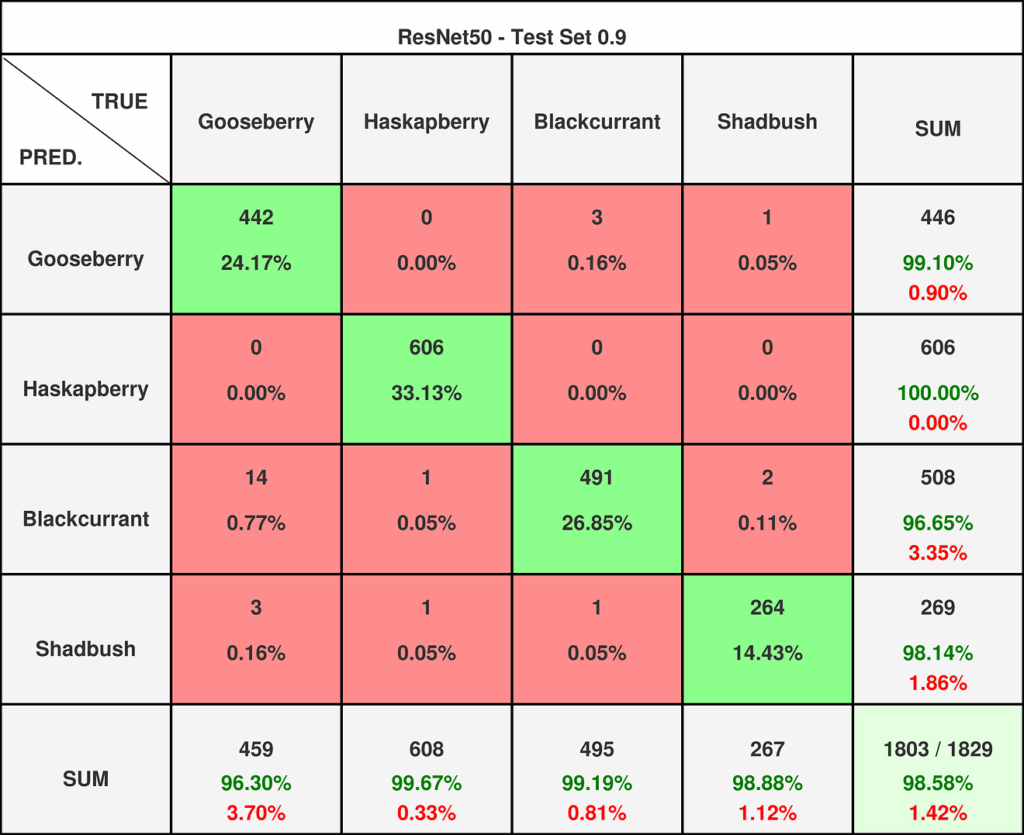
图10 — ResNet50在0.9阈值数据集上的混淆矩阵。如图所示,两个数据集中将欧洲醋栗误分类为黑加仑的问题都微乎其微。
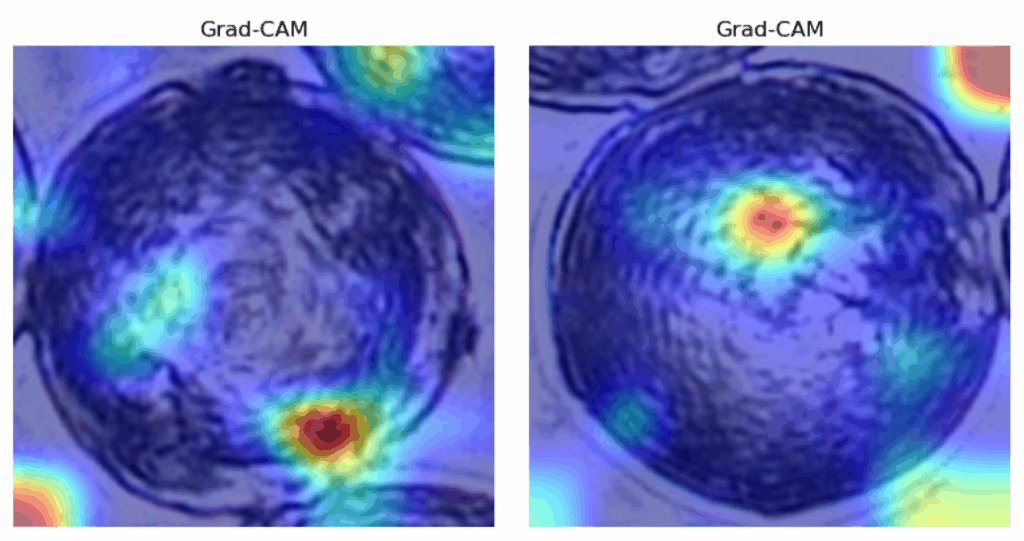
图11 — Grad-CAM在0.8和0.9阈值数据集随机图像上的结果。
关于Grad-CAM,它并没有提供关于模型内部工作原理的任何有价值的见解——高亮区域包括背景和看似随机的位置。由于它实现了非常高的准确性,该网络似乎注意到了人眼无法检测到的模式。
ResNet152
ResNet152同样是微软研究人员的成果,它是一种残差网络和CNN架构,具有显著的深度和远超ResNet50的深度学习能力。
因此,研究人员对该模型的期望高于ResNet50。然而,其表现与ResNet50持平,这令人有些意外。尽管如此,该模型的表现依然非常出色(参见包含混淆矩阵的图12和图13,以及包含Grad-Cam可视化的图14)。
ResNet152指标:
0.8阈值数据集:
F1: 0.98
精确率: 0.98
召回率: 0.98
0.9阈值数据集:
F1: 0.99
精确率: 0.99
召回率: 0.99
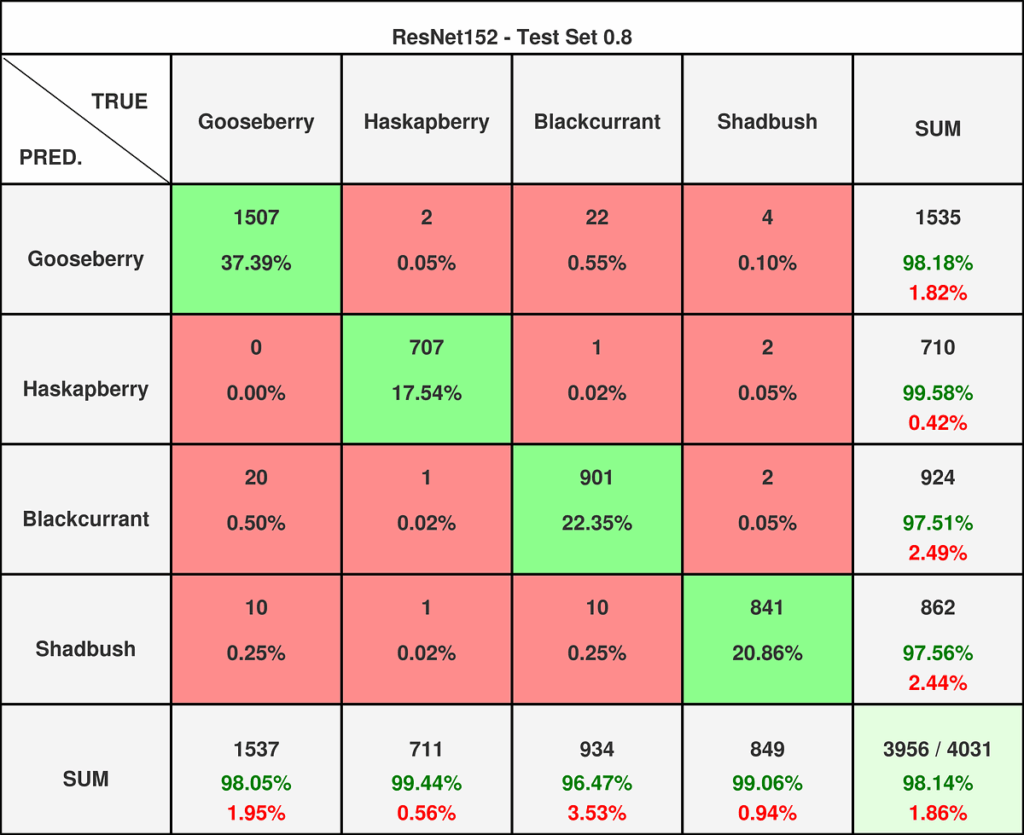
图12 — ResNet152在0.8阈值数据集上的混淆矩阵。
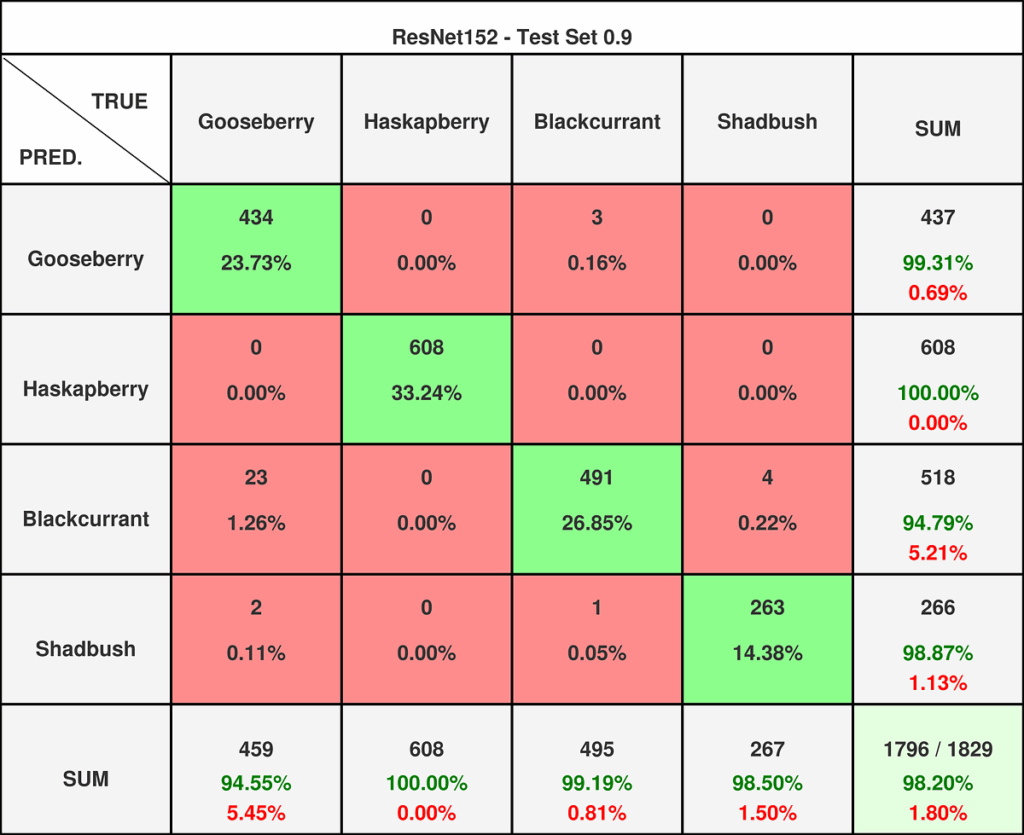
图13 — ResNet152在0.9阈值数据集上的混淆矩阵。ResNet152在0.8阈值数据集上对多个类别存在轻微问题,但在0.9阈值数据集上仅表现出与ResNet50相同的问题。
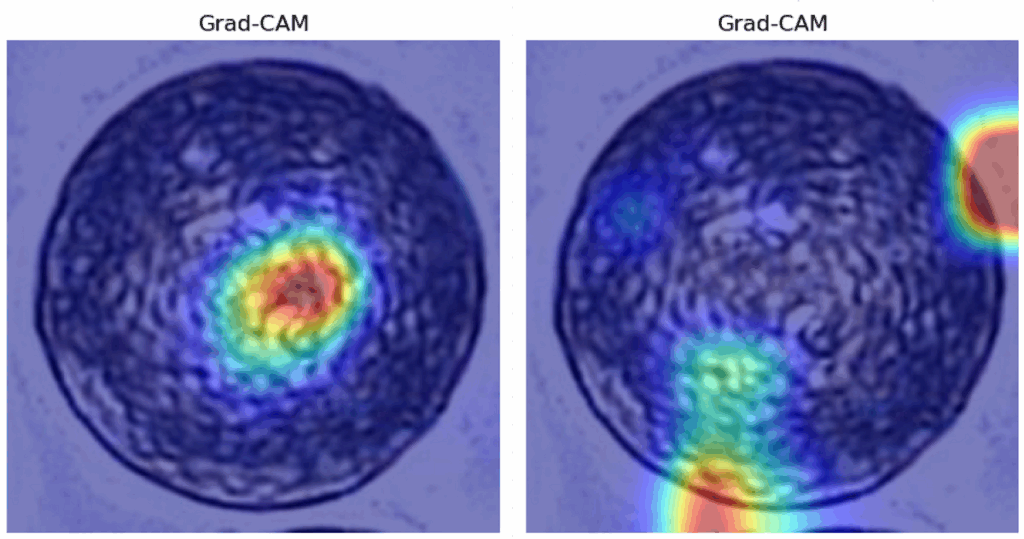
对于ResNet152,Grad-CAM同样没有提供有益的帮助——研究人员再次体验了深度学习模型的神秘本质,它们能实现高精度,但难以轻易解释。
研究人员惊讶地发现,更复杂的ResNet152在0.9数据集上并未超越ResNet50。两者都取得了目前尝试过的所有模型中的最高指标——它们超越了经典模型,最佳经典模型与CNNs之间的差距超过10个百分点。现在是时候测试最具创新性的模型——Vision Transformer了。
4.4 使用Vision Transformer进行单花粉分类
对于单花粉分类,研究人员首先尝试了简单模型,它们提供了从不足到令人满意不同程度的性能。随后,又引入了卷积神经网络,其性能完全超越了简单模型。现在是时候尝试名为Vision Transformer的创新模型了。
Transformer模型起源于谷歌研究人员2017年发表的著名论文《Attention Is All You Need》,但最初主要用于自然语言处理。2020年,Transformer架构被应用于计算机视觉领域,催生了Vision Transformer(ViT)。其卓越的性能标志着卷积神经网络在该领域统治地位的终结。
研究人员在此处采用的方法与训练CNN时类似。导入了一个预训练模型:vit-base-patch16–224-in21k,该模型在ImageNet-21k上进行过训练。然后,对数据集图像进行归一化,再进行微调,并记录了指标和混淆矩阵的结果(参见图15和图16)。
vit-base-patch16–224-in21k 结果:
0.8阈值数据集:
F1: 0.98
精确率: 0.98
召回率: 0.98
0.9阈值数据集:
F1: 1.00
精确率: 1.00
召回率: 1.00
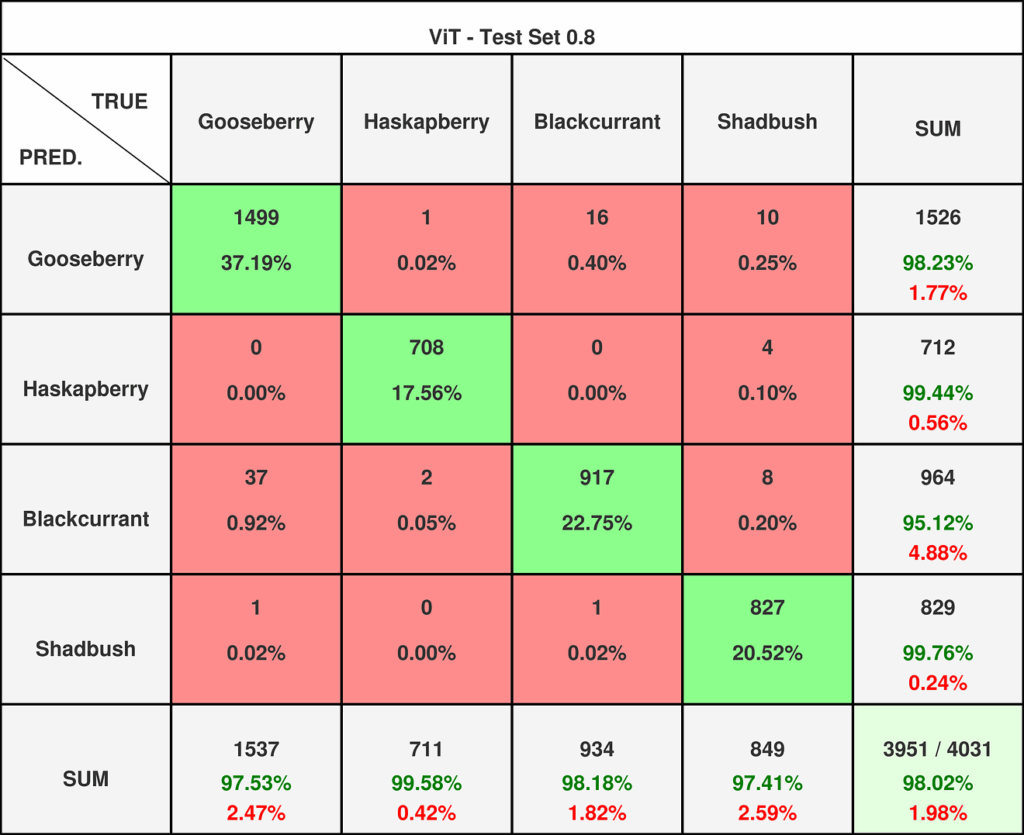
图15 — Vision Transformer在0.8阈值数据集上的混淆矩阵。
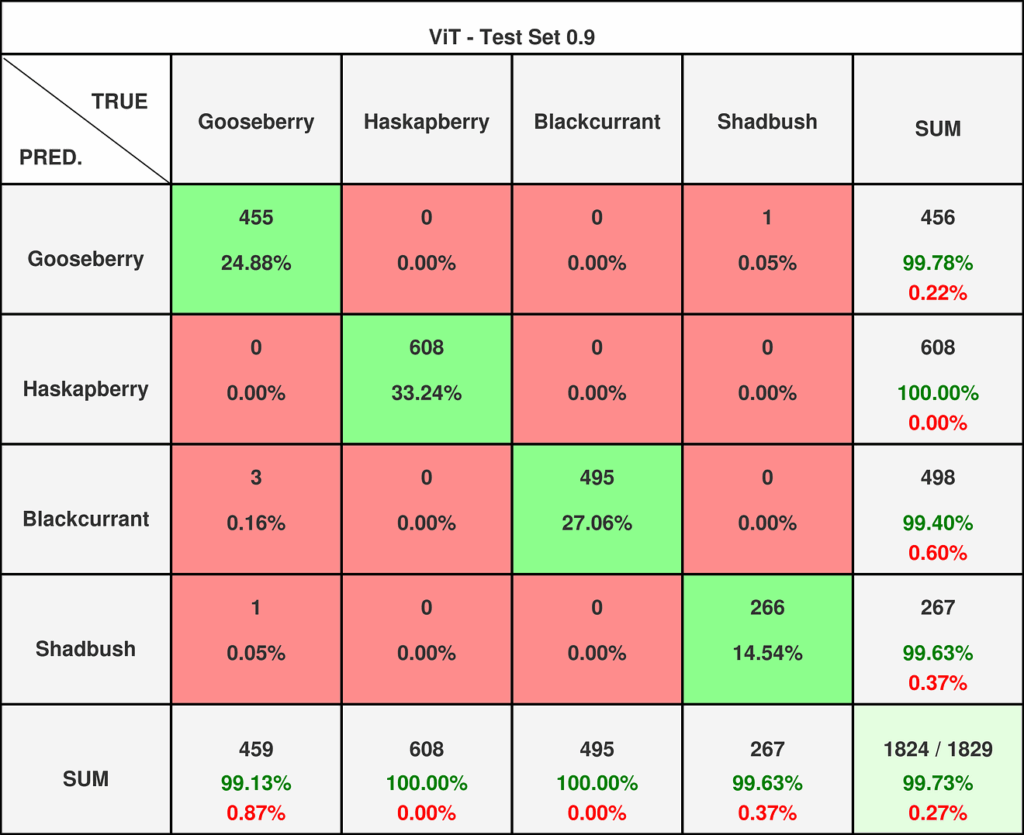
在0.8数据集上,Vision Transformer的性能并未超越残差网络,并且面临着类似的问题——将欧洲醋栗误分类为黑加仑。然而,在0.9数据集上,它取得了近乎完美的得分。这展示了创新技术超越传统解决方案的强大力量。
4.5 各模型指标比较
在花粉分类任务中,研究人员使用了多种模型:包括kNN、SVM、MLP和随机森林等传统模型;卷积神经网络(ResNet50和ResNet152);以及Vision Transformer(vit-base-patch16–224-in21k)。本文旨在对这些模型的性能进行概述和排名(参见表1)。
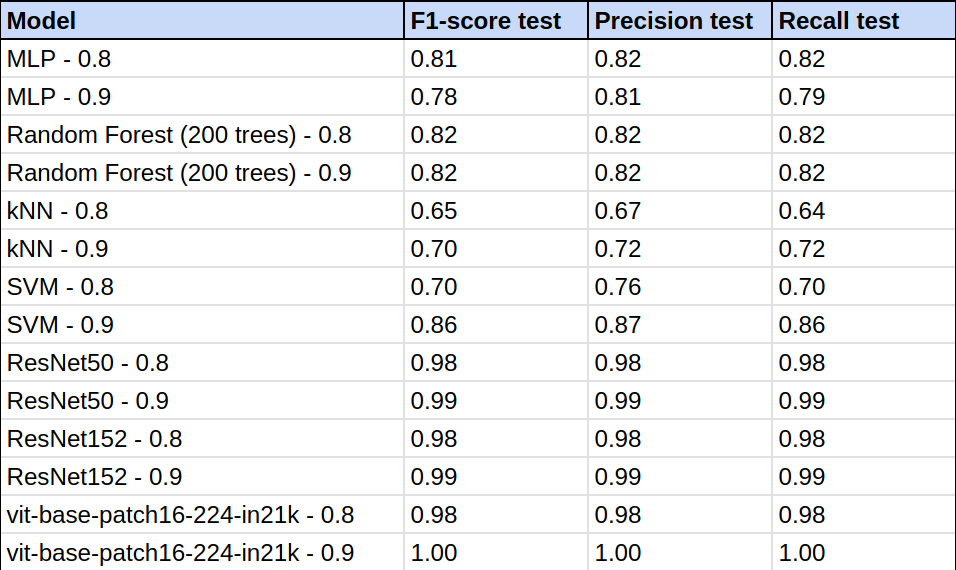
表1 — 所有测试模型的性能指标。
排名
- kNN (k-近邻)
最简单的分类器。正如预期,训练速度快,但性能最差。
- MLP (多层感知机)
该模型的架构基于人类神经系统。MLP的性能被其他标准模型超越,这出乎意料。
- RF (随机森林)
随机森林分类器在所有模型中表现出最高的稳定性,但其指标远非理想。
- SVM (支持向量机)
传统分类器中的意外赢家。其性能虽然存在随机性,但在0.9数据集上作为标准分类器取得了不错的结果。
- ResNet50 和 ResNet152 (残差网络)
两种架构凭借其复杂性,在两个数据集上的能力都远超任何标准分类器,并取得了同样优异的结果。
- ViT (Vision Transformer)
这项最具创新性的解决方案超越了经典模型,并在0.8数据集上追平了残差网络。然而,真正的挑战是0.9数据集,在该数据集上CNN的准确率达到了0.99,而Vision Transformer的结果如此之高,以至于被四舍五入到1.00——一个完美的得分。其结果是创新力量的真实体现。
注:分类报告对模型的指标进行了四舍五入——它们并非完全等于1,因为那意味着所有图像无一例外地被正确分类。研究人员之所以采用这个值,是因为只有极少数五张图像(0.27%)被错误分类。
通过比较视觉花粉识别领域中的不同分类器,研究人员亲身体验了机器学习的历史和演变。从最简单的分类器到基于注意力机制的Vision Transformer,模型创新程度的提高伴随着结果的显著提升。基于这一比较,ViT被一致选定为处理花粉任务的首选模型。
5. 结论
视觉花粉分类这项长期困扰全球生物学家、超越人类能力的任务,最终借助机器学习的力量被证明是可行的。本文中提出的所有模型都展示了分类花粉的潜力,并具有不同程度的准确性。某些模型,如CNN和Vision Transformer,甚至达到了近乎完美的精度,以人类前所未见的精准度识别花粉。
为了更好地理解这一成就的非凡之处,可以通过图17进行说明。
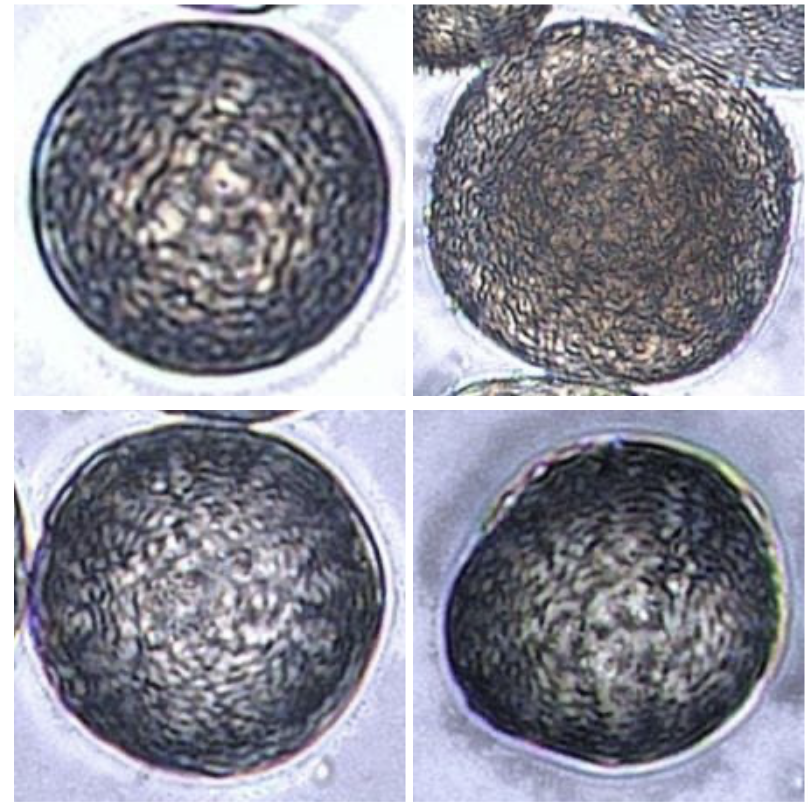
很有可能大多数读者无法将这些图像正确分类到前述的四个类别中。然而,研究人员训练的模型却能以近乎完美的准确率识别它们,最高F1分数超过99%。
人们可能会好奇这种分类器有何用途,或者为何要对其进行训练。这种方法的应用前景广泛,从追踪植物种群到局部测量空气中过敏原水平。本项目旨在不仅为植物学专家提供一个用于分类所采集花粉的工具,还为其他机器学习爱好者提供一个可供在此基础上进一步研究的平台,并展示该领域不断扩展的应用。
至此,本文内容结束。真诚希望读者能在研究工作中发现这些信息有所助益,并且这些文章能为使用该技术启发新的项目思路。






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}