

千问再次重磅发布!Qwen3-VL-30B-A3B模型现已开源,仅需两张4090显卡即可运行,无疑为个人开发者和研究者带来了巨大便利!
近期,千问团队再次开源了Qwen3-VL-30B-A3B多模态模型,并提供了Instruct和Thinking两个版本。Qwen团队的持续创新回应了社区对高效、可部署多模态模型的强烈期待。

同时,该模型还提供了对应的FP8量化版本,这意味着仅需两张4090显卡就能高效运行,极大地降低了硬件门槛,真正实现了“平民福利”。
模型已在Hugging Face平台发布:https://huggingface.co/collections/Qwen/qwen3-vl-68d2a7c1b8a8afce4ebd2dbe
Qwen3-VL-30B-A3B模型的结构细节,可参考此前的文章:等了大半年的Qwen3-VL终于也开源了!附模型细节&实测!
从整体榜单来看,Qwen3-VL-30B-A3B-Instruct版本在多项指标上表现优于Qwen2.5-VL-72B-Instruct。
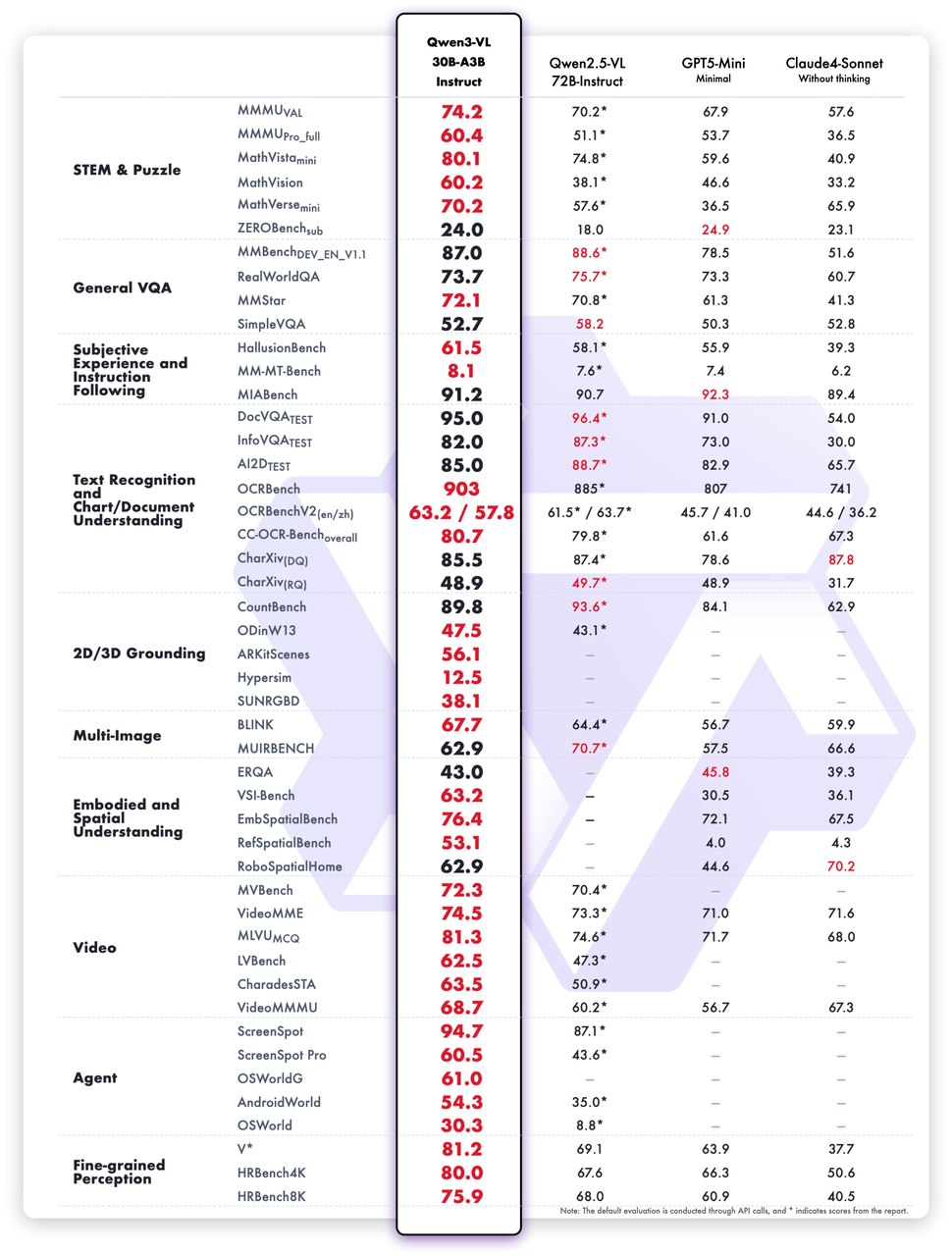
以下是Qwen3-VL-30B-A3B的实测结果速览:
- Qwen3-VL-30B-A3B模型的整体智能水平相较于Qwen3-VL-235B-A22B存在差距,这是由于两者的参数量和激活量不同所致。
- 与Qwen3-VL-30B-A3B Instruct版本相比,Thinking版本的图像理解和计算能力更强。
- 表格识别能力有待提升。
- 图片排序方面,Thinking版本表现较强,Instruct版本则相对较弱。
- 数学解题能力突出,在某些方面甚至超越了Qwen3-30B-A3B。
- 网页复刻表现仍不理想。
- 色盲测试中,模型即使将图片翻转也能正确识别。
OCR识别
为考察多模态大模型的内容提取能力,本次测试采用了手写体,以增加难度。
Prompt:请识别图中的文本内容,言简意赅。
Qwen3-VL-30B-A3B:回答正确

内容理解
此项测试旨在考察多模态大模型提取图片内容并进行深层理解的能力。
Prompt:我今天喝了这个果汁会怎么样

Qwen3-VL-30B-A3B:回答正确

表格识别
本环节考察多模态大模型的内容提取和指令跟随能力,要求将表格图片用HTML格式进行还原。
Qwen3-VL-30B-A3B:回答错误
网页复刻
本测试旨在考察多模态大模型的网页还原、审美及代码生成能力。
Prompt:请帮我1:1还原这个网页内容,用HTML呈现。
Qwen3-VL-30B-A3B:表现不佳,生成内容存在一些奇怪之处。
报告分析
此测试考察多模态大模型的内容理解能力及知识储备能力。
Prompt:请帮我解读一下报告内容。
Qwen3-VL-30B-A3B:解读正确

理解计算
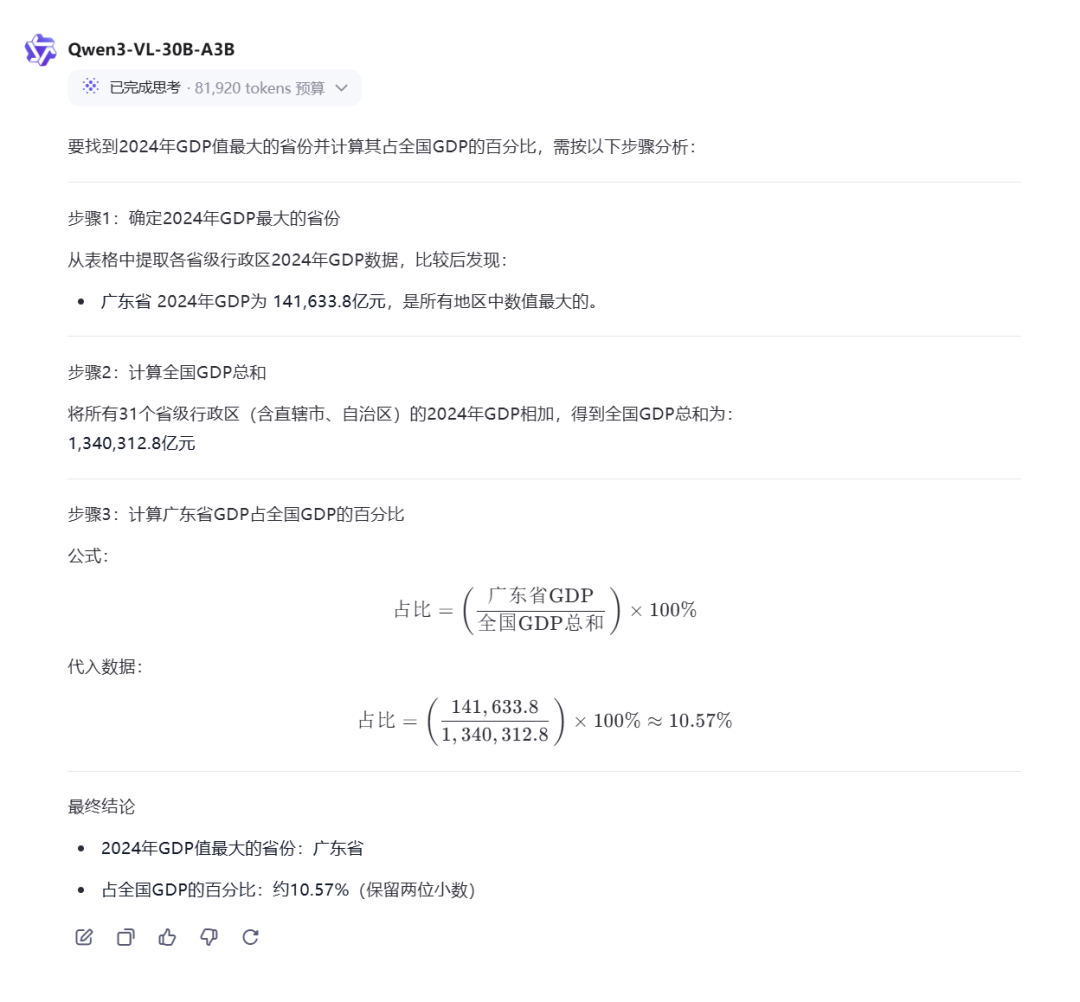
本环节考察多模态大模型的内容理解与计算能力。
Prompt:找到2024年GDP值最大的省份,并且计算占全国GDP的百分之多少?
2024年总和=1340312.8
Qwen3-VL-30B-A3B-Instruct:识别出广东为GDP最大的省份,但最终计算结果错误。

Qwen3-VL-30B-A3B-Thinking:回答完全正确。
目标识别
此测试考察多模态模型对事物的识别能力,包括判断事物是否准确或清点物品数量。
Prompt:告诉我桌子上菇娘儿的个数。
Qwen3-VL-30B-A3B:回答正确

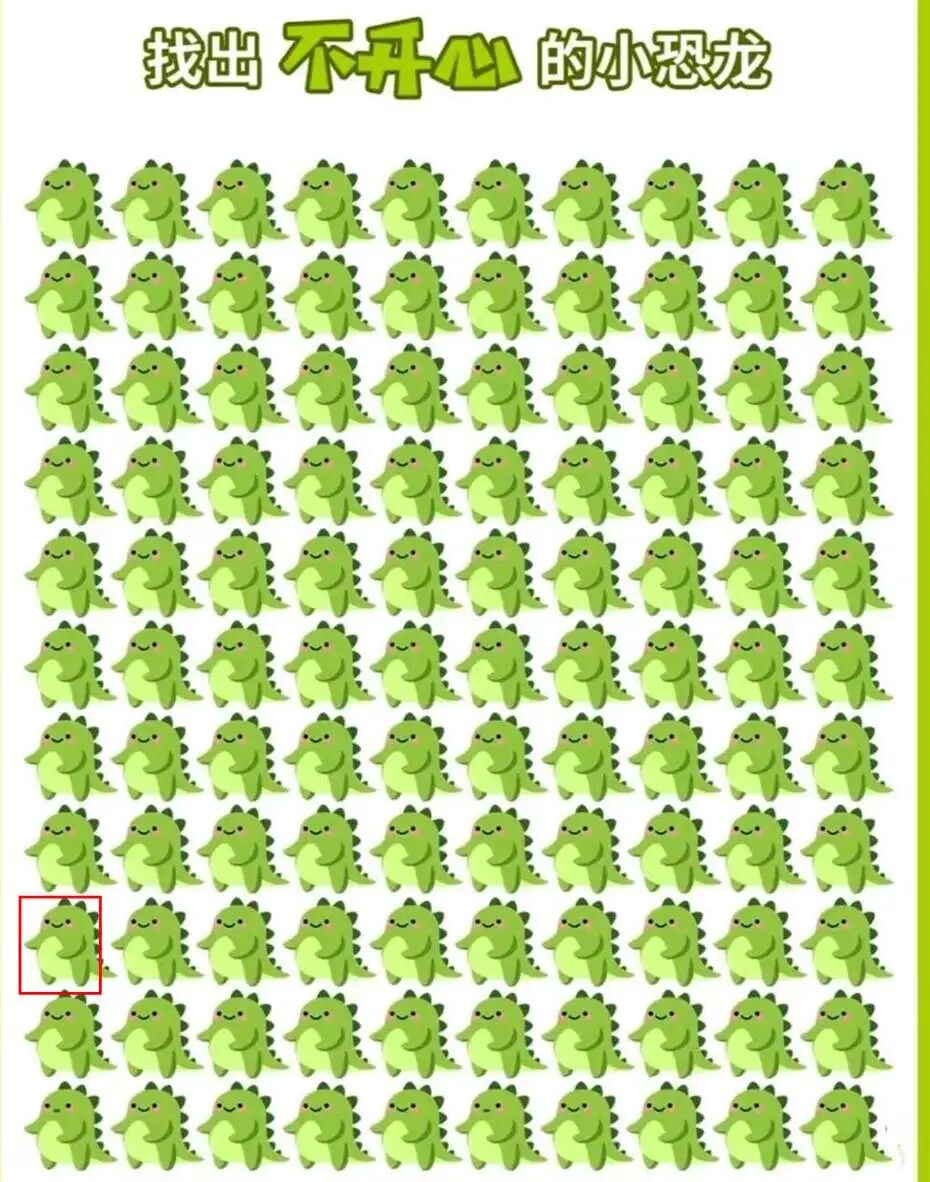
Grounding
本环节检验模型的目标定位能力,此前纯文本输出无法找到的内容,通过Grounding可以实现定位。
Prompt:找出图片中奔跑的人,以JSON格式返回边界框坐标。
Qwen3-VL-30B-A3B:

然而,模型仍未能定位到小恐龙。
数学做题
为评估多模态大模型的数学能力,本次测试采用了2025年高考题。
Prompt:解题
Qwen3-VL-30B-A3B:回答正确,最后一问也得到了正确解答。
图片排序
此测试旨在检验多模态模型能否理清多张图片之间的逻辑关系,并理解事件发展规律。
Prompt:根据图中显示的多个场景,将最有可能发生的事件按顺序排列。
正确答案CADB:走到商店,买雪糕,滑倒,雪糕打到脸上。
Qwen3-VL-30B-A3B-Instruct:回答错误

Qwen3-VL-30B-A3B-Thinking:回答正确
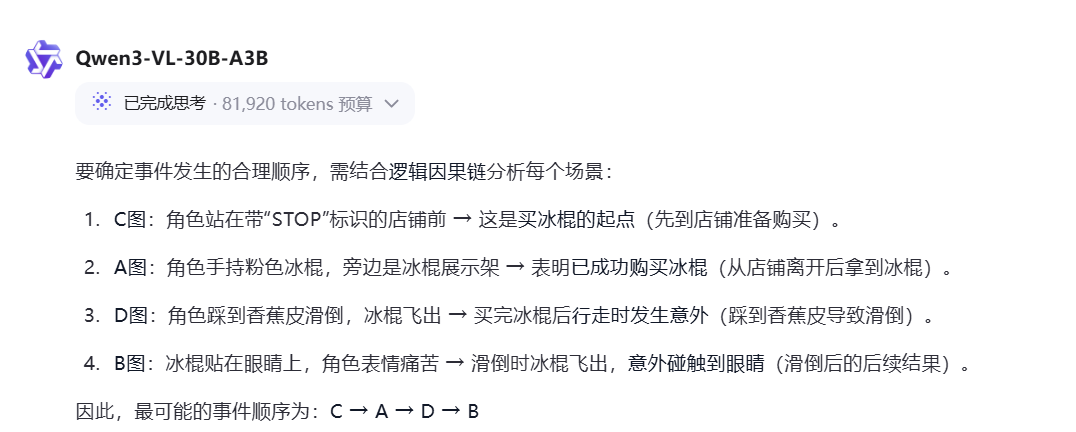
Prompt:根据图中显示的多个场景,将最有可能发生的事件按顺序排列。
正确答案CDAB:发现蘑菇,采摘并食用,感到眩晕,产生蘑菇会走的幻觉。
Qwen3-VL-30B-A3B:回答不正确,其理解能力不及235B版本。

空间逻辑
此测试旨在考察多模态模型在理解图片基础上的深度逻辑分析能力。
Prompt:请回答。
正确答案为A。
Qwen3-VL-30B-A3B:回答错误,且在回答内容较长时,仍旧出现中英文夹杂的现象。

空间变换
此测试考察多模态模型对图像进行空间转换的理解能力。
Prompt:请回答。
Qwen3-VL-30B-A3B-Instruct:回答错误

Qwen3-VL-30B-A3B-Thinking:回答正确,能准确识别主视图。
色盲测试
此测试考察多模态大模型对颜色的识别能力。
Prompt:图片里有数字吗?如果有的话是什么?
正常者能读出6,红绿色盲者及红绿色弱者读成5,而全色弱者则全然读不出上述的两个字。
Qwen3-VL-30B-A3B:回答正确
即使将图片翻转,模型也能识别正确。

总体而言,Qwen在开源领域始终保持领先地位。Qwen3-VL-30B-A3B模型虽然在某些能力上与更大规模的模型相比仍有差距,但其轻量化特性使其具备显著优势。作为30B MoE模型,它仅激活3B参数,非常适合在端侧设备上高效运行。此外,对于其表现不足之处,用户也有机会进行微调优化,不像235B等超大模型那样,多数用户只能远远地观望。




