

曾几何时,处理流式数据还被视为一种前沿方法。自20世纪70年代关系型数据库管理系统问世,以及80年代末传统数据仓库系统出现以来,所有数据工作负载都始于并终于所谓的批处理。批处理的核心概念是将众多任务收集成组(或批次),然后通过一次性操作来处理这些任务。
另一方面,存在着流式数据的概念。尽管流式数据有时仍被认为是尖端技术,但它已拥有坚实的发展历史。一切始于2002年,当时斯坦福大学的研究人员发表了题为“数据流系统中的模型与问题”的论文。然而,直到近十年后(2011年),随着用于存储和处理流式数据的Apache Kafka平台开源,流式数据系统才开始被更广泛的受众所接触。如今,处理流式数据不再是一种奢侈,而是一种必然需求。
微软早已认识到处理“数据一到达即处理”的日益增长的需求。因此,Microsoft Fabric在这一方面表现出色,其“实时智能”(Real-time Intelligence)功能是整个平台的核心,提供一系列全面的能力来高效处理流式数据。
在深入解释实时智能的每个组件之前,文章将首先退一步,采用一种更不依赖特定工具的方法来探讨流处理的一般概念。
什么是流处理?
如果在谷歌搜索中输入本节标题中的短语,将会获得超过100,000条结果!因此,这里将分享一张图示,它代表了对流处理的理解。
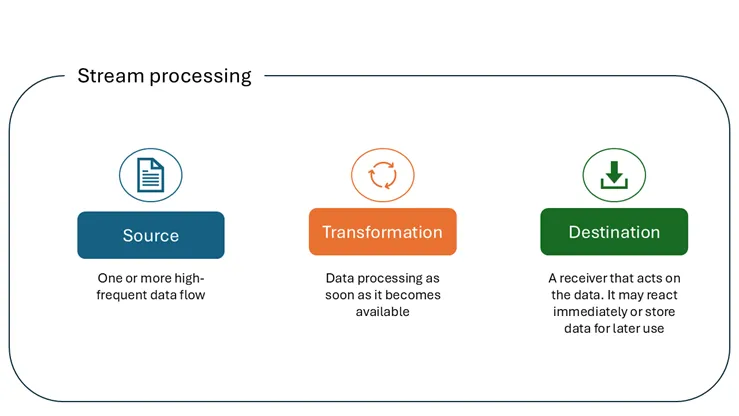
作者绘图
接下来,文章将探讨流处理的典型用例:
- 欺诈检测
- 实时股票交易
- 客户活动分析
- 日志监控——系统、设备故障排除等
- 安全信息与事件管理——分析日志和实时事件数据以进行监控和威胁检测
- 仓库库存管理
- 网约车匹配
- 机器学习和预测分析
正如读者所见,流式数据已成为众多现实生活场景中不可或缺的一部分,并且在上述用例中被认为远远优于传统的批处理方法。
现在,文章将深入探讨Microsoft Fabric中如何执行流式数据处理,以及可供使用的工具。
下图展示了Microsoft Fabric中所有实时智能组件的高级概览:
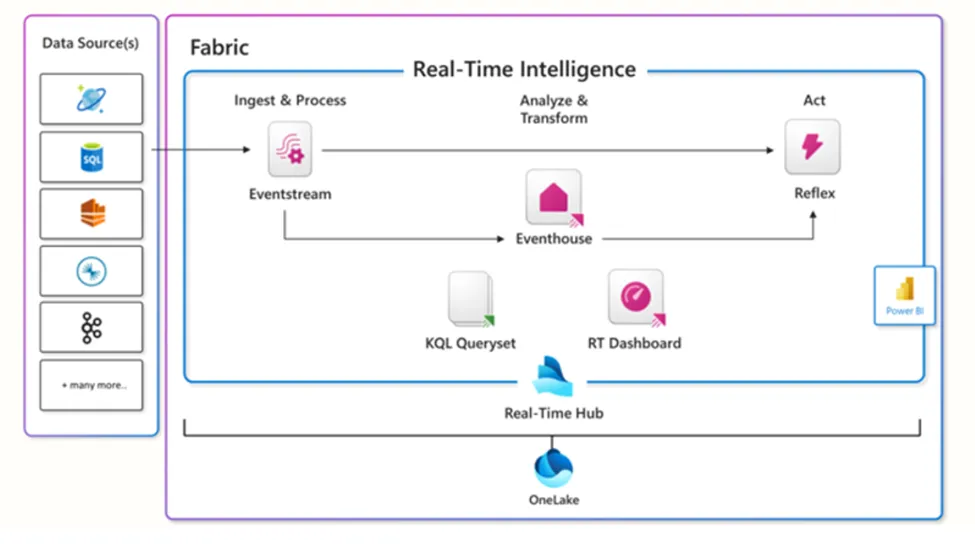
图片来源:Microsoft Learn
实时中心(Real-Time hub)
首先,文章将介绍实时中心(Real-Time hub)。每个Microsoft Fabric租户都会自动预置一个实时中心,它是整个组织中所有动态数据的焦点。与OneLake类似,每个租户只能拥有一个实时中心,这意味着无法预置或创建多个实时中心。
实时中心的主要目的是实现从各种来源快速便捷地发现、摄取、管理和消费流式数据。在下图中,可以看到Microsoft Fabric实时中心中所有数据流的概览:
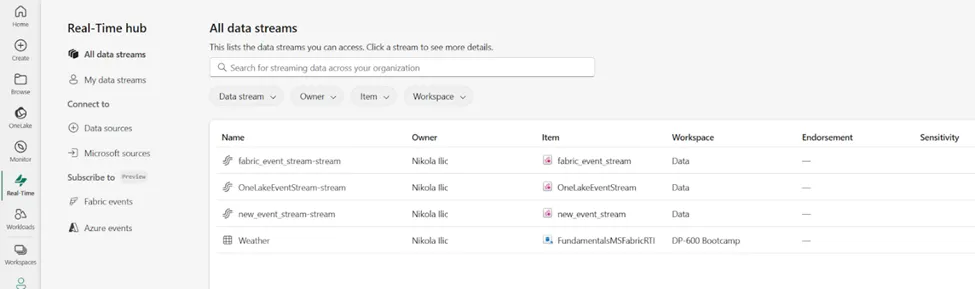
作者绘图
现在,将探讨实时中心中所有可用的选项。
-
所有数据流(All data streams)选项卡显示了可访问的所有流和表。流代表Fabric事件流(eventstreams)的输出,而表则来自KQL数据库。事件流和KQL数据库将在后续章节中详细探讨。
-
我的数据流(My data streams)选项卡显示了导入Microsoft Fabric“我的工作区”中的所有流。
-
数据源(Data sources)选项卡是数据从内部和外部引入Fabric的核心。在此选项卡中,可以选择众多开箱即用的连接器,例如Kafka、各种数据库系统的CDC流、AWS和GCP等外部云解决方案等等。
-
微软源(Microsoft sources)选项卡过滤了之前的源集,仅包含微软数据源。
-
Fabric事件(Fabric events)选项卡显示了Microsoft Fabric中生成的系统事件列表,用户可以访问这些事件。在这里,可以选择作业事件、OneLake事件和工作区项事件。以下将深入探讨这三个选项:
- 作业事件:由Fabric监控活动的状态变化产生,例如作业创建、成功或失败。
- OneLake事件:由OneLake中文件和文件夹的操作产生,例如文件创建、删除或重命名。
- 工作区项事件:由工作区项的操作产生,例如项创建、删除或重命名。
-
Azure事件(Azure events)选项卡显示了Azure blob存储中生成的系统事件列表。
实时中心提供了多种连接器,用于将数据摄取到Microsoft Fabric中。它还支持为所有支持的源创建流。创建流后,可以对其进行处理、分析和操作。
- 处理(Processing)流允许应用多种转换,例如聚合、过滤、联合等。目标是在将输出发送到支持的目标之前对数据进行转换。
- 分析(Analyzing)流使用户能够将KQL数据库作为流的目标,然后打开KQL数据库并对数据库执行查询。
- 操作(Acting)流涉及根据条件设置警报,并指定在满足某些条件时应采取的行动。
事件流(Eventstreams)
如果是一名低代码或无代码的数据专业人员,并且需要处理流式数据,那么将会喜欢事件流(Eventstreams)。简而言之,事件流允许用户连接到上节中探讨过的众多数据源,可以选择性地应用各种数据转换步骤,并将结果输出到一个或多个目标。下图展示了将流式数据摄取到三个不同目标——Eventhouse、Lakehouse和Activator的常见工作流程:
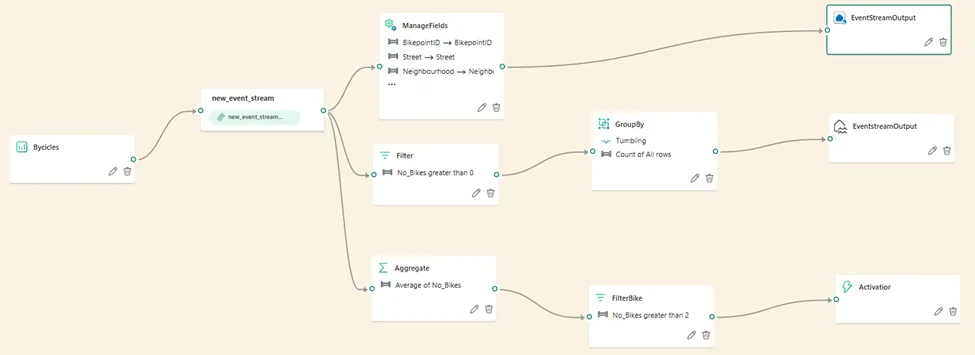
作者绘图
在事件流设置中,可以调整传入数据的保留期限。默认情况下,数据保留一天,当保留期限到期时,事件将自动移除。
此外,可能还需要对传入和传出事件的事件吞吐量进行微调。有以下三个选项可供选择:
- 低(Low): < 10 MB/秒
- 中(Medium): 10-100 MB/秒
- 高(High): > 100 MB/秒
事件库(Eventhouse)与KQL数据库
在上一节中,读者已了解如何连接到各种流式数据源,选择性地转换数据,并最终将其加载到最终目的地。正如读者可能注意到的,其中一个可用目的地是事件库(Eventhouse)。在本节中,文章将探讨Microsoft Fabric中用于在实时智能工作负载中存储数据的项目。
事件库(Eventhouse)
文章将首先介绍事件库(Eventhouse)项目。事件库本质上是KQL数据库的容器。事件库本身不存储任何数据,它只是在Fabric工作区内提供处理流式数据所需的基础设施。下图展示了事件库的系统概览页面:
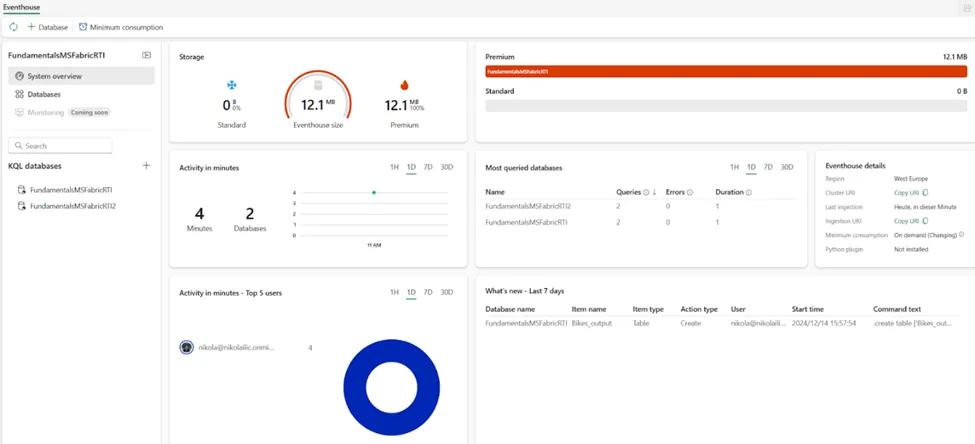
作者绘图
系统概览页面的一大优点是它能一目了然地提供所有关键信息。因此,用户可以立即了解事件库的运行状态、OneLake存储使用情况(可进一步细分到每个KQL数据库级别)、计算资源使用情况、最活跃的数据库和用户以及近期事件。
如果切换到“数据库”页面,将能够看到现有事件库中包含的KQL数据库的高级概览,如下图所示:
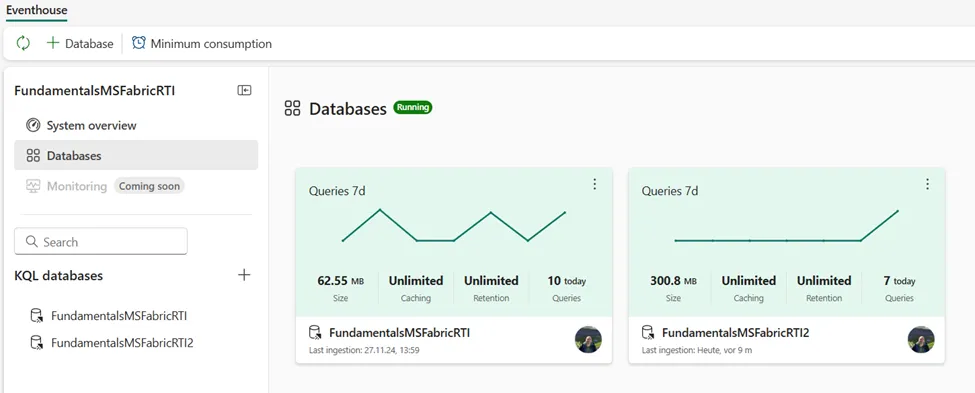
作者绘图
可以在单个Fabric工作区中创建多个事件库。此外,一个事件库可以包含一个或多个KQL数据库:
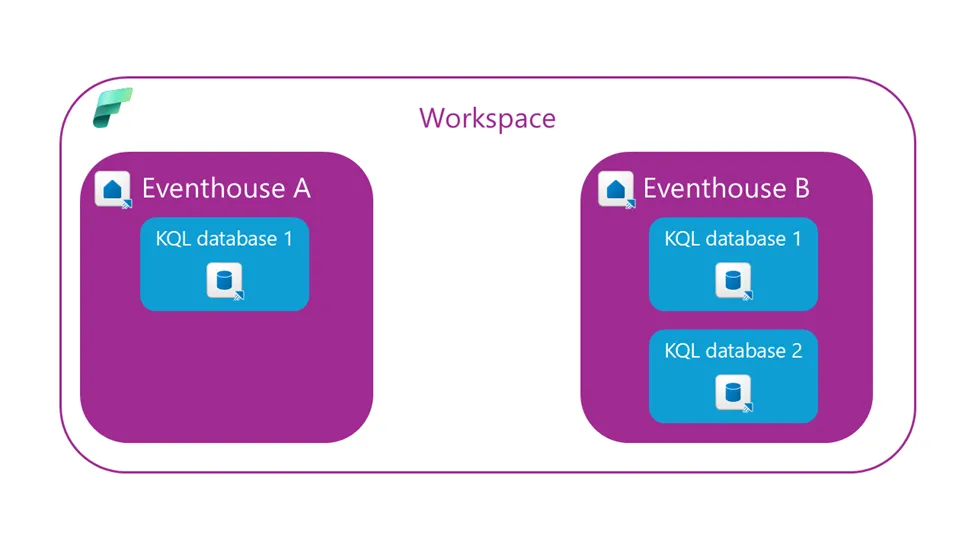
作者绘图
接下来,将通过解释“最小消费”(Minimum consumption)的概念来总结事件库的部分。事件库在设计上优化为在不使用时自动暂停服务。因此,当这些服务重新激活时,事件库可能需要一些时间才能完全可用。然而,在某些业务场景中,这种延迟是不可接受的。在这些情况下,请务必配置“最小消费”功能。通过配置“最小消费”,服务将始终可用,但需要由用户来确定最小级别,该级别随后可供事件库内的KQL数据库使用。
KQL数据库
既然已了解事件库容器,现在将重点介绍用于存储实时分析数据的核心项目——KQL数据库。
首先,文章将回顾并解释该项目的名称。虽然大多数数据专业人员至少听说过SQL(结构化查询语言),但KQL可能比其“结构化”的亲属更加神秘。
读者可能正确地猜测到,缩写中的QL代表查询语言(Query Language)。但是,字母K又代表什么呢?它是Kusto的缩写。尽管坊间传闻该语言是以著名博学家和海洋学家雅克·库斯托(Jacques Cousteau,其姓氏发音为“Kusto”)的名字命名,但目前尚未找到微软的官方确认来证实这个说法。可以确定的是,Kusto曾是日志分析查询语言的内部项目名称。
谈及历史,不妨分享更多历史背景。如果读者过去曾使用过Azure数据资源管理器(ADX),那么现在将感到幸运。Microsoft Fabric中的KQL数据库是ADX的官方继任者。与许多其他经过重构并集成到Fabric SaaS化特性中的Azure数据服务类似,ADX为KQL数据库提供了存储和查询实时分析数据的平台。KQL数据库的引擎和核心功能与Azure数据资源管理器相同——关键区别在于管理行为:Azure数据资源管理器代表PaaS(平台即服务),而KQL数据库则是SaaS(软件即服务)解决方案。
尽管可以在KQL数据库中存储任何类型的数据(非结构化、半结构化和结构化),但其主要目的是处理遥测数据、日志、事件、跟踪信息和时间序列数据。在底层,该引擎利用优化的存储格式、自动索引和分区以及高级数据统计信息,以实现高效的查询规划。
现在,将探讨如何在Microsoft Fabric中利用KQL数据库存储和查询实时分析数据。创建数据库的过程尽可能地简单。下图展示了在Fabric中创建KQL数据库的2步过程:
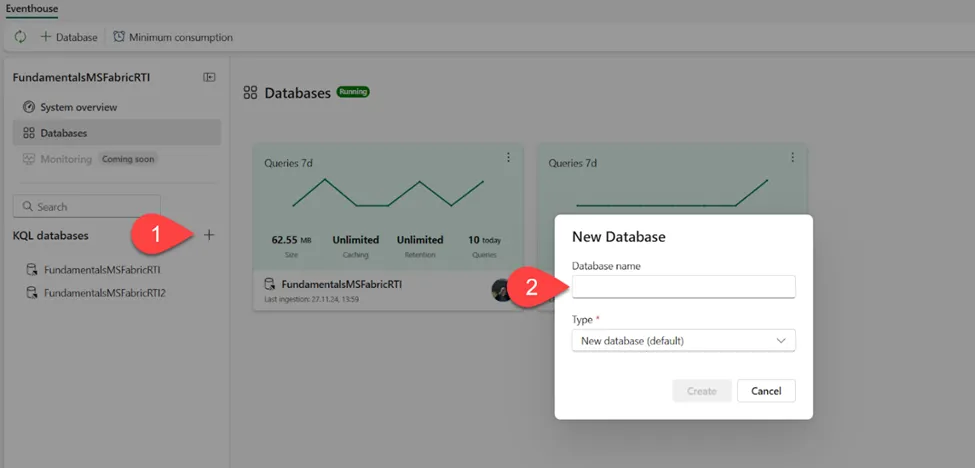
作者绘图
- 点击KQL数据库旁边的“+”号。
- 提供数据库名称并选择其类型。类型可以是默认的新数据库,也可以是快捷方式数据库。快捷方式数据库是对另一个数据库的引用,该数据库可以是Microsoft Fabric实时智能中的另一个KQL数据库,也可以是Azure数据资源管理器数据库。
请勿混淆OneLake快捷方式与实时智能中快捷方式数据库类型的概念!后者仅仅引用整个KQL/Azure数据资源管理器数据库,而OneLake快捷方式则允许在其他OneLake工作负载(如湖仓和/或数据仓库)甚至外部数据源(例如ADLS Gen2、Amazon S3、Dataverse、Google Cloud Storage等)中使用存储在Delta表中的数据。这些数据随后可以通过使用external_table()函数从KQL数据库中访问。
现在,将从用户界面角度快速浏览KQL数据库的关键功能。下图展示了主要关注点:
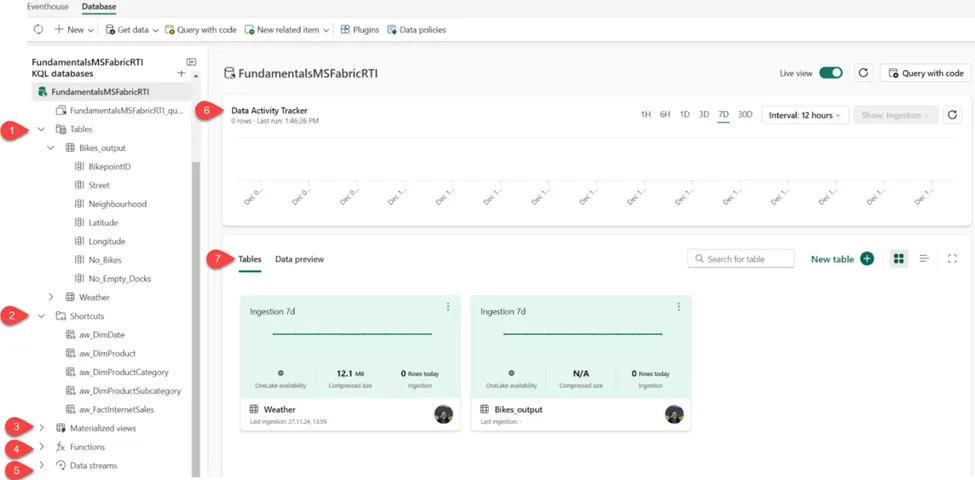
作者绘图
- 表(Tables)– 显示数据库中的所有表。
- 快捷方式(Shortcuts)– 显示作为OneLake快捷方式创建的表。
- 物化视图(Materialized views)– 物化视图表示对源表或另一个物化视图的聚合查询。它由一个summarize语句组成。
- 函数(Functions)– 这些是存储和管理在数据库级别的用户定义函数,类似于表。这些函数通过使用.create function命令创建。
- 数据流(Data streams)– 与所选KQL数据库相关的所有流。
- 数据活动跟踪器(Data Activity Tracker)– 显示数据库在选定时间段内的活动。
- 表/数据预览(Tables/Data preview)– 允许在两种不同视图之间切换。表视图显示数据库表的高级概览,而数据预览则显示所选表的前100条记录。
在实时智能中查询和可视化数据
既然已了解如何在Microsoft Fabric中存储实时分析数据,现在是时候动手实践,从这些数据中提炼出商业洞察了。在本节中,文章将重点解释从KQL数据库中存储的数据中提取有用信息的各种选项。
因此,在本节中,文章将介绍用于数据检索的常用KQL函数,并探讨用于数据可视化的实时仪表板。
KQL查询集(KQL queryset)
KQL查询集是用于运行查询、查看和自定义来自各种数据源结果的Fabric项目。一旦创建新的KQL数据库,KQL查询集项目将开箱即用地被预置。这是一个默认的KQL查询集,它会自动连接到其所存在的KQL数据库。默认的KQL查询集不支持多重连接。
另一方面,当创建自定义KQL查询集项目时,可以将其连接到多个数据源,如下图所示:
作者绘图
现在,将介绍KQL的构建块,并探讨一些最常用的运算符和函数。KQL是一种相当简单但功能强大的语言。在某种程度上,它与SQL非常相似,尤其是在使用按层次结构组织的模式实体(如数据库、表和列)方面。
KQL查询语句最常见的类型是表格表达式语句。这意味着查询输入和输出都由表或表格数据集组成。表格语句中的运算符通过“|”(管道)符号进行序列化。数据从一个运算符流向(通过管道传递)下一个运算符,如下面的代码片段所示:
MyTable
| where StartTime between (datetime(2024-11-01) .. datetime(2024-12-01))
| where State == "Texas"
| count
管道是顺序执行的——数据从一个运算符流向另一个运算符——这意味着查询运算符的顺序很重要,并可能对输出结果和性能产生影响。
在上述代码示例中,MyTable中的数据首先根据StartTime列进行筛选,然后根据State列进行筛选,最后,查询返回一个包含单列单行的表,显示筛选后的行数。
此时一个合理的问题可能是:如果已经掌握SQL,是否还需要为了查询实时分析数据而学习另一种语言?答案通常是:视情况而定。
幸运的是,这里有一些好消息和更好的消息!
好消息是:用户可以编写SQL语句来查询KQL数据库中存储的数据。但是,能做某事并不意味着应该做……仅使用SQL查询,可能会忽略KQL的独特优势,并限制自己使用许多专为高效处理实时分析查询而构建的KQL特定函数。
更好的消息是:通过利用explain运算符,用户可以“要求”Kusto将SQL语句转换为等效的KQL语句,如下图所示:
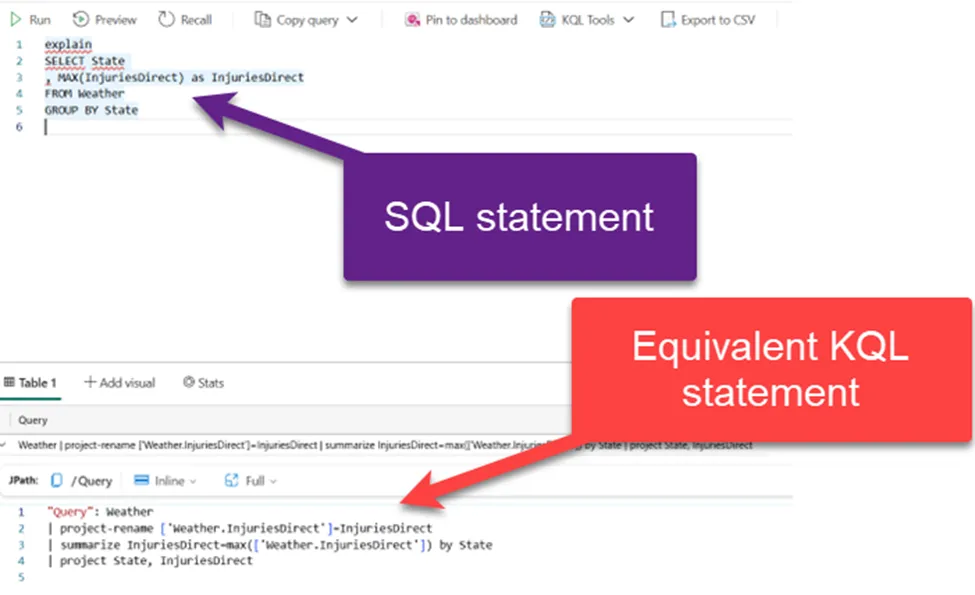
作者绘图
在以下示例中,将查询样本天气数据集,其中包含有关美国天气风暴和损害的数据。首先从简单查询开始,然后引入一些更复杂的查询。在第一个示例中,将计算Weather表中的记录数:
//统计记录数
Weather
| count
想知道如何仅检索记录的子集吗?可以使用take或limit运算符:
//样本数据
Weather
| take 10
请记住,take运算符不会返回前n条记录,除非数据已按特定顺序排序。通常,take运算符从表中返回任意n条记录。
下一步,文章将扩展此查询,不仅返回行的子集,还返回列的子集:
//子集列的样本数据
Weather
| take 10
| project State, EventType, DamageProperty
project运算符等同于SQL中的SELECT语句。它指定结果集中应包含哪些列。
在以下示例中,将创建一个计算列Duration,表示EndTime和StartTime值之间的时间差。此外,只显示按DamageProperty值降序排列的前10条记录:
//创建计算列
Weather
| where State == 'NEW YORK' and EventType == 'Winter Weather'
| top 10 by DamageProperty desc
| project StartTime, EndTime, Duration = EndTime - StartTime, DamageProperty
现在是时候介绍summarize运算符了。该运算符生成一个聚合输入表内容的表。因此,以下语句将显示每个州的总记录数,仅包括前5个州:
//使用summarize运算符
Weather
| summarize TotalRecords = count() by State
| top 5 by TotalRecords
文章将扩展之前的代码,直接在结果集中可视化数据。将添加另一行KQL代码,以将结果渲染为条形图:
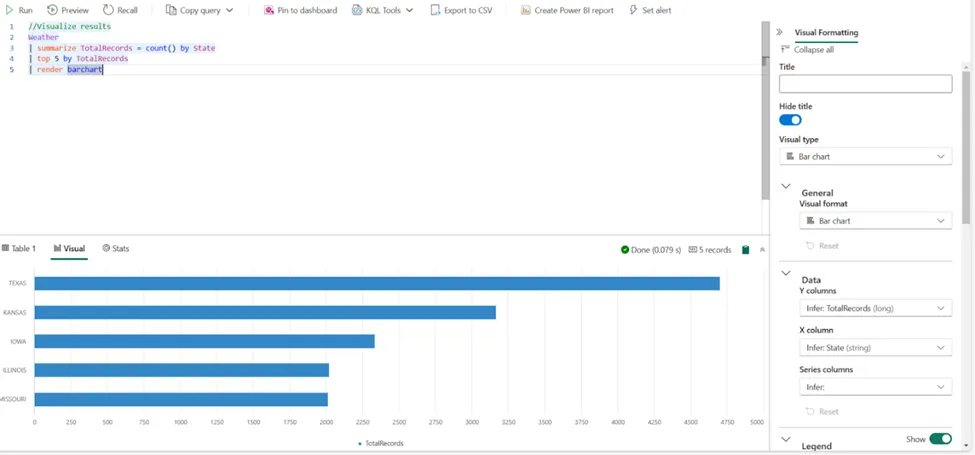
作者绘图
正如读者可能注意到的,该图表可以从右侧的“视觉格式化”窗格中进行额外自定义,这在可视化KQL数据库中存储的数据时提供了更大的灵活性。
这些只是使用KQL语言检索事件库和KQL数据库中存储数据的基本示例。可以确信,在需要操作和检索实时分析数据时,KQL在更高级的用例中也不会令人失望。
SQL是许多数据专业人员的“通用语”。尽管可以编写SQL来从KQL数据库检索数据,但强烈建议避免这样做。作为一个快速参考,这里提供一份“SQL到KQL速查表”,以帮助读者在从SQL过渡到KQL时快速入门。
此外,同事兼MVPBrian Bønk发布并维护了一份精彩的KQL语言参考指南,可在此处查阅。如果正在使用KQL,务必尝试一下。
实时仪表板(Real-time dashboards)
尽管KQL查询集是探索和查询存储在事件库和KQL数据库中数据的强大方式,但其可视化功能却相当有限。是的,可以在查询视图中可视化结果,正如在之前的示例中所示,但这更多是一种“急救式”可视化,可能无法让管理人员和业务决策者满意。
幸运的是,实时智能中提供了一个开箱即用的解决方案,支持高级数据可视化概念和功能。实时仪表板(Real-Time Dashboard)是一个Fabric项目,能够创建交互式且视觉吸引力强的业务报告解决方案。
首先,文章将确定实时仪表板的核心元素。一个仪表板由一个或多个磁贴组成,这些磁贴可以选择性地结构化并组织成页面,每个磁贴都由底层的KQL查询填充。
作为创建实时仪表板过程的第一步,必须在Fabric租户的管理员门户中启用此设置:

作者绘图
接下来,应该在Fabric工作区中创建一个新的实时仪表板项目。然后,将连接到天气数据集并配置第一个仪表板磁贴。将执行上一节中的一个查询,以使用条件计数函数检索前10个州的数据。下图显示了磁贴设置面板,其中包含众多可配置选项:
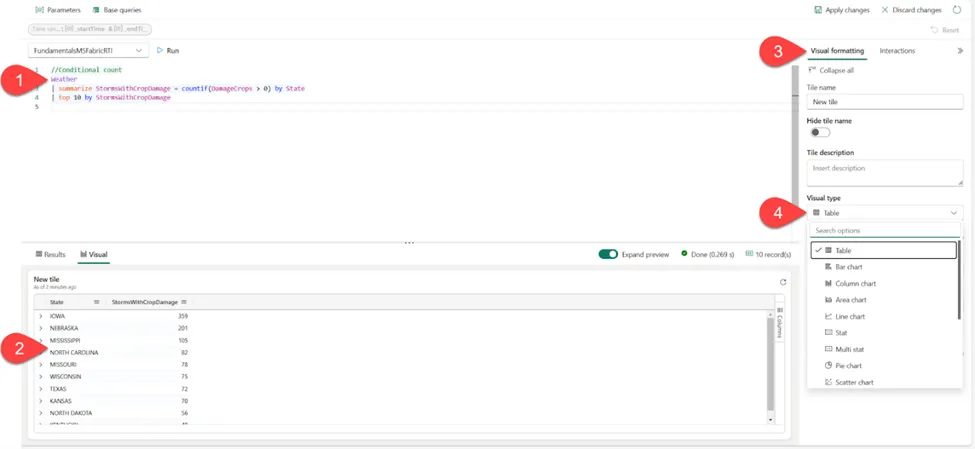
作者绘图
- 用于填充磁贴的KQL查询。
- 数据的视觉表示。
- 视觉格式化窗格,包含设置磁贴名称和描述的选项。
- 视觉类型下拉菜单,用于选择所需的视觉类型(在本例中为表格视觉对象)。
现在,将向仪表板添加另外两个磁贴。将复制并粘贴之前使用的两个查询——第一个将检索总记录数排名前5的州,而另一个将显示纽约州冬季天气事件类型下财产损失值随时间的变化。
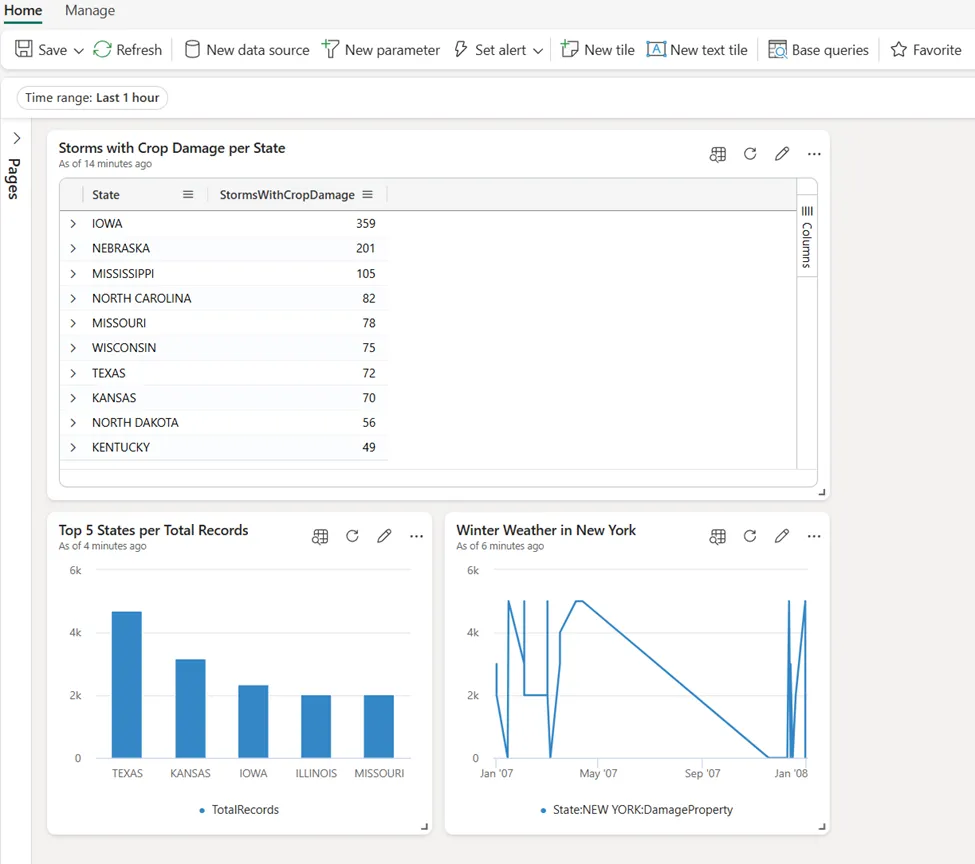
作者绘图
还可以直接从KQL查询集向现有仪表板添加磁贴,如下图所示:

作者绘图
现在,将重点关注使用实时仪表板时的各种功能。在顶部功能区中,可以找到添加新数据源、设置新参数和添加基本查询的选项。然而,真正使实时仪表板强大的,是在其上设置警报的可能性。根据警报中定义的条件是否满足,可以触发特定操作,例如发送电子邮件或Microsoft Teams消息。警报是使用Activator项目创建的。
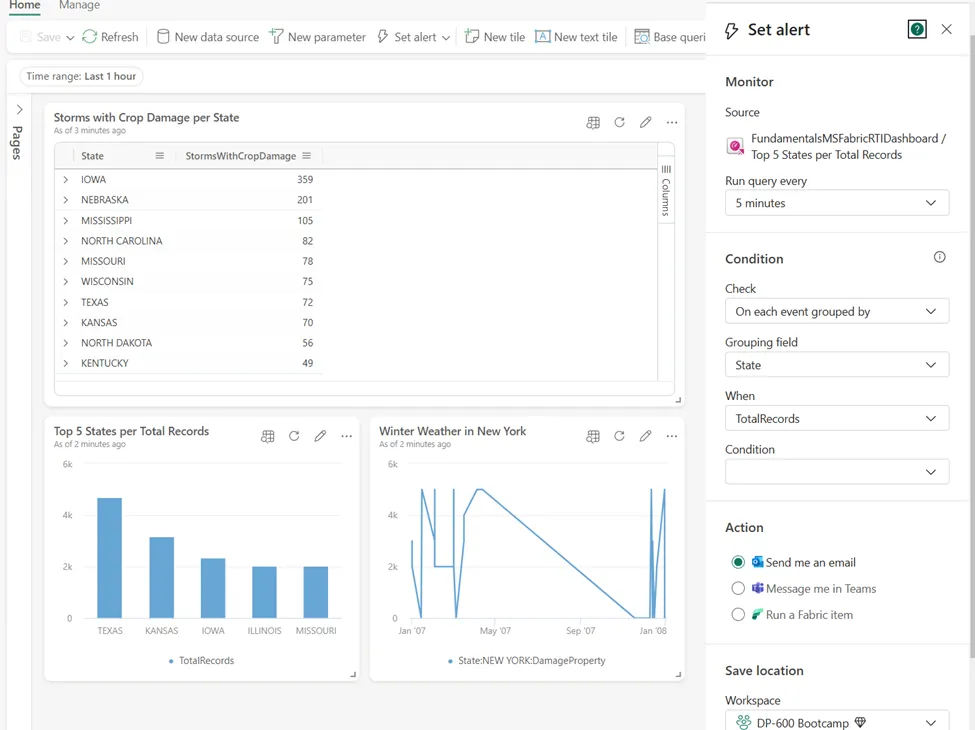
作者绘图
使用Power BI可视化数据
Power BI是用于构建强大、可扩展和交互式业务报告解决方案的成熟且广泛采用的工具。在本节中,文章将特别关注Power BI如何与Microsoft Fabric中的实时智能工作负载协同工作。
基于KQL数据库中存储的数据创建Power BI报告再简单不过了。可以直接从KQL查询集创建Power BI报告,如下图所示:
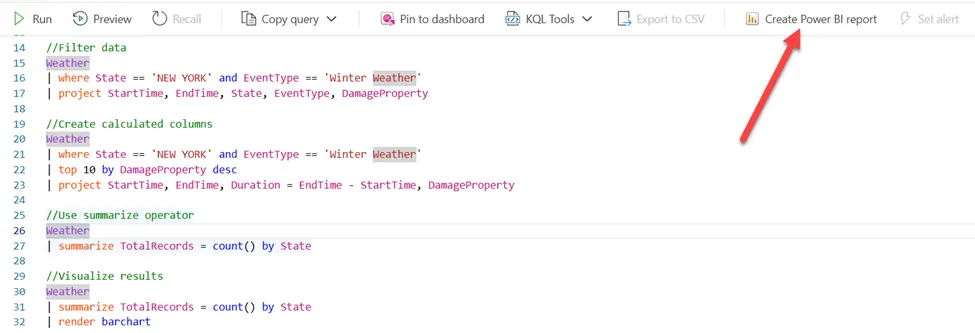
作者绘图
显然,仍然可以利用“常规”的Power BI工作流程,即从Power BI Desktop连接到KQL数据库作为数据源。在这种情况下,需要打开OneLake数据中心并选择KQL数据库作为数据源:
作者绘图
与基于SQL的数据源一样,对于实时分析数据,可以选择导入(Import)和DirectQuery两种存储模式。导入模式在Power BI的数据库中创建数据的本地副本,而DirectQuery则支持近实时地查询KQL数据库。
Activator
Activator是整个Microsoft Fabric领域中最具创新性的功能之一。关于Activator的详细内容,将在另一篇文章中进行深入探讨。本节仅旨在介绍这项服务并简要强调其主要特点。
Activator是一种无代码解决方案,用于在满足底层数据条件时自动采取行动。Activator可与事件流(Eventstreams)、实时仪表板(Real-Time Dashboards)和Power BI报告结合使用。一旦数据达到特定阈值,Activator将自动触发指定的操作——例如,发送电子邮件或Microsoft Teams消息,甚至启动Power Automate流。所有这些场景将在另一篇专门文章中进行更深入的探讨,其中也将提供一些实现Activator项目的实际场景。
总结
实时智能(Real-Time Intelligence)——这项最初作为Microsoft Fabric中“Synapse体验”一部分的功能,现已成为一个独立且专用的工作负载。这充分展示了微软对实时智能的愿景和发展路线图!
值得注意的是:最初,实时分析(Real-Time Analytics)与数据工程、数据仓库和数据科学体验一同包含在Synapse的范畴之下。然而,微软认为处理流式数据值得在Microsoft Fabric中拥有一个专用工作负载,考虑到日益增长的对动态数据处理的需求,以及数据一经捕获即需提供洞察的迫切性,这一决定是完全合理的。从这个意义上讲,Microsoft Fabric提供了一整套强大的服务,作为处理、分析和作用于生成数据的下一代工具。
可以确信,考虑到数据源的演变和数据生成速度的加快,实时智能工作负载在未来将变得越来越重要。




