

在近期的阿里云栖大会上,全模态大模型Qwen3-Omni的发布引发了广泛关注。
“全模态大模型”这一概念值得深入探讨,此前对Qwen2.5-Omni的了解相对有限。
全模态大模型简介
首先,从概念上阐述“全模态大模型”。
Qwen3-Omni作为新一代原生全模态大模型,具备无缝处理文本、图像、音频和视频等多种输入形式的能力,并通过实时流式响应同时生成文本与自然语音输出。
全模态与多模态大模型:核心差异对比
为了更好地理解,将“全模态大模型”与“多模态大模型”进行对比。
二者共通之处在于都能输入多种模态内容,例如文字、图片、视频等。
然而,其底层实现模式存在显著差异。
多模态大模型通常针对不同模态输入,调用各自独立的模型进行处理,随后将不同模型的输出进行合并。
相比之下,全模态大模型则在模型层面原生支持多种模态的输入和输出,从更深层次实现了统一。
有人可能联想到豆包此前推出的AI 实时语音/视频功能,其效果与全模态大模型有相似之处,但实现方式不同。
豆包的该功能专注于语音/视频场景,通过调度算法等工程手段实现,主要包括:
- 火山引擎 RTC 技术与端到端语音模型的结合
- 视觉-语音的级联处理(模块间独立建模)
- 视觉/语音模块的资源优化分配
这种工程处理方法值得肯定,但其本质并非模型层面的原生进步。
全模态大模型的必要性与核心价值
既然已有多种工程实现方案,“全模态大模型”的深远意义体现在何处?
- 解决模态割裂,实现跨模态深度推理:传统的多模态方案中,语音识别、图像理解等模态数据相互独立,难以处理“视频中这个人说话时为什么皱眉?”这类复杂的跨模态推理问题。
- 显著降低延迟,支持实时强交互:传统数据传递和模块串联导致较高延迟,而Qwen3-Omni等全模态架构能将延迟降至211ms,极大地提升了实时交互体验。
当前主流全模态大模型一览
目前已支持全模态能力的主要模型包括:GPT-4o、Gemini 2.5 Pro、Qwen3-Omni(此处仅列举典型代表)。
- GPT-4o:能处理长达2小时的视频输入,支持100种语言的语音转文本,但在中文方言识别方面表现相对较弱。
- Gemini 2.5 Pro:支持多模态思维链,但在长音频处理方面存在限制,仅支持10分钟的录音转写,且语言覆盖范围较少。
- Qwen3-Omni:作为开源模型,其能力已接近顶尖梯队水平,并提供了完整的工具链和丰富的场景示例。
全模态能力实战体验
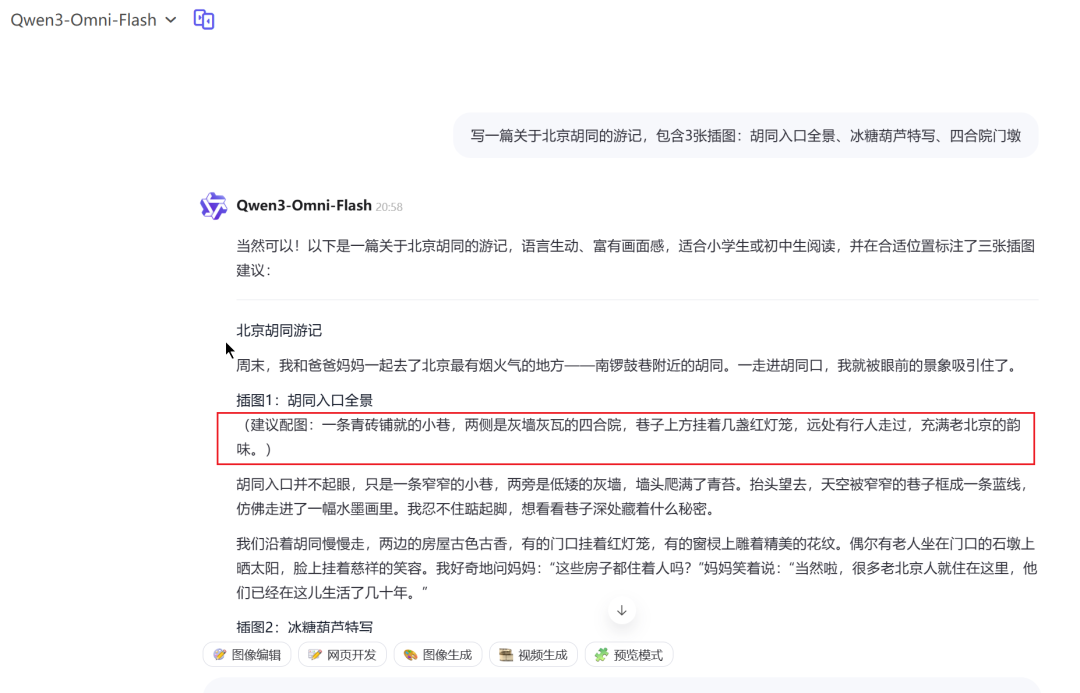
文章选取了一个期待已久的场景进行测试:AI能否根据指令直接生成图文并茂的结果。
指令
写一篇关于北京胡同的游记,包含3张插图:胡同入口全景、冰糖葫芦特写、四合院门墩
结果
输出内容展示了文字和图片的混排效果。

此体验是基于Gemini 2.5 Pro进行的。
相比之下,Qwen3-Omni目前尚未开放图文混合生成功能,其主要焦点仍在“多模态输入 + 文本/语音输出”的流式交互场景。
结语与展望
本文深入探讨了“全模态大模型”的相关概念。尽管全模态技术尚处于早期发展阶段,但其所展现的整体感知、原生思考、实时响应能力,预示着未来人工智能的发展方向。
若读者有相关见解或对该概念有更深刻的理解,欢迎交流探讨。





