在人工智能应用开发与部署过程中,确保其安全性和可控性至关重要。技术护栏正是为AI应用提供这种控制与保障的关键机制。那么,如何在实际应用中有效地构建这些护栏呢?
实际上,在AI应用的编码工作开始之前,就已经需要建立一系列的护栏。首先是政府层面的法律护栏,例如欧盟AI法案,它明确界定了AI可接受与被禁止的使用场景。其次是企业内部制定的政策护栏,这些护栏从安全和伦理两个维度,规定了公司认可的AI应用场景。这两类护栏共同构成了AI应用前期筛选的依据,确保只有符合规范的用例才能进入后续开发阶段。
在通过前两类护栏的筛选后,可接受的AI用例会交付给工程团队。在工程团队实现这些用例时,会进一步融入技术护栏,以确保数据的安全使用并维持应用程序的预期行为。本文将深入探讨这第三类至关重要的技术护栏。
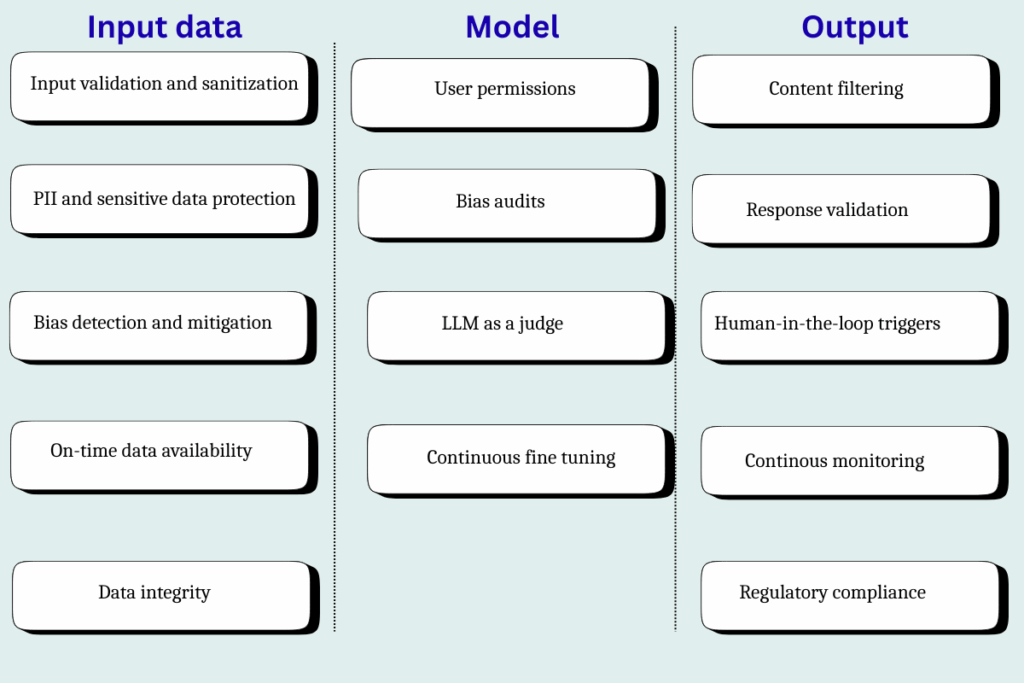
AI应用各层级的关键技术护栏
技术护栏主要在AI应用的输入层、模型层和输出层进行构建,每一层都承载着独特而重要的作用:
- 数据层: 数据层的护栏旨在防止任何敏感、潜在问题或不正确的数据进入系统,是保障数据质量和安全的第一道防线。
- 模型层: 在这一层构建护栏,能够确保模型按照预期工作,避免模型行为偏离既定轨道。
- 输出层: 输出层护栏的核心任务是确保模型不会以高置信度提供错误答案,这正是AI系统常见的风险之一。
1. 数据层
在数据层,以下是构建AI应用必须具备的关键护栏:
(i) 输入验证与数据清洗
在任何AI应用中,首先需要检查输入数据的格式是否正确,并确保不包含任何不当或冒犯性语言。这项工作实施起来相对容易,因为大多数数据库都提供了内置的SQL函数用于模式匹配。例如,如果某个字段应为字母数字型,那么可以使用简单的正则表达式模式验证其值是否符合预期格式。类似地,在Microsoft Azure等云应用中,也提供了执行脏话检测(不当或冒犯性语言)的功能。如果数据库缺乏此类内置功能,团队可以随时构建自定义函数来满足需求。
Data validation:
– The query below only takes entries from the customer table where the customer_email_id is in a valid format
SELECT * FROM customers WHERE REGEXP_LIKE(customer_email_id, '^[A-Z0-9._%+-]+@[A-Z0-9.-]+.[A-Z]{2,}$' );
—-----------------------------------------------------------------------------------------
Data sanitization:
– Creating a custom profanity_check function to detect offensive language
CREATE OR REPLACE FUNCTION offensive_language_check(INPUT VARCHAR)
RETURNS BOOLEAN
LANGUAGE SQL
AS $$
SELECT REGEXP_LIKE(
INPUT
'(abc|...)', — list of offensive words separated by pipe
);
$$;
– Using the custom profanity_check function to filter out comments with offensive language
SELECT user_comments from customer_feedback where offensive_language_check(user_comments)=0;
(ii) 个人身份信息(PII)与敏感数据保护
在构建安全的AI应用时,另一个关键考量是确保任何个人身份信息(PII)都不会未经处理地进入模型层。大多数数据工程师会与跨职能团队协作,识别并标记表格中的所有PII列。此外,市面上也存在自动化PII识别工具,它们能够借助机器学习模型进行数据画像分析,从而自动标记PII列。常见的PII列包括:姓名、电子邮件地址、电话号码、出生日期、社会安全号码(SSN)、护照号码、驾驶执照号码以及生物识别数据。其他间接PII的例子还包括健康信息或财务信息。
防止此类数据进入系统的常见方法是应用去标识化机制。这可以简单到完全删除数据,也可以采用更复杂的哈希处理技术,进行数据屏蔽或假名化处理,使模型无法直接解读这些敏感信息。
– Hashing PII data of customers for data privacy
SELECT SHA2(customer_name, 256) AS encrypted_customer_name, SHA2(customer_email, 256) AS encrypted_customer_email, … FROM customer_data
(iii) 偏差检测与缓解
在数据进入模型层之前,另一个重要的检查点是验证其准确性并确保其不含偏见。常见的偏见类型包括:
- 选择偏差(Selection bias):输入数据不完整,未能准确代表全部目标受众。
- 幸存者偏差(Survivorship bias):数据更多地集中于“成功路径”,导致模型难以处理失败场景。
- 种族或关联偏差(Racial or association bias):数据因过去的模式或偏见而偏向某一特定性别或种族。
- 测量或标签偏差(Measurement or label bias):数据因标注错误或记录者的偏见而导致不准确。
- 稀有事件偏差(Rare event bias):输入数据缺乏所有边缘情况,呈现出不完整的全貌。
- 时间偏差(Temporal bias):输入数据已经过时,未能准确反映当前世界的实际情况。
虽然人们都希望存在一个简单的系统能够自动检测这些偏见,但这实际上是一项细致而艰巨的工作。数据科学家需要亲自进行深入分析,运行查询并针对每种场景测试数据,以发现潜在的偏见。例如,如果正在构建一个健康应用,但缺乏特定年龄组或BMI数据,那么数据中存在偏见的高风险就会增加。
– Identifying if any age group data or BMI group data is missing
select age_group, count(*) from users_data group by age_group;
select BMI, count(*) from users_data group by BMI;
(iv) 数据的及时可用性
另一个需要验证的重要方面是数据的及时性。模型若要良好运行,必须能够获取到正确且相关的数据。有些模型可能需要实时数据,有些则要求近实时数据,而对于某些场景,批处理数据就已足够。无论具体要求如何,都必须建立一个系统来监控所需的最新数据是否已按时到位。
例如,如果品类经理根据市场动态每晚午夜更新产品价格,那么模型必须获取到午夜之后刷新过的数据。可以部署系统在数据过时时发出警报,或者围绕数据编排层构建主动预警机制,持续监控ETL管道的及时性。
–Creating an alert if today’s data is not available
SELECT CASE WHEN TO_DATE(last_updated_timestamp) != TO_DATE(CURRENT_TIMESTAMP()) THEN 'FRESH' ELSE 'STALE' END AS table_freshness_status FROM product_data;
(v) 数据完整性
维护数据的完整性对于模型准确性至关重要。数据完整性指的是数据的准确性、完整性和可靠性。系统中任何陈旧、不相关或不正确的数据都可能导致输出结果混乱。例如,如果正在构建一个面向客户的聊天机器人,那么它必须只能访问最新的公司政策文件。如果访问了不正确的文件,可能导致模型出现“幻觉”,即将多个文件中的信息合并,并向客户提供完全不准确的答案。在这种情况下,企业仍需承担法律责任。例如,加拿大航空就曾因其聊天机器人错误地承诺退款而不得不向客户退还机票费用。
目前没有直接了当的方法来验证数据完整性,这需要数据分析师和工程师亲力亲为,仔细核查文件和数据,确保只有最新、最相关的数据被送往模型层。保持数据完整性也是控制模型“幻觉”的最佳途径,以避免“垃圾进,垃圾出”的情况发生。
2. 模型层
在完成数据层的护栏构建后,可以在模型层设置以下关键检查点:
(i) 基于角色的用户权限管理
保护AI模型层的安全至关重要,以防止任何未经授权的更改可能导致系统引入错误或偏见,同时也有助于避免数据泄露。必须严格控制谁能够访问这一层。一个标准化的方法是引入基于角色的访问控制(RBAC),只允许具有授权角色的员工,如机器学习工程师、数据科学家或数据工程师,访问模型层。
例如,DevOps工程师可以拥有只读访问权限,因为他们通常不应修改模型逻辑。而机器学习工程师则可以拥有读写权限。建立RBAC是维护模型完整性的一项重要安全实践。
(ii) 偏见审计
偏见处理是一个持续不断的过程。即使在输入层进行了所有必要的检查,偏见仍可能在系统后期悄然出现。事实上,某些偏见,特别是确认偏见(confirmation bias),往往倾向于在模型层发展。当模型过度拟合数据,导致无法捕捉细微之处时,这种偏见就会产生。在发生任何过拟合的情况下,模型都需要进行细微的校准。样条校准(Spline calibration)是一种常用的模型校准方法,它通过对数据进行微调,以确保所有数据点之间的连接更加平滑和准确。
import numpy as np
import scipy.interpolate as interpolate
import matplotlib.pyplot as plt
from sklearn.metrics import brier_score_loss
# High level Steps:
#Define input (x) and output (y) data for spline fitting
#Set B-Spline parameters: degree & number of knots
#Use the function splrep to compute the B-Spline representation
#Evaluate the spline over a range of x to generate a smooth curve.
#Plot original data and spline curve for visual comparison.
#Calculate the Brier score to assess prediction accuracy.
#Use eval_spline_calibration to evaluate the spline on new x values.
#As a final step, we need to analyze the plot by:
# Check for fit quality (good fit, overfitting, underfitting), validating consistency with expected trends, and interpreting the Brier score for model performance.
######## Sample Code for the steps above ########
# Sample data: Adjust with your actual data points
x_data = np.array([...]) # Input x values, replace '...' with actual data
y_data = np.array([...]) # Corresponding output y values, replace '...' with actual data
# Fit a B-Spline to the data
k = 3 # Degree of the spline, typically cubic spline (cubic is commonly used, hence k=3)
num_knots = 10 # Number of knots for spline interpolation, adjust based on your data complexity
knots = np.linspace(x_data.min(), x_data.max(), num_knots) # Equally spaced knot vector over data range
# Compute the spline representation
# The function 'splrep' computes the B-spline representation of a 1-D curve
tck = interpolate.splrep(x_data, y_data, k=k, t=knots[1:-1])
# Evaluate the spline at the desired points
x_spline = np.linspace(x_data.min(), x_data.max(), 100) # Generate x values for smooth spline curve
y_spline = interpolate.splev(x_spline, tck) # Evaluate spline at x_spline points
# Plot the results
plt.figure(figsize=(8, 4))
plt.plot(x_data, y_data, 'o', label='Data Points') # Plot original data points
plt.plot(x_spline, y_spline, '-', label='B-Spline Calibration') # Plot spline curve
plt.xlabel('x')
plt.ylabel('y')
plt.title('Spline Calibration')
plt.legend()
plt.show()
# Calculate Brier score for comparison
# The Brier score measures the accuracy of probabilistic predictions
y_pred = interpolate.splev(x_data, tck) # Evaluate spline at original data points
brier_score = brier_score_loss(y_data, y_pred) # Calculate Brier score between original and predicted data
print("Brier Score:", brier_score)
# Placeholder for calibration function
# This function allows for the evaluation of the spline at arbitrary x values
def eval_spline_calibration(x_val):
return interpolate.splev(x_val, tck) # Return the evaluated spline for input x_val
(iii) 以大型语言模型(LLM)作为评判者
将大型语言模型(LLM)作为评判者是一种验证模型的有趣方法,其中一个LLM被用来评估另一个LLM的输出。这种方法能够替代人工干预,支持大规模地实施响应验证。
要实现“LLM作为评判者”,需要构建一个用于评估输出的提示词(prompt)。该提示词的评估结果必须是可量化的标准,例如分数或排名。
A sample prompt for reference:
Assign a helpfulness score for the response based on the company’s policies, where 1 is the highest score and 5 is the lowest
该提示词的输出结果可以用于在检测到非预期输出时触发监控框架。
提示:近年来技术进步的优势在于,甚至无需从零开始构建一个LLM。市面上已有即插即用的解决方案,例如Meta的Llama系列模型,可以下载并在本地部署运行。
(iv) 持续微调
对于任何模型的长期成功而言,持续微调(Continuous fine-tuning)都是不可或缺的。通过持续微调,模型能够定期进行优化以提升准确性。实现这一目标的一个简单方法是引入基于人类反馈的强化学习(Reinforcement Learning with Human Feedback, RLHF),即由人类评审员对模型的输出进行评分,模型从中学习改进。然而,这一过程资源密集。若要实现大规模应用,则需要自动化。
一种常见的微调方法是低秩适应(Low-Rank Adaptation, LoRA)。在这种技术中,可以创建一个单独的可训练层,其中包含用于优化的逻辑。这样可以在不修改基础模型的前提下提高输出准确性。例如,若正在为流媒体平台构建推荐系统,且当前的推荐效果不佳,未能带来足够的点击。在LoRA层中,可以构建一个独立的逻辑,将具有相似观看习惯的观众进行聚类,并利用这些聚类数据生成推荐。该层可以持续用于生成推荐,直到达到预期的准确性。
3. 输出层
在输出层,需要进行一些最终的安全检查:
(i) 内容过滤:语言、脏话与关键词屏蔽
与输入层类似,输出层也需要进行内容过滤,以检测任何冒犯性语言。这种双重检查能够确保最终用户不会遇到不良体验。
(ii) 响应验证
通过创建一个简单的基于规则的框架,可以对模型的响应进行一些基本检查。这些检查可以包括验证输出格式、可接受的值等。这项工作在Python和SQL中都可以轻松实现。
– Simple rule-based checking to flag invalid response
select
CASE
WHEN <condition_1> THEN ‘INVALID’
WHEN <condition_2> THEN ‘INVALID’
ELSE ‘VALID’ END as OUTPUT_STATUS
from
output_table;
(iii) 置信度阈值与人工干预触发机制
没有任何AI模型是完美的,只要能够在必要时引入人工干预,这种不完美也是可以接受的。目前有可用的AI工具,允许开发者硬编码设置何时使用AI以及何时启动人工干预(Human-in-the-Loop)触发器。通过引入置信度阈值,也可以实现这一动作的自动化。每当模型对输出结果显示出较低的置信度时,即可将请求转交给人类进行处理,以获得更准确的答案。
import numpy as np
import scipy.interpolate as interpolate
# One option to generate a confidence score is using the B-spline or its derivatives for the input data
# scipy has interpolate.splev function takes two main inputs:
# 1. x: The x values at which you want to evaluate the spline
# 2. tck: The tuple (t, c, k) representing the knots, coefficients, and degree of the spline. This can be generated using make_splrep (or the older function splrep) or manually constructed
# Generate the confidence scores and remove the values outside 0 and 1 if present
predicted_probs = np.clip(interpolate.splev(input_data, tck), 0, 1)
# Zip the score with input data
confidence_results = list(zip(input_data, predicted_probs))
# Come up with a threshold and identify all inputs that do not meet the threshold, and use it for manual verification
threshold = 0.5
filtered_results = [(i, score) for i, score in confidence_results if score <= threshold]
# Records that can be routed for manual/human verification
for i, score in filtered_results:
print(f"x: {i}, Confidence Score: {score}")
(iv) 持续监控与警报
与任何软件应用程序一样,AI模型同样需要一个能够检测预期和非预期错误的日志记录与警报框架。借助这一护栏,可以为每一次操作生成详细的日志文件,并在出现问题时自动触发警报。
(v) 监管合规性
许多合规性处理工作早在输出层之前就已经完成。合法可接受的用例在最初的需求收集阶段就已经确定。任何敏感数据都会在输入层进行哈希处理。在此之外,如果存在任何额外的监管要求,例如对某些数据进行加密,则可以在输出层通过简单的基于规则的框架来实现。
平衡AI与人类专业知识
技术护栏有助于充分发挥AI自动化的优势,同时仍能对整个过程保持必要的控制。本文已经涵盖了在模型不同层级可能需要设置的所有常见护栏类型,旨在为AI应用的稳健发展提供指引。