

作为本数据可视化系列文章的第三部分,本文将深入探讨色彩在数据呈现中的核心作用。此前,读者可回顾第一部分:“数据可视化解析:何谓数据可视化,为何它至关重要”,以及第二部分:“数据可视化解析(第二部分):视觉变量简介”。
观察下图,您会看到什么?

大多数人会看到四种颜色:白色、绿色以及两种不同深浅的粉红色调。然而,实际上这两种粉红色调是完全相同的,图片中只有三种颜色。
这个广为人知的光学错觉揭示了一个在设计数据可视化时必须考虑的重要事实:选择不当的颜色组合可能会欺骗人眼。要全面探讨色彩,需要深入研究人眼的生理机制以及我们感知色彩的实际方式。
然而,鉴于本文并非眼科学术论文,因此将重点关注构建清晰数据可视化所需的色彩使用基础原则。
色相与明度:色彩的关键区分
在前一篇文章中,介绍了视觉编码通道,其中包含两种与色彩相关的通道:色相(hue)和明度(value)。在此,将对它们进行正式讨论。
色相通常是人们听到“颜色”一词时首先想到的概念。红色、绿色、蓝色、粉色、黄色等都属于不同的色相。而明度,则指的是单一色相的“亮度”。下图展示了彩虹色系的不同明度,说明了相同的色相如何通过亮度/饱和度产生显著变化:

图片来源:Wikimedia Commons
尽管色相和明度都可以作为有效的视觉编码(详见本系列前文关于视觉编码的讨论),但明度相对于色相有一个显著优势:即使可视化图表以灰度打印,其信息仍可被感知。
色彩刻度类型
若要将色彩作为视觉编码使用,首先需要选择合适的色彩刻度。在选择过程中,有几个特性需要考虑:
- 如果数据是名义型的(nominal),可以使用分类色彩刻度,这类刻度仅依赖于色相。
- 对于定量数据,则需要额外做出两项决策:1) 刻度是顺序型还是发散型(即使用一种还是两种色相),以及 2) 刻度是连续型还是分级型。
因此,共有五种可用的色彩刻度,本文将逐一探讨:1) 顺序型无分级,2) 顺序型分级,3) 发散型无分级,4) 发散型分级,以及 5) 分类型 [1]。
顺序型刻度(单一色相)适用于可视化从低到高的数值。当数值从负到正变化,或设计者希望强调刻度两端颜色之间的差异时,发散型刻度会非常有用。
当然,这些只是一般性规则。不同类型的刻度最适合特定的可视化场景,有时甚至多种刻度都能适用。
顺序型无分级刻度
以下地图使用顺序型、无分级的色彩刻度,展示了2011年人口普查时澳大利亚圣公会教徒的比例。可以看出,单一的绿色色相从浅到深逐渐增加其明度。由于只使用了一种颜色,因此没有发散,且由于刻度是连续的,所以没有分级。
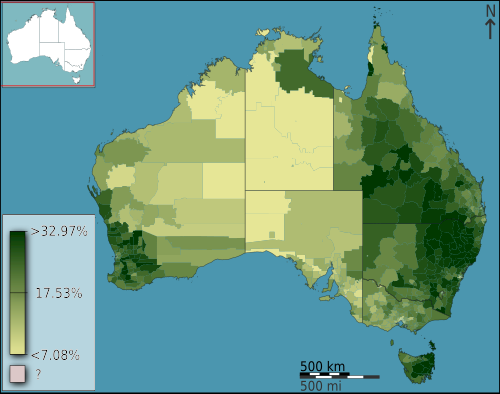
图片来源:Toby Hudson (Wikimedia Commons)
顺序型分级刻度
与上述可视化图表不同,下图的美国地图具有离散的分级,其颜色明度各异。它仍然是顺序型的,仅使用了粉红色调。随着各县20多岁成年人百分比的增加,颜色的明度也随之加深。
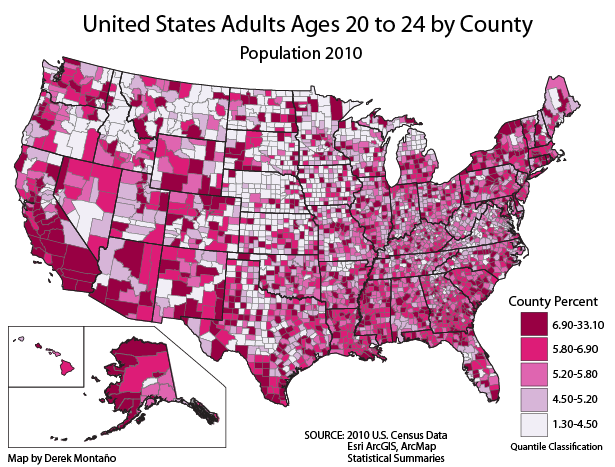
此可视化图表的一个值得注意之处是分级的不均匀性(请注意最大类别的宽度)。这并非总是最佳实践,尤其是在未给出理由的情况下。图片来源:Derek Montaño (Wikimedia Commons)。
发散型分级与无分级刻度
发散型刻度理解起来稍显复杂,因此将通过对比示例一同探讨这两种类型。同时,也将借此机会观察分级和无分级刻度的不同优势。
以下两张图表是使用Python和模拟数据生成的。这些数据包含以下视觉表示(即视觉编码通道):
- X轴代表商店位置编号。
- Y轴代表月份。
- 颜色代表虚构商店通过月度调查收集的“客户满意度评分”。
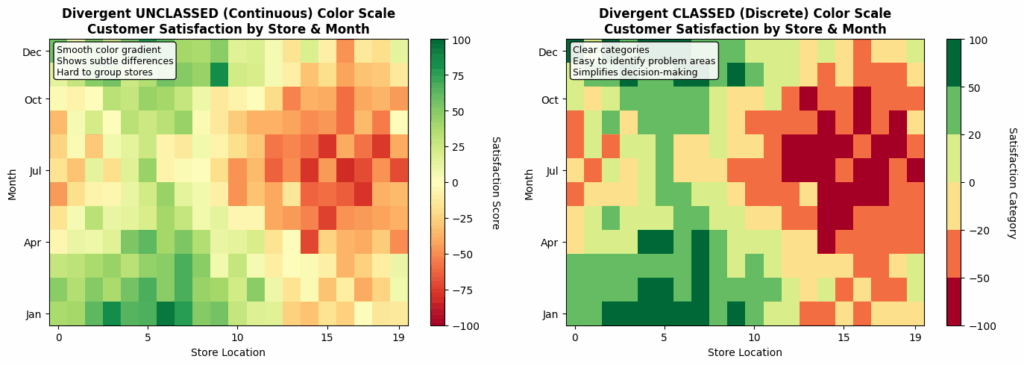
这些可视化图表的“分级与无分级”方面与上述顺序型刻度非常相似。在左侧(无分级)刻度中,表示了数值的完整范围;而在右侧(分级)刻度中,颜色代表了按组划分的数值区间。左侧的可视化提供了更高的精确度,但右侧的图表则更容易解释和应用。
这些刻度的发散性方面更为复杂,具体分析如下:
- 这里的发散型刻度使用了两种颜色:红色和绿色(这并非世界上最易于访问的颜色,后续章节将讨论)。
- 中性白色(或分级刻度中的两种浅色)代表数据中一个逻辑上的“中点”,在本例中是值 0。
- 这个中点是关键,它使得发散型刻度非常适合此类数据。如果数值只是单向变化而没有一个有意义的中心点,使用多种颜色就没有太大意义。
分类型刻度
最后一种,也是可以说最直接的色彩刻度类型,是分类型刻度。下图清晰展示了各国政府资金分配情况,提供了一个明确的例子。
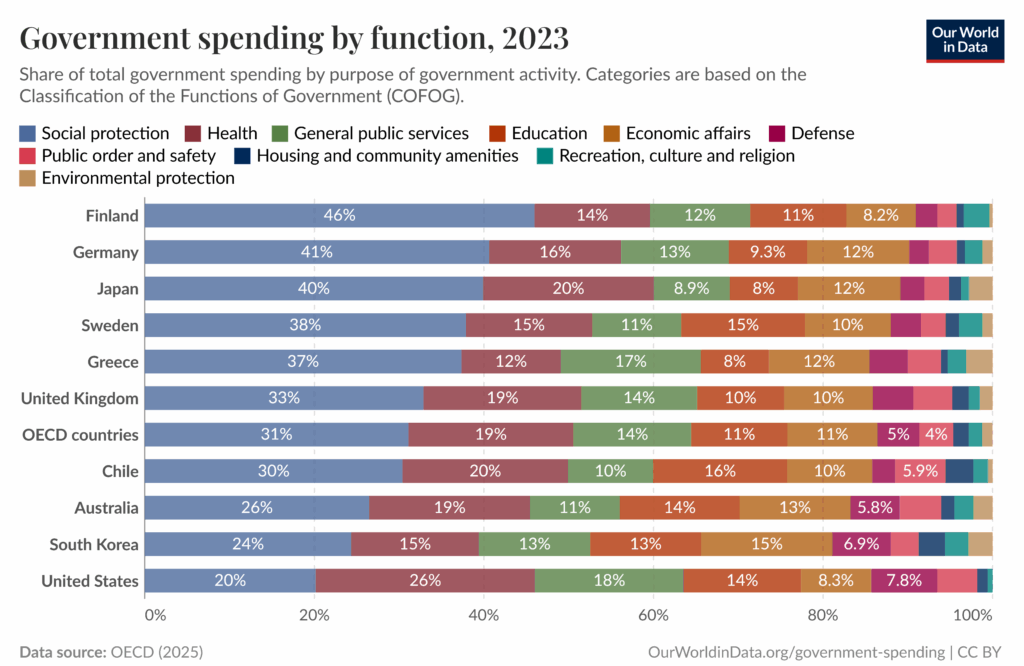
图片来源:Our World in Data
如果读者一直关注本章迄今讨论的原则,可能会发现这并非一个设计得特别出色的数据可视化图表。它虽然传达了大致要点,但颜色种类过多,导致最终设计显得有些混乱。
尽管如此,它仍然有效运用了分类型刻度,正确地将这种刻度类型应用于名义数据(具有独特、无序类别的数据)。数据可视化中一个常见的错误——也是读者应尽力避免的——是当数据呈现明确的数值增减趋势时,却使用带有多种不同色相的分类型刻度。在这种情况下,应根据具体数据情况,参考上文讨论的顺序型或发散型色彩刻度。
以上总结了进行有效数据可视化必须了解的色彩刻度基础知识。最后,再提供几个关于如何更好地使用色彩的建议。
避免冗余的色彩使用
在可视化中,当色彩并非必需时,很容易忍不住使用它。例如,常见的条形图明明有清晰的X轴标签来区分各条形,却仍然使用不同颜色的条形。
这并非错误,但可能是不必要的。如果类别很少,且它们与其他可视化图表相关联,那么使用颜色作为额外的视觉提示当然可以。然而,如果可视化图表在没有色彩的情况下也能正常发挥作用,则无需强行添加。
通常,除非能为观看者提供额外的解释便利性,否则应避免任何和所有冗余的编码(表示)。这要么是浪费,因为该编码通道本可用于不同的变量;要么是令人困惑,因为观看者会试图判断额外的编码是否描绘了他们不理解的信息。
确保配色方案无障碍
这一点虽短,但极其重要。不要仅仅因为您能区分可视化中的颜色,就假设所有人都能做到。数据可视化应该对所有人开放,包括患有各种色盲症的人群 [2]。
例如,考虑上文发散型色彩刻度部分中的Python可视化图表。您认为患有红绿色盲症的人能否正确解读它?可能性不大。
幸运的是,我们无需做太多额外工作来确保可视化图表的无障碍性。有无数在线工具 [3, 4, 5] 可以自动检查所选配色方案的无障碍性。有些甚至能帮助您生成配色方案。请充分利用这些工具,使您的可视化图表尽可能地无障碍。
总结
至此,本系列文章的第三部分已带领读者掌握了设计引人入胜的数据可视化图表的关键原则。接下来的文章将引导读者亲手设计并构建可视化图表!敬请期待。
参考文献
[1] https://blog.datawrapper.de/which-color-scale-to-use-in-data-vis/





{kind=link}
{kind=link}