

最近,两篇新论文正在学术圈引发热议。
Google的ReasoningBank和斯坦福的ACE(Agentic Context Engineering)研究方向看似不同,实则都在解决同一个根本问题:如何让AI系统真正学会学习。
这种学习并非仅限于训练阶段,也非局限于数据集,而是指AI在使用过程中,能从自身经历中持续学习和进化。
重复犯错的AI:传统模型学习瓶颈
想象这样一个场景:当AI助手被要求在购物网站上找到某个商品的首次购买日期时,它可能先点击“最近订单”,只看到了最近的购买记录,从而错误地报告了最近一次的日期。下次遇到类似任务,它仍可能重复相同的操作,再次失败。
这正是目前大多数AI系统的现状。Google研究团队在论文中指出,即使是最先进的大语言模型Agent,也会不断重复相同的错误,因为它们缺乏从过往经验中学习的能力。每次任务都是孤立的,宝贵的经验被丢弃,导致错误不断重演。
Google的解法:ReasoningBank——AI的经验管理系统
Google提出的ReasoningBank,本质上是一个AI的经验管理系统,旨在赋能AI从自身经验中学习。它包含三个核心组件:
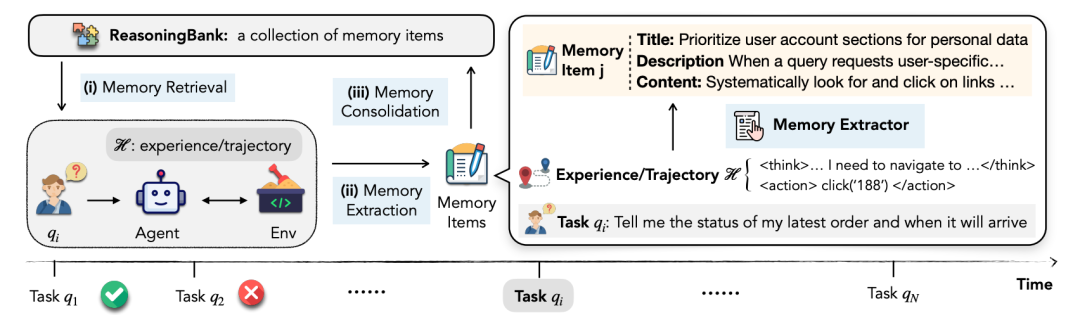
记忆提取:系统将每个执行轨迹转化为结构化的记忆项,每项包含标题(核心策略总结)、描述(一句话概述)和内容(具体的推理步骤和见解)。
双向学习:与以往只存储成功经验不同,ReasoningBank同时从成功和失败中学习。成功的轨迹提供验证过的策略,失败的轨迹则提供反面教训和需要避免的陷阱。
智能检索:面对新任务时,系统通过嵌入向量搜索找到最相关的记忆项,将其注入到系统提示中,指导决策。
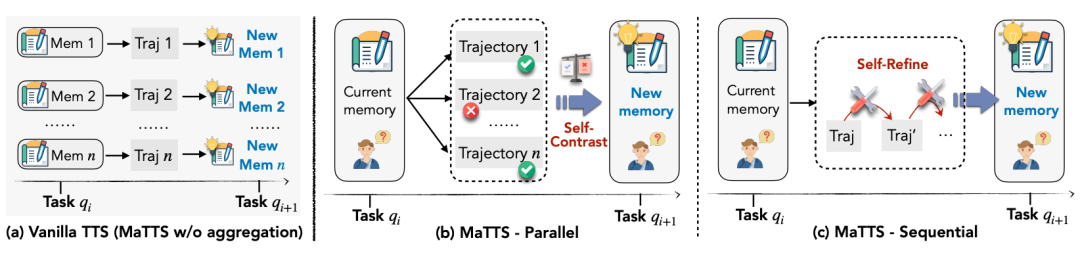
更进一步,论文提出了MaTTS(Memory-aware Test-Time Scaling)机制。通过并行生成多个轨迹或迭代优化单个轨迹,系统获得丰富的对比信号,从而合成更高质量的记忆。
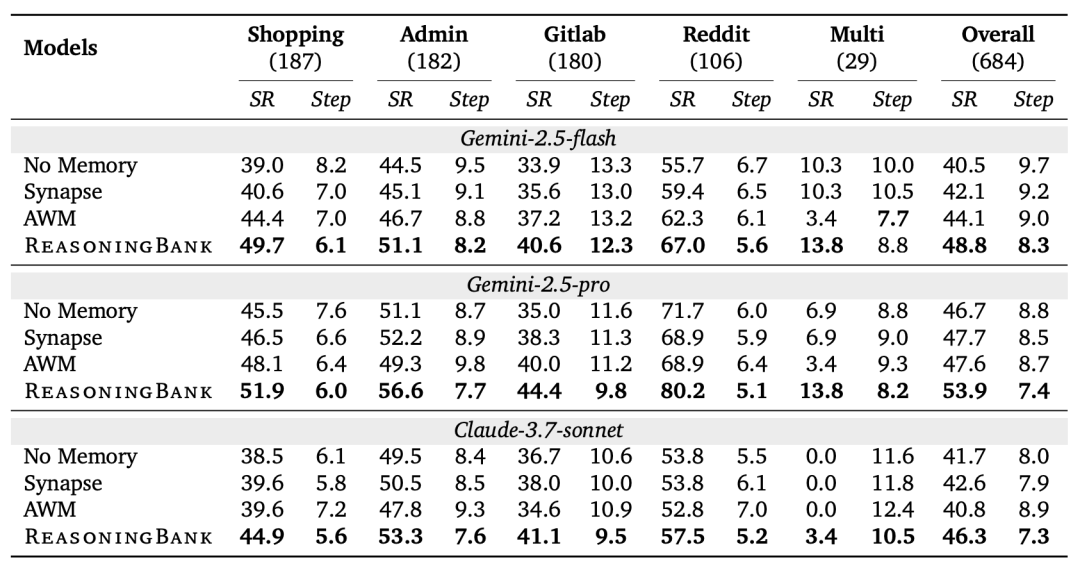
实验结果令人瞩目:在WebArena网页导航任务上,配备ReasoningBank的Gemini-2.5模型成功率从40.5%提升到48.8%,平均步数从9.7减少到8.3。在SWE-Bench代码修复任务上,平均步数减少了2.8步。
斯坦福的创新:ACE框架——活的提示词
斯坦福的ACE框架(Agentic Context Engineering)则走了完全不同的路线。该研究团队认为,与其修改模型权重,不如让输入上下文本身进化。
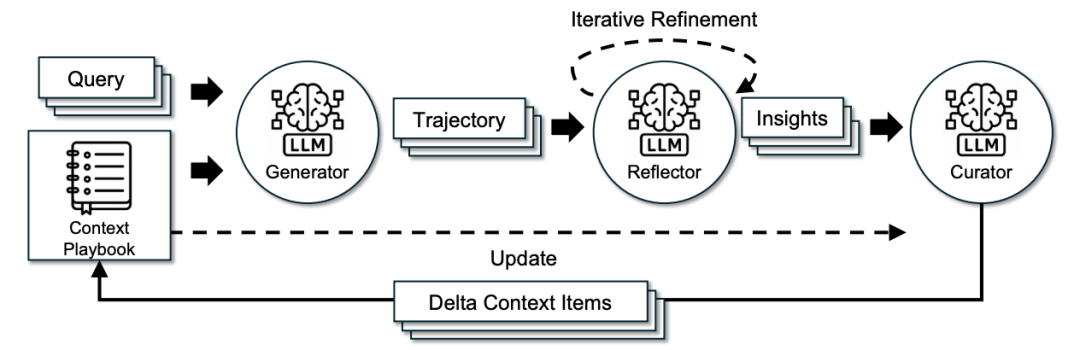
ACE将模型Agent分成三个专门角色:
- 生成器(Generator):负责执行实际任务。
- 反思器(Reflector):负责分析执行轨迹,提取成功原因或失败教训。
- 策展人(Curator):负责将见解整合成结构化的上下文更新。
关键创新在于“增量更新”机制。传统方法倾向于重写整个提示词,容易导致“上下文崩溃”,即提示词越来越短,细节逐渐丢失。ACE则采用增量的“delta更新”,每次只添加或修改相关部分,有效保持知识的连续性。
在AppWorld基准测试上,ACE实现了惊人的提升:任务完成率达到76.2%(基线仅63.7%),在更困难的challenge分割上提升更是达到24.5%。更重要的是,ACE将适应延迟降低了86.9%,成本降低了80%以上。
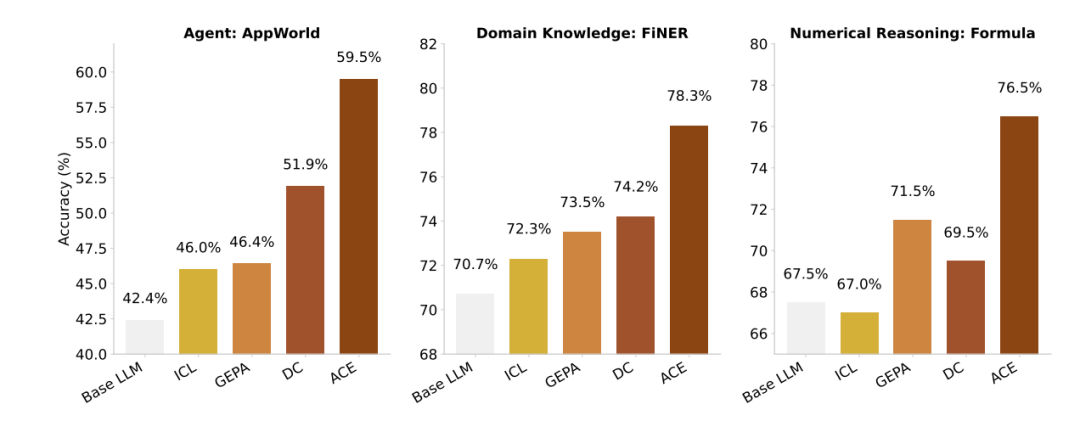
智能涌现:AI学习的进化轨迹
这两项研究都观察到了有趣的智能涌现行为。ReasoningBank中的记忆项会随时间演化,从简单的执行指令(如“找到导航链接”)逐步发展为复杂的组合策略(如“交叉验证需求并重新评估选项”)。这种演化过程类似于人类从新手到专家的成长轨迹。
ACE生成的上下文则变成了详尽的“操作手册”,其中包含领域特定的见解、工具使用指南,甚至可直接使用的代码片段。研究发现,与人类偏好简洁不同,大语言模型在面对长而详细的上下文时表现更好——它们能够自主提取相关信息。
AI学习新范式:告别微调,迈向持续进化
结合Google的ReasoningBank和斯坦福的ACE来看,AI学习正在发生从“无状态的计算工具”向“有记忆的智能体”的范式转变。这两篇论文都在绕开传统微调,在模型外围寻找解决方案,探索如何让AI系统真正具备持续学习和自我改进的能力。
ReasoningBank让Agent记住具体教训,而ACE则让上下文持续优化。一个侧重外部记忆,一个侧重内部流程。如果将两者结合,将得到一个既能积累经验(ReasoningBank),又能优化方法(ACE)的强大系统。
AI不仅需要变得更聪明,更要学会如何学习。“活的提示词”和“会学习的记忆”时代可能真的要来了。




