

通用大模型在实际应用中并非总是“靠谱的专家”。在企业级智能客服、知识库管理等场景中,它们常出现“幻觉”现象,即便资料库中存在答案,也可能生成貌似合理但实为编造的内容。为有效降低此类风险,越来越多的企业选择引入文本Embedding技术,通过精准提取信息后再交由大模型生成回复。
然而,文本Embedding模型也面临“负迁移”的挑战。“负迁移”指模型在通用语料等原训练领域表现良好,但由于新领域语境和表达方式的差异,其性能可能急剧下降。
例如,将通用Embedding模型应用于法律合同分析时,若用户提问“这份协议的甲方有哪些权利?”,模型可能难以准确找到答案。这是因为模型倾向于依赖通用语料中“甲方”、“权利”等常见搭配,却可能忽视合同中真正的关键表述,如“许可方享有下述独家授权”。这导致检索结果看似相关实则无关,错失了最重要的信息。
为解决这一难题,腾讯优图实验室正式开源了Youtu-Embedding模型。
Youtu-Embedding是一款专为企业级应用设计的通用文本表示模型,能够同时胜任文本检索、意图理解、相似度判断、分类聚类等六大主流任务。它不仅有效避免了“负迁移”带来的性能限制,还具备即插即用的通用性。
开源后,开发者可直接利用Youtu-Embedding构建语义检索系统,也可基于其训练框架,结合自身业务数据进行进一步训练,从而打造更符合特定场景需求的语义基础能力。
这款“全能”模型的炼成,主要通过以下三步实现——
//第一步:通读3万亿Token语料,打好语言底子
模型若要具备强大的理解力,首要任务是奠定坚实的语言基础。Youtu-Embedding并非基于现有开源模型进行微调,而是从零开始训练,利用3万亿Token的中英文语料构建了语言理解的基本盘。
同时,充足的“数据燃料”也至关重要,其中包括人工精标的语义任务数据、常见中文表达的真实语料,以及通过大模型辅助生成并经人工筛选的合成样本。这些数据不仅数量庞大、结构清晰,更关键的是贴近真实业务语境,为后续多任务协同训练奠定了语言理解基础。
//第二步:建好语义桥梁,让模型理解真实意图
语言模型天然擅长“生成”任务,但语义检索、相似度判断等功能则更侧重于“理解”和“判断”能力。
通过引入大规模弱监督训练,模型实现了从“语言建模者”到“语义理解者”的转变。例如,用户提问“这款产品保修多久?”与“坏了可以免费修吗?”——尽管用词和句式有所不同,但语义相近,均是在询问保修期。
此类训练使模型能够识别“表达不同但意图一致”的句子,并在向量空间中建立准确的语义映射。
//第三步:创新微调框架,多任务协同进化
为使模型真正落地业务场景,需要其能适配具体任务的复杂规则与多样需求,例如检索任务要求判断文本与问题的接近程度,分类任务则需为内容打上恰当标签。
各类任务的训练方式各异,若不加区分地进行训练,可能导致模型混淆或能力相互干扰。为解决“多任务训练”的挑战,该模型设计了一套创新的“协同-判别式微调框架”,其核心做法包括:
●统一格式:针对不同语义任务(如文本相似度、文本检索)迥异的数据结构,采用统一建模方式实现格式标准化,使模型无需切换理解不同格式,即可适应各类任务;
●差异化训练:为每类任务定制专属的损失函数,相当于为不同任务类型设定不同的“评分标准”。例如,检索任务仅需模型粗略判断文本与问题“相关”或“不相关”;而语义相似度任务则需更细致地区分“非常相似”、“有点相似”、“基本无关”等不同程度。通过差异化设计,模型能明确每类任务的评估方式及优化方向,从而更精准地提升各项能力;
●动态采样:考虑到不同任务的难度和重要性差异,引入动态采样机制,使模型在训练过程中能够按阶段“合理分配精力”。如同安排课程表,模型并非一股脑儿混学所有任务,而是“有计划地轮训”——例如今天重点训练“检索”,明天专攻“语义相似度”。这种方式确保模型在各类任务上都能扎实学习,避免顾此失彼或出现“偏科”。
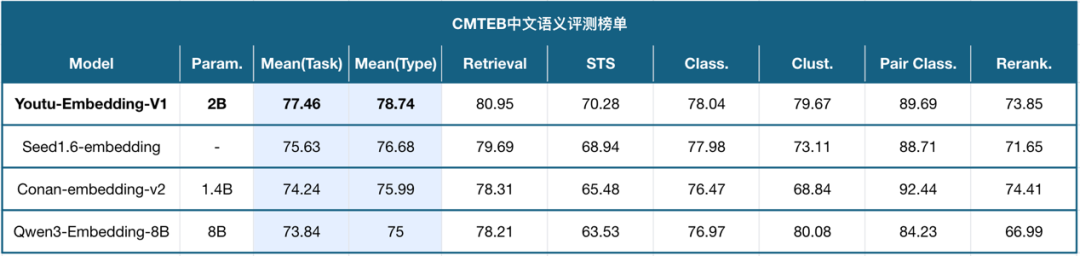
Youtu-Embedding的实力已获得权威检验——
在中文语义评测基准CMTEB上,Youtu-Embedding此前以77.46分的综合成绩登顶,成为表现最均衡的中文语义模型之一。
Youtu-Embedding可广泛应用于企业客服、智能问答、内容推荐、知识管理等场景,尤其适用于构建RAG检索增强生成系统。
同时,Youtu-Embedding支持集成至LangChain、LlamaIndex等主流框架,实现“开箱即用”,从而降低开发门槛,助力开发者快速构建更智能的语义应用。
自九月以来,腾讯优图实验室已陆续开源了Youtu-Agent和Youtu-GraphRAG,以及Youtu-Embedding。
真正的AI价值不仅在于性能提升,更在于底层能力的持续夯实与对开发者生态的长期开放。
欢迎开发者访问GitHub获取源码、查看技术报告。详情请查阅以下链接:
●GitHub源码(含微调框架):
https://github.com/TencentCloudADP/youtu-embedding.git
●Hugging Face模型下载(效果全面领先的2B量级模型):
https://huggingface.co/tencent/Youtu-Embedding
●论文链接:
https://arxiv.org/abs/2508.11442





