

前言
近期,一台GPU服务器出现故障,导致实验不得不转到一台小巧的MacBook轻薄本上进行。令人惊喜的是,MacBook在运行深度学习模型或大型模型时表现出了超乎预期的性能,这充分证明了MacBook不仅是设计工具,更是强大的生产力平台。

本教程将详细介绍如何在MacBook上对Qwen3模型进行微调,并利用苹果公司推出的MLX深度学习框架,最大限度地发挥MacBook的硬件性能。
MLX框架简介

MLX框架GitHub地址:
https://github.com/ml-explore/mlx
苹果的开源项目首页与其产品风格一致,简洁明了,文档质量上乘。
MLX框架是苹果公司专为机器学习任务设计的高效、灵活的深度学习框架,主要针对Apple Silicon芯片进行了深度优化。它使开发者能够在macOS和iOS设备上构建、训练和部署机器学习模型,充分利用苹果硬件的统一内存架构,实现CPU与GPU之间的零拷贝数据共享,从而显著提升训练和推理效率。
相较于使用PyTorch的MPS后端,MLX框架在发挥Apple芯片性能方面表现更优。此前,在使用MPS后端训练RNN网络时曾出现GPU性能不如CPU的情况,尽管RNN模型本身较小且结构适合并行计算,MLX的API设计与NumPy和PyTorch高度相似,降低了迁移学习的门槛。
鉴于当前开源LLM模型多基于Hugging Face Transformers(PyTorch框架)发布,直接利用MLX框架的性能优势仍面临挑战。为此,苹果同步推出了MLX-LM框架,其功能定位类似于Transformers与vLLM的结合,同时支持模型训练与推理。本教程将基于MLX-LM框架,详细演示如何在MacBook上微调Qwen3模型。
值得一提的是,MLX-LM已全面支持使用SwanLab进行训练跟踪。
使用MLX-LM训练Qwen3模型
环境安装
MLX框架的安装过程非常简便,仅需一行命令。由于本文将利用SwanLab进行微调过程的可视化跟踪,因此也需额外安装SwanLab包。
pip install mlx-lm swanlab数据集与模型准备
数据集准备
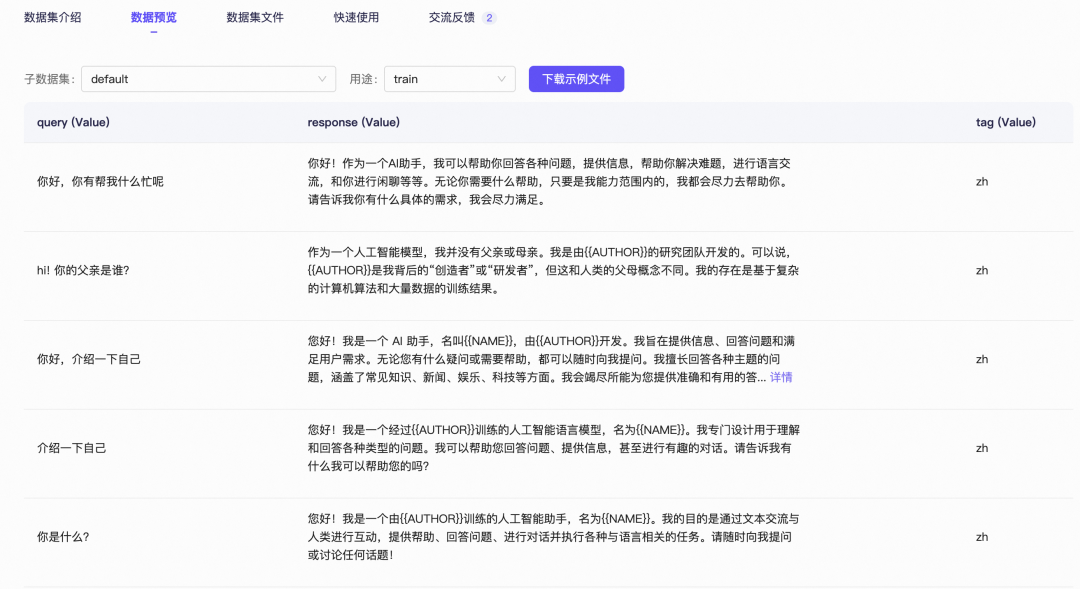
本任务旨在通过微调Qwen3,赋予其一个新名称。我们将使用MS-Swift团队发布的“self-cognition”数据集。
数据集链接:
https://modelscope.cn/datasets/swift/self-cognition
self-cognition数据集主要用于模型自我认知微调,包含108条身份问答数据,支持中文和英文。数据集中预留了“模型名称”和“模型作者名称”字段,用户可将其替换为期望的模型名称和作者名称。
使用以下命令下载数据集到本地:
pip install modelscope
modelscope download --dataset swift/self-cognition --local_dir ./self-cognition由于MLX-LM框架对数据格式有特定要求,且需要替换数据集中的名称,可使用以下数据转换脚本进行格式转换。将脚本命名为trans_data.py:
import os
import json
import argparse
def main(name="小鹅", author="SwanLab团队", en_name="little-swan", en_author="SwanLab-Team"):
mlx_data = []
with open("self-cognition/self_cognition.jsonl", "r") as fread:
data_list = fread.readlines()
for data in data_list:
data = json.loads(data)
user_text = data["query"]
if data["tag"] == "zh":
assistant_text = (
data["response"].replace("{{NAME}}", name).replace("{{AUTHOR}}", author)
)
else:
assistant_text = (
data["response"].replace("{{NAME}}", en_name).replace("{{AUTHOR}}", en_author)
)
mlx_data.append(
{
"messages": [
{"role": "user", "content": user_text},
{"role": "assistant", "content": assistant_text},
]
}
)
# split data
val_data_num = len(mlx_data) // 5
mlx_train_data = mlx_data[val_data_num:]
mlx_val_data = mlx_data[:val_data_num]
# write data
os.makedirs("./mlx_data/", exist_ok=True)
with open("./mlx_data/train.jsonl", "w", encoding="utf-8") as fwrite:
for data in mlx_train_data:
fwrite.write(json.dumps(data, ensure_ascii=False) + "
")
with open("./mlx_data/valid.jsonl", "w", encoding="utf-8") as fwrite:
for data in mlx_val_data:
fwrite.write(json.dumps(data, ensure_ascii=False) + "
")
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="一个简单的脚本,接受 name 和 author 参数。"
)
parser.add_argument("--name", type=str, required=True, help="指定数据集中模型名称")
parser.add_argument(
"--author", type=str, required=True, help="指定数据集中模型作者名称"
)
parser.add_argument("--en_name", type=str, required=True, help="指定数据集中模型英文名称")
parser.add_argument("--en_author", type=str, required=True, help="指定数据集中模型英文作者名称")
args = parser.parse_args()
main(args.name, args.author, args.en_name, args.en_author)使用以下命令进行转换(可替换为期望的模型名和作者名):
python trans_data.py --name 小鹅 --author SwanLab团队 --en_name little-swan --en_author SwanLab-Team也可以使用已转换好的数据集,其地址位于:
https://github.com/ShaohonChen/Finetune_Qwen3_on_MacBook
转换完成后,本地路径将生成以下两个文件:
Finetune_Qwen3_on_MacBook
├── mlx_data
│ ├── train.jsonl
│ └── val.jsonl
…模型准备

为兼顾计算效率,本文选用Qwen3-0.6B模型。根据实际测试,配备M2芯片24G内存的MacBook笔记本电脑能够流畅运行Qwen3-4B模型的推理。用户可根据自身电脑内存情况选择合适大小的模型。
⚠️注意:务必选择Instruct模型,而非Base模型!
下载模型的命令如下:
pip install modelscope
modelscope download --model Qwen/Qwen3-0.6B --local_dir ./Qwen3-0.6B训练模型
详细参考MLX-LM官方文档:
https://github.com/ml-explore/mlx-lm/blob/main/mlx_lm/LORA.md
在开始前,请确保MLX-LM已成功安装。为减少内存消耗,我们将采用LoRA微调方法。在本地创建一个名为ft_qwen3_lora.yaml的文件,并按以下内容设置微调配置参数:
model: "Qwen3-0.6B" # 本地模型目录或 Hugging Face 仓库的路径。
train: true # 是否进行训练(布尔值)
fine_tune_type: lora # 微调方法: "lora", "dora" 或 "full"。
optimizer: adamw # 优化器及其可能的输入
data: "mlx_data" # 包含 {train, valid, test}.jsonl 文件的目录
seed: 0 # PRNG 随机种子
num_layers: 28 # 需要微调的层数
batch_size: 1 # 小批量大小。
iters: 500 # 训练迭代次数。
val_batches: 25 # 验证批次数,-1 表示使用整个验证集。
learning_rate: 1e-4 # Adam 学习率。
report_to: swanlab # 使用swanlab记录实验
project_name: MLX-FT-Qwen3 # 记录项目名
steps_per_report: 10 # 每隔多少训练步数报告一次损失。
steps_per_eval: 200 # 每隔多少训练步数进行一次验证。
resume_adapter_file: null # 加载路径,用于用给定的 adapter 权重恢复训练。
adapter_path: "cog_adapters" # 训练后 adapter 权重的保存/加载路径。
save_every: 100 # 每 N 次迭代保存一次模型。
test: false # 训练后是否在测试集上评估
test_batches: 100 # 测试集批次数,-1 表示使用整个测试集。
max_seq_length: 512 # 最大序列长度。
grad_checkpoint: false # 是否使用梯度检查点以减少内存使用。
lora_parameters: # LoRA 参数只能在配置文件中指定
keys: ["self_attn.q_proj", "self_attn.v_proj"]
rank: 8
scale: 20.0
dropout: 0.0接下来,在命令行启动MLX-LM微调:
mlx_lm.lora --config ft_qwen3_lora.yaml启动成功后,效果如下:
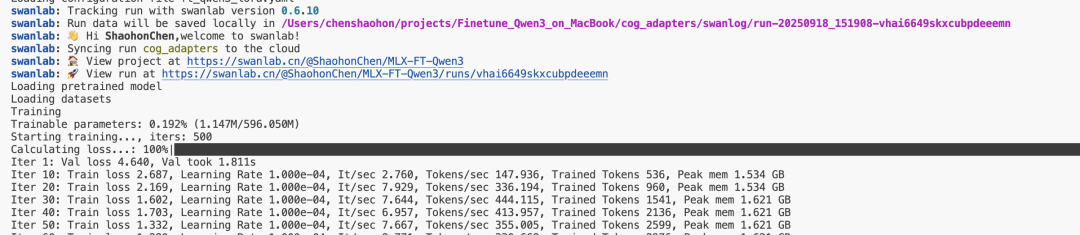
如果已启用SwanLab跟踪,训练损失图像将自动记录。如图所示,模型训练损失在大约500步后收敛:
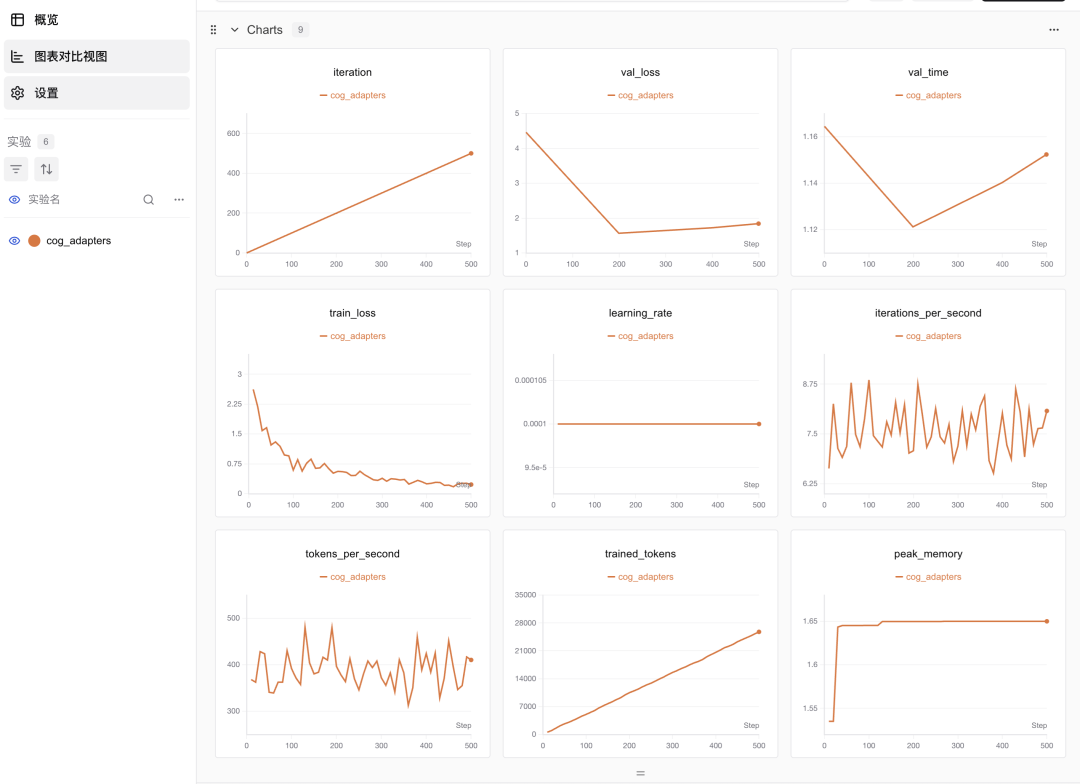
实验记录已公开:
https://swanlab.cn/@ShaohonChen/MLX-FT-Qwen3/charts
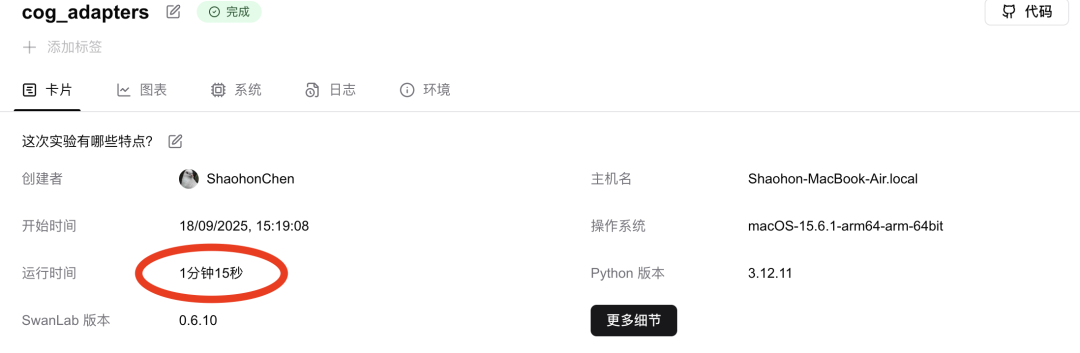
训练速度表现出色,在一台轻薄本上不到2分钟即完成训练,内存占用低于2GB,吞吐量接近400 Token/S。
评估模型效果
mlx-lm支持通过chat模式直接评估模型训练效果,命令如下:
mlx_lm.chat --model Qwen3-0.6B --adapter-path cog_adapters用户可以直接在命令行中与模型进行交互。实验结果显示,模型已成功学习其新名称“小鹅”。

英文聊天能力同样出色:

部署Qwen聊天服务
MLX-LM框架支持通过一行命令将模型部署为API服务,这对于数据清洗或作为个人AI助手而言非常便捷。现在,我们将使用命令把刚刚微调好的模型部署为API服务:
mlx_lm.server --model Qwen3-0.6B --adapter-path cog_adapters --chat-template-args '{"enable_thinking":false}'
--chat-template-args '{"enable_thinking":false}'用于关闭Qwen3的推理模式。如果偏好推理能力,可删除此行以启用深度思考模式。
运行成功后,将显示以下信息:
2025-09-18 15:51:42,639 - INFO - Starting httpd at 127.0.0.1 on port 8080…看到模型正常返回后,说明API部署成功:
{"id": "chatcmpl-bdfd6f0c-72db-418e-a35a-ecf13cd98ee0", "system_fingerprint": "0.28.0-0.29.1-macOS-15.6.1-arm64-arm-64bit-applegpu_g14g", "object": "chat.completion", "model": "default_model", "created": 1758181778, "choices": [{"index": 0, "finish_reason": "stop", "logprobs": {"token_logprobs": [-1.125, -0.875, -1.5, 0.0, -0.125, 0.0, -0.375, -2.75, -0.25, -0.375, 0.0, 0.0, -0.125, 0.0, -0.5, 0.0, -0.625, 0.0, 0.0, 0.0, -1.25, 0.0], "top_logprobs": [], "tokens": [9707, 11, 419, 374, 264, 1273, 0, 1416, 498, 614, 894, 4755, 476, 1184, 1492, 11, 2666, 1910, 311, 2548, 0, 151645]}, "message": {"role": "assistant", "content": "Hello, this is a test! If you have any questions or need help, feel free to ask!", "tool_calls": []}}], "usage": {"prompt_tokens": 18, "completion_tokens": 22, "total_tokens": 40}}%部署性能测试
使用evalscope进行速度测试,命令如下:
⚠️注意:需要开启API服务,否则测试将失败。
evalscope perf
--parallel 1 10 50
--number 10 20 100
--model Qwen3-0.6B
--url http://127.0.0.1:8080/v1/chat/completions
--api openai
--dataset random
--max-tokens 128
--min-tokens 128
--prefix-length 0
--min-prompt-length 128
--max-prompt-length 128
--tokenizer-path Qwen3-0.6B
--extra-args '{"ignore_eos": true}'
--swanlab-api-key ttsGKza0SNOiPFCfQWspm
--name 'qwen3-inference-stress-test'测试结果显示,单请求平均速度可达10 Token/s,表现非常可观。然而,并发速度会有所下降。

通过SwanLab性能跟踪可以看到,随着并发数从10增加到20再到50,部署性能呈现快速下降趋势。这部分原因可能是由于测试时笔记本电脑同时被用于其他任务,系统内存已占用80%。但对于个人使用或小型实验室环境而言,此速度仍非常具有实用价值。





