

ChatGPT6,自主进化的大模型
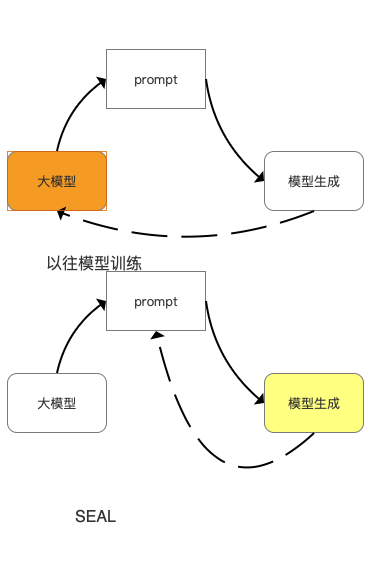
一篇最新研究论文揭示了未来大模型的发展方向与实现方法。该论文提出了一种超越传统强化学习和监督学习的模型优化方法。其核心在于通过监督模型每次生成机制(即prompt),对比生成结果,并持续优化效果更佳的prompt进行再训练。此外,该方法还支持模型自主生成内容并用于自身训练,从而实现AI模型的自我进化。
论文以学生考前复习碎片化笔记为例,指出人类通过阅读笔记重组知识、加深记忆以提升考试表现。AI模型亦可借鉴此模式,将零散知识内容进行组合、重建,生成更精准的内容。模型每次生成后,会评估其效果,并据此不断优化其策略“prompt”,最终实现模型的进化。
该研究中,团队利用ARC方法(完成模型生成数据),对碎片数据进行组块、重建以生成完整内容,并通过模型自校验其提示词的最佳性,持续提升模型优化提示词的能力,实现自我进化与学习。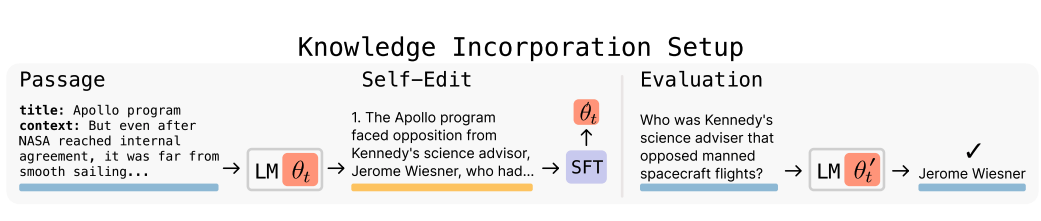
如图所示,研究表明,通过名为SEAL(自我学习大模型)的框架,在少量知识块的条件下,模型生成的准确度能够达到与ChatGPT4.1相当的水平。与传统模型训练相比,该框架的核心区别在于其对生成策略(即Prompt)的持续优化。
研究文献展示了SEAL方法的实现效果:模型在接收输入内容后,通过反复重写以实现自我提升,每次重写后的内容准确度均有提高。其中,首次重写与最终重写的内容在长度和质量上均有显著变化。
可以预见,该框架亦可应用于图像模型,实现模型几乎零标注的自我训练。用户在完成一轮任务后,模型即可利用任务图片数据集完成自我提升训练。这项技术有望使医生、律师、产品经理乃至程序员在各自专业领域实现更高的准确性和目标达成度。
然而,SEAL模型框架的研究也存在限制,即“灾难性遗忘”。随着时间的推移,知识陈旧可能导致模型回溯准确度降低,甚至出现幻觉,这源于模型的过度拟合和过度蒸馏。目前,AI模型的灾难性遗忘是一个普遍难题。有实验表明,对一张图像在通用模型上进行数百次重复训练后,模型最终会生成女性二次元图像,这反映了由于大模型数据源中包含大量女性角色和二次元图片,导致模型过度拟合的现象。
如图所示,莱斯大学(Rice University)的算法研究表明,将一张图片反复训练后,最终生成的结果可能是另一个人物,甚至性别都发生变化。因此,如何存储和检索过往数据,是该算法后续需要探索的方向。该论文提出了后续研究计划,旨在解决记忆问题,例如通过整合与单独保存历史数据,并修改数据调用策略,以避免灾难性遗忘。相较于通用模型,SEAL模型在过往数据上的灾难性遗忘程度较低,显示出一定的有效性。
论文图示表明,随着知识块的增加及模型的反复进化与收敛,仍会出现记忆丢失现象。在仅有一段数据的情况下,经过8次反复进化,准确度从0.33降至0.19;无论是几段数据,准确度都会随之降低。因此,该算法的进化方向不仅限于prompt校准,还需计算过往数据的精准度,以确保模型在自我进化的同时,避免遗忘。这有望成为未来ChatGPT7甚至8的发展目标。
对于人类而言,通常不会将记住的事情记错,而是会遗忘;让人类精确记住过去某时的数据也极具挑战。就像人类难以记住所有童年记忆一样,这些记忆碎片往往难以寻找,但当某个记忆碎片或情景被触发时,往往能迅速唤起更多相关片段。这类似于大脑的记忆数据检索机制。然而,当前AI模型在进化过程中,反复进化可能导致错误数据或“错误记忆”的产生,这是研究团队亟需解决的问题。
目前来看,这篇论文至少揭示了一个重要趋势,即AI大模型将具备自我进化能力。这意味着模型无需额外的数据训练,通过日常沟通与任务完成即可实现自我提升。这项研究的最大意义在于推动模型智能化,使个人账户下的ChatGPT能更深入地理解用户,逐步成为与其认知和需求完美契合的“灵魂伴侣”。模型的自我进化能力可覆盖从个人账户到整个模型基座的范围,从而消除对人工训练的依赖,让用户无需等待版本发布即可体验到模型的新能力。然而,这种进化目前主要体现在模型的准确度和生成内容量方面,尚未涉及功能和多模态能力的转变,例如文本模型尚不能直接进化为图像模型。可以预见,ChatGPT6及后续模型将展现出更强的“拟人化”特性。




