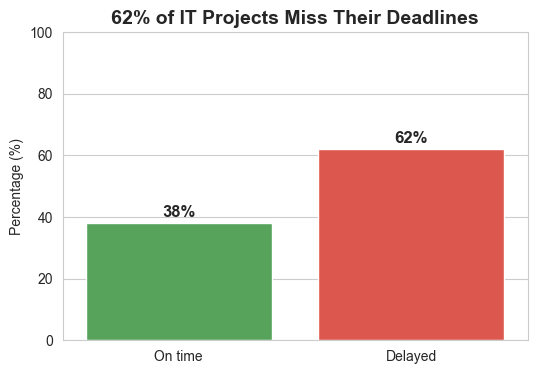
AI 应用的竞争焦点正从“模型能力”转向“知识工程”。Claude Skills 通过渐进式披露机制和可执行代码,让 AI 像人类学习技能一样,无需每次都从零开始。这标志着从“教 AI”到“为 AI 搭建认知脚手架”的范式转变。未来不属于最会用 AI 的人,而属于最会“教 AI 学习”的人——那些能将隐性知识结构化的“知识架构师”。
每天都在上演的困境
作为产品经理,使用 Claude 生成了一份完美的季度报告:配色、字体、数据呈现都恰到好处。
第二天开启新对话,要求类似的月度分析时,结果却令人失望:品牌色偏离、图表风格不一、标题层级混乱。产品经理不得不重新解释:“记住,主色调是#2E5BFF,图表用 recharts,标题用 Inter 字体…”
这种重复教学已成为常态。
开发者的处境更显尴尬。已经反复教导 Claude 代码风格、项目架构和部署流程,但每次新建对话,它就像失忆般忘记 TypeScript 严格模式,或把测试文件放错位置。
据估算,中度 AI 用户每周花费 2-4 小时在“重复教导”上。这不仅是效率问题,更是尊严问题——用户在为一个永远记不住的“学徒”打工。
问题并非出在AI的智能水平,而是当前的教导方式存在误区。
通用模型的专业困境
Claude Sonnet 4.5 能写诗、编程、分析金融数据、设计 UI,堪称全能。但在实际工作中,其表现为何总是“差那么一点”呢?
这源于根本矛盾:上下文成本与专业深度的博弈。
通用性的代价
大语言模型的训练目标是“在海量数据中学习通用模式”,这赋予了它广博的知识面。但当需要“精通公司特定财务流程的专家”时,通才只能给出“大致正确”的建议。
要让 Claude 真正理解业务,理论上需要将所有相关知识塞进提示词。但现实是:
- •上下文窗口有限:即使 200K token 的容量,也装不下完整的企业知识库
- •对话重启成本高:每次新对话都意味着“培训”归零
- •Token 成本线性增长:完整指令重复发送,如同每次通话前先念一遍通讯录
生成的不确定性
更深层的问题是:某些任务根本不适合“生成”完成。
比如,让 Claude 用自然语言生成“对 1000 个数字排序”的算法,就像让建筑工人现场手工制砖——理论上可行,但实际操作却低效且不可靠。而预写的排序脚本,能确保结果既确定又高效。
LLM 的非确定性输出与任务可靠性的需求,构成了难以调和的矛盾。
真正需要的是“更懂我的 AI”,而非“更强的 AI”
这就是 Claude Skills 要解决的核心:如何让通用模型在特定领域表现得像训练有素的专家,而非每次都从零开始的新手?
Skills 的渐进式认知设计
Claude Skills 的创新并非在于使模型本身“更聪明”,而是使其无需每次都从零开始学习和推理。
从“背诵百科全书”到“使用图书馆”
传统提示工程如同要求 AI “背诵整本百科全书”并在对话中默写,这显然不现实。
Skills 采用不同思路:为 AI 建立“个人图书馆”,教导它按需查阅。
- • 图书馆每本书(Skill)都有书脊标题(元数据)
- • AI 先浏览书架,了解可用资源(启动时加载所有 Skill 的名称和描述)
- • 需要时取出具体书籍阅读(按需加载 SKILL.md)
- • 若书中提及附录或参考文献,再进一步查阅(递归加载相关文件或执行脚本)
这便是“渐进式披露”的核心理念——避免一次性灌输全部信息,而是分层、按需地加载知识。
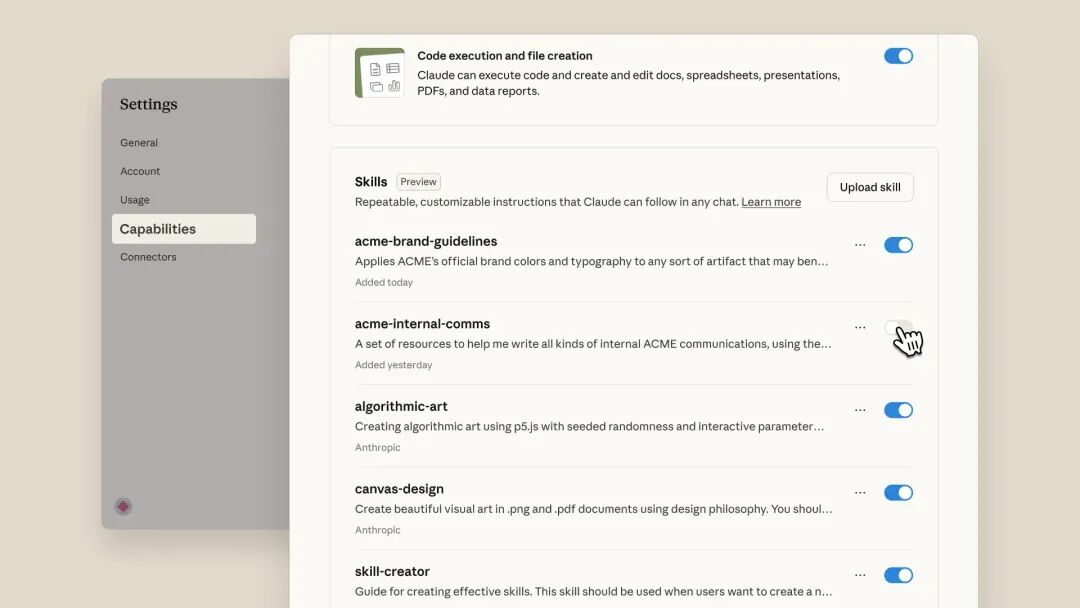
Claude.ai 中的 Skills 功能界面,展示示例 Skills 的开关控制
三层加载机制:从元数据到可执行代码
以 Anthropic 提供的 PDF 处理 Skill 为例,解析这一机制:
第一层:元数据(常驻内存,约 100 tokens)
name: PDF Processing
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
第二层:指令(触发时加载,通常 <5K tokens)
当用户说“从这个 PDF 提取表格”,Claude 识别关键词“PDF”并触发相应 Skill。此时通过bash命令读取SKILL.md完整内容:
# PDF Processing
## Quick Start
Use pdfplumber to extract text from PDFs:
python
import pdfplumber
with pdfplumber.open("document.pdf") as pdf:
text = pdf.pages[0].extract_text()
For advanced form filling, see FORMS.md.
这是“书的目录和核心章节”——提供核心指令与工作流程。总结:第二层是“知道如何做”的步骤指南,仅在需要时进入上下文。
SKILL.md 文件的基本结构:YAML 前置元数据 + Markdown 正文指令
第三层:资源与代码(按需加载,理论上无限制)
若任务涉及表单填写,Claude 会进一步读取FORMS.md:
pdf-skill/
├── SKILL.md (主指令)
├── FORMS.md (表单填写指南)
├── REFERENCE.md (详细 API 参考)
└── scripts/
└── fill_form.py (表单填充脚本)
精妙之处在于:脚本可直接执行,而不必加载到上下文中。例如,fill_form.py用于提取 PDF 表单字段。当 Claude 执行:
python scripts/fill_form.py document.pdf
只有脚本输出(如“发现 5 个字段:姓名、地址、日期…”)进入上下文,脚本本身的数百行代码零 token 消耗。
 Skills 可包含多个文件:主指令文件、辅助文档、可执行脚本等,按需加载
Skills 可包含多个文件:主指令文件、辅助文档、可执行脚本等,按需加载
总结:第三层是“可执行工具”,它们工作但不占用阅读带宽。
设计优势对比
| 维度 | 传统提示词 | Claude Skills |
|---|---|---|
| 知识加载 | 一次性完整加载 | 三层渐进式按需加载 |
| Token 消耗 | 每次对话重复完整指令(数万 tokens) | 元数据常驻(~100 tokens/skill),指令按需(<5K),资源零成本 |
| 可扩展性 | 10 个复杂任务就会撑爆上下文 | 理论上可安装无限 Skills,只要使用总量不超限 |
| 可靠性 | 依赖 LLM 生成,存在随机性 | 可执行代码部分完全确定 |
| 复用性 | 每次对话重新编写/复制粘贴 | 一次创建,跨平台复用(API、Web、Claude Code) |
用编程类比:传统提示词是解释执行(每次重新解析),Skills 是 JIT 编译(按需编译,高效复用)。
渐进式披露的三个层级:元数据(永远加载)→ 指令(触发时加载)→ 资源和代码(按需加载)
从“Prompt”到“Skill”:范式跃迁
若仅将 Skills 视为“更好的提示词管理工具”,便错过了其革命性意义。
本质转变:从“教导”到“搭建认知脚手架”
传统提示词工程的心智模型:将 AI 视为“服从指令的执行器”。编写提示词如同下达命令:“做这个,按此格式,注意那些细节…”
Skills 的心智模型:将 AI 视为“学习中的学徒”。并非下达命令,而是搭建“认知脚手架”——提供工具、参考手册、最佳实践,让它自主判断何时使用何种工具。
这不只是术语差异,而是控制权的转移:
- •提示词是“微观管理”:需告知 AI 每一步操作
- •Skill 是“赋能管理”:提供资源,AI 自主决策调用时机
类比:从“脚本”到“专业工具包”
设想一位木匠:
- •传统提示词:每次工作,师傅都会在旁指导:“先用锯子横切,力度需如此,再使用锤子…”这种重复指导效率低下。
- •Claude Skills:师傅会提供工具箱,内含锯子、锤子、尺子,每件工具附使用说明。AI能够自主判断何时使用何种工具,用户只需下达“做个书架”之类的宏观指令。
Skills 让 AI 从“被动执行者”进化为“主动工具使用者”。
可执行代码:AI 的“肌肉记忆”
更深层的洞见:
人类学习技能时,部分操作会固化为“肌肉记忆”——如骑自行车,无需每次都思考“左脚蹬、右脚蹬”,动作已自动化。
Skills 中的可执行代码,就是 AI 的“肌肉记忆”。
对比两种实现方式:
方式 A:让 LLM 生成代码(现场思考)
用户:帮我对这个 PDF 的表单字段排序
Claude:(思考)我需要先读取 PDF...用什么库?pdfplumber?PyPDF2?...好的,编写脚本...(生成数十行代码,消耗数千 tokens,可能包含错误)
方式 B:调用 Skill 中的脚本(肌肉记忆)
用户:帮我对这个 PDF 的表单字段排序
Claude:(识别 PDF 任务,加载 PDF Skill)
(执行 scripts/extract_fields.py,0.1 秒返回结果,0 token 消耗,100% 可靠)
当任务需要确定性、高性能时,不应让 AI“现场发挥”,而应调用“肌肉记忆”。
这也是 Anthropic 特别强调之处:Skills 可包含可执行代码,且代码运行在安全的虚拟机环境中。
 Skills 动态加载进上下文窗口的过程:从系统提示词到触发加载,再到按需读取资源
Skills 动态加载进上下文窗口的过程:从系统提示词到触发加载,再到按需读取资源
Skills 在 AI 生态中的定位
若觉得 AI 领域概念混乱——Tools、Functions、Skills、MCPs、Agents、Subagents…——这并非错觉,行业快速迭代确实导致“概念增生”。
通过清晰框架理解 Skills 的定位。
三角模型:感知-技能-执行
将完整 AI 应用系统想象成“人”:
+-------------+ | Agents | (大脑:决策与编排) | (子代理编排) | +------+------+ | +--------+--------+ | |+----v----+ +-----v----+| Skills | | MCP | (感官:连接外部)| (技能库) | | (数据接口)|+---------+ +----------+
- •MCP(模型上下文协议):“感知器官”——让 AI“看到”外部数据(数据库、API、文件系统等)。MCP 服务器如同眼睛、耳朵,负责获取实时信息。
- •Skills:“技能记忆”——存储“如何做某事”的程序性知识。如同学会骑自行车后,技能存储在大脑中,需要时自动调用。
- •Agents/Subagents:“执行大脑”——负责任务分解、决策、编排。决定“此任务需使用哪些 Skills + 哪些 MCP 数据”。
实际工作流示例
场景:用户要求:“分析公司上季度销售数据,生成 Excel 报告”
1. Agent 接收任务,分解步骤: - 需要获取销售数据 → 触发 MCP(连接数据库) - 需要生成 Excel → 触发 Skills(加载 Excel Skill)
2. MCP Server 执行: - 查询 PostgreSQL,返回销售数据(5000 条记录)
3. Agent 将数据传给 Excel Skill: - 加载 excel-skill/SKILL.md(指令) - 执行 excel-skill/scripts/pivot_table.py(生成透视表,不消耗 token) - 根据指令应用公司品牌样式
4. 生成最终报告,展示给用户
关键点:
- •MCP 提供“原材料”(数据)
- •Skills 提供“加工方法”(如何生成 Excel、应用样式)
- •Agent 负责“项目管理”(编排整个流程)
Projects 与 Custom Instructions 的定位
另有两个概念需要厘清:
- •Projects:适合“有长期上下文积累的工作”(如产品完整开发周期)。Skills 可在 Project 内部使用。
- •Custom Instructions:全局偏好设置(如“回复简洁”、“代码加注释”)。Skills 是任务特定的专业知识。
用餐桌类比:
- •Custom Instructions= 饮食偏好(不喜香菜、少油)
- •Skills= 具体菜谱(如何烹制宫保鸡丁)
- •Projects= 完整宴席(多道菜组合)
- •MCP= 食材供应商(提供鸡肉、蔬菜)
Agent Skills 技术架构:Skills 如何与代理配置和虚拟机环境集成
Skills 的挑战与局限
在描绘美好愿景前,需正视 Skills 面临的挑战。这些不仅是技术问题,更是对整个 AI 应用范式的考验。
挑战一:AI 选择 Skill 的可靠性
Skills 的触发依赖 AI 的“判断”:通过元数据的description决定是否加载某个 Skill。
但存在不确定性:
- • 若两个 Skill 描述相似,AI 可能选错
- • 若用户表述不清,AI 可能漏掉相关 Skill
- • 若 Skills 过多,AI 可能“选择困难”
真实用户反馈(来自 Hacker News):
“已多次遇到 Claude 本应使用某个 Skill 却未使用,或使用一半后忘记…”
这表明:Skills 让 AI 更强大,但也使其行为更不可控。
挑战二:依赖高质量的文档能力
Skills 的质量上限取决于文档水平。
若 SKILL.md 逻辑混乱、指令模糊,AI 同样会犯错。而编写优质 Skill 需要:
- • 清晰的思维(能将工作流程条理化)
- • 精准的表达(用 AI 理解的方式描述)
- • 持续的维护(业务变化时更新 Skill)
这对许多团队是挑战——如果连给人看的文档都写不好,给 AI 的 Skill 大概率也不理想。
挑战三:概念过载与生态碎片化
正如前文提及,AI 领域概念繁多:
- • OpenAI 的GPTs和Actions
- • Anthropic 的Skills、MCPs、Agents、Projects
- • 各种第三方框架的Plugins、Tools、Functions…
开发者的困惑真实存在:
“该用 MCP 还是 Skill?Subagent 与 Skill 有何区别?为何又要发明新概念?”
尽管这些概念各有侧重,但缺乏统一标准带来了学习与迁移成本。
但这些挑战,恰恰指向未来的机会…
 Skills 中可执行代码的工作流程:Claude 通过 bash 调用脚本,仅获取输出结果而不消耗上下文
Skills 中可执行代码的工作流程:Claude 通过 bash 调用脚本,仅获取输出结果而不消耗上下文
核心洞见
现在,抽离技术细节,审视 Skills 背后真正重要的内涵。
洞见一:AI 竞争从“算力”转向“知识工程”
过去两年,AI 行业的竞争逻辑是:谁的模型参数更多、训练数据更大、算力更强,谁就能获胜。
然而,随着模型能力逐渐触及S曲线的顶部,边际收益递减效应日益显著:
- • GPT-4 到 GPT-5,性能提升已非数量级飞跃
- • Claude Sonnet 4 和 4.5 之间,差异更多在细节优化而非革命性突破
- • 开源模型(如 DeepSeek)已接近闭源模型表现
这意味着什么?
未来 AI 应用的竞争力,将更多取决于“知识库的质量与组织方式”,而非单纯的模型参数规模。
如同互联网时代,最终胜出的不是“谁的服务器更多”,而是“谁的信息架构更合理”(Google 的 PageRank、亚马逊的推荐系统)。
Skills 揭示的路径:
- • 拥有精心设计 100 个 Skills 的中等模型,可能在特定领域超越无 Skills 的顶级模型
- • 企业护城河不再是“买得起最贵 API”,而是“能否将企业知识结构化为高质量 Skills”
这对中小团队是重大利好——无需与 OpenAI 比拼算力,只需比竞争对手更擅长“知识工程”。
洞见二:隐性知识显性化成为核心能力
Skills 的创建过程,本质是将隐性知识转化为显性知识的过程。
何为隐性知识?
- • 资深财务如何一眼识别异常数据
- • 设计师如何“感觉”配色不当
- • 开发者如何“习惯性”组织代码结构
这些知识往往“只可意会,不可言传”,存在于经验丰富的专家脑中。
Skills 倒逼我们将这些知识“可言传”:
- • 创建“财务异常检测 Skill”,必须总结具体规则或模式
- • 创建“品牌设计 Skill”,必须将“感觉”转化为可执行的色彩理论与组合原则
这带来惊人推论:
未来最有价值的职业技能之一,是“知识架构师”——那些能将专家隐性知识,结构化为 AI 可理解、可执行 Skills 的人。
他们不一定是最强程序员,但具备:
- • 业务逻辑理解(知道专家在做什么)
- • 信息架构能力(知道如何结构化知识)
- • AI 能力边界认知(知道哪些该用指令,哪些该用代码)
文档工程师、知识管理专家、技术写作者——这些曾被认为“不如编码高级”的职业,可能在 AI 时代迎来价值重估。
洞见三:Skills 真正强化的是人类能力
这是最关键的认知反转。
当为工作流程创建 Skill 时,必须:
- 1.拆解思维过程(是如何做的?)
- 2.提炼关键步骤(哪些步骤必要?)
- 3.结构化知识(如何让 AI 理解?)
- 4.标准化流程(如何确保每次正确?)
此过程本身,就是对自身认知的深度优化。
Skills 不是让 AI 学习,而是强迫你学会“教学”——而教学是最好的学习。
换言之:
- •表面上,在教 AI 如何做事
- •实际上,在重构自己的知识体系
AI 只是放大器。知识架构能力才是被放大的对象。
洞见四:AI 能力的“乐高化”正在到来
Skills 的可组合性,预示更宏大的趋势:AI 能力的模块化与标准化。
想象未来:
- • GitHub 上有数万个开源 Skills(如同 npm 包)
- • 可一键安装“财务分析 Skill Pack”、“UI 设计 Skill Pack”
- • 这些 Skills 像乐高积木般自由组合,构建定制化 AI 应用
这就是“AI 能力的乐高化”——并非每次从零训练模型,而是组装现有能力模块。
但这带来新挑战:
- •供应链安全:如何防止恶意 Skill?(如同 npm 的供应链攻击)
- •质量控制:如何评估 Skill 质量?(需要类似“五星评级”机制)
- •版本管理:当底层模型更新,Skills 是否需要重新适配?
Anthropic 已在布局:提供 Claude Console,让开发者“查看、创建、升级 Skill 版本”,这是在为生态系统搭建基础设施。
实践指南:创建你的第一个 Skill
读到这里,可能想问:“听起来不错,但该从哪里开始?”
第一步:识别“重复劳动”
回顾过去一个月与 AI 的交互:
- •哪些指令重复输入 3 次以上?(如“使用我们的品牌色”)
- •哪些工作流程每次都要重新解释?(如“先验证数据,再生成图表,最后导出 Excel”)
- •哪些错误 AI 反复犯?(如“总是忘记加类型注解”)
这些就是第一批 Skill 候选。
第二步:从简单 Skill 开始
勿试图创建“包罗万象”的超级 Skill。从简单、聚焦的场景起步:
示例:品牌色 Skill
name: Brand Colors
description: Use company brand colors in any design or visualization task. Trigger when user mentions "our brand", "company colors", or creates visual content.
# Brand Colors
## Color Palette
- Primary: #2E5BFF (蓝色,用于主要按钮和标题)
- Secondary: #7C3AED (紫色,用于次要元素)
- Accent: #10B981 (绿色,用于成功提示)
- Neutral: #6B7280 (灰色,用于正文)
## Usage Rules
- 背景与文字对比度必须 ≥4.5:1(WCAG AA 标准)
- 主色占比 60%,辅色 30%,强调色 10%
- 数据可视化优先使用主色系的渐变
如此简单。但这 17 行的 Skill,让你不再每次重复输入品牌色。
第三步:迭代与观察
创建 Skill 后,实际使用并观察:
- •Claude 是否正确识别并触发此 Skill?(检查思维链)
- •Skill 的指令是否被准确执行?(对比输出结果)
- •是否有遗漏或模糊之处?(根据错误反馈优化)
关键:用 Claude 本身帮助优化 Skill。询问:
“我这个 Skill 写得如何?有哪些需要改进的地方?”
第四步:从指令到代码的升级
当 Skill 稳定后,识别其中“适合用代码实现”的部分。
判断标准:
- •确定性强:输入固定,输出唯一(如数据验证、格式转换)
- •性能敏感:需处理大量数据(如排序、聚合)
- •可靠性要求高:容错空间极小(如财务计算)
将这些部分写成 Python/JavaScript 脚本,放入scripts/文件夹,在 SKILL.md 中说明调用时机。
第五步:建立“思维习惯”
从明天起,当进行任何重复性工作时,问自己:
“这个流程,我能否将其 Skills 化?”
这个问题本身,就是思维升级的开始。
它会让你:
- • 更主动地反思工作流程
- • 更清晰地识别可优化环节
- • 更系统地积累可复用知识资产
结语
如果说 2023 年的 AI 竞争是“谁能买得起最强 GPU”,那么 2025 年的竞争正转向“谁更擅长设计认知工具”。
Claude Skills 的推出,表面是产品功能,实质是信号:模型能力竞争已近饱和,生态能力竞争才刚刚开始。
未来属于那些能够:
- •将隐性知识显性化的人(把“老师傅的经验”变成 Skill)
- •将专业知识模块化的人(让 Skills 可组合、可复用)
- •为 AI 搭建认知脚手架的人(不是命令 AI,而是赋能 AI)
无需是最强程序员,无需拥有最大 GPU 集群,需要成为优秀的“知识架构师”。
当别人还在为“如何编写更好的提示词”苦恼时,已在为 AI 打造“专业工具箱”。
这才是 AI 时代真正的竞争力。
最讽刺的是:以为 AI 将取代人类,但 Skills 告诉我们,AI 最需要的,恰恰是最“人性化”的能力——将经验转化为知识,将混沌结构为秩序,将直觉翻译为逻辑。
这些,只有人类能做。