


语音大语言模型(Speech LLM)在实际落地中,面临一个核心挑战:既要快速准确地理解语音语义,又要生成自然的音色,同时还需保证实时响应。常见问题包括智能音箱“听不懂”用户指令、车载助手“说”话生硬如机器人,以及实时翻译出现明显延迟。究其根本,问题出在“语音 Token 化”这一关键步骤上。作为将语音拆分为Speech LLM“离散单元”的核心环节,传统方案难以在语义提取、声学还原和实时性之间取得平衡,从而制约了Speech LLM的广泛应用。
为解决Speech LLM落地过程中的音频处理难题,美团LongCat团队正式开源了专用语音编解码方案——LongCat-Audio-Codec。该方案提供了一站式的Token生成器(Tokenizer)与Token还原器(DeTokenizer)工具链。其核心功能是将原始音频信号高效映射为语义与声学并行的Token序列,并通过解码模块重构高质量音频,从而为Speech LLM提供从信号输入到输出的全链路音频处理支持。凭借创新的架构设计与训练策略,LongCat-Audio-Codec在语义建模、声学重建、流式合成三大维度实现了显著突破。
开源平台:
- Github:https://github.com/meituan-longcat/LongCat-Audio-Codec
- Hugging Face:https://huggingface.co/meituan-longcat/LongCat-Audio-Codec
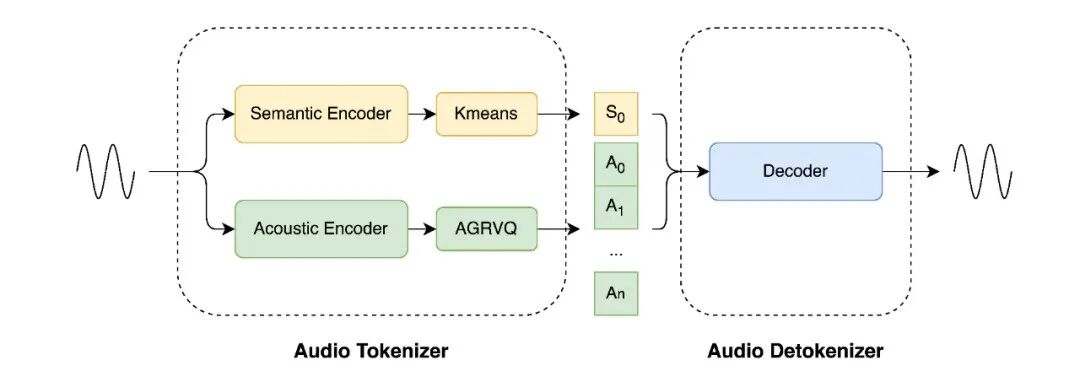
LongCat-Audio-Codec 模型架构图
LongCat-Audio-Codec 的核心竞争力源于三大创新设计:
设计一:语义-声学双Token并行提取机制:兼顾理解与生成
为解决语义空间干扰声学空间导致的重构质量不佳问题,LongCat-Audio-Codec创新性地采用“级联训练-并行推理”设计:
-
语义 Token:首先基于双向Transformer架构,聚焦语音内容的核心信息,利用CTC微调后的ASR模型提取纯粹的语义信息,为Speech LLM的语义理解提供有力支撑。
-
声学 Token:随后,结合已有的语义信息和改进的量化技术,在大码本空间下补充韵律、音色等副语言特征的声学Token,有效解决非语义信息覆盖不足的问题。
同时,该方案支持声学码本的动态配置。在保证语义能力一致的前提下,可以根据下游任务需求调整码本层数。例如,若下游任务为少音色场景,可选择单个声学码本以降低Speech LLM的学习负担;若为多音色场景,则可选择全部声学码本以提供丰富的说话人支持。
设计二:低延迟流式解码器:兼顾实时与质量
低延迟流式处理能力是Speech LLM在实时交互场景(如车载语音助手、实时翻译)中的核心需求,其关键指标是端到端延迟(End-to-End Latency)。传统解码架构并非专为流式场景设计,容易导致实时交互延迟高(例如实时翻译卡顿半秒)。LongCat-Audio-Codec通过引入低延迟流式解码器解决了这一问题。其解码器采用帧级增量处理模式,通过控制对未来语音Token的依赖,将解码延迟控制在百毫秒级。此架构显著提升了Speech LLM的交互实时性,符合工业级实时响应标准。
设计三:超低比特率高保真与集成超分辨率设计:兼顾压缩效率与音质
为解决“低比特率音质劣化”和“超分辨率需额外模型”的挑战,LongCat-Audio-Codec采用了协同优化设计:
-
超低比特率:比特率是衡量音频压缩效率的核心指标。依靠模型优化与三阶段训练机制,通过降低信息量,该技术在确保Speech LLM能从海量数据中学习语音本质的同时,也降低了其训练难度,并为Speech LLM的规模化落地提供了有力支撑。
-
集成超分辨率:LongCat-Audio-Codec将超分辨率思想嵌入解码器,通过神经网络对重建音频进行频域补全。此集成设计不仅提升了核心内容的压缩率,还通过提高输出音频的采样率,增强了语音的自然度和细节表现力。

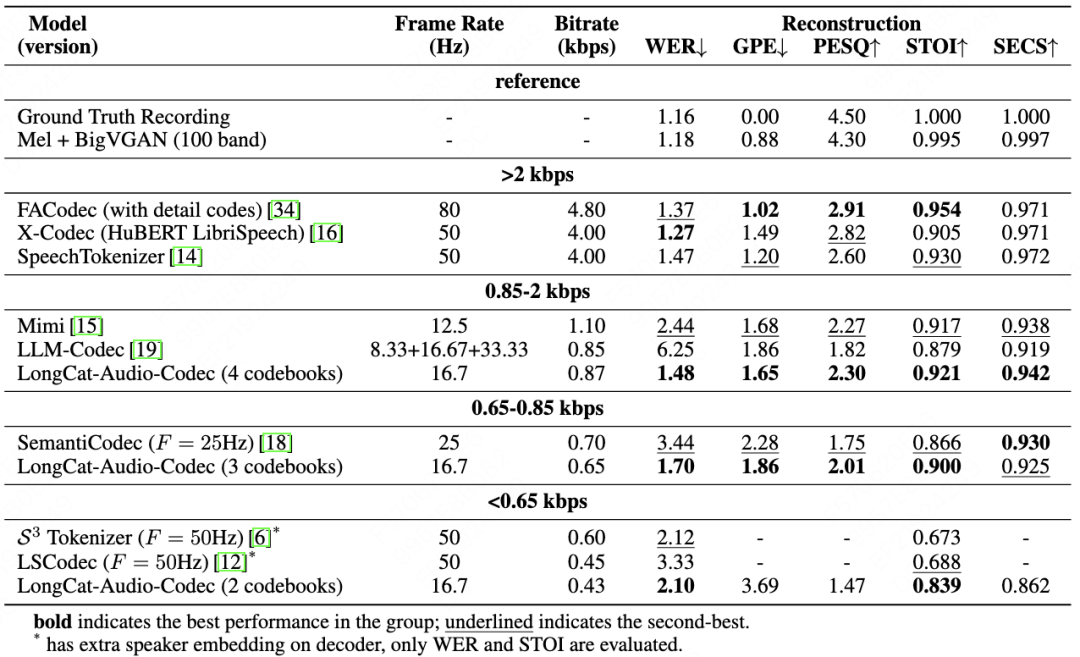
低比特率下的可懂性与音质优势
在测试中,LongCat-Audio-Codec在低比特率区间(0.43-0.87kbps)的关键指标优于同类方案。对比其他携带语义的编解码器,LongCat-Audio-Codec在各比特率区间均表现最优。
-
0.85-2kbps 区间(4 个码本,0.87kbps):词错误率(WER,越低表示语音可懂性越高)仅 1.48;语音质量感知评估(PESQ,越高表示主观音质越好)达 2.30;短时客观可懂性(STOI,越高表示语音信息保留越完整)达 0.921;说话人相似度(SECS)0.942,兼顾可懂性与音色一致性。
-
0.65-0.85kbps 区间(3 个码本,0.65kbps):WER 1.70,STOI 0.900,优于同类低比特率方案。
-
<0.65kbps 区间(2 个码本,0.43kbps):WER 2.10,STOI 0.839,在极端低比特率下仍保持高可懂性,适合资源受限场景。
比特率与性能的灵活适配
当前架构支持在保证语义理解能力的情况下灵活调整码本数量(2-4 个)。LongCat-Audio-Codec能够实现比特率从0.43kbps到0.87kbps的渐进式优化,且指标同步提升:
-
WER 从 2.10 降至 1.48,STOI 从 0.839 升至 0.921,语音可懂度显著提高。
-
总基音误差(GPE)从 3.69 降至 1.65,PESQ 从 1.47 升至 2.30(增幅 56.5%),说话人相似度从 0.862 升至 0.942,语音重构相似度进一步提高。
多阶段训练策略适配多样化场景
LongCat-Audio-Codec设计了多阶段训练策略,以兼容压缩率和音质的需求。其中,Stage1用于满足高压缩率下的重构需求,Stage2用于满足高音质合成需求,Stage3用于满足个性化定制需求。
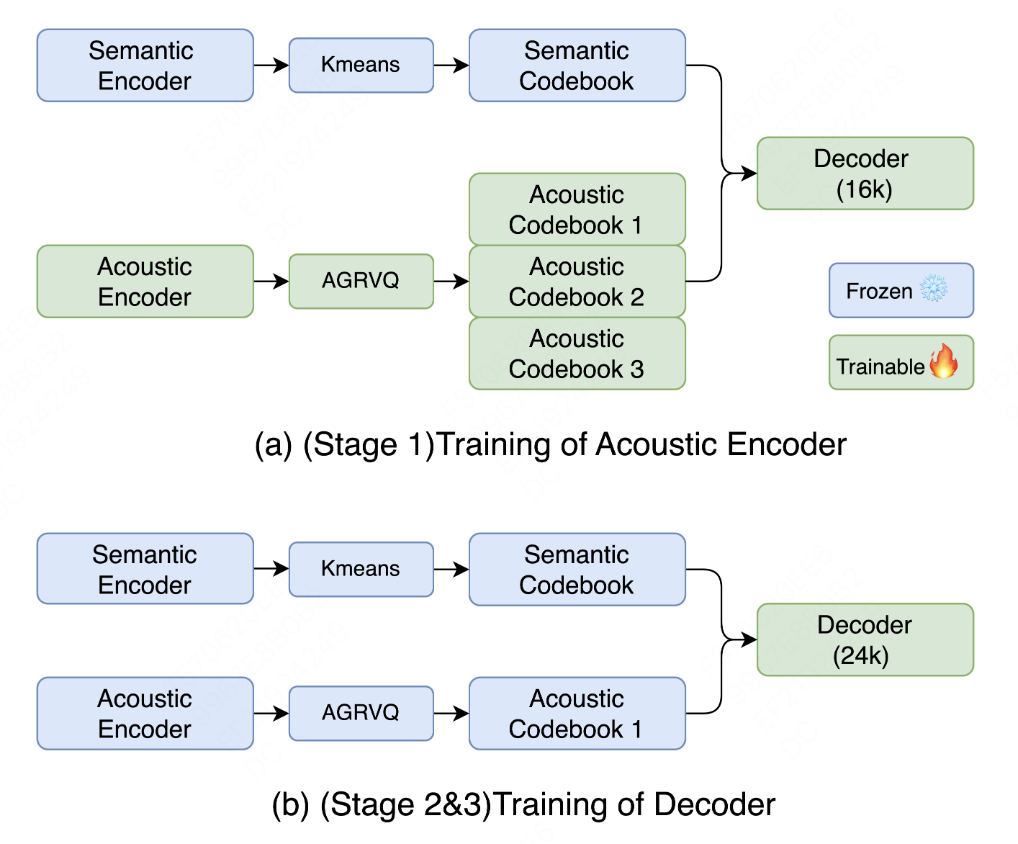

经过Stage2优化后,LongCat-Audio-Codec在音质上表现突出,无参考音质指标SIGMOS达3.35,NISQA达4.33,甚至超过LibriTTS clean数据集(SIGMOS 3.24、NISQA 4.09)的录音水平。
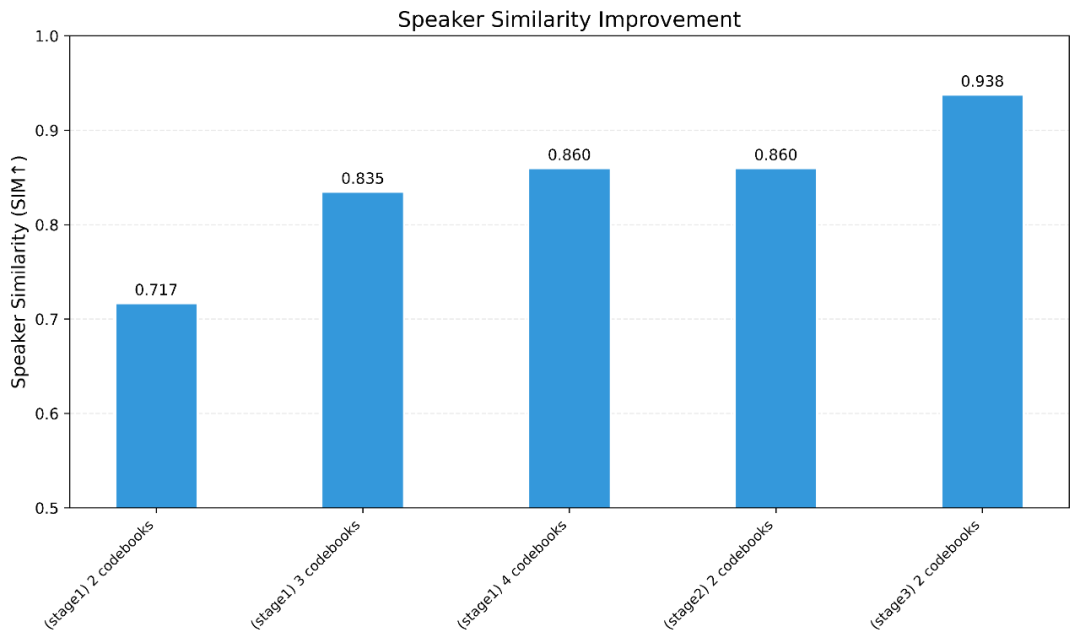
经过Stage3优化后,有限集说话人相似度(SIM)从0.717升至0.938,这证明在当前架构下,使用最低码率(0.43kbps)也能满足说话人定制需求。

作为工业级语音大模型(Speech LLM)的专用语音Token解决方案,LongCat-Audio-Codec以三大核心创新打破了语音大模型落地的关键瓶颈:通过“语义-声学双Token并行提取”破解“懂却说不清”的平衡难题;以“低延迟流式解码”解决“说得清却不实时”的交互痛点;并依靠“超低比特率高保真+集成超分辨率”兼顾压缩效率与音质细节,真正让语音大模型既“听懂”语义,又能够“说清”。
LongCat-Audio-Codec的开源发布,为语音大模型领域带来了三重关键价值:
-
第一,降低技术门槛:为缺乏专用语音处理模块的研究团队提供一站式Token生成器(Tokenizer)与Token还原器(DeTokenizer)工具链,有效缓解语音大模型领域架构碎片化和上手难度高的问题,使开发者能够基于开源代码快速构建语音大模型;
-
第二,丰富应用场景:凭借灵活的码本配置、轻量化设计及低延迟解码方案,该编解码器能够适应更多样化的应用场景;
-
第三,完善技术生态:与美团此前发布的LongCat系列模型形成协同,覆盖从语音Token处理到语音大模型全链路能力,为构建全栈式语音智能系统奠定坚实基础。
作为开源的语音大模型专用语音编解码器,LongCat-Audio-Codec的技术路线不仅为当前语音大模型落地提供了高效适配的解决方案,更给语音-语言跨模态研究提供了新的参考范式。
未来,LongCat团队还将在多语言语音处理、长音频建模等方向持续优化,期待为行业带来更多突破,也欢迎更多开发者关注与参与共建。
LongCat-Audio-Codec现已全面开源,欢迎访问项目主页获取更多信息:




