

在人工智能与大模型技术爆发式发展的背景下,数据治理正经历从静态管控向智能协同的范式跃迁。传统数据治理模式面临数据孤岛、数据质量参差不齐、安全合规隐患不断等核心痛点。面向 Data+AI 的深度融合正驱动数据治理体系向智能化、自动化、实时化演进。大模型通过自然语言理解、动态血缘分析等技术,实现元数据自动补全与质量实时监控,显著提升治理效率。同时,数据治理智能体的崛起重构了人机协同模式,通过自然语言交互降低分析门槛,推动治理从幕后管控走向前台赋能。然而,这一转型仍需突破三大核心挑战:质量陷阱、安全合规压力以及价值转换瓶颈。本文将深入探讨数据治理在 Data+AI 元数据数据血缘方面的最新实践成果,旨在助力企业数字化转型能力的提升。
文章将从以下 5 个方面展开介绍:
- 多云与 AI 时代的数据治理挑战
- Apache Gravitino 统一元数据架构和场景
- 统一数据血缘的价值
- 如何实现统一血缘
- 未来展望
1. 多云与 AI 时代的数据治理挑战
企业面临的核心痛点主要体现在三个维度:
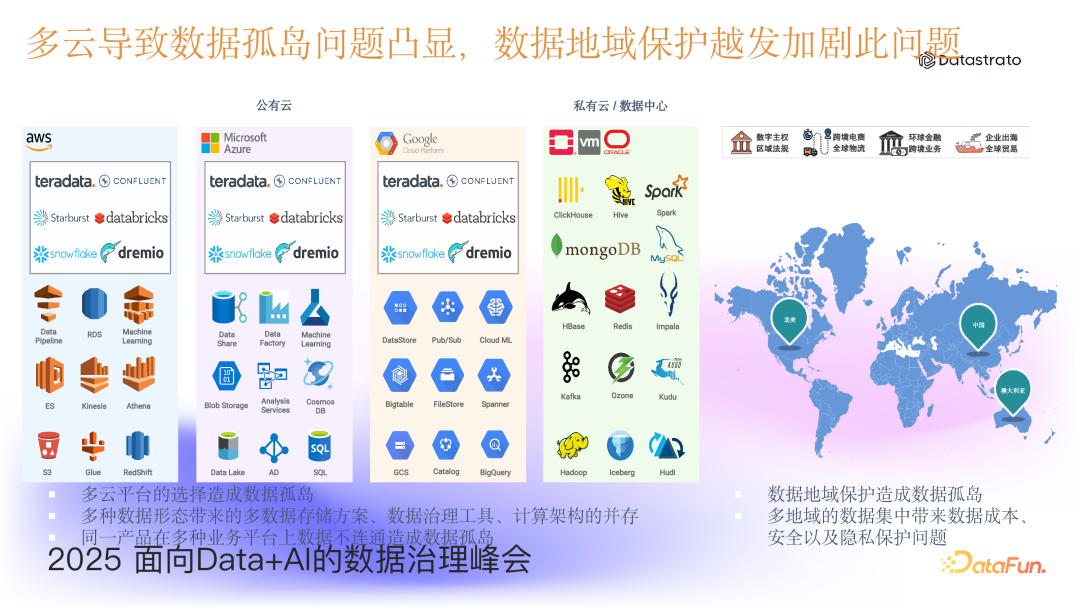
1.1. 数据孤岛问题
首先,基于企业采取的多云架构策略(私有云+多公有云),数据以多种形态散落在云上,天然导致了数据割裂问题的存在。此外,由于各个国家对数据的安全保护以及私有数据跨境传输的合规要求,进一步加剧了数据孤岛问题。
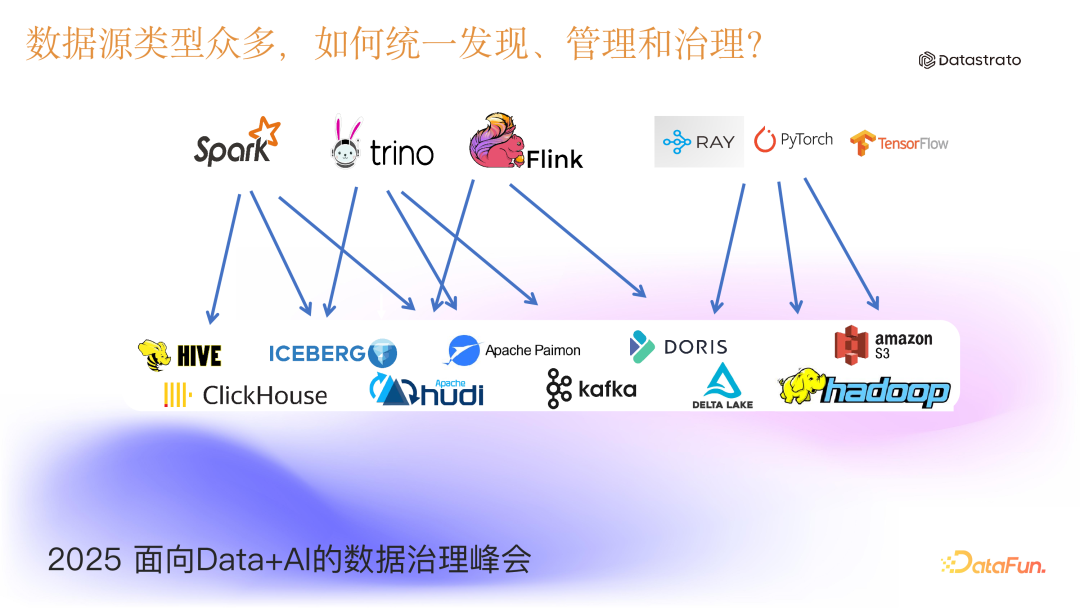
1.2. 数据源类型多样化
从企业内部来看,数据源同时存在传统数据库、数据仓库、离线/实时数据湖、AI 非结构化数据(文本/图片/音视频)等多种形态,这对统一发现、管理和治理提出了严峻挑战。
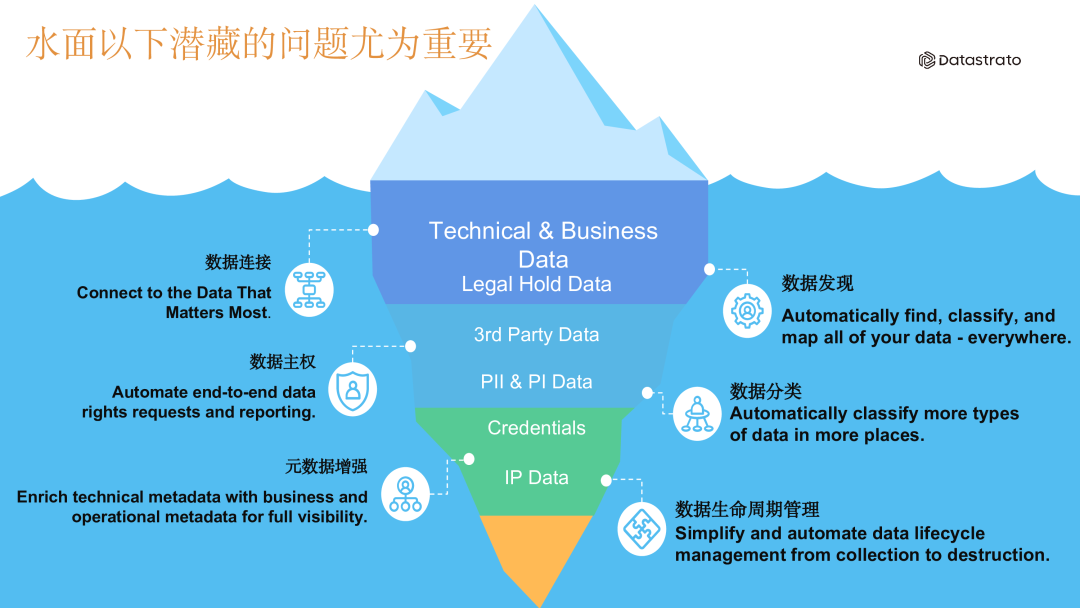
1.3. 被忽略的元数据信息
如果将使用的数据比作海上漂浮的冰山,那么海平面之下隐藏的元数据往往被忽视。它们包括数据连接信息、数据属主信息、数据发现、数据权限信息、数据分类分级以及数据的生命周期等,这些元数据对数据的使用起着重要作用。
2. Apache Gravitino 统一元数据架构和背景
针对上述问题,本文将介绍 Apache Gravitino 项目。Apache Gravitino 定位为统一的支持多源异构元数据湖(Metadata Lake)。底层支持包括 Hive、Iceberg、Hudi、Paimon 等数据湖、主流数据仓库(Doris、StarRocks、OceanBase)和 Kafka 等分布式消息队列。此外,它也支持非结构化数据和 AI 模型通过 Fileset Catalog 和 Model Catalog 进行管理。在统一元数据之上,Gravitino 提供 RESTful API、SDK 和多种 connector,通过各种引擎和 AI 生态(PyTorch、Ray、TensorFlow 等)接入并访问元数据,从而帮助企业统一元数据管理,掌握整个数据和 AI 的全貌,进而更好地开展数据治理工作。
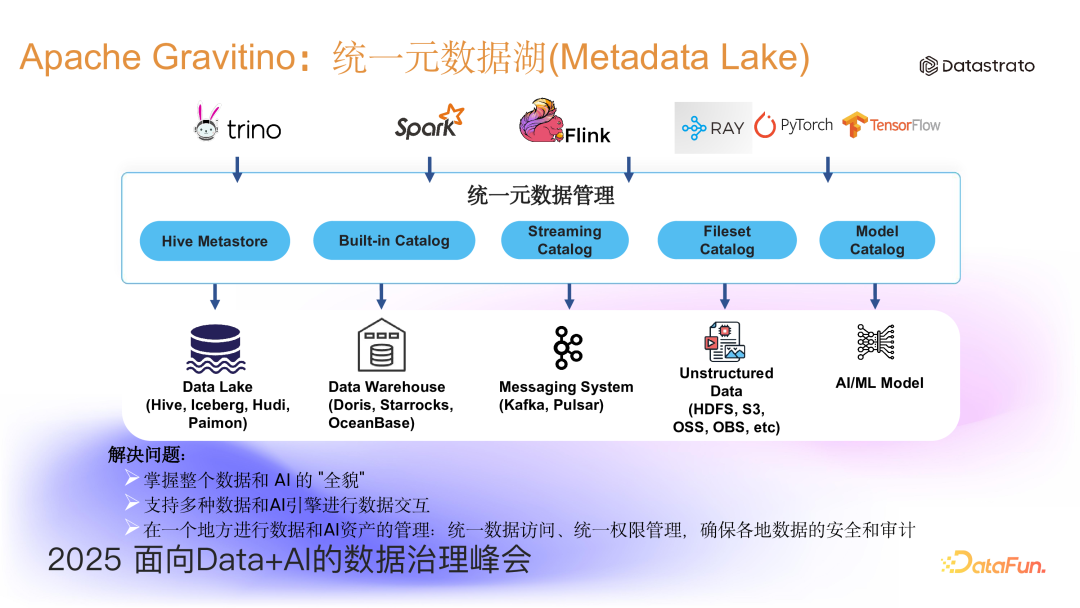
从 Gravitino 内部来看,它将多种数据源挂载进来形成联邦数据目录,这些目录组成了 Metalake。在上层,Gravitino 提供了 RESTful API,在此之上进一步提供了 SDK 与 connector,帮助用户进行统一访问和统一治理。此外,Gravitino 还率先为现今流行的 Iceberg 湖格式提供了一套标准 Iceberg RESTful API 的实现,支持 Iceberg 生态用户的无缝迁移。
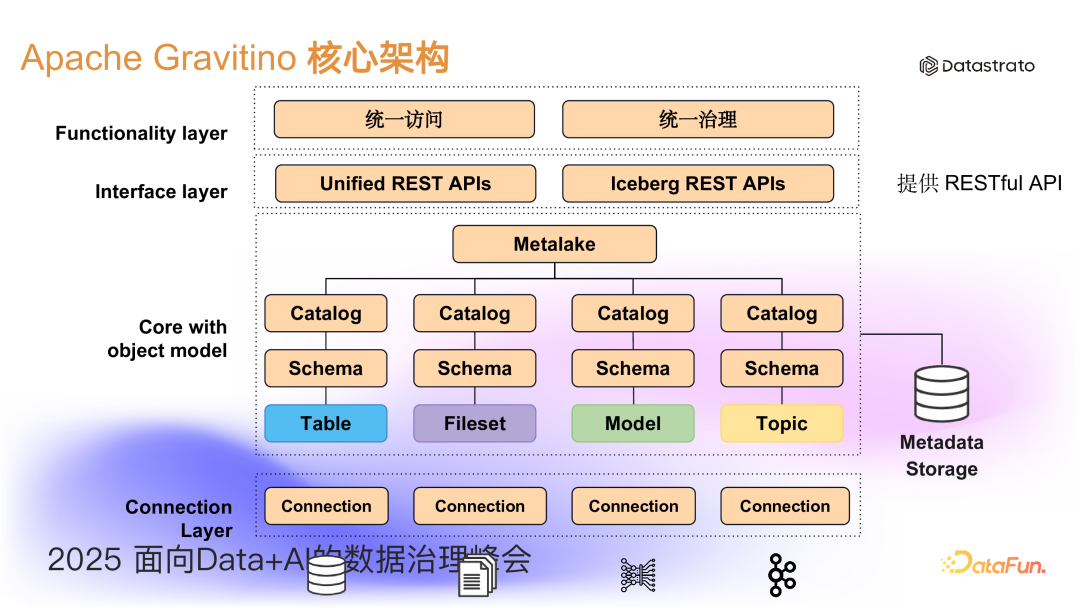
在形成统一元数据之后,用户可以进一步通过其引擎来访问表格数据与非表格数据。对于表格类型数据,用户可以使用 SQL 来操作、修改、删除元数据,还包括对数据的增删改查。对于非表格数据,主要针对文件的操作,Gravitino 支持主流的存储系统如:S3、HDFS、OSS、ADLS、GCS。用户可以将物理存储目录映射成逻辑目录,这个逻辑目录被称为 Fileset Catalog。用户在访问时,可以通过 Gravitino 的虚拟文件系统(GVFS),以逻辑目录的方式访问数据,从而为用户屏蔽了底层不同物理存储的差异。在 Python 生态中,提供基于 fsspec 的标准 Python 文件系统,用户也可以方便地访问这些数据。
因此,Gravitino 统一了结构化与非结构化数据访问,对数据资产提供了标准化管理,为每个数据资产提供全局唯一的数据坐标:<catalog.schema.asset>。用户无需关注物理连接信息,从而降低了出错概率、提升了沟通和使用的效率。
进一步地,Gravitino 在基于统一目录和统一元数据的基础上实现了统一数据的授权和鉴权,可以在一个层面上实现数据的管控,满足数据治理方面合规性的要求。
3. 统一数据血缘的价值
Gravitino 统一元数据之后,自然产生了统一数据血缘的需求。数据血缘本身就是描述数据从生产、加工、流转到最终应用的全生命周期链路关系。统一数据血缘对于企业至少有三个方面的价值:
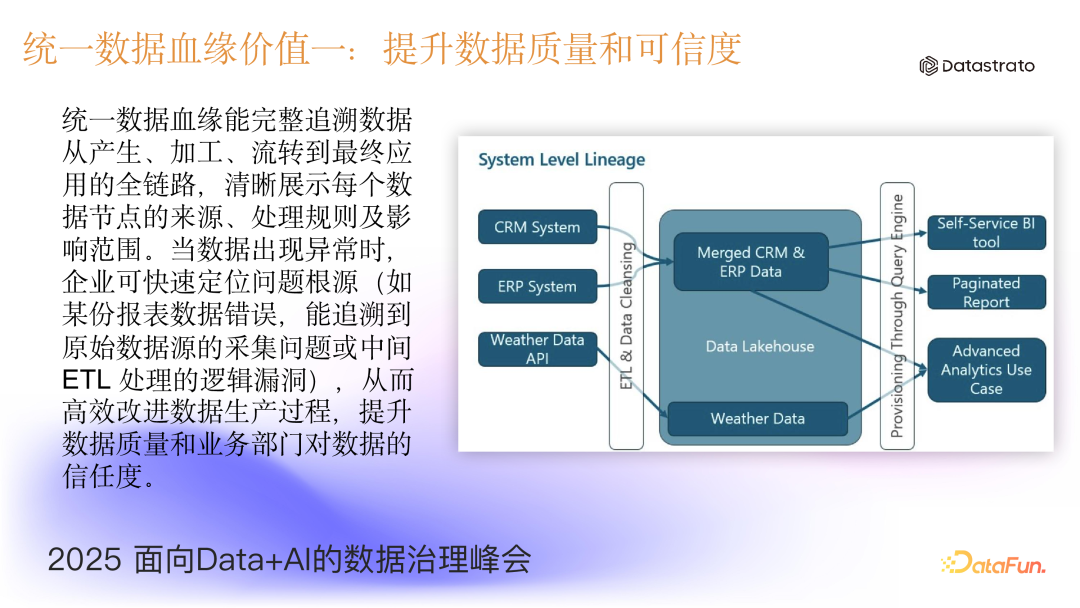
- 提升数据质量和可信度
统一数据血缘能完整追溯数据从产生、加工、流转到最终应用的全链路,清晰展示每个数据节点的来源、处理规则及影响范围。当数据出现异常时,企业可快速定位问题根源(如某份报表数据错误,能追溯到原始数据源的采集问题或中间 ETL 处理的逻辑漏洞),从而高效改进数据生产过程,提升数据质量和业务部门对数据的信任度。
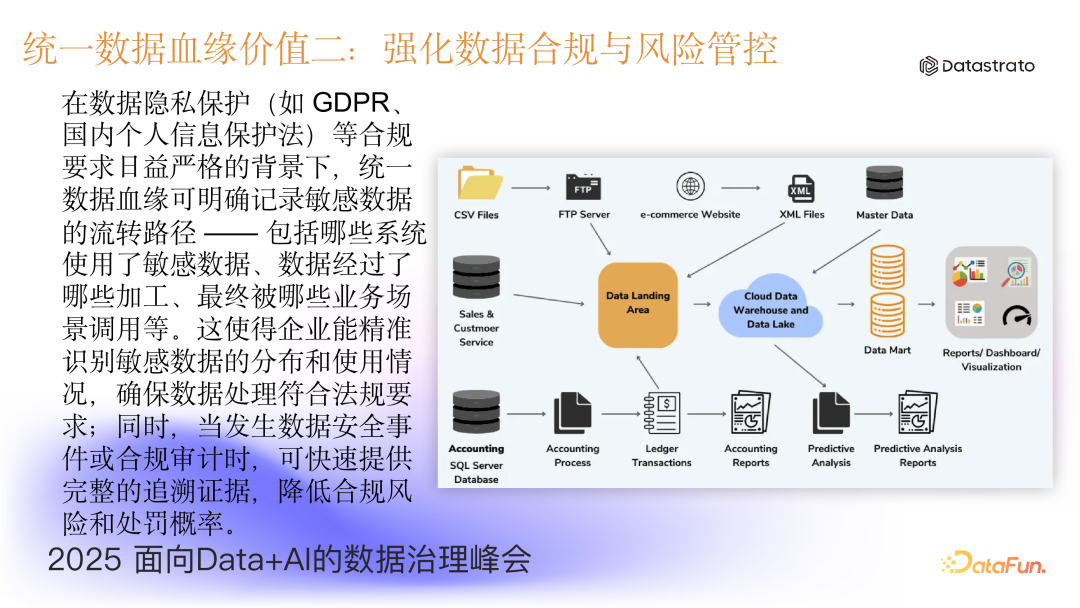
- 强化数据合规与风险管控
在数据隐私保护(如 GDPR、个人信息保护法)等合规要求日益严格的背景下,统一数据血缘可明确记录敏感数据的流转路径——包括哪些系统使用了敏感数据、数据经过了哪些加工环节、最终被哪些业务场景所引用等。这使得企业能精准识别敏感数据的分布和使用情况,确保数据处理符合法规要求;同时,当发生数据安全事件或合规审计时,可快速提供完整的追溯证据,降低合规风险和处罚概率。
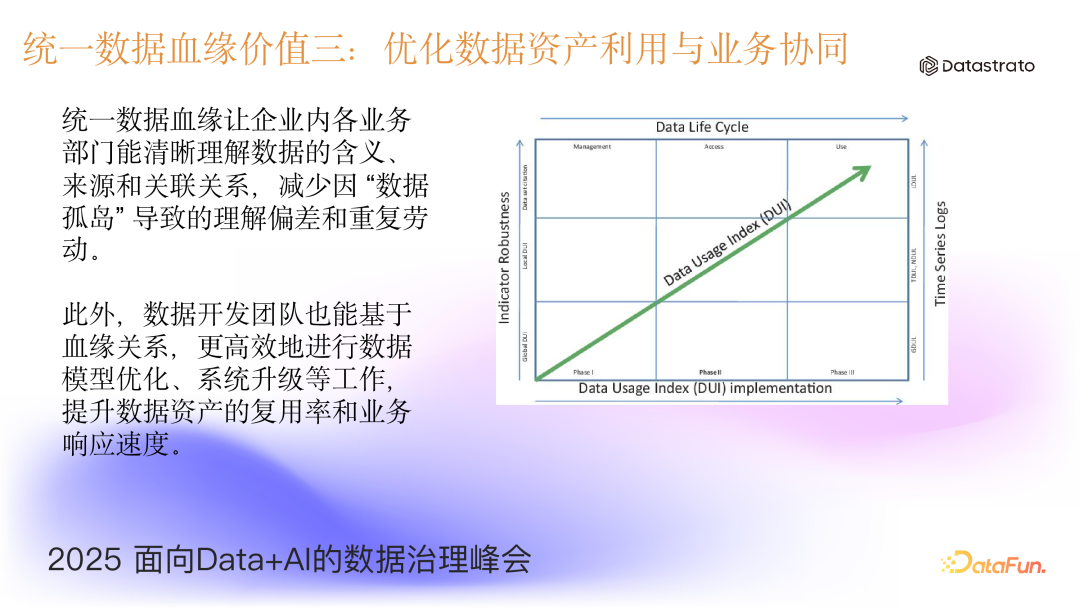
- 优化数据资产利用与业务协同
统一数据血缘让企业内各业务部门能清晰理解数据的含义、来源和关联关系,减少因“数据孤岛”导致的理解偏差和重复劳动。此外,数据开发团队也能基于血缘关系,更高效地进行数据模型优化、系统升级等工作,提升数据资产的复用率和业务响应速度。
4. 如何实现统一数据血缘
OpenLineage 这个开源项目的目标是打造数据血缘行业标准,旨在让各方基于统一标准实现数据血缘的采集和存储,从而减少多平台之间的重复工作。
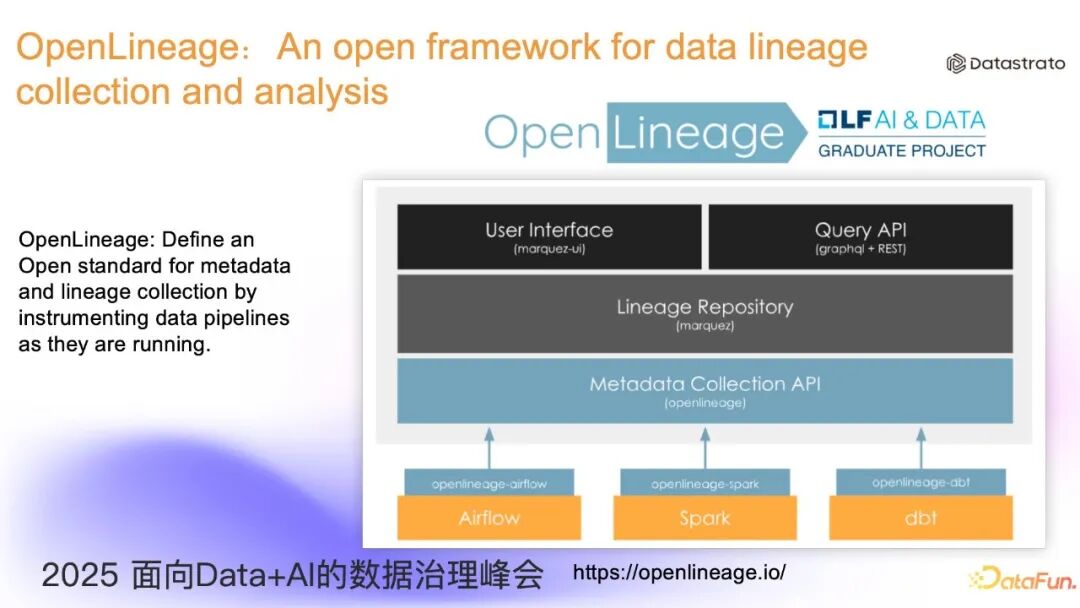
OpenLineage 作为标准化方案,核心是引入了统一的数据 Schema 来描述数据血缘。其核心概念包括:
- Dataset:数据实体(可以是一个表/文件集/Topic 等),是 Job 读写的数据对象。
- Job:数据处理任务的描述信息。
- Run:Job 的单次执行实例。
同时,OpenLineage 通过 Facet 机制支持元数据扩展,扩展的信息能够被解析出来,即可完成血缘的整个链路过程。
事件机制本身用于传递血缘信息,因此包含了触发的 Job、对应的 Run、读/写的 Dataset 以及 Facet 信息。以 OpenLineage 事件上报记录为例,可以更容易理解以上核心概念的实际内容。整个事件上报包含了两个 Event,即:start event 和 complete event。可以看到 Event 下的 Run 包含了 Run ID,Job 包含了相应的 Namespace 和 Job Name,Input 和 Output 都是 Dataset。当收到 Start 事件时,OpenLineage 并不会立刻构建血缘关系,而是在收到 Complete 事件后,才会完成数据血缘的成功构建。



血缘事件消息被采集和记录后,如何把消息发送到后端,OpenLineage 是开放的。目前主要支持 Kafka 和 HTTP 协议。
至此,Gravitino 与 OpenLineage 形成互补架构,同时 OpenLineage 在存储方面并没有绑定,给予后端灵活的实现方案。Marquez 作为参考,完整实现了 OpenLineage 的协议和方案,因此可以将三者结合实现统一数据血缘。
在相应的系统设计中,Gravitino 提供 Lineage API 接收 OpenLineage Event,内部提供 processor 扩展机制,可对血缘信息进行自定义处理;之后通过 sink 接口转到下游存储,如 Marquez。
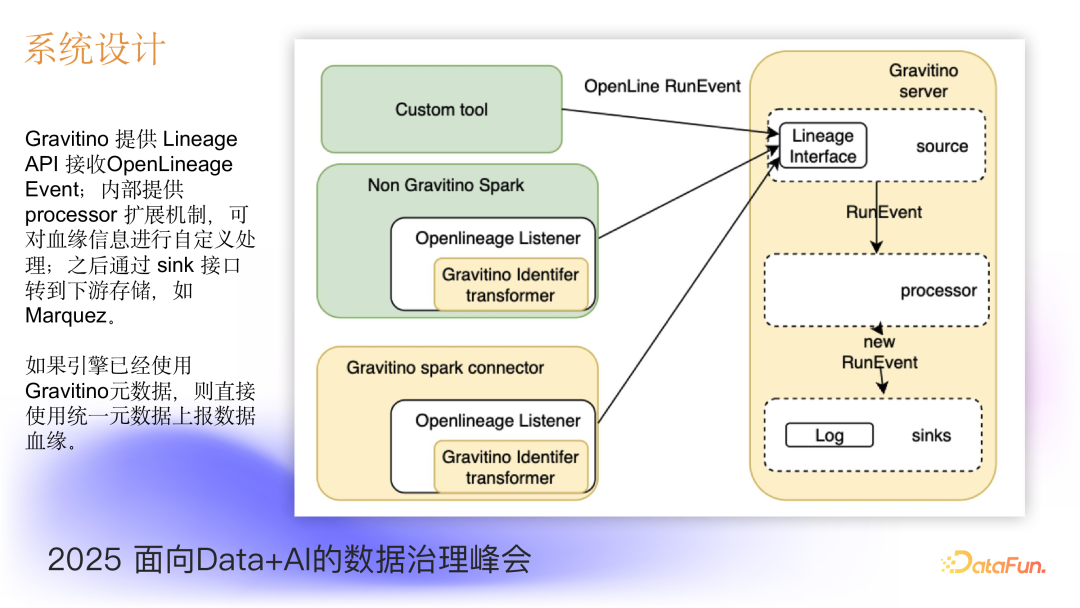
通过如此的系统架构与系统设计,可以清晰看到一个统一血缘的实现。如图所示,能够直观看到左侧 OpenLineage 采集的血缘信息,经过 Gravitino 进行了统一标准化。
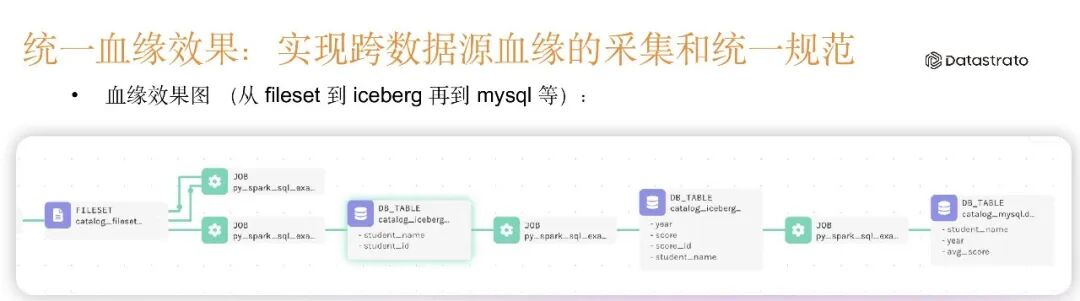
针对多引擎多数据源血缘采集的支持目标,目前 Gravitino 已经实现了 Spark 引擎的血缘采集自动化。Spark 引擎(使用 Gravitino connector)支持 Hive、Iceberg、MySQL、Fileset、Model 等元数据的自动识别,并映射到 OpenLineage Dataset。对于未使用 Gravitino connector 的场景,用户可自行实现 processor,完成对 Dataset facet 内容的识别和匹配,并转换为统一元数据的命名。针对 Flink、Trino 等引擎的支持正在下一步规划中。
以下示例展示了从 Fileset 到 Iceberg 再到 MySQL 的血缘效果图,以及字段级血缘的情况:
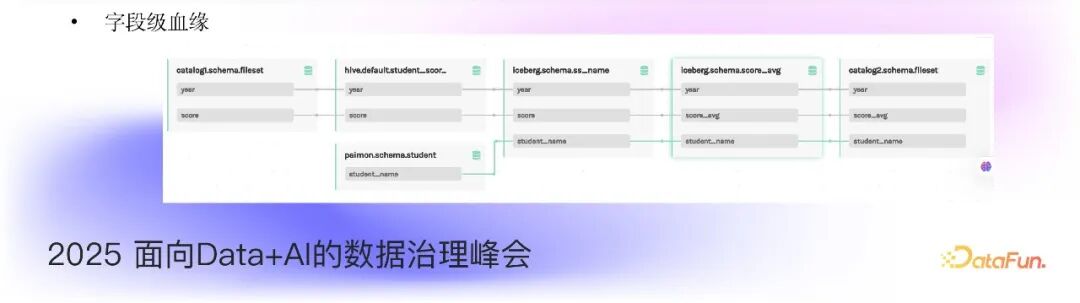
总结而言,Gravitino 统一数据血缘方案的核心价值包括:
- 标准化采集:通过 OpenLineage 插件采集多引擎血缘信息。
- 统一命名空间:将物理数据源映射为逻辑名称,解决血缘图中物理连接信息混乱问题。
- 灵活处理管道:提供 Processor 机制自定义血缘转换规则。
5. 社区发展与未来展望
Apache Gravitino 已于 5 月份成为 Apache TLP 项目,目前 1.0 版本已发布。
- 1.0 版本(2025 年 9 月):新增 Policy System、Action System、Job System、元数据鉴权、MCP server、缓存系统等功能。
- 1.1 及以后版本:将增强 MCP 与 AI Agent 支持,并提供 UDF/AI 函数支持能力。
Gravitino 项目的目标是打造一个开放社区,成为元数据领域的开发标准。其代码仓库地址为 https://github.com/apache/gravitino,项目官网为 https://gravitino.apache.org/。欢迎广大用户和开发者参与社区贡献,共同推进元数据领域标准化的发展。





