DeepSeek近日开源了一款参数量达3B的新型OCR模型。

这不只是又一个OCR模型,更是对AI处理长文本方式的重新思考:如何高效地利用视觉token压缩文本信息。
核心思路
传统方式处理长文档需要大量文本token,计算成本随序列长度二次增长。DeepSeek-OCR的核心想法是:既然一张图片能包含大量文字信息,为什么不用更少的视觉token来表示?
从实验结果来看,这种思路是奏效的。在10倍压缩比内,模型的OCR解码精度能达到97%。即使在20倍压缩比下,准确率仍有60%左右。这意味着,1000个文本token的内容,用100个视觉token就能基本无损表示。
核心技术
DeepSeek-OCR包含两个核心组件:DeepEncoder和DeepSeek3B-MoE解码器。
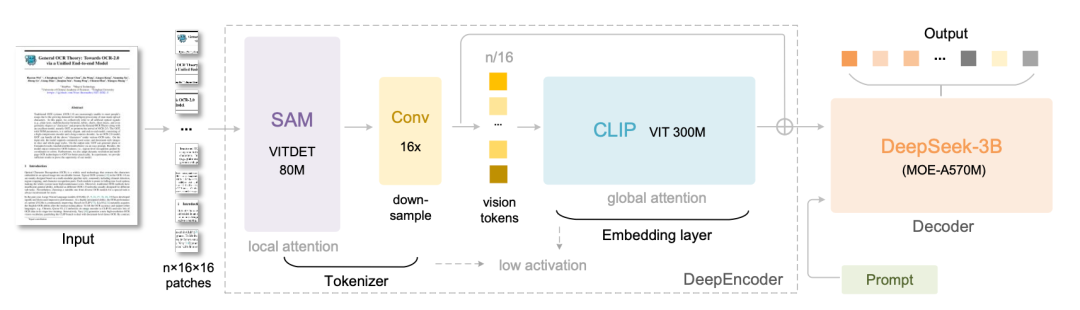
DeepEncoder是关键创新点。它串联了SAM(负责窗口注意力的感知组件)和CLIP(负责全局注意力的知识组件),中间通过16倍卷积压缩器连接。这样设计的好处是窗口注意力能够处理大量视觉token,而压缩器在进入密集全局注意力之前减少token数量,从而既保证了效果又控制了内存消耗。
模型还支持多分辨率。从512×512的Tiny模式到1280×1280的Large模式,甚至支持动态分辨率的Gundam模式,能灵活应对不同场景需求。
性能表现
在OmniDocBench测试中,DeepSeek-OCR仅用100个视觉token就超越了使用256个token的GOT-OCR2.0,用不到800个视觉token就超过了需要近7000个token的MinerU2.0。
不同文档类型的表现差异也值得关注。幻灯片文档只需64个视觉token就能获得良好效果,书籍和报告用100个token就足够了,但报纸需要Gundam模式才能达到可接受的准确率。这反映了不同文档类型的文本密度差异。
点评
DeepSeek的思路可谓“刁钻”。传统OCR通常只将图片转换为文本,而他们却思考如何用视觉信息更高效地表示文本内容。
这种方法直接带来了成本的显著降低。以一个1万页的文档库为例,传统方式需要1000万个文本token,而现在只需100万个视觉token,成本直接降低了10倍。
更深层次地看,这种压缩不仅仅是节约成本,它还解决了几个长期困扰算法和工程领域的大问题:
-
训练数据瓶颈得到缓解。多模态模型此前受限于数据处理能力,现在这一限制已基本不存在。
-
AI智能体的记忆问题有了新解法。智能体最大的问题是会瞬间失忆,上下文过长时容易崩溃。渐进式压缩模拟了人类的遗忘曲线,使得智能体能够持续运行,避免因上下文过载而失效。
-
RAG(检索增强生成)技术可能需要重新考虑其存在价值。既然能够将整个文档库压缩到上下文窗口中,为何还需要分块检索?直接将所有内容放入进行处理即可。
-
实时AI应用变得经济可行。实时文档分析、流式OCR、带视觉上下文的实时翻译等应用,此前因成本过高而难以普及,现在其门槛大幅降低。
或许,这也是有人称之为AI的“JPEG”时刻的原因。
不过,正如论文所指出,这是一项方向性探索,目前主要局限在OCR任务上,许多实际问题仍需进一步验证。