

RAG检索优化的方法论之一,是通过对问题进行改写和优化。例如,当用户输入一个问题(query)时,由于用户行为的不可控性,输入内容可能包含错别字、语义错误或无意义信息。
在多轮对话场景下,这种情况会严重影响数据召回的效果,是RAG系统面临的核心痛点。
RAG检索优化:问题改写的重要性
RAG问题改写的方法多种多样,包括问题优化、相似性子问题生成、假设性回复等。其核心在于利用大模型的能力,对用户提问进行完善和增强。
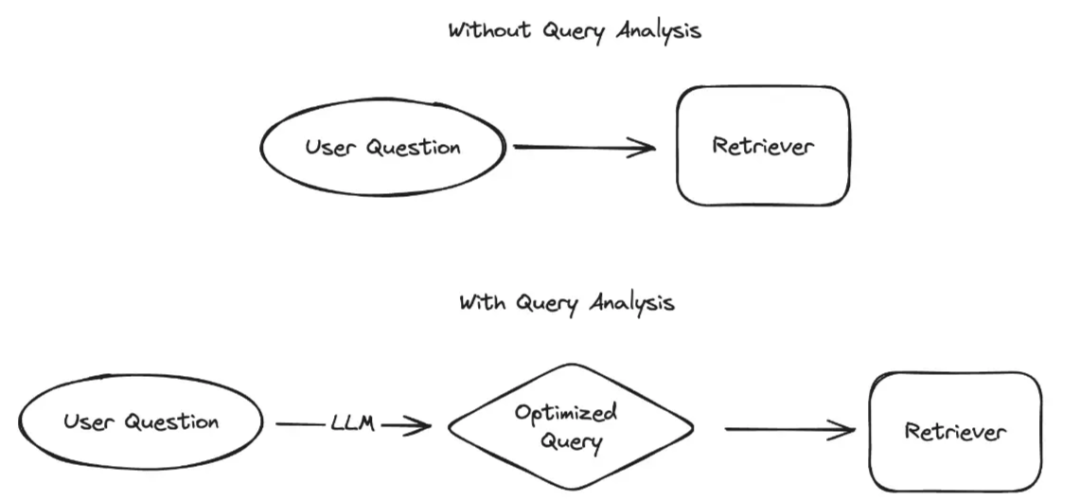
然而,在进行问题改写时,基于历史对话记录进行改写至关重要。为什么会这样?
举例来说,用户提出“怎么学习人工智能技术?”这一问题。RAG系统经过文档检索、生成增强等处理后给出回答,但用户可能认为不够全面,进而提出第二个问题“继续”,意在第一个问题基础上继续追问。这便是典型的多轮对话场景。
那么,当第二个问题“继续”被输入时,会出现什么情况?
若不进行问题改写,基于原始的“继续”二字,数据召回技术可能匹配到完全不相关的内容。这是因为RAG系统缺乏完整的上下文,无法理解“继续”的真实意图,只能进行字面匹配,从而导致召回结果与用户意图严重偏离。这显然是一个关键问题。
RAG的工作原理在于检索和增强是两个独立的步骤。检索旨在通过相似度或其他方式,从向量库或知识存储中获取相关参考文档;而增强则是在检索到的文档基础上,由大模型利用这些文档进行信息整合和生成。
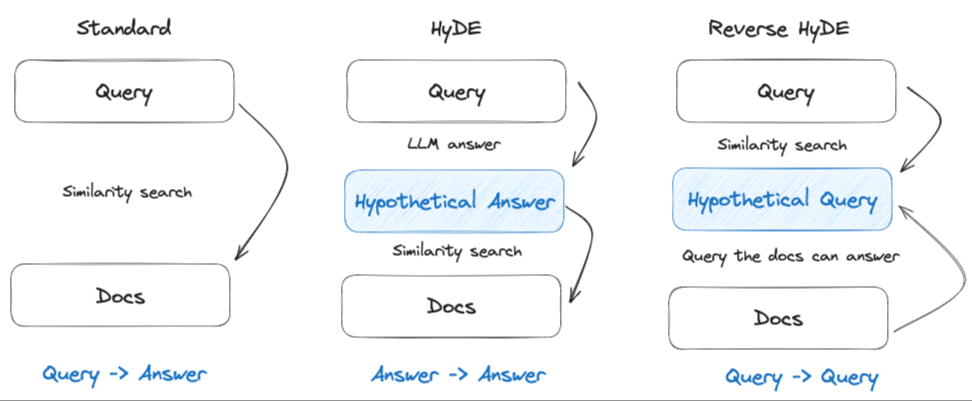
因此,在多轮对话中,确保上下文的完整性至关重要。
尽管在没有问题改写的情况下,用户输入“继续”可能召回无关文档,但如果模型具备记忆功能,它在生成阶段仍能基于自身能力进行回复,而非完全依赖外部知识库。然而,这种回复的质量和相关性远不及基于检索增强的回复。
由此可见,问题改写的重要性不言而喻。若不改写,用户原始问题在丢失上下文的情况下将导致文档召回偏差。因此,在进行问题改写时,务必融入历史对话记录。这将使大模型能够以历史记录作为上下文,更准确地理解用户当前提问,进而生成更相关的问题,以大幅提升文档召回的准确性,最终实现高质量的增强生成效果。
然而,这也带来一个挑战:当用户的两个问题完全无关时,利用历史问题来优化当前问题,反而可能导致召回文档的不准确性。因此,针对这种场景,仍需探索其他解决方案,以期达到最佳优化效果。




