

本系列文章旨在通过实际项目而非枯燥的功能罗列与文档阅读,深入探讨NumPy的实际应用。一直以来,人们普遍认为“边做边学”是最佳的学习方式,因此该项目致力于构建一个兼具实用性与个性化的应用。
该项目的核心理念在于对日常习惯(包括睡眠、学习时长、屏幕时间、锻炼和情绪)进行分析,从而探究这些习惯对个人生产力与整体幸福感的影响。尽管所用数据为虚构并模拟了30天的情况,但项目的重点并非数据的精确性,而是如何通过NumPy进行有意义的数据处理与分析。
接下来,本文将逐步引导读者了解整个分析过程。
步骤一:加载与理解数据
项目首先创建一个简单的NumPy数组,该数组包含30行(代表30天的数据)和6列,每列分别代表一项不同的习惯指标。随后,该数组被保存为.npy文件,以便后续便捷加载。
# TODO: Import NumPy and load the .npy data file
import numpy as np
data = np.load('activity_data.npy')
数据加载完成后,需要对数据结构进行验证,以确保其符合预期。为此,检查了数组的形状(shape)以确定行数与列数,并检查维度数量(ndim)以确认其为二维表格而非一维列表。
# TODO: Print array shape, first few rows, etc.
data.shape
data.ndim
输出结果:30行,6列,ndim=2
此外,还打印了数组的前几行数据,以便直观检查各项数值是否正常,例如,确保睡眠时长没有负值,以及情绪评分在合理范围内。
# TODO: Top 5 rows
data[:5]
输出结果:
array([[ 1. , 6.5, 5. , 4.2, 20. , 6. ],
[ 2. , 7.2, 6. , 3.1, 35. , 7. ],
[ 3. , 5.8, 4. , 5.5, 0. , 5. ],
[ 4. , 8. , 7. , 2.5, 30. , 8. ],
[ 5. , 6. , 5. , 4.8, 10. , 6. ]])
步骤二:数据验证
在进行任何数据分析之前,务必确保数据的合理性与有效性。尽管在处理虚构数据时这一步骤常被省略,但它仍然是良好的实践。
因此,主要检查了以下几点:
- 睡眠时长无负值
- 情绪评分范围在1到10之间
对于睡眠数据,需要选择睡眠时长列(在数组中索引为1),并检查其中是否存在任何小于零的值。
# Make sure values are reasonable (no negative sleep)
data[:, 1] < 0
输出结果:
array([False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False])
该输出表明睡眠时长数据中不存在负值。随后,对情绪评分数据进行了相似的验证。通过计数发现情绪评分列的索引为5,接着检查了该列中是否存在任何小于1或大于10的值。
# Is mood out of range?
data[:, 5] < 1
data[:, 5] > 10
得到了相同的输出结果。
经过验证,所有数据均符合预期,可以继续进行下一步分析。
步骤三:将数据按周进行分割
拥有30天的数据,需要进行逐周分析。最初的思路是使用NumPy的split()函数,但由于30不能被4整除,该方法无法实现均等分割。因此,转而采用了允许非均等分割的np.array_split()函数。
这样便得到了:
- 第一周 → 8天数据
- 第二周 → 8天数据
- 第三周 → 7天数据
- 第四周 → 7天数据
# TODO: Slice data into week 1, week 2, week 3, week 4
weekly_data = np.array_split(data, 4)
weekly_data
输出结果:
[array([[ 1. , 6.5, 5. , 4.2, 20. , 6. ],
[ 2. , 7.2, 6. , 3.1, 35. , 7. ],
[ 3. , 5.8, 4. , 5.5, 0. , 5. ],
[ 4. , 8. , 7. , 2.5, 30. , 8. ],
[ 5. , 6. , 5. , 4.8, 10. , 6. ],
[ 6. , 7.5, 6. , 3.3, 25. , 7. ],
[ 7. , 8.2, 3. , 6.1, 40. , 7. ],
[ 8. , 6.3, 4. , 5. , 15. , 6. ]]),
array([[ 9. , 7. , 6. , 3.2, 30. , 7. ],
[10. , 5.5, 3. , 6.8, 0. , 5. ],
[11. , 7.8, 7. , 2.9, 25. , 8. ],
[12. , 6.1, 5. , 4.5, 15. , 6. ],
[13. , 7.4, 6. , 3.7, 30. , 7. ],
[14. , 8.1, 2. , 6.5, 50. , 7. ],
[15. , 6.6, 5. , 4.1, 20. , 6. ],
[16. , 7.3, 6. , 3.4, 35. , 7. ]]),
array([[17. , 5.9, 4. , 5.6, 5. , 5. ],
[18. , 8.3, 7. , 2.6, 30. , 8. ],
[19. , 6.2, 5. , 4.3, 10. , 6. ],
[20. , 7.6, 6. , 3.1, 25. , 7. ],
[21. , 8.4, 3. , 6.3, 40. , 7. ],
[22. , 6.4, 4. , 5.1, 15. , 6. ],
[23. , 7.1, 6. , 3.3, 30. , 7. ]]),
array([[24. , 5.7, 3. , 6.7, 0. , 5. ],
[25. , 7.9, 7. , 2.8, 25. , 8. ],
[26. , 6.2, 5. , 4.4, 15. , 6. ],
[27. , 7.5, 6. , 3.5, 30. , 7. ],
[28. , 8. , 2. , 6.4, 50. , 7. ],
[29. , 6.5, 5. , 4.2, 20. , 6. ],
[30. , 7.4, 6. , 3.6, 35. , 7. ]])]
至此,数据已被成功分割成四个部分,可以轻松地对每一周的数据进行独立分析。
步骤四:计算每周指标
为了了解各项习惯在不同周之间的变化趋势,将分析重点放在了以下四个主要指标上:
- 平均睡眠时长
- 平均学习时长
- 平均屏幕使用时间
- 平均情绪评分
将每周的数组分别存储在不同的变量中,然后使用np.mean()函数计算每个指标的平均值。
平均睡眠时长
# store into variables
week_1 = weekly_data[0]
week_2 = weekly_data[1]
week_3 = weekly_data[2]
week_4 = weekly_data[3]
# TODO: Compute average sleep
week1_avg_sleep = np.mean(week_1[:, 1])
week2_avg_sleep = np.mean(week_2[:, 1])
week3_avg_sleep = np.mean(week_3[:, 1])
week4_avg_sleep = np.mean(week_4[:, 1])
平均学习时长
# TODO: Compute average study hours
week1_avg_study = np.mean(week_1[:, 2])
week2_avg_study = np.mean(week_2[:, 2])
week3_avg_study = np.mean(week_3[:, 2])
week4_avg_study = np.mean(week_4[:, 2])
平均屏幕使用时间
# TODO: Compute average screen time
week1_avg_screen = np.mean(week_1[:, 3])
week2_avg_screen = np.mean(week_2[:, 3])
week3_avg_screen = np.mean(week_3[:, 3])
week4_avg_screen = np.mean(week_4[:, 3])
平均情绪评分
# TODO: Compute average mood score
week1_avg_mood = np.mean(week_1[:, 5])
week2_avg_mood = np.mean(week_2[:, 5])
week3_avg_mood = np.mean(week_3[:, 5])
week4_avg_mood = np.mean(week_4[:, 5])
为了使结果更易于阅读,对数据进行了清晰的格式化输出。
# TODO: Display weekly results clearly
print(f"Week 1 — Average sleep: {week1_avg_sleep:.2f} hrs, Study: {week1_avg_study:.2f} hrs, "
f"Screen time: {week1_avg_screen:.2f} hrs, Mood score: {week1_avg_mood:.2f}")
print(f"Week 2 — Average sleep: {week2_avg_sleep:.2f} hrs, Study: {week2_avg_study:.2f} hrs, "
f"Screen time: {week2_avg_screen:.2f} hrs, Mood score: {week2_avg_mood:.2f}")
print(f"Week 3 — Average sleep: {week3_avg_sleep:.2f} hrs, Study: {week3_avg_study:.2f} hrs, "
f"Screen time: {week3_avg_screen:.2f} hrs, Mood score: {week3_avg_mood:.2f}")
print(f"Week 4 — Average sleep: {week4_avg_sleep:.2f} hrs, Study: {week4_avg_study:.2f} hrs, "
f"Screen time: {week4_avg_screen:.2f} hrs, Mood score: {week4_avg_mood:.2f}")
输出结果:
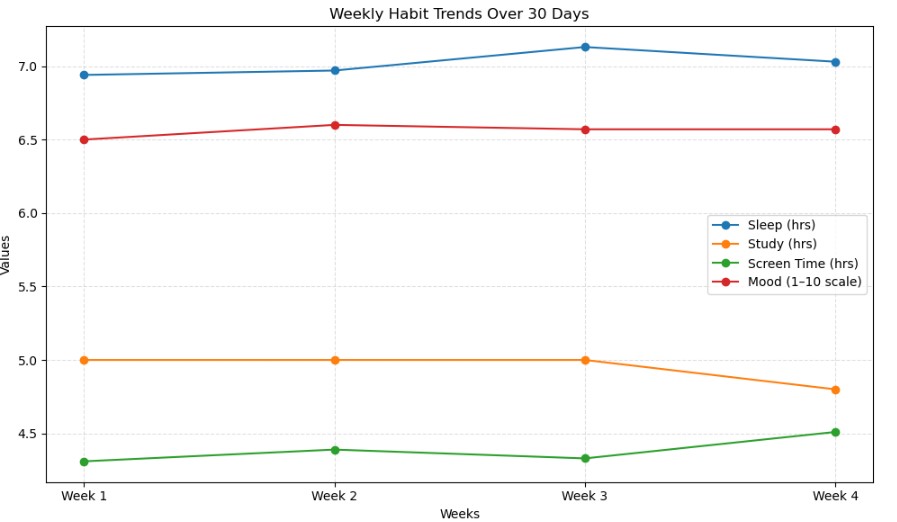
Week 1 – Average sleep: 6.94 hrs, Study: 5.00 hrs, Screen time: 4.31 hrs, Mood score: 6.50
Week 2 – Average sleep: 6.97 hrs, Study: 5.00 hrs, Screen time: 4.39 hrs, Mood score: 6.62
Week 3 – Average sleep: 7.13 hrs, Study: 5.00 hrs, Screen time: 4.33 hrs, Mood score: 6.57
Week 4 – Average sleep: 7.03 hrs, Study: 4.86 hrs, Screen time: 4.51 hrs, Mood score: 6.57
步骤五:解读分析结果
在打印出各项数据后,一些显著的模式逐渐显现。
睡眠时长在前两周保持相对稳定(约6.9小时),但到第三周则显著增加至约7.1小时,这表明随着时间推移,睡眠质量有所改善。第四周的平均睡眠时长则稳定在7.0小时左右。
学习时长则呈现出相反的趋势。第一周和第二周的平均学习时长约为每天5小时,但到第四周,这一数字下降至约4小时。这反映出项目初期投入较高,但随后学习动力逐渐减弱——这一情况也符合普遍观察。
接下来是屏幕使用时间。这项数据有些令人担忧。第一周平均每天约4.3小时,此后每周都呈现出持续攀升的趋势。这反映了一种典型的模式:项目初期效率较高,但随着时间推移,人们逐渐倾向于增加“刷手机”的休息时间。
最后是情绪评分。情绪评分在第一周约为6.5分,第二周略微上升至6.6分,随后在剩余的时间里保持在这一水平。尽管情绪评分没有出现剧烈波动,但在第二周观察到一个小幅上升,这恰好发生在学习时长下降和屏幕使用时间增加之前,是一个有趣的发现。
为了使分析结果更具互动性和直观性,通过Matplotlib进行数据可视化将是一个极佳的选择。
步骤六:探寻潜在模式
掌握了各项数据后,下一步是探究**为何**第二周的情绪评分会有所提升。
对各周数据进行对比分析发现,第二周的睡眠时长适中,学习时长较高,且相对于后续几周,屏幕使用时间也相对较低。
这或许解释了情绪评分在该周达到顶峰的原因。到了第三周,即使睡眠时间有所增加,学习时长却开始下降——这可能意味着虽然休息更多,但完成的任务量减少,因此情绪提升的效果不如预期。
该项目最吸引人的地方在于,其意义并非局限于数据是否真实,而在于如何运用NumPy来探索数据中的模式、关联和细微洞察。即使是虚构数据,只要方法得当,也能讲述引人入胜的故事。
步骤七:总结与展望
通过这个小型项目,掌握了一些关键要点,不仅加深了对NumPy的理解,也熟悉了此类数据分析的结构化方法。
整个过程始于一份包含虚构日常习惯的原始数组,随后学习了如何检查其结构与有效性,将其分割成有意义的时间段(周),并运用简单的NumPy操作对每个时间段进行了分析。
这样的项目提醒着人们,数据分析并非总是复杂深奥的。有时,它只是关乎提出一些简单的问题,例如“我的屏幕使用时间是如何随时间变化的?”或“我在什么时候感觉最好?”
如果希望进一步拓展此项目(后续很可能会进行),有许多方向可供探索:
- 找出整体表现**最佳和最差的日子**
- 对比**工作日与周末**的习惯差异
- 甚至可以根据多项习惯的组合创建一个简单的“幸福感评分”
不过,这些内容将留待本系列的下一部分进行探讨。
目前,能够将NumPy应用于实际且贴近生活的问题(而非仅仅是抽象的数组和数字,而是具体的习惯与情绪),这本身就是一种令人满意的体验。这种将知识与实际结合的学习方式,往往能留下更深刻的印象。




