Anthropic公司近期动作频频,继推出MCP标准之后,又发布了全新的Skills功能。每一次发布都为他们的智能体工具包增添了新的组成部分。随之而来的,自然是关于这些新功能的核心疑问:何时使用?作用何在?以及它们如何融入当前的智能体生态系统?
本文将尝试解答这些问题。经过初步探索,Skills功能被视为一种用户范围(并可能扩展到组织范围)的、基于文件的程序性记忆形式。它用于存储指令、最佳实践以及使用模式,指导大型语言模型(LLM)如何与特定工具或任务进行交互。
单个Skill以文件夹的形式组织,其中包含指令、脚本和资源,Claude可以动态加载这些内容,以提升其在专业任务上的表现。目前,大多数示例都展示了Python代码执行,演示了Skills如何直接在Claude环境中自动化或扩展工作流。Skills的复杂程度各异,从简单的基于指令的工作流到结合代码、元数据和资源的完整模块化功能。其核心在于,每个Skill都是一个文件夹,封装了指令和可选脚本,让Claude能够为任务动态加载正确的上下文。例如,一个基本Skill可能只包含简短的描述和基于Markdown的指导,而一个更高级的Skill则可以打包参考文件和可执行脚本,实现跨工具或MCP服务器的可重复自动化。以下是一个SKILL.md文件的示例:
=== Level 1
---
name: pdf-processing
description: Extract text and tables from PDF files, fill forms, and merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
---
=== Level 2
# PDF Processing
## Quick start
Use pdfplumber to extract text from PDFs:
python
import pdfplumber
with pdfplumber.open(“document.pdf”) as pdf:
text = pdf.pages[0].extract_text()
=== Level 3
## When to Load Reference Documentation
Load the appropriate reference file when:
### references/pdfplumber-api.md
* You need details on all available methods for extracting text, tables, or metadata.
* You want examples of using `extract_text()`, `extract_tables()`, or layout analysis features.
* You're troubleshooting inconsistent extraction results or bounding box coordinates.
每个Skill都可以包含三个层级或类型的内容。
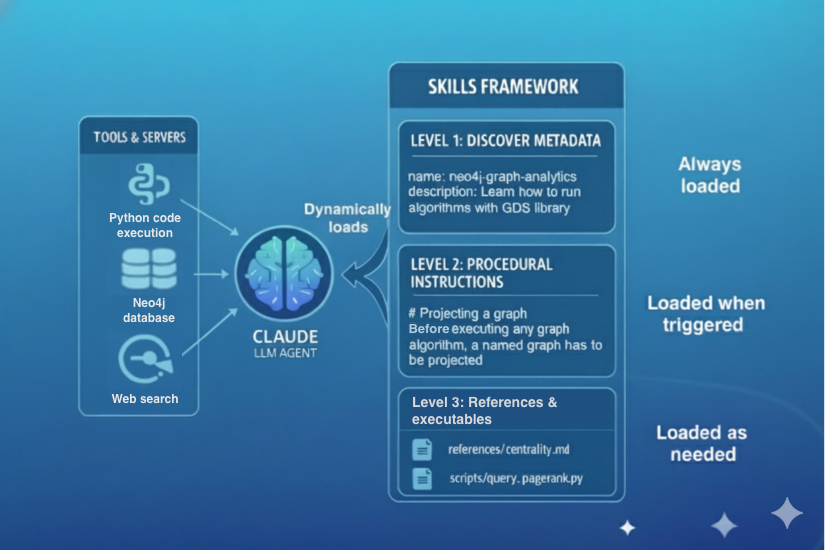
Claude Skills的层级及其如何融入智能体生态系统。图片由作者创建。
第一层级(Level 1)提供简洁的元数据,始终可供LLM发现,帮助Claude了解何时应用某个Skill。第二层级(Level 2)包含程序性指令,仅在相关时加载,为Claude提供任务特定的专业知识,而不会不必要地占用上下文,这些指令以SKILL.md文件的形式存在。第三层级(Level 3)引入了支持资源和可执行脚本,实现确定性操作和更丰富的自动化。这些是SKILL.md文件中提及的附加文件,以便LLM知道何时打开哪个文件。这种渐进式结构共同确保了上下文使用的效率,同时根据需要解锁越来越强大的专业行为。
尽管大多数示例展示了Skills与Python代码执行的结合,但它们并不局限于此。Skills还可以定义可重用的指令和结构化流程,用于与其他可用工具或MCP服务器协同工作,使其成为一种灵活的方式,能够更有效地教导Claude执行特定任务。
提升LLM对Cypher的理解
鉴于与Neo4j的紧密合作关系,本文将以其作为示例进行深入探讨。目前,大多数LLM仍然使用过时或已弃用的语法,对最新的Cypher模式不够熟悉,这常常导致常见的错误。在本文中,将构建一个Claude Skill,以提高LLM生成Cypher查询的能力,无论模型是通过MCP Cypher服务器还是Python代码执行来从Neo4j获取信息。
一个值得称赞的特性是,可以使用Claude来辅助创建Skill。但需要注意的是,这会消耗大量的token,有几次甚至达到了Pro版本的限制。
Claude Desktop中的Skill创建功能。图片由作者提供。
提示词指示模型通过网络搜索了解Neo4j 5.0以来被弃用的语法,包括更新的子查询格式,并处理量化路径模式。LLM通常会在这方面遇到困难,因为网上大多数Cypher示例都是在Neo4j 5.0之前编写的。此外,还添加了多种使用模式,例如要求模型在排序之前应用过滤器,以确保被排序的属性不为空(尽管最新的Claude模型似乎已不再存在此问题)。
经过多次迭代,开发出了以下Claude Skill。其设计理念是仅关注读取查询,因此有意排除了任何写入或索引语法的变更。
该Skill可在GitHub上获取。
第一层级(Level 1)
第一层级的元数据定义了Skill的身份和目的,以便Claude能够识别何时激活它。它提供了Skill功能和实用性的高层次摘要,使其在涉及Cypher生成或Neo4j查询验证的项目中易于发现。通过保持这些信息的轻量级并始终加载,Claude可以快速将涉及Cypher或Neo4j的提示与此Skill匹配,而无需首先解析详细指令。
---
name: neo4j-cypher-guide
description: Comprehensive guide for writing modern Neo4j Cypher read queries.
Essential for text2cypher MCP tools and LLMs generating Cypher queries.
Covers removed/deprecated syntax, modern replacements, CALL subqueries for reads, COLLECT patterns, sorting best practices, and Quantified Path Patterns (QPP) for efficient graph traversal.
---
这在概念上类似于工具描述,因为它告诉模型Skill的功能、何时使用以及它与哪些类型的任务相关。主要区别在于,Skill的执行仅仅是打开一个包含程序性记忆的文件(即使用模式的指令),而不是直接调用工具。然而,也可以实现一个处理记忆的工具(例如,如果希望将此类程序性指令存储在数据库而不是文件中)。
第二层级(Level 2)
在第二层级,Skill超越了简单的能力声明,包含了作为正确执行任务具体方法的程序性知识。当Claude检测到与Skill触发条件(在第一层级定义)匹配的用户请求时,它会动态地从磁盘读取相应的SKILL.md文件。该文件仅在需要时加载,保持上下文轻量级,同时仍提供详细指令。
一个好的SKILL.md文件不仅描述了Skill能做什么,还展示了如何安全、正确地完成任务。它通常以简短的程序性检查和原则开头,作为模型的操作规则。这些规则定义了需要避免什么、偏好什么以及哪些模式代表了现代最佳实践。对于这个示例,Skill专注于生成现代Neo4j Cypher查询。它首先列出需要避免的过时语法,并建立明确的生成规则以强制一致性:
This skill helps generate Neo4j Cypher read queries using modern syntax patterns and avoiding deprecated features. It focuses on efficient query patterns for graph traversal and data retrieval.
## Quick Compatibility Check
When generating Cypher queries, immediately avoid these REMOVED features:
- `id()` function → Use `elementId()`
- Implicit grouping keys → Use explicit WITH clauses
- Pattern expressions for lists → Use pattern comprehension or COLLECT subqueries
- Repeated relationship variables → Use unique variable names
- Automatic list to boolean coercion → Use explicit checks
## Core Principles for Query Generation
1. **Use modern syntax patterns** - QPP for complex traversals, CALL subqueries for complex reads
2. **Optimize during traversal** - Filter early within patterns, not after expansion
3. **Always filter nulls when sorting** - Add IS NOT NULL checks for sorted properties
4. **Explicit is better than implicit** - Always use explicit grouping and type checking
最后,SKILL.md文件定义了何时引入额外的参考文件。这告诉Claude何时获取更深层次的上下文,例如迁移指南、子查询技术或路径优化说明,但仅在任务需要时才进行。
## When to Load Reference Documentation
Load the appropriate reference file when:
### references/deprecated-syntax.md
- Migrating queries from older Neo4j versions
- Encountering syntax errors with legacy queries
- Need complete list of removed/deprecated features
### references/subqueries.md
- Working with CALL subqueries for reads
- Using COLLECT or COUNT subqueries
- Handling complex aggregations
- Implementing sorting with null filtering
### references/qpp.md
- Optimizing variable-length path queries
- Need early filtering during traversal
- Working with paths longer than 3-4 hops
- Complex pattern matching requirements
在定义了规则之后,该Skill通过简短的示例展示了如何应用这些规则,从而模拟了正确的行为。这些代码片段并非随意选取,它们展示了模型在生成查询时实际使用的程序性知识。
### For Aggregations
Use COUNT{}, EXISTS{}, and COLLECT{} subqueries:
cypher
MATCH (p:Person)
WHERE count{(p)-[:KNOWS]->()} > 5
RETURN p.name,
exists{(p)-[:MANAGES]->()} AS isManager
### For Complex Read Operations
Use CALL subqueries for sophisticated data retrieval:
cypher
MATCH (d:Department)
CALL (d) {
MATCH (d)<-[:WORKS_IN]-(p:Person)
WHERE p.salary IS NOT NULL // Filter nulls
WITH p ORDER BY p.salary DESC
LIMIT 3
RETURN collect(p.name) AS topEarners
}
RETURN d.name, topEarners
## Common Query Transformations
### Counting Patterns
cypher
// Old: RETURN size((n)-[]->())
// Modern: RETURN count{(n)-[]->()}
### Checking Existence
cypher
// Old: WHERE exists((n)-[:REL]->())
// Modern: WHERE EXISTS {MATCH (n)-[:REL]->()}
// Also valid: WHERE exists{(n)-[:REL]->()}
简而言之,第二层级Skill在SKILL.md内部定义了一个清晰、分步的程序:它设置兼容性检查,通过示例编码方法,并指定何时获取额外上下文。
第三层级(Level 3)
在第三层级,LLM具备了智能扩展自身上下文的能力。Claude不再仅仅依赖主SKILL.md文件,而是可以根据任务需求决定加载哪些支持文件。例如,如果用户提示涉及遗留语法,它可以打开references/deprecated-syntax.md;如果涉及聚合或子查询,它可以引入references/subqueries.md;而对于遍历优化,它可以加载references/qpp.md。这些文件仍然是静态的Markdown格式,但Claude现在拥有自主权,可以从中精确地组装所需的上下文,而不再依赖单一的入口点。
第三层级还可以包含可执行文件。尽管此Skill中未包含,但Python脚本可以与Markdown参考文件并存,例如,一个validate_syntax.py或generate_query.py实用程序。在这种情况下,Claude既可以阅读程序性指导,也可以调用可执行文件来执行具体的验证、转换或快速计算等操作。
总之,第三层级增加了上下文自主性和可选执行能力。Claude可以决定加载哪些参考材料以更有效地进行推理,并且,如果可用,它还可以调用支持性可执行文件来根据其推理进行操作。
另外,计划将很快撰写一篇博客文章,介绍如何为Python代码执行添加Neo4j Skill。
使用示例
可以通过附加一个Cypher MCP服务器来测试Cypher Skill。将使用一个名为companies的演示数据库,其中包含关于组织、人员等信息。可以通过以下MCP配置进行设置:
{
"mcpServers": {
"neo4j-database": {
"command": "uvx",
"args": [ "mcp-neo4j-cypher@0.4.1", "--transport", "stdio" ],
"env": {
"NEO4J_URI": "neo4j+s://demo.neo4jlabs.com",
"NEO4J_USERNAME": "companies",
"NEO4J_PASSWORD": "companies",
"NEO4J_DATABASE": "companies"
}
}
}
}
现在,给出一个示例问题!

图片由作者提供。
在此示例中,模型首先确定需要检索图谱模式。为了遵循最佳实践,它随后加载了Neo4j指南Skill,然后才生成Cypher查询。可以看到,它使用了QPP(量化路径模式),这是复杂遍历的推荐方法。然而,使用Skills带来的所有这些好处,也伴随着成本增加和延迟增高。
也可以在不使用Skill的情况下进行测试,以观察其差异。
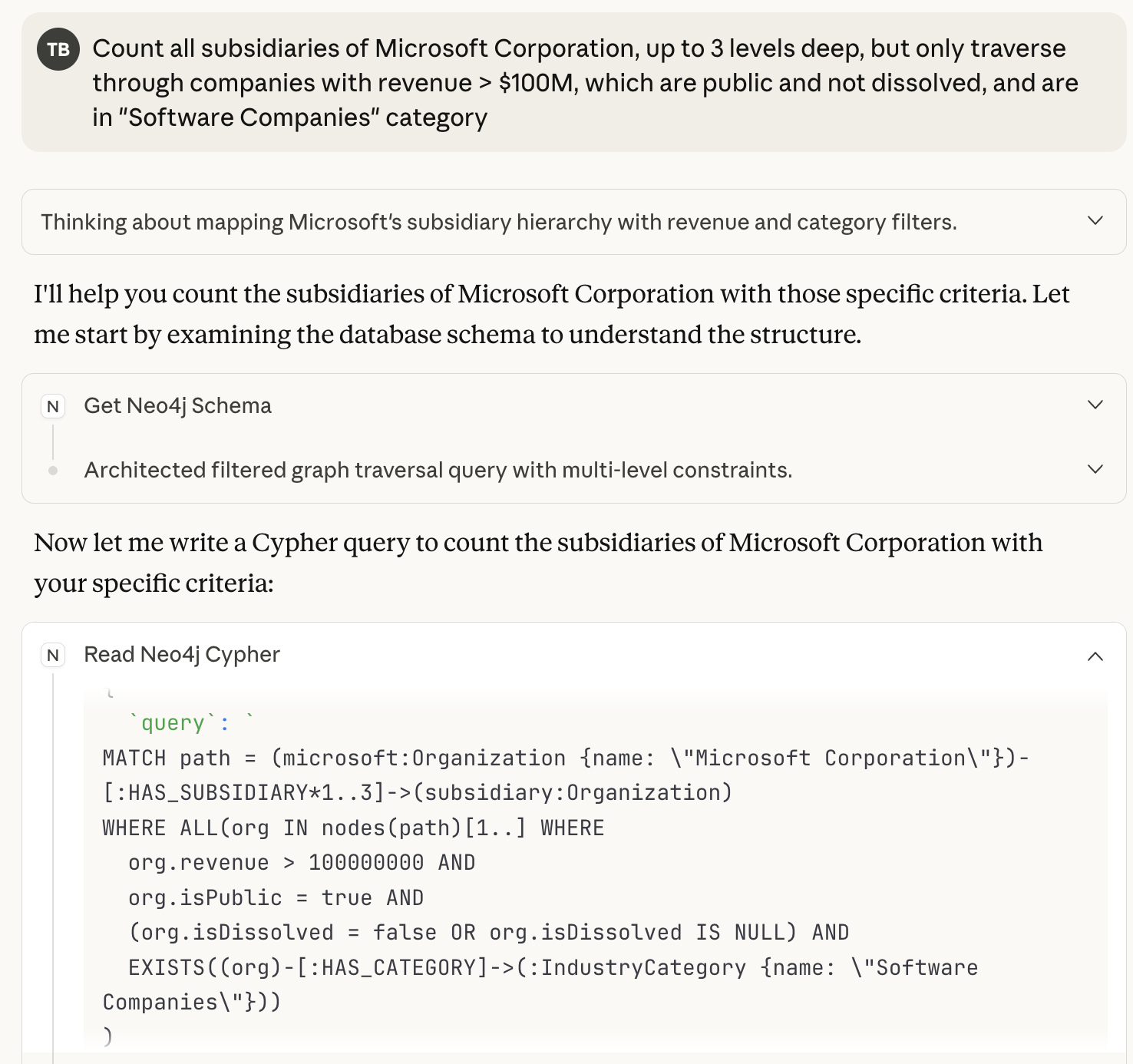
图片由作者提供。
在没有Skill的情况下,LLM直接生成了Cypher查询,并使用了旧的复杂遍历语法,这可能导致高达1000倍的性能下降。
总结
Skills功能被认为是智能体生态系统朝着标准化和可重用性迈进的自然下一步。它们本质上是模块化、基于文件的程序性记忆构建块,通过清晰、可重用的指导,可以跨项目或团队共享,从而教会模型如何更一致地工作。在Neo4j的语境中,这意味着最终可以为LLM提供一个可靠的现代Cypher语法和最佳实践参考,而不是寄希望于它们能从过时来源中回忆起零散的示例。
与此同时,Skills仍处于早期阶段。它们增加了另一层复杂性,并带来了一定的延迟,因为每个步骤都涉及获取、加载和解释额外的文件。从某种意义上说,它们只是工具的一种变体,是一种结构化的方式来存储和重用指令,而非直接执行代码。系统提示和Skill之间界限将如何演变,将是一个值得关注的问题。
无论如何,这是朝着正确方向迈出的坚实一步。它推动了生态系统走向更模块化、可解释和可重用的智能体行为。鉴于这个领域发展迅速,一切都还很新,所以目前只能拭目以待其后续发展。