

在构建RAG(Retrieval-Augmented Generation)系统时,许多开发者常常面临一个核心难题:如何处理文本分词以确保高效准确的全文检索。错误的文本切分可能导致专有名词无法被正确识别,严重影响检索质量。


Milvus Analyzer 如何避免大模型将《无线电法国别研究》误解为“无线电,法国别研究”?

在RAG系统与向量数据库的实践中,分词问题常常成为一个“噩梦”。Milvus虽然在2.5版本就引入了全文检索(Full-text Search)功能,但用户在实际部署RAG时,仍可能遇到地名、人名、专有词汇无法被准确检索的问题。
例如,在《鲁迅全集》中,可能检索到“藤野先生”却无法检索到“藤野”;在半导体领域,能够搜索“EUV”或“光刻机”,却无法搜到“EUV光刻机”。
这并非是Embedding模型选择不当,也不是向量检索阈值设置过高,更与Milvus本身的性能无关。最大的可能在于分词环节,选择了不合适的Analyzer。
典型错误包括将“武汉市长江大桥”错误分词为“武汉市长”和“江大桥”,以及将“霍格沃兹魔法学院”分词为“霍格沃兹魔”和“法学院”等。

分词环节常见问题除了过度分词,还包括分词不足和语言不匹配等。要解决这些挑战并实现高效全文检索,选择合适的Analyzer至关重要。在文本处理中,Analyzer负责将原始文本转换为结构化、可搜索的格式,其选择直接决定了最终的查询质量。
因此,本文将重点解读Analyzer 的工作原理、不同场景下的选型策略,以及如何在生产环境中落地实践。
什么是 Milvus Analyzer?
简而言之,Milvus Analyzer 是 Milvus 提供的文本预处理与分词工具,用于将原始文本拆解为 token,并对其进行标准化和清洗,从而更好地支持全文检索和 text match。
下图展示了 Milvus Analyzer 的整体架构:
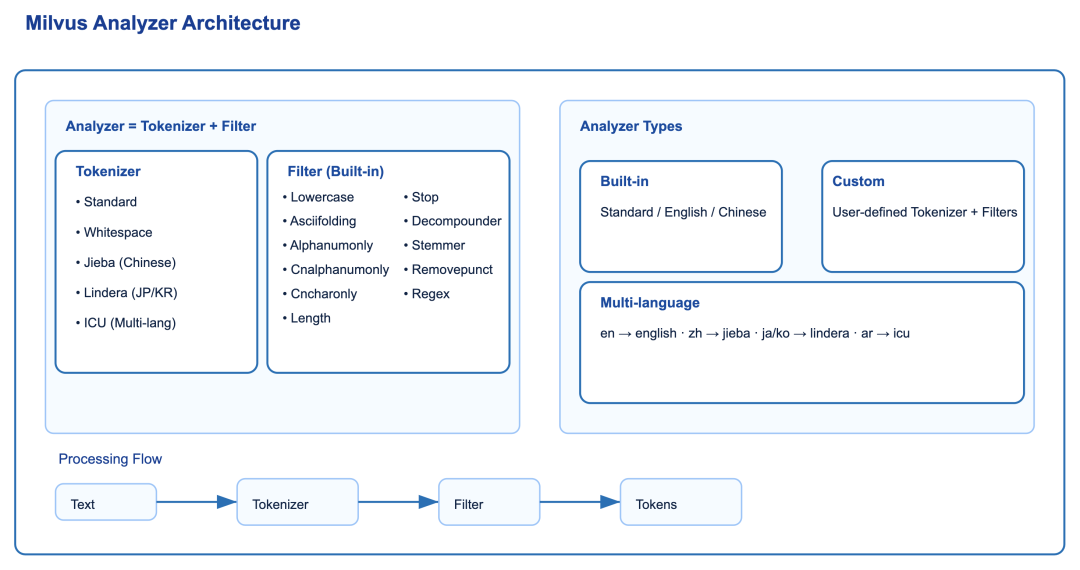 从图中可以看出,Milvus Analyzer 的整体处理流程可以总结为:原始文本 → Tokenizer → Filter → Tokens。
从图中可以看出,Milvus Analyzer 的整体处理流程可以总结为:原始文本 → Tokenizer → Filter → Tokens。
Analyzer 的核心组件有两个,Tokenizer(分词器)与Filter(过滤器)。它们共同将输入文本转换为词元(token),并对这些词元进行优化,以便为高效的索引和检索做好准备。
-
Tokenizer(分词器):负责把文本切分成基础的 token,例如按空格切分(Whitespace)、中文分词(Jieba)、多语言分词(ICU)等。
-
Filter(过滤器):对 token 进行特定的处理方法,Milvus 内置了丰富的 filter,例如统一大小写(Lowercase)、去掉标点(Removepunct)、停用词过滤(Stop)、词干提取(Stemmer)、正则匹配(Regex)等。Milvus 支持设置多个 filter 按顺序处理,可以满足复杂的 token 处理需求。
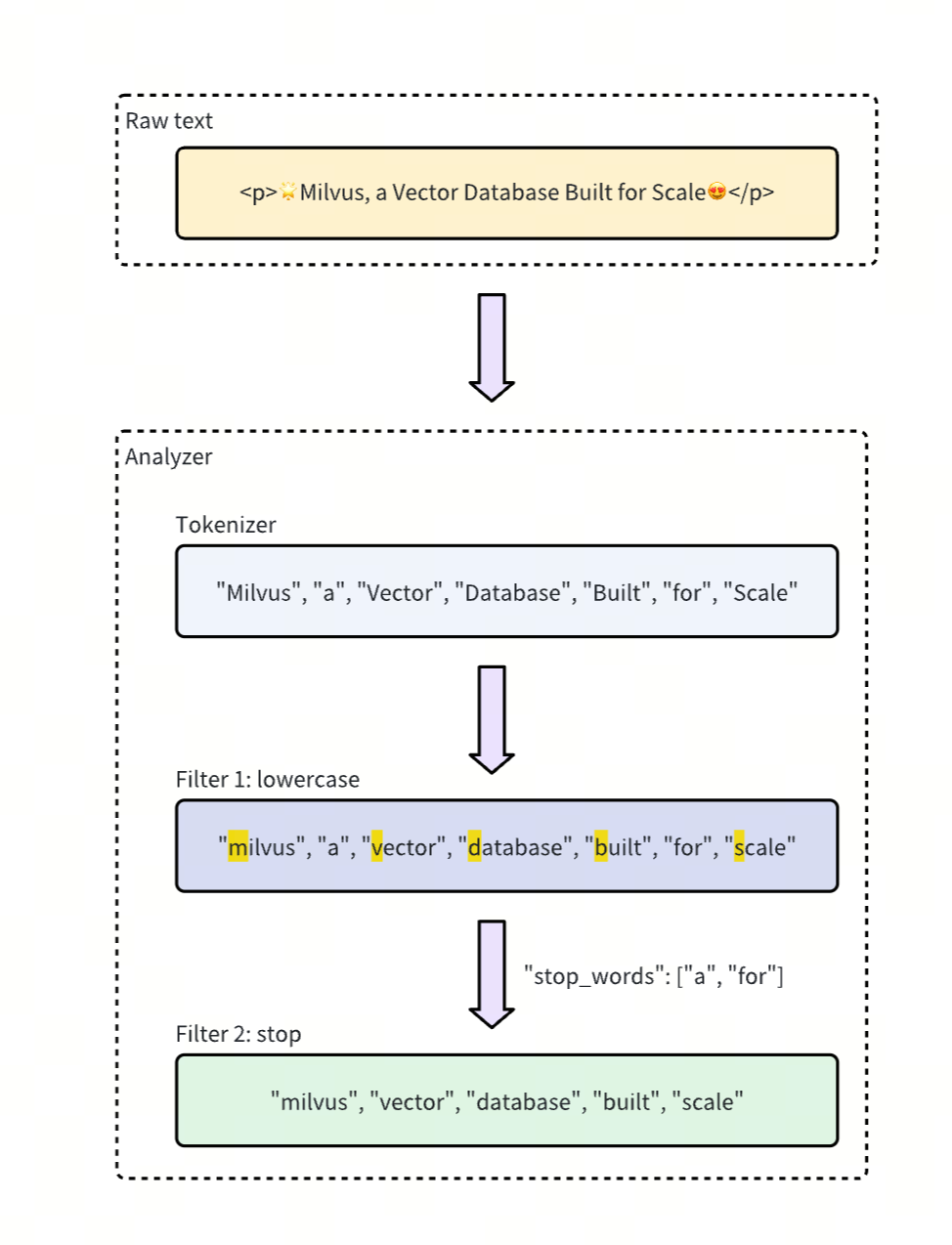
(1) Tokenizer
Tokenizer 是 Milvus Analyzer 的第一步处理工具,它的任务是将一段原始文本切分成更小的 token(词或子词)。不同语言、不同场景需要使用不同的 Tokenizer。Milvus 目前支持以下几类 Tokenizer:
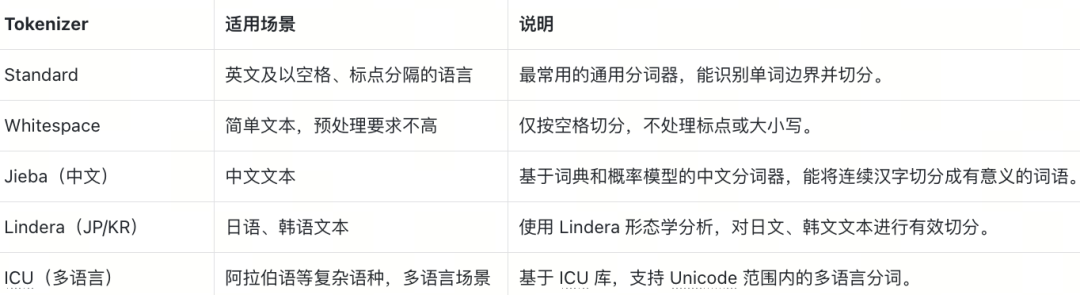
在 Milvus 中,Tokenizer 是在创建 Collection 的 Schema 时配置的,具体是在定义 VARCHAR 字段时,通过analyzer_params指定。这意味着 Tokenizer 并不是一个单独的对象,而是绑定在字段级别的配置里,Milvus 在插入数据时会自动进行分词和预处理。
FieldSchema( name="text", dtype=DataType.VARCHAR, max_length=512, analyzer_params={"tokenizer": "standard" # 这里配置 Tokenizer })
(2)Filter
如果说 Tokenizer 是切分文本的“刀”,那么 Filter 就是其后的“精修工序”。在 Milvus Analyzer 中,Filter 的作用是对切分后的 token 进行进一步的标准化、清洗或改造,使最终的 token 更适合用于检索。
例如,统一大小写、去除停用词(如 “the”、“and”)、去除标点、词干提取(如 running → run)等,都是典型的 Filter 工作。
Milvus 内置了多种常用 Filter,可满足大部分语言处理需求:
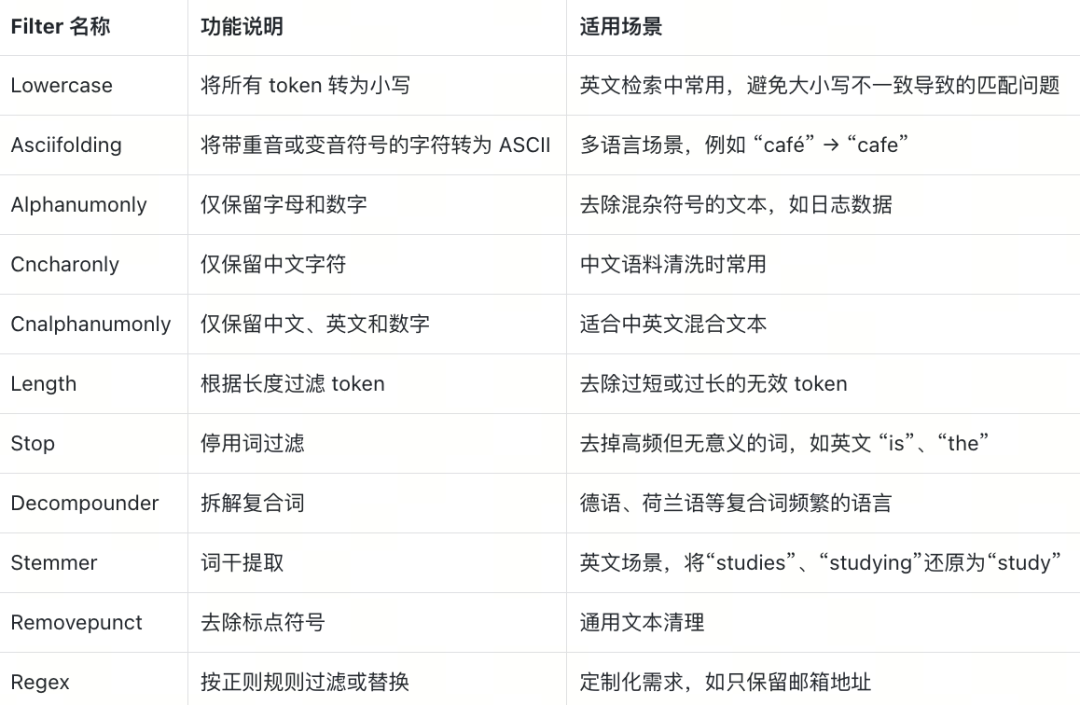
使用 Filter 的优势在于,开发者可以根据业务场景灵活组合不同的清洗规则。例如,在英文搜索中,常见的组合是 Lowercase + Stop + Stemmer,这能确保大小写统一、去除无意义词汇,并将不同形态的词统一为词干。
在中文搜索中,通常会结合 Cncharonly + Stop,使分词结果更简洁、更精准。在 Milvus 中,Filter 与 Tokenizer 一样,通过analyzer_params配置在 FieldSchema 中。例如:
FieldSchema( name="text", dtype=DataType.VARCHAR, max_length=512, analyzer_params={ "tokenizer": "standard","filter": ["lowercase", {"type": "stop", # Specifies the filter type as stop"stop_words": ["of","to","_english_"], # Defines custom stop words and includes the English stop word list }, {"type": "stemmer", # Specifies the filter type as stemmer"language": "english" }], })
Analyzer 类型
选择合适的 Analyzer 可以显著提高检索效率并降低成本。为满足不同场景需求,Milvus 提供了三类 Analyzer:
-
内置(Built-in)的 Standard/English/Chinese 三种 Analyzer
-
基于用户自定义 Tokenizer 和 Filter 组成的 Custom Analyzer
-
在多语言文档场景中非常实用的 Multi-language Analyzer。
(1) 内置 Analyzer (Built-in)
内置 Analyzer 是 Milvus 自带的标准配置,开箱即用,适用于大多数常见场景。它们已预定义好 Tokenizer 和 Filter 的组合:
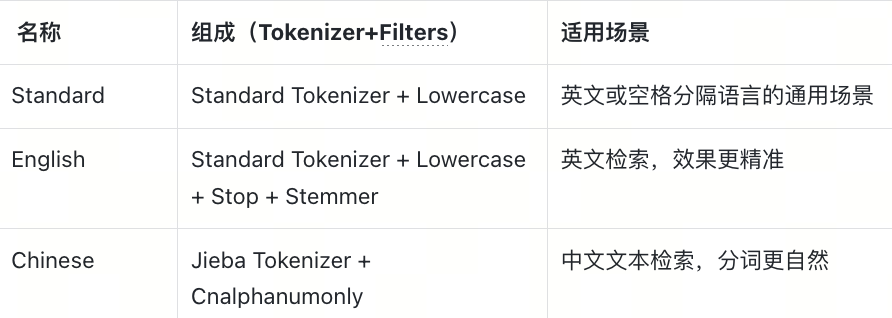
如果仅需常见的英文或中文搜索,可以直接使用内置 Analyzer,无需额外配置。
这里需要注意的是,Standard Analyzer 默认处理英文文档。如果中文使用 Standard Analyzer,后续可能出现全文搜索无结果的问题,社区中已有不少用户遇到此情况。
(2) 多语言 Analyzer (Multi-language)
在跨语言文本库中,单一分词器往往无法覆盖所有语种。为此,Milvus 提供了 Multi-language Analyzer,它会根据文本的语言自动选择合适的分词器。
不同语言使用的 Tokenizer 对照表:
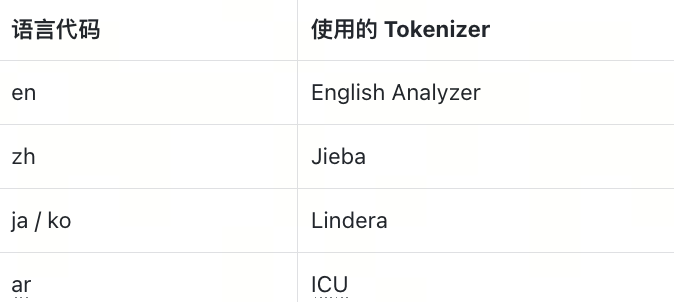
这意味着,如果数据集同时包含英文、中文、日文、韩文甚至阿拉伯文,Milvus 可以在同一个字段里进行灵活处理,大大减少了手工预处理的复杂度。
(3) 自定义 Analyzer (Custom)
如果内置或多语言 Analyzer 不能完全满足需求,Milvus 还支持用户自定义 Analyzer。通过自由组合 Tokenizer 和 Filter,可以形成一个符合业务特点的 Analyzer。
例如:
FieldSchema( name="text", dtype=DataType.VARCHAR, max_length=512, analyzer_params={"tokenizer": "jieba", "filter": ["cncharonly","stop"] # 自定义组合,比如中英混合语料中只搜中文,且去掉中文停用词,比如“的”、“了”、“在” } )
代码实践
以下通过 Python SDK 演示如何在 Milvus 中使用 Analyzer,将分别展示普通 Analyzer 和多语言 Analyzer 的用法。
本文使用的 Milvus 版本为 v2.6.1,Pymilvus 版本为 v2.6.1。
(1) 普通 Analyzer 示例
假设要建立一个英文文本搜索的 Collection,并在插入数据时自动完成分词和预处理。这里选用内置的 English Analyzer(相当于standard + lowercase + stop + stemmer的组合)。
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="http://localhost:19530",)
schema = client.create_schema()
schema.add_field(
field_name="id", # Field name
datatype=DataType.INT64, # Integer data type
is_primary=True, # Designate as primary key
auto_id=True # Auto-generate IDs (recommended)
)
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=1000,
enable_analyzer=True,
analyzer_params={
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stop", # Specifies the filter type as stop
"stop_words": ["of","to","_english_"], # Defines custom stop words and includes the English stop word list
},
{
"type": "stemmer", # Specifies the filter type as stemmer
"language": "english"
}],
},
enable_match=True,
)
schema.add_field(
field_name="sparse", # Field name
datatype=DataType.SPARSE_FLOAT_VECTOR # Sparse vector data type
)
bm25_function = Function(
name="text_to_vector", # Descriptive function name
function_type=FunctionType.BM25, # Use BM25 algorithm
input_field_names=["text"], # Process text from this field
output_field_names=["sparse"] # Store vectors in this field
)
schema.add_function(bm25_function)
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse", # Field to index (our vector field)
index_type="AUTOINDEX", # Let Milvus choose optimal index type
metric_type="BM25"
# Must be BM25 for this feature
)
COLLECTION_NAME = "english_demo"
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME)
print(f"Dropped existing collection: {COLLECTION_NAME}")
client.create_collection(
collection_name=COLLECTION_NAME, # Collection name
schema=schema, # Our schema
index_params=index_params # Our search index configuration
)
print(f"成功创建集合: {COLLECTION_NAME}")
# 准备示例数据
sample_texts = [
"The quick brown fox jumps over the lazy dog",
"Machine learning algorithms are revolutionizing artificial intelligence",
"Python programming language is widely used for data science projects",
"Natural language processing helps computers understand human languages",
"Deep learning models require large amounts of training data",
"Search engines use complex algorithms to rank web pages",
"Text analysis and information retrieval are important NLP tasks",
"Vector databases enable efficient similarity searches",
"Stemming reduces words to their root forms for better searching",
"Stop words like 'the', 'and', 'of' are often filtered out"]
# 插入数据
print("
正在插入数据...")
data = [{"text": text} for text in sample_texts]
client.insert(
collection_name=COLLECTION_NAME,
data=data)
print(f"成功插入 {len(sample_texts)} 条数据")
# 演示分词器效果
print("
" + "="*60)
print("分词器分析演示")
print("="*60)
test_text = "The running dogs are jumping over the lazy cats"
print(f"
原始文本: '{test_text}'")
# 使用 run_analyzer 展示分词结果
analyzer_result = client.run_analyzer(
texts=test_text,
collection_name=COLLECTION_NAME,
field_name="text")
print(f"分词结果: {analyzer_result}")
print("
分析说明:")
print("- lowercase: 将所有字母转换为小写")
print("- stop words: 过滤掉停用词 ['of', 'to'] 和英语常见停用词")
print("- stemmer: 将词汇还原为词干形式 (running -> run, jumping -> jump)")
# 全文检索演示
print("
" + "="*60)
print("全文检索演示")
print("="*60)
# 等待数据索引完成
import time
time.sleep(2)
# 搜索查询示例
search_queries = [
"jump", # 测试词干匹配 (应该匹配 "jumps")
"algorithm", # 测试精确匹配
"python program", # 测试多词查询
"learn"
# 测试词干匹配 (应该匹配 "learning")
]
for i, query in enumerate(search_queries, 1):
print(f"
查询 {i}: '{query}'")
print("-" * 40)
# 执行全文检索
search_results = client.search(
collection_name=COLLECTION_NAME,
data=[query], # 查询文本
search_params={"metric_type": "BM25"},
output_fields=["text"], # 返回原始文本
limit=3
# 返回前3个结果
)
if search_results and len(search_results[0]) > 0:
for j, result in enumerate(search_results[0], 1):
score = result["distance"]
text = result["entity"]["text"]
print(f" 结果 {j} (相关度: {score:.4f}): {text}")
else:
print(" 未找到相关结果")
print("
" + "="*60)
print("检索完成!")
print("="*60)
(2) 多语言 Analyzer 示例
如果数据集中同时包含多种语言,例如英文、中文和日文,可以启用 Multi-language Analyzer。这样 Milvus 会根据文本语言自动选择合适的分词器。
from pymilvus import MilvusClient, DataType, Function, FunctionType
import time
# 配置连接
client = MilvusClient(
uri="http://localhost:19530",
)
COLLECTION_NAME = "multilingual_demo"
# 删除已存在的集合
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME)
# 创建schema
schema = client.create_schema()
# 添加主键字段
schema.add_field(
field_name="id",
datatype=DataType.INT64,
is_primary=True,
auto_id=True
)
# 添加语言标识字段
schema.add_field(
field_name="language",
datatype=DataType.VARCHAR,
max_length=50
)
# 添加文本字段,配置多语言分析器
multi_analyzer_params = {
"by_field": "language", # 根据language字段选择分析器
"analyzers": {
"en": {
"type": "english" # 英语分析器
},
"zh": {
"type": "chinese" # 中文分析器
},
"jp": {
"tokenizer": "icu", # 日语使用ICU分词器
"filter": [
"lowercase",
{
"type": "stop",
"stop_words": ["は","が","の","に","を","で","と"]
}
]
},
"default": {
"tokenizer": "icu" # 默认使用ICU通用分词器
}
},
"alias": {
"english": "en",
"chinese": "zh",
"japanese": "jp",
"中文": "zh",
"英文": "en",
"日文": "jp"
}
}
schema.add_field(
field_name="text",
datatype=DataType.VARCHAR,
max_length=2000,
enable_analyzer=True,
multi_analyzer_params=multi_analyzer_params
)
# 添加稀疏向量字段用于BM25
schema.add_field(
field_name="sparse_vector",
datatype=DataType.SPARSE_FLOAT_VECTOR
)
# 定义BM25函数
bm25_function = Function(
name="text_bm25",
function_type=FunctionType.BM25,
input_field_names=["text"],
output_field_names=["sparse_vector"]
)
schema.add_function(bm25_function)
# 准备索引参数
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse_vector",
index_type="AUTOINDEX",
metric_type="BM25"
)
# 创建集合
client.create_collection(
collection_name=COLLECTION_NAME,
schema=schema,
index_params=index_params
)
# 准备多语言测试数据
multilingual_data = [
# 英文数据
{"language": "en","text": "Artificial intelligence is revolutionizing technology industries worldwide"},
{"language": "en","text": "Machine learning algorithms process large datasets efficiently"},
{"language": "en","text": "Vector databases provide fast similarity search capabilities"},
# 中文数据
{"language": "zh","text": "人工智能正在改变世界各行各业"},
{"language": "zh","text": "机器学习算法能够高效处理大规模数据集"},
{"language": "zh","text": "向量数据库提供快速的相似性搜索功能"},
# 日文数据
{"language": "jp","text": "人工知能は世界中の技術産業に革命をもたらしています"},
{"language": "jp","text": "機械学習アルゴリズムは大量のデータセットを効率的に処理します"},
{"language": "jp","text": "ベクトルデータベースは高速な類似性検索機能を提供します"},
]
client.insert(
collection_name=COLLECTION_NAME,
data=multilingual_data
)
# 等待BM25函数生成向量
print("等待BM25向量生成...")
client.flush(COLLECTION_NAME)
time.sleep(5)
client.load_collection(COLLECTION_NAME)
# 演示分词器效果
print("
分词器分析:")
test_texts = {
"en":"The running algorithms are processing data efficiently",
"zh":"这些运行中的算法正在高效地处理数据",
"jp":"これらの実行中のアルゴリズムは効率的にデータを処理しています"
}
for lang, text in test_texts.items():
print(f"{lang}: {text}")
try:
analyzer_result = client.run_analyzer(
texts=text,
collection_name=COLLECTION_NAME,
field_name="text",
analyzer_names=[lang]
)
print(f" → {analyzer_result}")
except Exception as e:
print(f" → 分析失败: {e}")
# 多语言检索演示
print("
检索测试:")
search_cases = [
("zh","人工智能"),
("jp","機械学習"),
("en","algorithm"),
]
for lang, query in search_cases:
print(f"
{lang} '{query}':")
try:
search_results = client.search(
collection_name=COLLECTION_NAME,
data=[query],
search_params={"metric_type": "BM25"},
output_fields=["language","text"],
limit=3,
filter=f'language == "{lang}"'
)
if search_results and len(search_results[0]) > 0:
for result in search_results[0]:
score = result["distance"]
text = result["entity"]["text"]
print(f" {score:.3f}: {text}")
else:
print(" 无结果")
except Exception as e:
print(f" 错误: {e}")
print("
完成")
此外,Milvus 目前也支持使用 language_identifier 分词器进行搜索,其优势在于无需手动告知系统文本语言,Milvus 会自动识别。相应地,语言字段(language)也并非必需。社区之前的官宣:Milvus 2.6引入多语言分析器,全文搜索再升级,助力业务全球化博客中已对此做了详细介绍,这里不再赘述。




