

在计算机视觉领域,RF-DETR——Roboflow推出的全新实时目标检测模型——无疑已成为业界关注的焦点。凭借其卓越的性能,它迅速攀升至最先进(SOTA)模型的行列。然而,要真正理解其内在运作机制并领略其精妙之处,仅仅审视性能指标是远远不够的,深入探究其架构基因才是关键所在。
RF-DETR并非凭空出现的全新发明;其诞生背后是一个引人入胜的故事,讲述了如何循序渐进地解决问题,从初代DETR的根本性局限出发,最终发展成为一个轻量级、实时的Transformer模型。接下来,将追溯这一演进历程。
检测管道的范式转变
2020年,DETR(DEtection TRansformer)[1]横空出世,这款模型彻底改变了目标检测的传统流程。作为首个真正的端到端检测器,它成功摒弃了锚框生成和非极大值抑制(NMS)等手工设计的组件,实现了检测流程的极大简化。DETR通过将CNN骨干网络与Transformer编码器-解码器架构相结合来达成这一壮举。然而,尽管其设计具有革命性意义,初代DETR仍然面临诸多显著问题:
- 收敛速度极慢: DETR需要大量的训练周期才能收敛,其训练速度比Faster R-CNN等模型慢10到20倍,这在实际应用中带来了巨大的时间成本。
- 计算复杂度过高: Transformer编码器中的注意力机制,在处理特征图的空间维度(H, W)时,其复杂度高达O(H²W²C)。这种二次方复杂度使得处理高分辨率特征图变得异常昂贵,难以承受。
- 小目标检测性能不佳: 作为高计算复杂度的直接后果,DETR无法有效利用高分辨率特征图,而这些特征图对于精确检测小尺寸目标至关重要。
这些问题的根源,皆在于Transformer注意力机制处理图像特征的方式:它需要关注特征图中的每一个像素,这不仅效率低下,也极大地增加了训练的难度。
突破性进展:可变形DETR
为了解决DETR面临的难题,研究人员回溯并从可变形卷积网络[2]中汲取了灵感。多年来,卷积神经网络(CNN)一直主导着计算机视觉领域。然而,它们也存在一个固有的局限性:难以有效建模几何变换。这主要是因为CNN的核心构建模块,如卷积层和池化层,都具有固定的几何结构。正是在这样的背景下,可变形CNN应运而生。其核心思想简洁而巧妙:如果CNN中的采样网格不再是固定的,那会怎样?
- 全新的模块,即可变形卷积,通过引入2D偏移量来增强标准的网格采样位置。
- 至关重要的是,这些偏移量并非固定不变;它们是通过额外的卷积层,从前一个特征图中学习得到的。
- 这种机制使得采样网格能够动态地变形,以局部、密集的方式适应目标对象的形状和尺度。
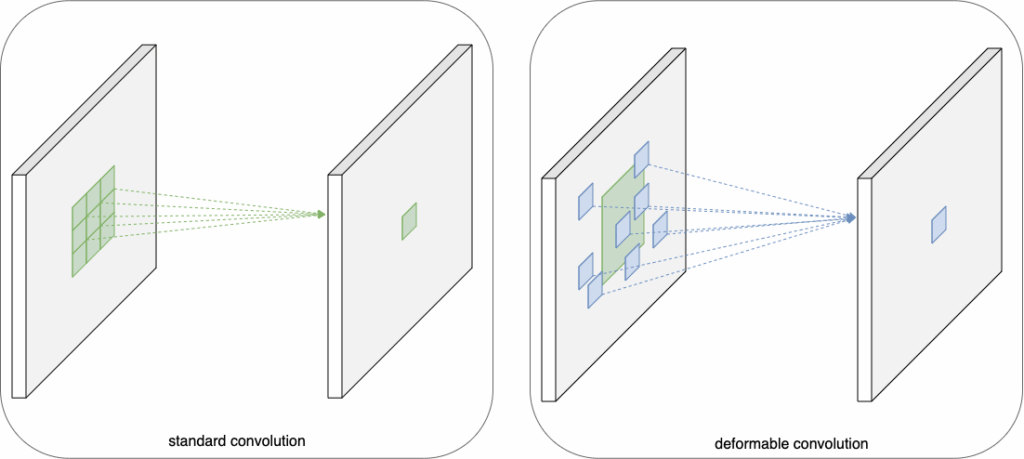
可变形卷积中这种自适应采样的理念,被巧妙地应用于Transformer的注意力机制。其成果便是可变形DETR[3]。
其中的核心创新是可变形注意力模块。该模块并没有像传统方式那样,对特征图中的所有像素计算注意力权重,而是采取了一种更为智能的策略:
- 它仅关注参考点周围一小组固定的关键采样点。
- 与可变形卷积类似,这些采样点的2D偏移量是通过线性投影,从查询元素本身学习而来的。
- 由于其注意力机制内置了直接处理和融合多尺度特征的能力,因此无需单独的特征金字塔网络(FPN)架构。
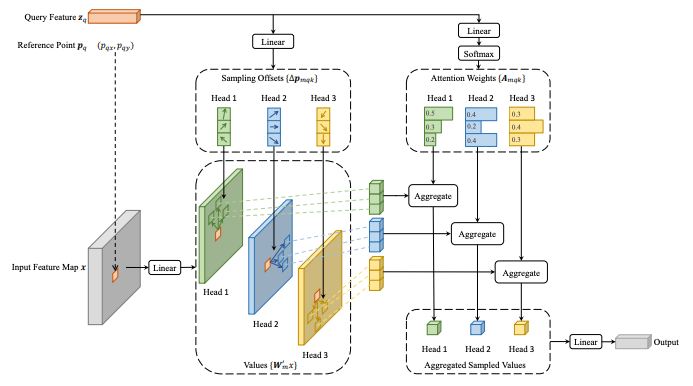
可变形注意力模块的插图,摘自参考文献[3]
可变形注意力的突破在于,它“仅关注参考点周围一小组关键采样点”[3],而与特征图的空间尺寸无关。该论文的分析表明,当这一新模块应用于编码器(其中查询数量Nq等于空间尺寸HW)时,其计算复杂度降至O(HWC²),与空间尺寸呈线性关系。这一关键性改变使得处理高分辨率特征图在计算上成为可能,从而显著提升了模型在检测小目标上的性能。
实现实时性:LW-DETR
可变形DETR虽然解决了收敛速度和准确性的问题,但若要与YOLO等模型在实时性上竞争,它还需要进一步提速。正是在这样的背景下,LW-DETR(轻量级DETR)[4]应运而生。其目标是构建一个基于Transformer的架构,能够在实时目标检测领域超越YOLO模型。LW-DETR的架构堆栈相对简洁:一个Vision Transformer (ViT) 编码器、一个投影器以及一个浅层DETR解码器。该模型摒弃了DETR框架中的编码器-解码器架构,仅保留了解码器部分,这一点可以从这段代码中清晰可见。
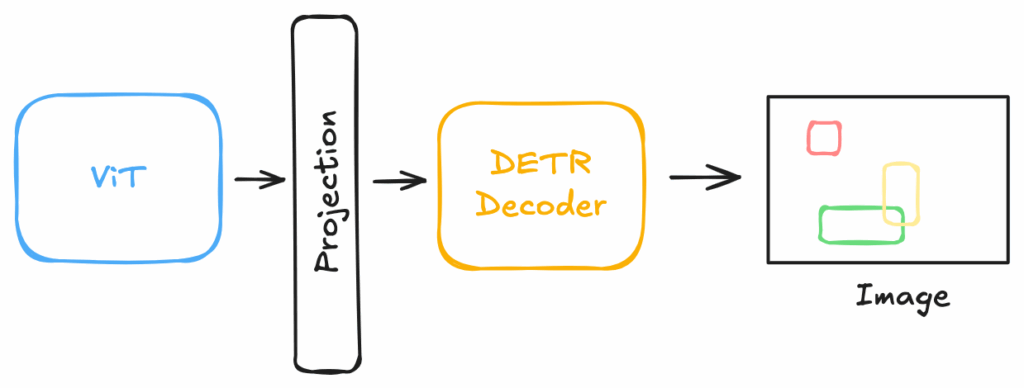
为了实现其卓越的速度,LW-DETR融合了多项关键的效率提升技术:
- 可变形交叉注意力: 解码器直接沿用了可变形DETR中高效的可变形注意力机制,这对模型性能至关重要。
- 交错的窗口注意力与全局注意力: Vision Transformer (ViT) 编码器通常计算成本较高。为了降低其复杂度,LW-DETR用成本更低的窗口自注意力层替换了部分昂贵的全局自注意力层。
- 更浅的解码器: 标准的DETR变体通常采用6个解码器层。而LW-DETR仅使用3层,这显著降低了模型的推理延迟。
LW-DETR中的投影器扮演着关键的桥梁角色,将Vision Transformer (ViT) 编码器与DETR解码器紧密连接起来。该投影器采用C2f模块构建,这是一个在YOLOv8模型中广为使用的、高效的卷积模块。此模块负责处理特征并将其准备好,以便供解码器的交叉注意力机制使用。通过将可变形注意力的强大能力与这些轻量级的设计选择相结合,LW-DETR证明了DETR风格的模型完全可以成为性能卓越的实时检测器。
RF-DETR的组件整合
至此,便回到了RF-DETR [5] 的讨论。它并非一个孤立的突破,而是这一演进链条中合乎逻辑的下一步。具体而言,RF-DETR的创建者通过将LW-DETR与预训练的DINOv2骨干网络相结合,从而构建了该模型,这一点可以从这段代码中得以印证。这种结合赋予了模型卓越的新领域适应能力,这得益于预训练DINOv2骨干网络中存储的丰富知识。DINOv2之所以具有如此非凡的适应性,是因为它是一个自监督模型。与传统上使用固定标签在ImageNet上训练的骨干网络不同,DINOv2是在一个庞大且未经人工标注的数据集上进行训练的。它通过解决一种“拼图游戏”式的任务进行学习,从而被迫形成了对纹理、形状和物体部件极其丰富且通用的理解。当RF-DETR采用DINOv2作为骨干网络时,它获得的不仅仅是一个特征提取器;而是一个能够以惊人效率针对特定任务进行微调的深层视觉知识库。
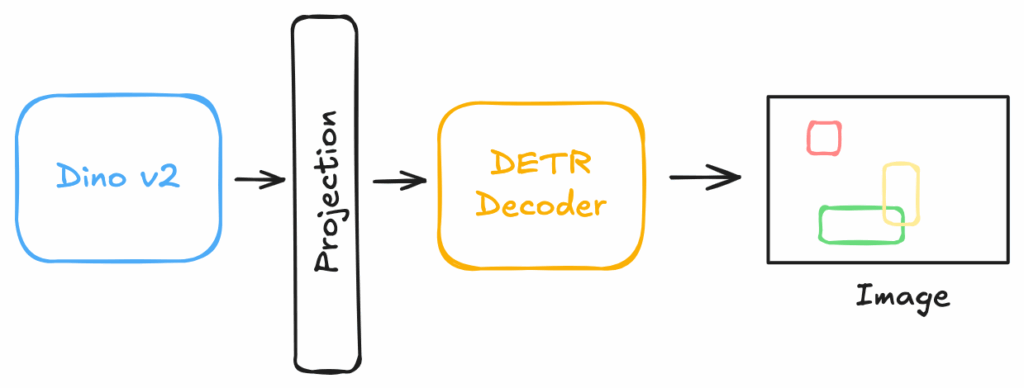
与之前的模型相比,一个关键的区别在于,可变形DETR采用了多尺度自注意力机制,而RF-DETR模型则从单尺度骨干网络中提取图像特征图。近期,RF-DETR模型背后的团队进一步集成了分割头,使其除了提供边界框外,还能生成分割掩码,这使得它也成为分割任务的理想选择。读者可以查阅其官方文档,以便开始使用、微调或将其导出为ONNX格式。
结论
初代DETR通过移除NMS等手工设计组件,彻底革新了目标检测的管道,但由于收敛缓慢和二次方复杂度而变得不切实际。可变形DETR提供了关键的架构突破,用受可变形卷积启发的、高效自适应的采样机制取代了全局注意力。随后,LW-DETR证明了这种高效架构可以封装以实现实时性能,从而挑战了YOLO的主导地位。RF-DETR则代表着逻辑上的下一步:它将这种高度优化、可变形的架构与现代自监督骨干网络的强大能力相结合。
参考文献
[1] End-to-End Object Detection with Transformers. Nicolas Carion 等人,2020年。
[2] Deformable Convolutional Networks. Jifeng Dai 等人,2017年。
[3] Deformable DETR: Deformable Transformers for End-to-End Object Detection. Xizhou Zhu 等人,2020年。
[4] LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection. Qiang Chen 等人,2024年。





