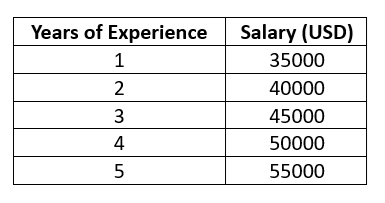在利用检索增强生成(RAG)方法回答数据问题时,是图数据库更具优势,还是传统SQL数据库表现更佳?本文将深入探讨这一问题。通过在图数据库和SQL数据库中存储相同的数据集,并结合多种大型语言模型(LLMs)进行提问,研究旨在评估哪种数据库范式能够提供更准确、更具洞察力的结果。
检索增强生成(RAG)是一种先进的AI框架,它通过允许大型语言模型(LLMs)在生成答案之前检索相关的外部信息,从而显著提升了模型的性能。RAG不再仅仅依赖模型预训练时所学到的知识,而是能够动态地查询一个知识来源(在本次研究中,这个知识来源是SQL或图数据库),并将检索到的结果整合到其响应中。关于RAG的详细介绍,读者可以参考此处。
SQL数据库将数据组织成由行和列组成的表。每行代表一个记录,每列代表一个属性。表之间的关系通过键和连接(joins)来定义,所有数据都遵循固定的模式(schema)。SQL数据库非常适合处理结构化、事务性数据,尤其是在数据一致性和精确性至关重要的场景中,例如金融交易、库存管理或患者记录。
图数据库将数据存储为节点(实体)和边(关系),两者都可以附带可选的属性。与SQL数据库通过连接表来建立关系不同,图数据库直接表示这些关系,从而实现对互联数据的快速遍历。图数据库特别适用于建模网络和复杂关系,例如社交图谱、知识图谱或分子相互作用图,在这些场景中,连接的重要性不亚于实体本身。
数据来源
本次用于比较RAG性能的数据集涵盖了1950年至2024年的F1赛车比赛结果。该数据集详细记录了车手和制造商(车队)在排位赛、冲刺赛、正赛中的表现,甚至包括单圈时间和进站时间。此外,每场比赛后车手和制造商的锦标赛积分榜排名也被包含在内。
SQL 数据库模式
该数据集已预先以带有键的表格形式进行结构化,因此可以轻松地构建一个SQL数据库。数据库的模式图如下所示:
SQL数据库设计
在SQL数据库设计中,Races(比赛)是核心表,它与其他各种结果表以及赛季、赛道等附加信息相连接。结果表进一步与Drivers(车手)和Constructors(制造商)表关联,以记录他们在每场比赛中的成绩。每场比赛后的锦标赛积分榜排名则分别存储在Driver_standings(车手积分榜)和Constructor_standings(制造商积分榜)表中。
图数据库模式
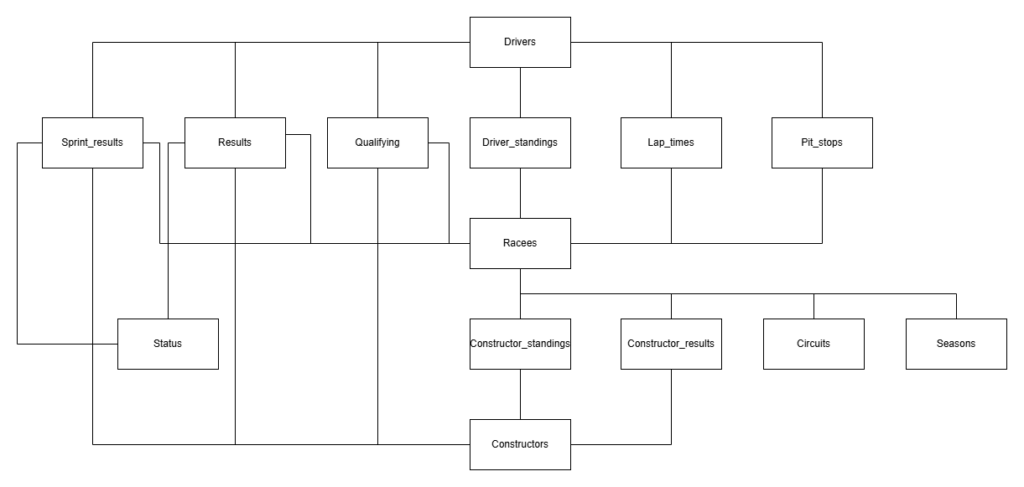
图数据库的模式图如下所示:
图数据库设计
由于图数据库能够将信息存储在节点和关系中,因此它仅需要六个节点,而SQL数据库则需要14个表。其中,Car(赛车)节点作为一个中间节点,用于建模车手在特定比赛中驾驶某个制造商赛车的情况。鉴于车手与制造商的搭配会随时间变化,这种关系需要针对每场比赛进行定义。比赛结果则存储在关系中,例如Car和Race之间的:RACED关系。而:STOOD_AFTER关系则包含了每场比赛后车手和制造商的锦标赛积分榜排名。
数据库查询实践
为了实现对数据库的查询,研究人员利用LangChain为两种数据库类型构建了检索增强生成(RAG)链。该链能够根据用户的提问自动生成查询语句,执行查询,并将查询结果转化为用户可理解的答案。相关代码已发布在此仓库中。实验中,定义了一个通用的系统提示,该提示适用于生成任何SQL或图数据库的查询。唯一的数据特定信息通过将自动生成的数据库模式(schema)插入到提示中来实现。系统提示的详细内容可在此处查阅。
以下是一个初始化模型链并提出问题“1992年比利时大奖赛的冠军车手是谁?”的示例:
from langchain_community.utilities import SQLDatabase
from langchain_openai import ChatOpenAI
from qa_chain import GraphQAChain
from config import DATABASE_PATH
# connect to database
connection_string = f"sqlite:///{DATABASE_PATH}"
db = SQLDatabase.from_uri(connection_string)
# initialize LLM
llm = ChatOpenAI(temperature=0, model="gpt-5")
# initialize qa chain
chain = GraphQAChain(llm, db, db_type='SQL', verbose=True)
# ask a question
chain.invoke("What driver won the 92 Grand Prix in Belgium?")
运行结果如下:
{'write_query': {'query': "SELECT d.forename, d.surname
FROM results r
JOIN races ra ON ra.raceId = r.raceId
JOIN drivers d ON d.driverId = r.driverId
WHERE ra.year = 1992
AND ra.name = 'Belgian Grand Prix'
AND r.positionOrder = 1
LIMIT 10;"}}
{'execute_query': {'result': "[('Michael', 'Schumacher')]"}}
{'generate_answer': {'answer': 'Michael Schumacher'}}
此SQL查询通过连接Results(结果)、Races(比赛)和Drivers(车手)表,筛选出1992年比利时大奖赛并找出第一名的车手。值得注意的是,LLM将年份“92”转换为“1992”,并将比赛名称从“Grand Prix in Belgium”转换为“Belgian Grand Prix”。这些转换是通过分析数据库模式中包含的每表三行示例数据推断出来的。最终查询结果为“Michael Schumacher”,LLM将其作为答案返回。
评估结果
本研究的核心问题在于评估LLM在查询SQL数据库和图数据库时的表现优劣。为此,定义了三个难度级别的问题:简单、中等和困难。简单问题仅需查询单个表或节点的数据即可回答;中等问题需要一到两个表或节点之间的连接;而困难问题则涉及更多连接或子查询。每个难度级别均设置了五个问题。此外,还特别定义了五个无法通过数据库数据回答的问题,以测试LLM的边界识别能力。
为了探究最先进的模型是否必需,或者较旧且成本较低的模型能否也产生令人满意的结果,每个问题都由三个LLM模型(GPT-5、GPT-4和GPT-3.5-turbo)进行回答。评分标准如下:如果模型给出正确答案,得1分;如果模型回答无法回答该问题,得0分;如果给出错误答案,则扣1分。所有问题及对应的答案均可在此处查阅。以下是所有模型和数据库类型的得分情况:
ModelGraph DBSQL DB
GPT-3.5-turbo-2 4
GPT-4 7 9
GPT-5 18 18
模型-数据库评估得分
更先进的模型显著优于较简单的模型,这一现象值得关注:GPT-3.5-turbo回答错误的问题数量约占一半,GPT-4回答错误2到3个问题,并且有6到7个问题无法回答,而GPT-5则几乎所有问题都回答正确,仅有一个例外。对于较简单的模型而言,它们似乎在SQL数据库上的表现优于图数据库,而GPT-5在两种数据库上均取得了相同的高分。
使用SQL数据库时,GPT-5唯一答错的问题是“哪位车手赢得的世界冠军头衔最多?”。其答案“刘易斯·汉密尔顿,获得7次世界冠军”并不完全正确,因为刘易斯·汉密尔顿和迈克尔·舒马赫都赢得了7次世界冠军。生成的SQL查询聚合了每位车手的冠军次数,按降序排列并仅选择了第一行,而实际上第二行的车手拥有相同的冠军次数。
在使用图数据库时,GPT-5唯一答错的问题是“谁赢得了2017年的F2锦标赛?”它回答为“刘易斯·汉密尔顿”(刘易斯·汉密尔顿当年赢得了F1锦标赛,但并非F2)。这是一个具有迷惑性的问题,因为数据库仅包含F1而非F2的比赛结果。预期的正确答案应是表明根据现有数据无法回答此问题。然而,考虑到系统提示中并未包含有关数据集的任何具体信息,模型未能正确回答此问题也是情有可原的。
有趣的是,在使用SQL数据库时,GPT-5却给出了“查尔斯·勒克莱尔”这个正确答案。生成的SQL查询仅在车手表中搜索了“查尔斯·勒克莱尔”的名字。这表明LLM可能已经识别出数据库中不包含F2比赛结果,并利用其通用知识回答了这个问题。尽管在此案例中这导致了正确答案,但当LLM不完全依赖提供的数据来回答问题时,这种行为可能带来风险。为了降低这种风险,可以在系统提示中明确指出数据库必须是回答问题的唯一来源。
总结
通过使用F1比赛结果数据集对RAG性能进行的本次比较研究表明,最新的大型语言模型(LLMs)表现卓越,无需额外的提示工程即可生成高度准确且上下文感知的答案。尽管较简单的模型在处理复杂查询时表现挣扎,但像GPT-5这样的新一代模型能够以近乎完美的精度处理这些查询。值得注意的是,图数据库和SQL数据库方法在性能上没有显著差异——这意味着用户可以简单地选择最适合其数据结构的数据库范式。
本研究中使用的数据集仅作为说明性示例;在处理其他数据集时,特别是那些需要专业领域知识或访问非公开数据源的数据集时,结果可能会有所不同。总的来说,这些发现强调了检索增强型LLMs在将结构化数据与自然语言推理相结合方面所取得的巨大进步。