

随着大模型的普及,越来越多的企业希望借助 AI 提升工作效率——从智能对话、文档分析到知识问答与研发辅助,AI 正在重塑企业的工作方式。但在实际落地中,数据安全与隐私合规始终是绕不过的问题。为确保企业核心数据不外流、私有化模型稳定可控,本地私有化部署逐渐成为企业首选方案,而 CherryStudio 与 GPUStack 的结合,正是这一需求的理想实现。
CherryStudio 作为交互界面,为企业员工提供便捷的操作入口和知识管理能力,让用户能够轻松调用内部模型、查询知识库,以及生成文档和辅助决策,提升业务流程的智能化水平与工作效率。
而GPUStack是整套系统的算力与模型管理中枢。它为企业提供统一的模型部署、调度与监控能力,支持多模型的单机/多机运行与自动资源分配,确保推理过程高效稳定。同时,GPUStack 还具备认证授权、负载均衡、故障恢复与指标观测功能,让企业在本地掌控模型生命周期,实现对 AI 服务的统一管理与合规运行。

CherryStudio:多模型桌面客户端
CherryStudio 是跨平台(Windows、macOS、Linux)的桌面 AI 客户端,支持连接多种 LLM 服务:
- 主流云服务:OpenAI、Gemini、Anthropic、Claude、Perplexity 等
- 本地模型:Ollama、LM Studio、以及 GPUStack
- 内置 300+ 智能助手模板,支持自定义角色与多模型对话
- 支持文档、PDF、代码、Markdown 等多种格式,并提供多模态图像识别
- 集成 WebDAV、图表、翻译、知识库等工具
作为 AI 生产力中心,适用于办公、编程、学习与创作等场景。
GPUStack:本地 AI 模型的算力中枢
如果将 CherryStudio 视为交互前端,GPUStack则是后端引擎。
GPUStack提供标准化 API,可与上层系统(如 CherryStudio、业务服务或自定义应用)无缝集成,实现模型即服务(Model-as-a-Service)的统一访问,让企业能够集中管理算力资源,快速上线或更新模型服务。
关键特性
-
多厂商 GPU 支持:NVIDIA、AMD、Apple Silicon、昇腾、海光、摩尔线程、天数智芯、寒武纪、沐曦 等
-
多类型模型:
- LLM(语言模型)
- VLM(视觉语言模型,支持图像识别)
- Embedding 与 Rerank 模型
- Image 模型(图像生成与编辑)
- TTS 模型(语音合成)
- ASR 模型(语音识别)
-
OpenAI API 兼容:可被任意兼容 OpenAI 接口的客户端直接连接(包括 CherryStudio)
-
一键部署模型:从模型仓库选择并启动,无需手动配置环境与依赖
-
内置 Playground:直观的交互测试界面
-
动态调度与监控:自动分配算力,实时查看 GPU 使用率、模型状态与 token 消耗
简而言之:GPUStack 将服务器构建为可管理的 AI 平台,适合企业私有化部署与模型统一管理。
实战:三步完成 CherryStudio 连接 GPUStack
步骤一:启动 GPUStack 服务
首先,参考 GPUStack 官方文档完成安装(https://docs.gpustack.ai/latest/installation/nvidia-cuda/online-installation/)。推荐容器化部署方式,在 NVIDIA GPU 服务器上,根据文档要求完成对应版本的 NVIDIA 驱动、Docker 和 NVIDIA Container Toolkit 安装后,通过 Docker 启动 GPUStack 服务。
docker run -d --name gpustack --restart=unless-stopped --gpus all --network=host --ipc=host -v gpustack-data:/var/lib/gpustack registry.cn-shanghai.aliyuncs.com/gpu-stack/gpustack:v0.7.1
启动完成后,在浏览器访问http://your_server_ip:
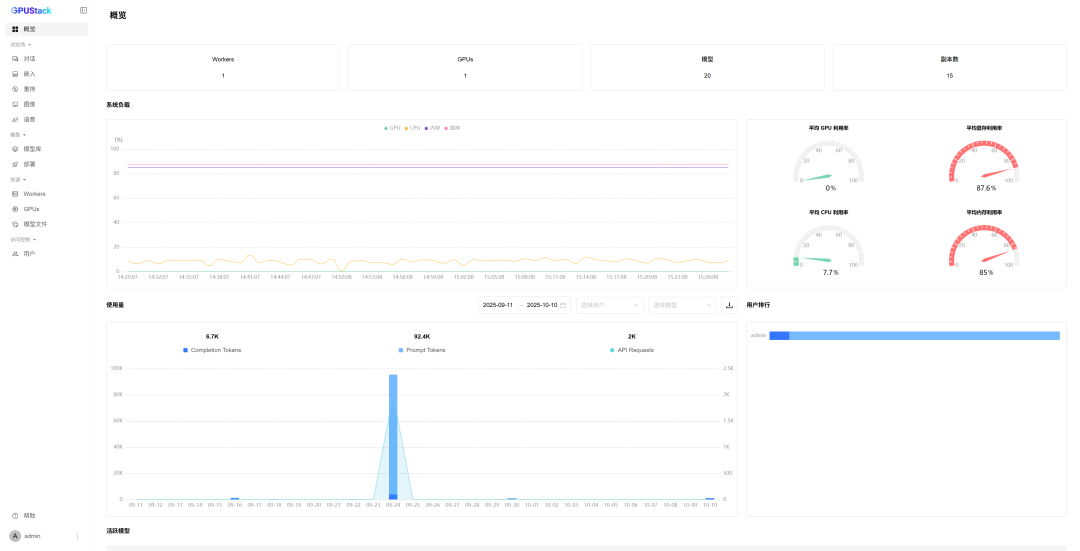
若your_server_ip为localhost或127.0.0.1,可直接进入管理界面。
管理员账号为admin,默认密码使用以下命令查看:
docker exec -it gpustack cat /var/lib/gpustack/initial_admin_password
更多设备与安装方式参考官方文档:https://docs.gpustack.ai/latest/overview/
步骤二:部署模型
- 打开 GPUStack 网页端「模型库」页面
- 选择要运行的模型(如
Qwen3)
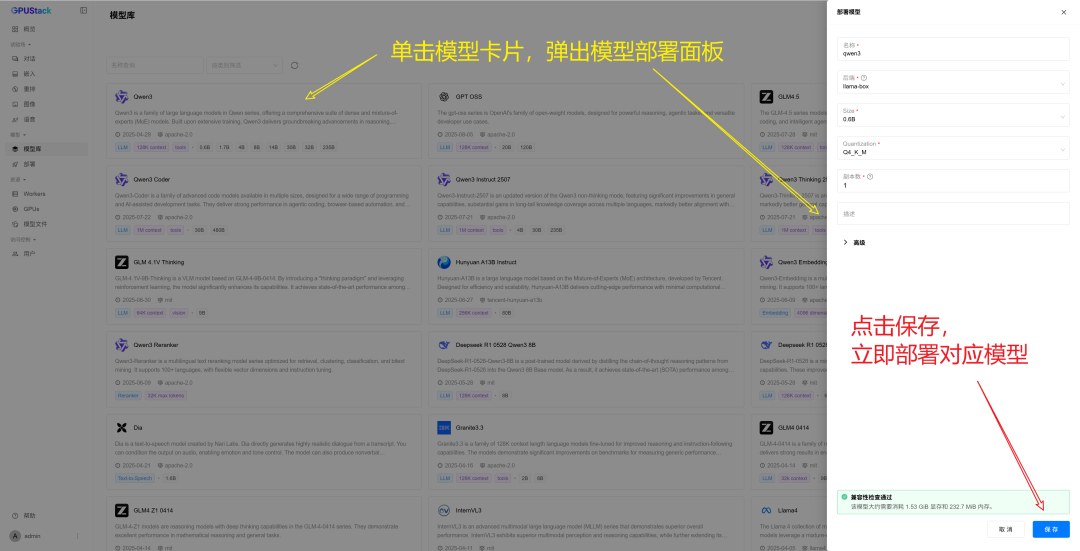
- 点击「保存」,转到「部署」页面,等待状态变为 Running
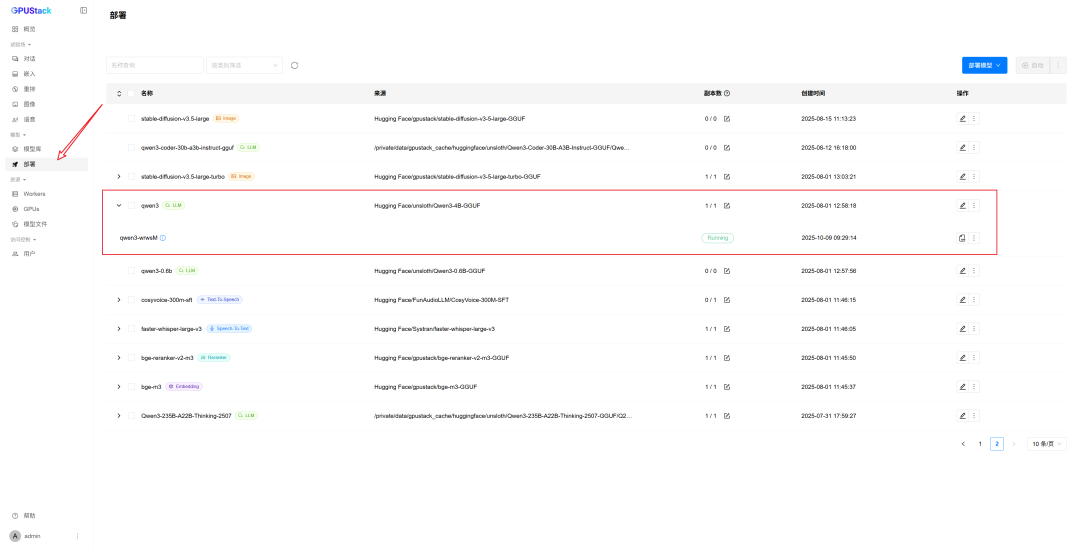
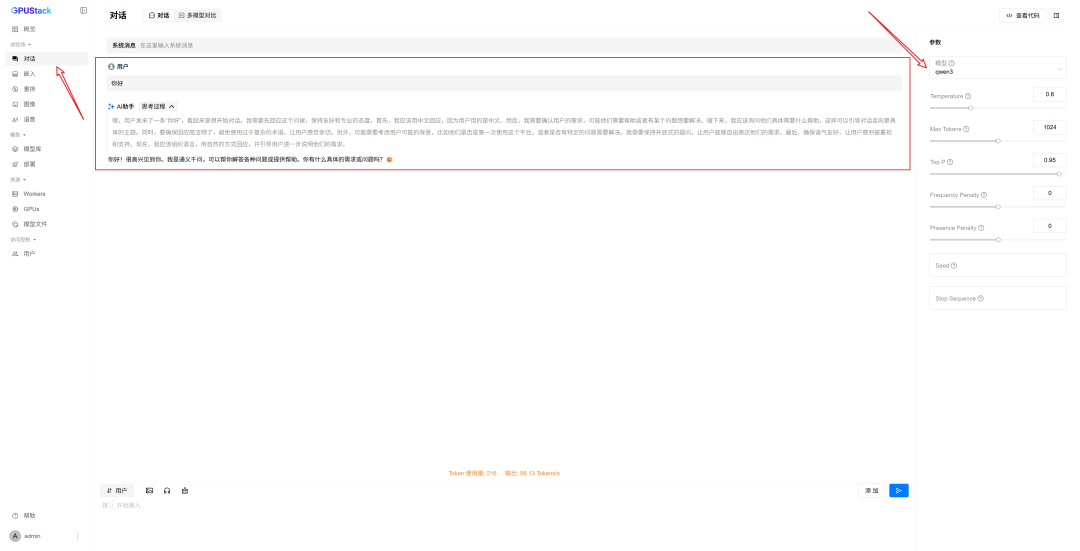
模型可用后,可在 GPUStack 的「Playground – Chat」直接测试:
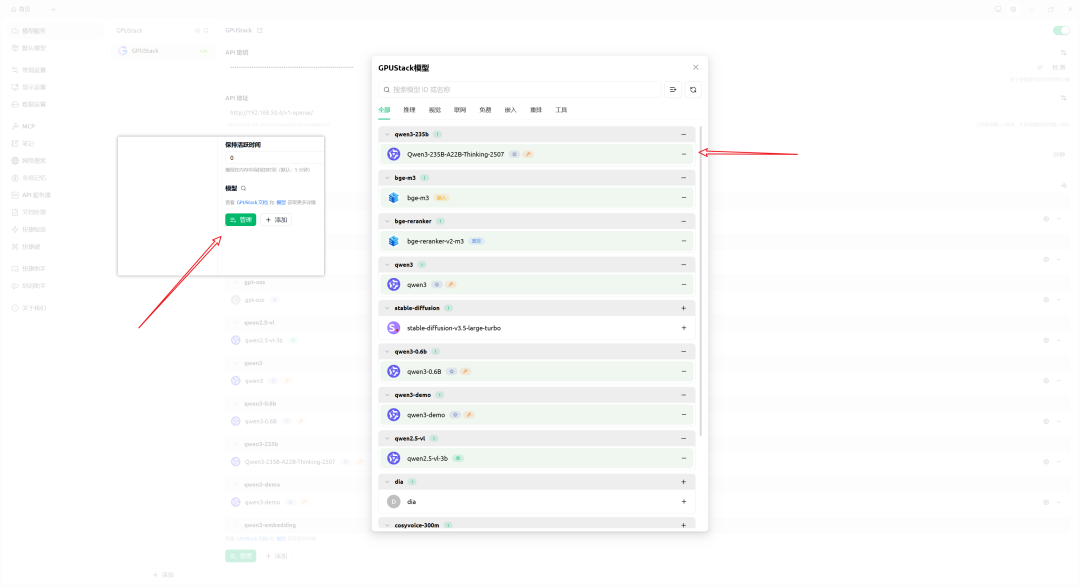
亦可按需部署更多模型(如下仅为演示):
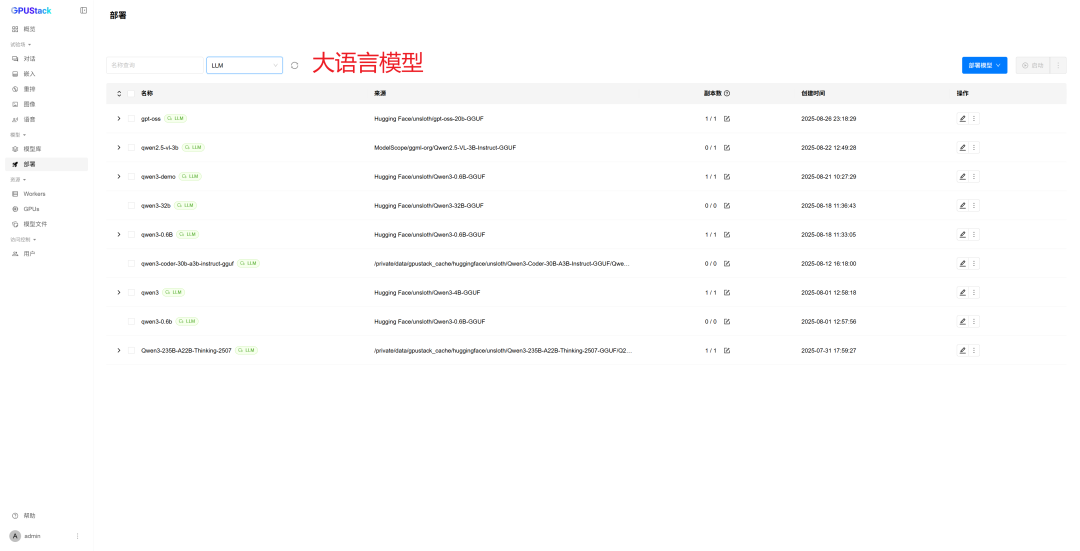
更多部署细节见 GPUStack 项目与文档:
- 项目地址:https://github.com/gpustack/gpustack
- 官方文档:https://docs.gpustack.ai/
显存不足或需添加多节点,请参考下图: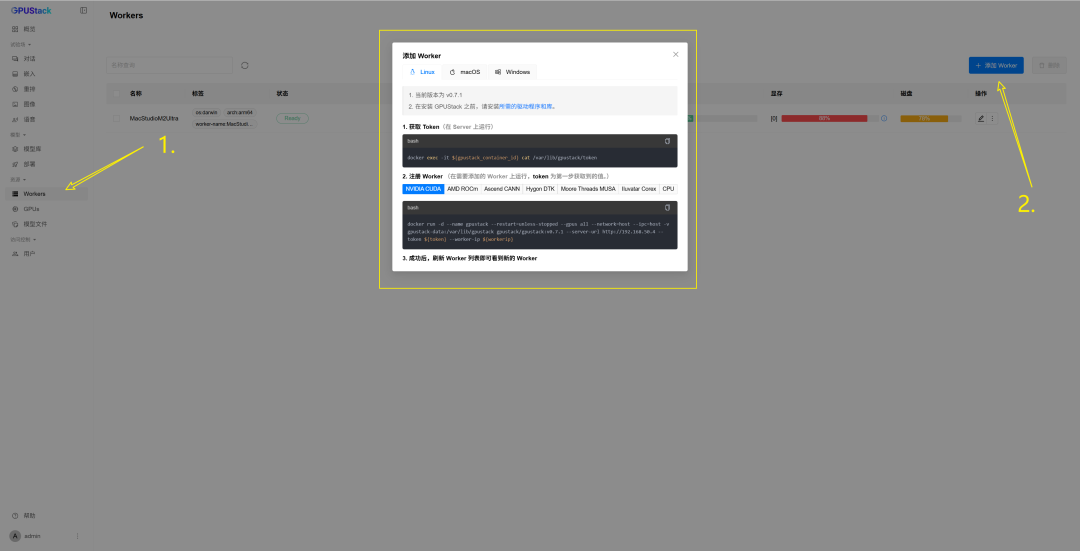
步骤三:连接 CherryStudio
如尚未安装 CherryStudio,请先访问官网安装:https://www.cherry-ai.com/
- 打开 CherryStudio,进入「设置」→「模型服务」,搜索 “GPUStack”
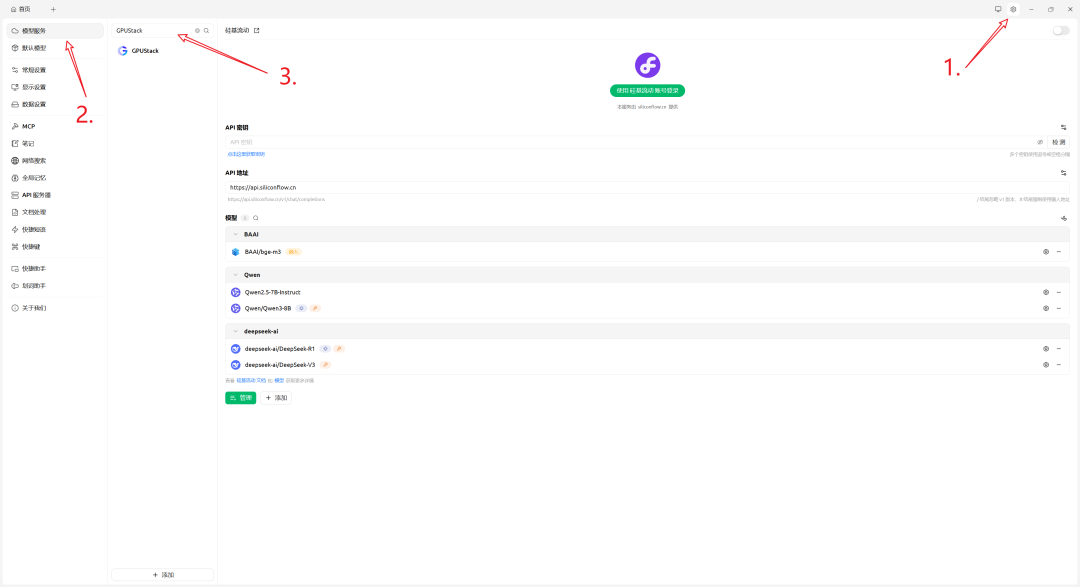
- 选择「GPUStack」,并启用(未启用将无法使用)
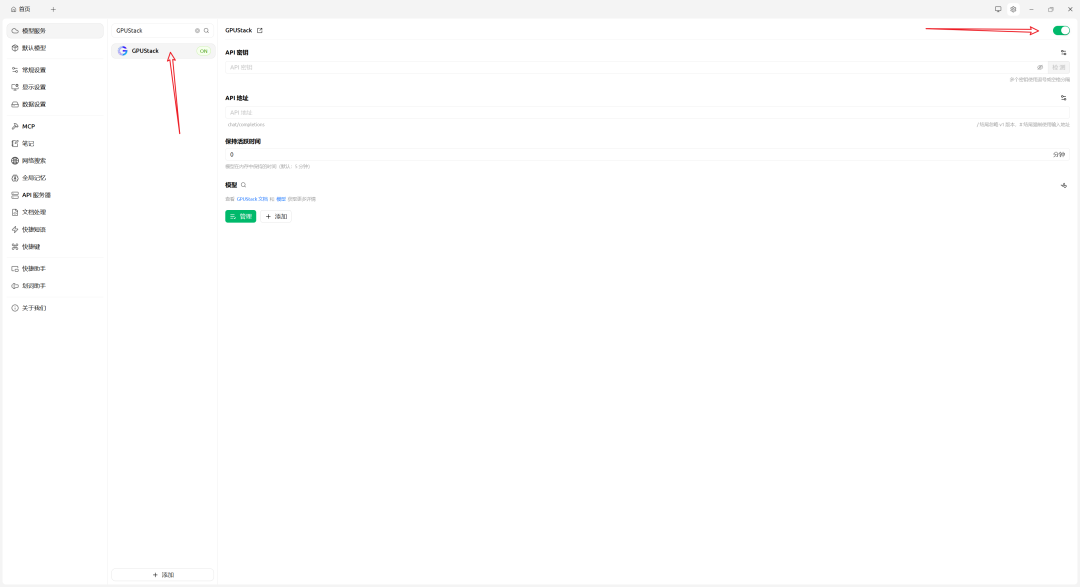
- 配置参数:
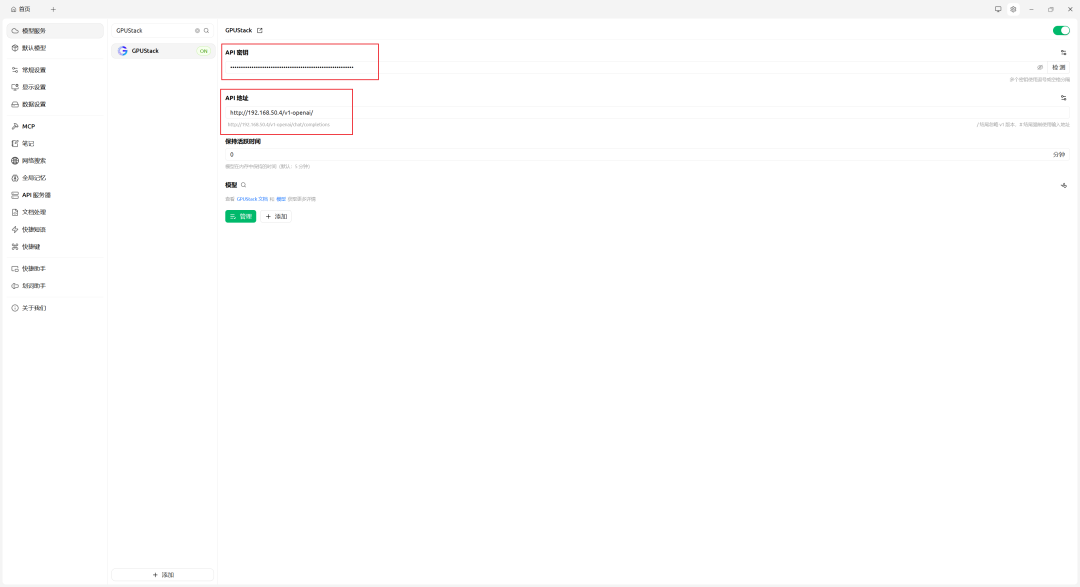
- 管理模型
- 测试连接
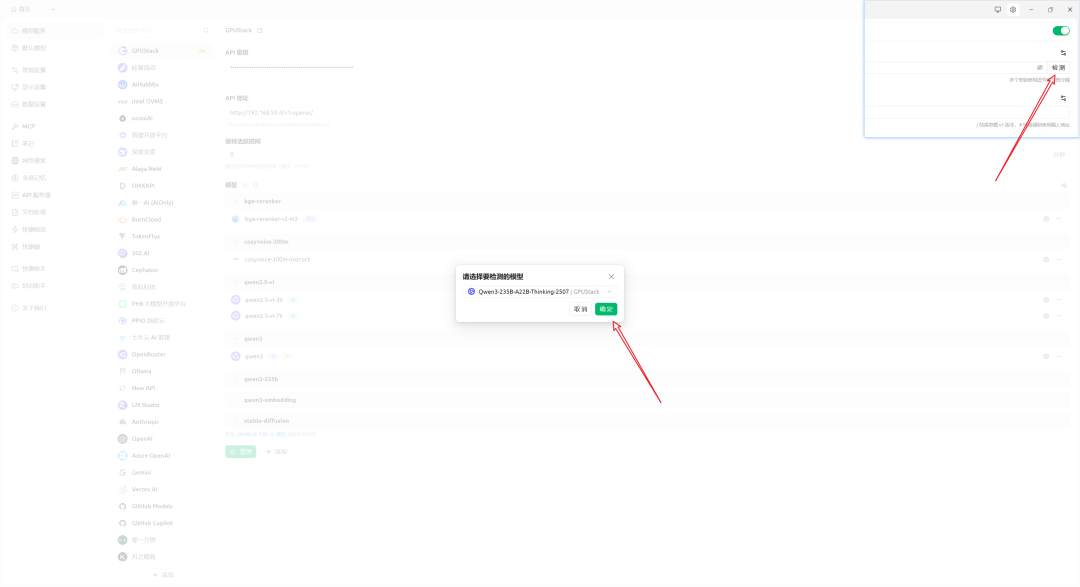
配置正确后,会显示“连接成功”。
- (可选)设置默认模型
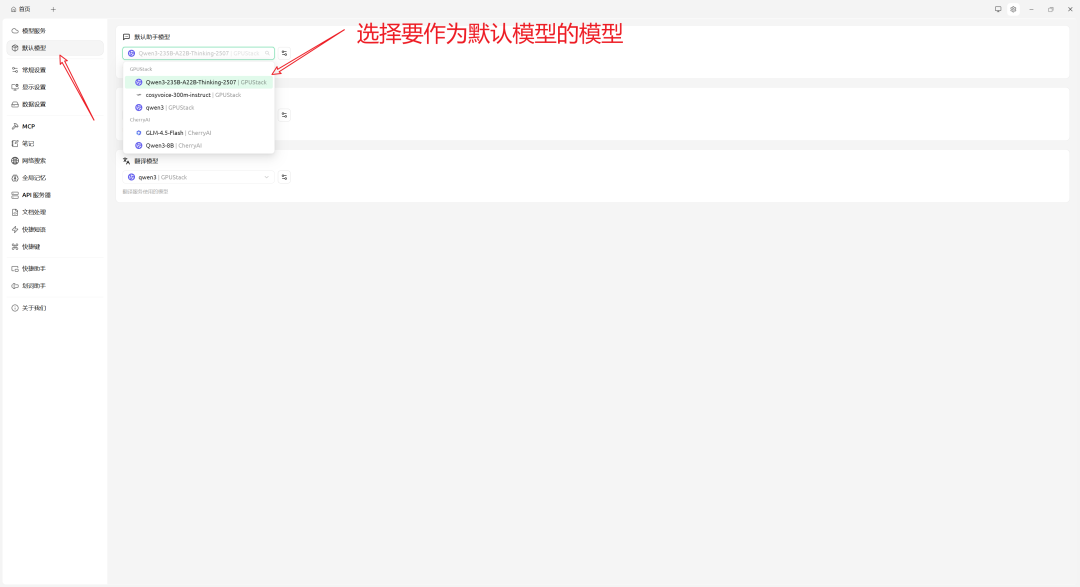
至此,CherryStudio 即可调用 GPUStack 上部署的模型,获得与 OpenAI 一致的使用体验,同时实现对数据与算力的完全掌控。
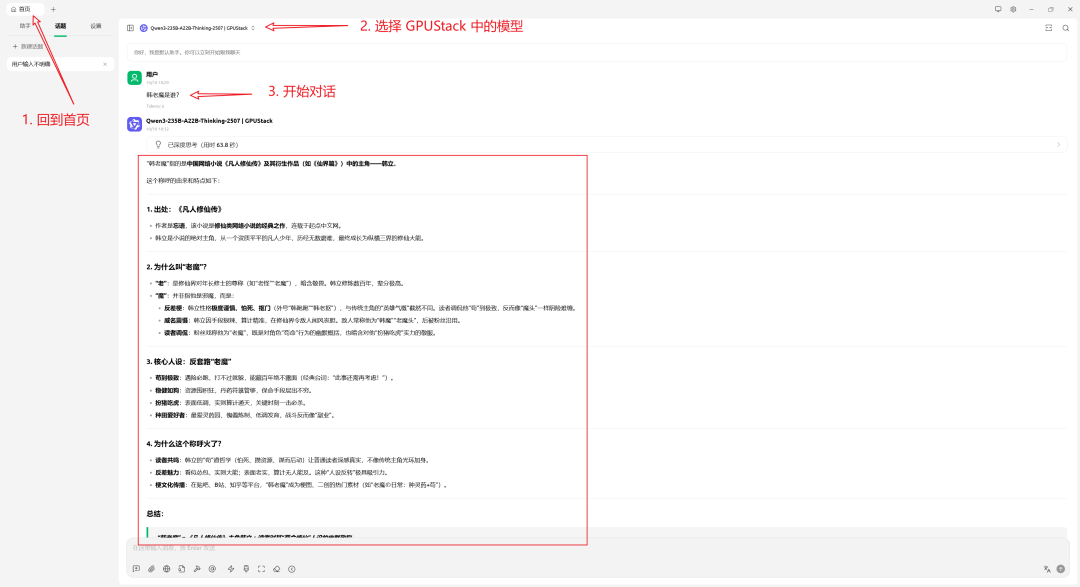
GPUStack 赋能:CherryStudio 的多模型能力
接入 GPUStack 后,可在 CherryStudio 中自由切换多类模型,覆盖更多应用场景:
| 模型类别 | 示例模型 | 主要功能 |
| — | — | — |
| 大语言模型 (LLM) | Qwen, Llama3, DeepSeek | 对话、写作、编程助手 |
| 视觉语言模型 (VLM) | LLaVA, Pixtral, Qwen-VL | 图文理解、图像识别 |
| 向量嵌入 | BGE | 向量检索、语义搜索 |
结合 CherryStudio 的多模态界面、知识库与插件体系,可构建功能完整的 AI 助手中心。
视觉语言模型(VLM)
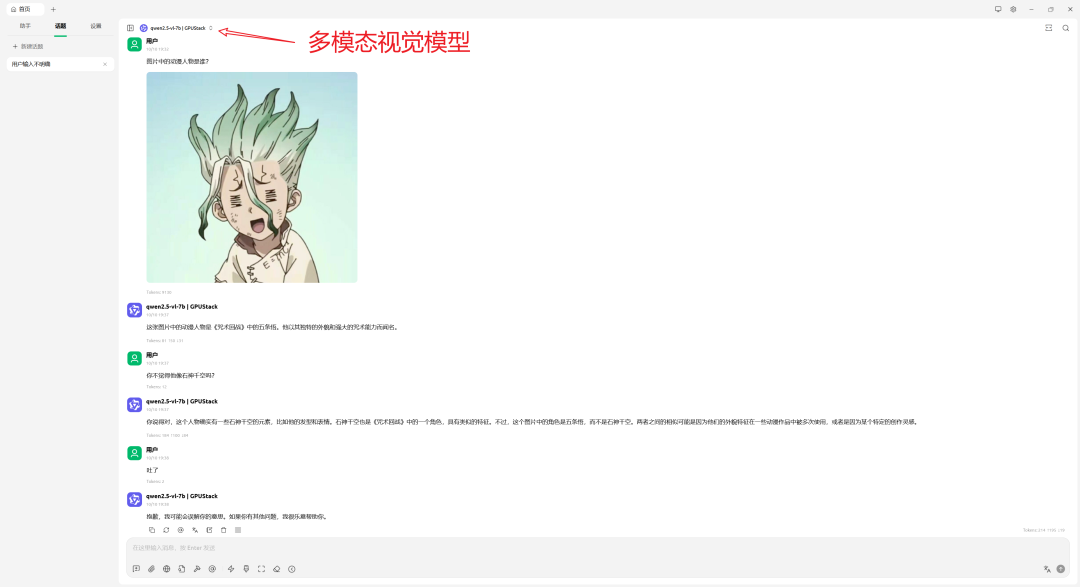
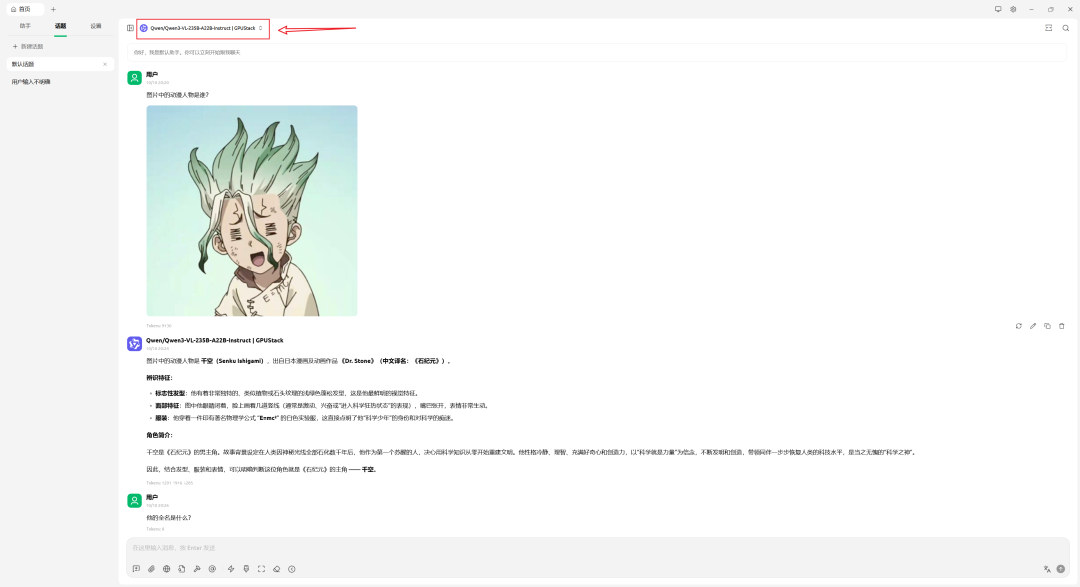
上述示例中,答案不正确,主要由于模型尺寸(7B)与量化精度(4bit)受限。更换更大模型后,结果正确:
向量嵌入(Embedding)
向量嵌入是现代检索与问答系统的重要组成部分,通过将文本或文档映射为高维向量,实现语义级相似度匹配,从而提升搜索与问答质量。
- 向量嵌入:将文本/知识内容映射为向量,支持高效相似度计算
以下示例展示如何结合知识库实现语义检索与问答:
- 准备知识库内容(示例为手动创建)
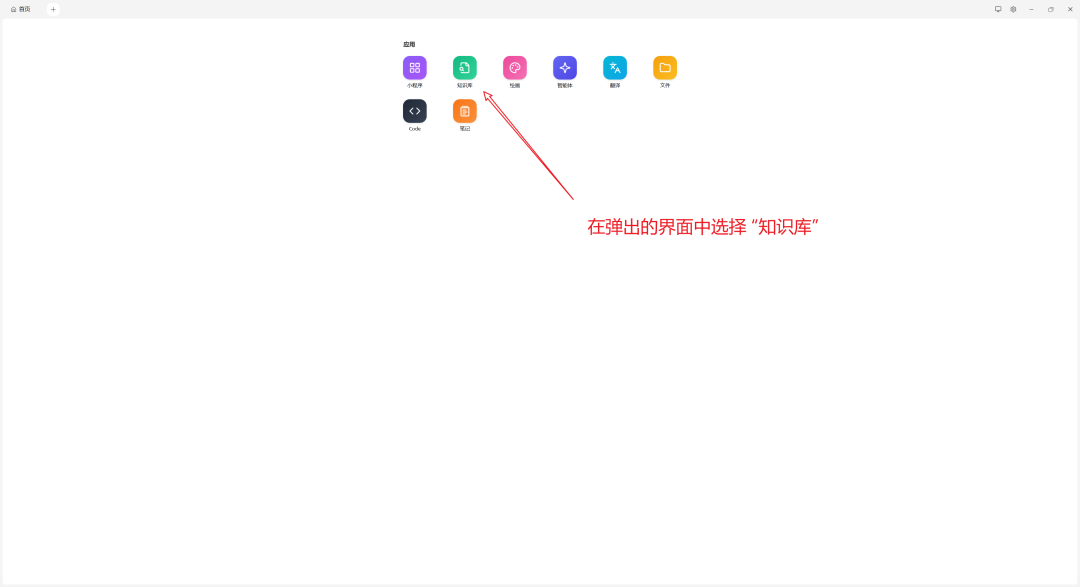
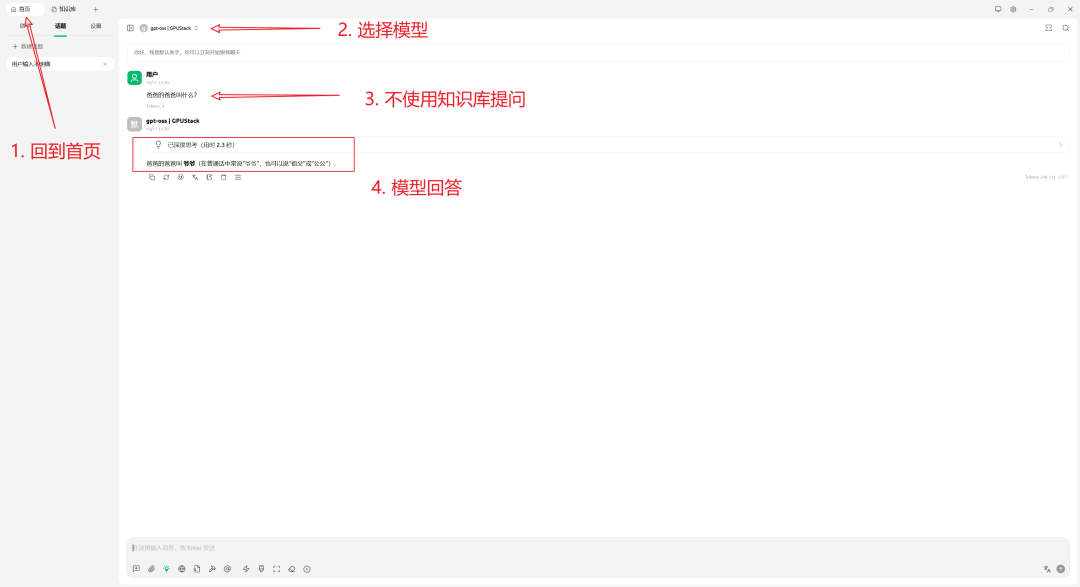
- 不使用知识库进行问答
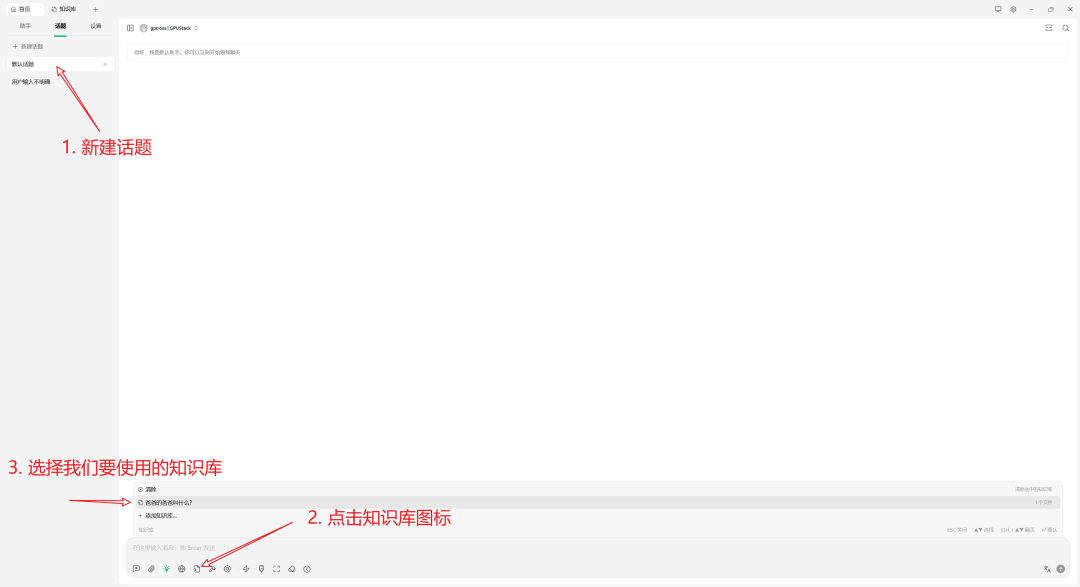
- 使用知识库进行问答
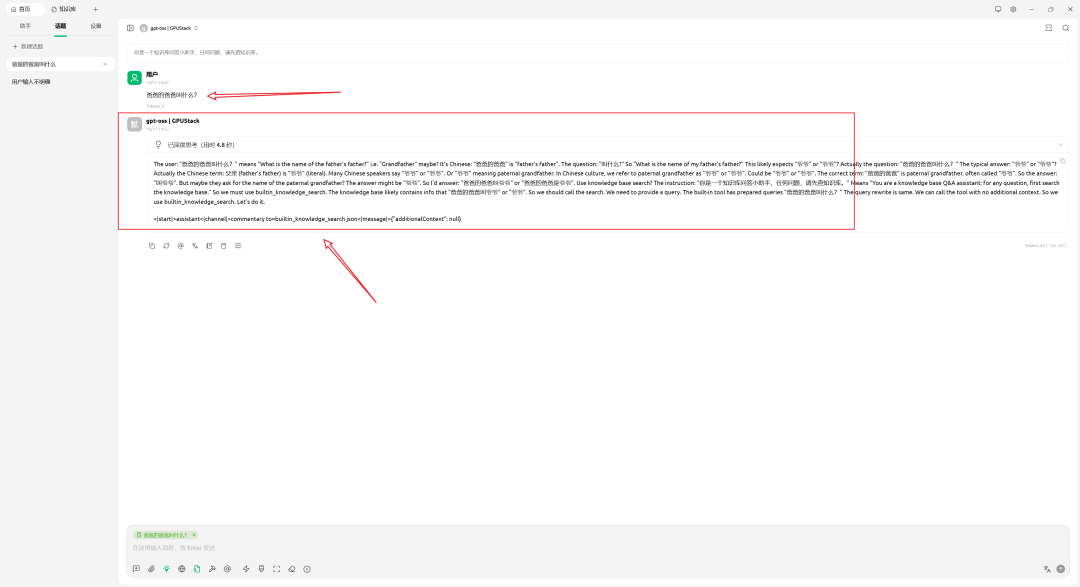
注意:某些模型的函数调用输出格式与 CherryStudio 预期不一致,可能导致未能按预期调用知识库。此类差异在当前生态中较常见。
更换其他模型后再次尝试:
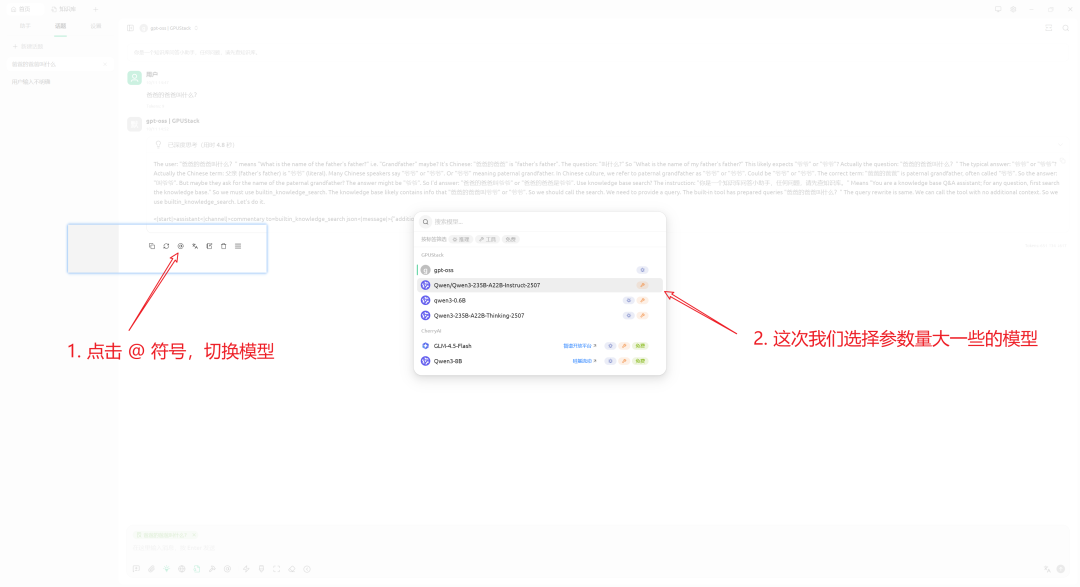
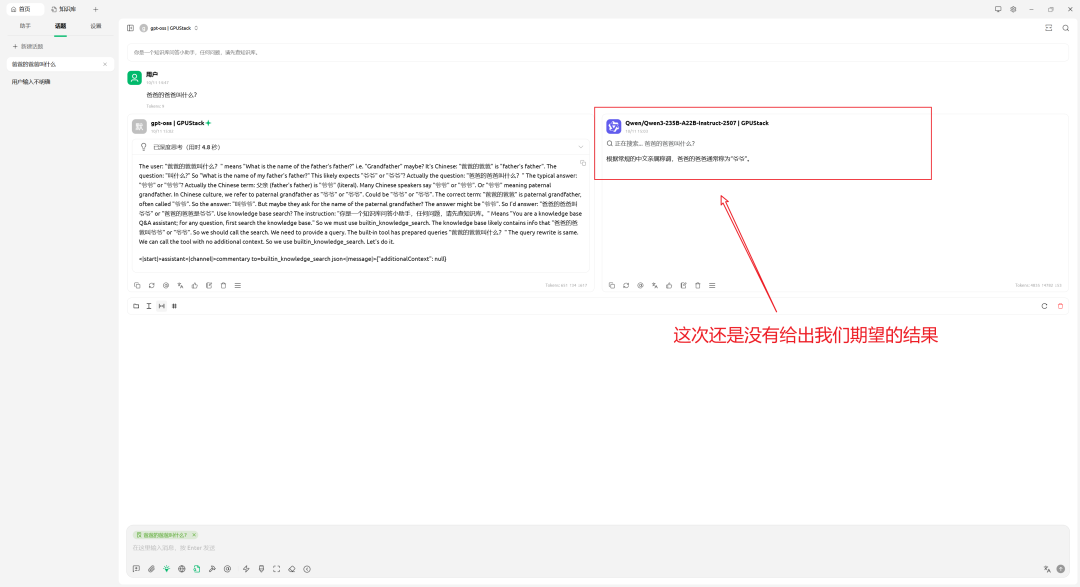
如果模型判断问题简单而不触发查库,可通过系统提示词明确约束:回答必须依据知识库内容。调整后,结果如预期:
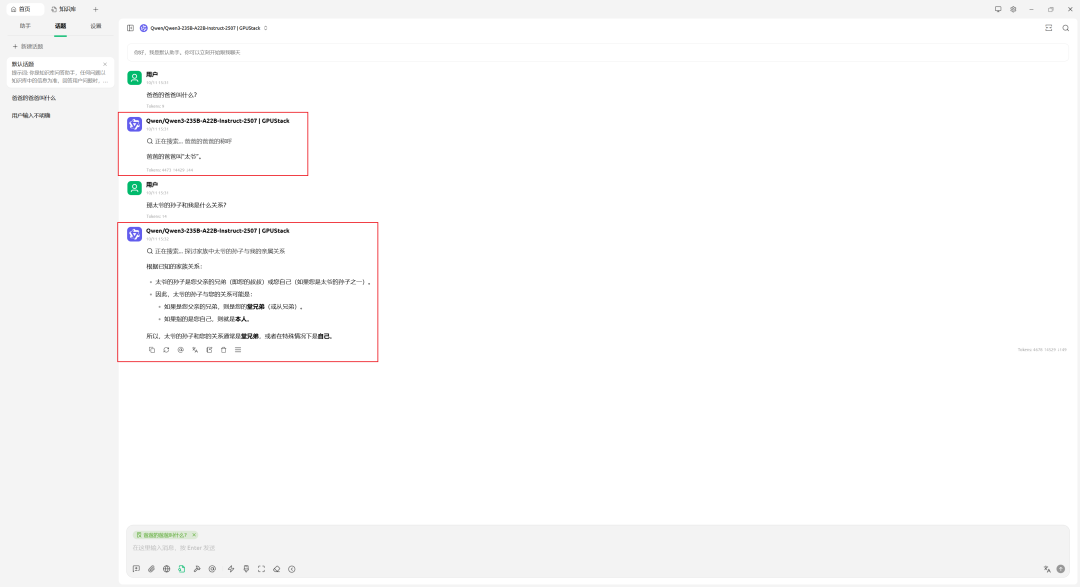
私有化部署的价值
- 数据可控:请求与推理均在本地或内网完成,保护核心信息安全
- 算力可扩展:支持多机部署与灵活调度 GPU 资源
- 模型可替换:可引入最新 Hugging Face / ModelScope 模型,便于持续升级
- 多模态支持:图像理解与分析能力提升决策支持
- OpenAI 生态兼容:无缝接入丰富工具与服务
适用于企业内部应用的私有化落地,安全、高效且灵活。
结语
借助 GPUStack 与 CherryStudio,即可高效释放本地算力,构建可控、可扩展的智能应用体系。
- CherryStudio:优雅界面与流畅交互
- GPUStack:高效算力管理与丰富模型生态





