

防患于未然,胜于亡羊补牢。
—— 本杰明·富兰克林
1. 湿度预测对于数据中心可靠性的重要性
随着人工智能(AI)的算力需求呈指数级增长,支撑其运行的基础设施正面临着日益紧张的资源限制。有最新研究显示,到2028年,AI的电力消耗可能高达美国所有家庭总用电量的22% [1]。高性能AI芯片的机架耗电量至少是传统服务器的10倍,随之产生巨量热能,导致数据中心内冷却系统占据了大部分建筑空间 [2]。除了巨大的碳足迹,AI还有着不可忽视的水足迹,其中很大一部分集中在水资源已经高度紧张的地区。例如,据估算,GPT-3在微软的美国数据中心进行训练时,需要消耗540万升水 [3]。对数据中心内部设备日常运行而言,季节性天气预报至关重要。温度和湿度等天气条件直接影响着数据中心内部冷却系统的工作强度 [4]。
在本文中,湿度预测将通过多种方法进行计算。更精确的温度和湿度预测能够帮助数据中心实现更高效的负载规划、优化冷却调度,从而降低对电力和当地水资源的需求。既然本文主要探讨湿度,那么就来看看湿度极值可能带来的影响:
- 高湿度: 凝露成为主要问题,可能导致硬件腐蚀并引发电气故障。高湿度还会迫使冷却器更努力地工作,增加能源和水资源的消耗。
- 低湿度: 危险转向另一方面:静电和静电放电(ESD)可能积聚并烧毁敏感芯片。
精确的湿度预测能够有效助力数据中心:
- 精细调整冷却调度
- 预测需求高峰
- 安排维护计划
- 在环境条件导致代价高昂的停机之前重新分配工作负载
通过实施上述保护措施,可以有效减轻电力和当地水资源的压力,确保AI中心的韧性以及分布式计算基础设施的整体效率。
受湿度影响的不仅仅是数据中心;传感器等边缘设备也可能受到影响。由于这些设备通常部署在室外和偏远地区,因此更容易受到天气条件的影响。边缘应用常常需要低延迟的预测,这使得XGBoost等轻量级算法更具优势。正因如此,在下面的预测部分中,XGBoost及其他轻量级算法将作为重点讨论对象。
本节最后,来探讨一下文章封面那张充满未来感的月球数据中心图片。月球数据中心将不受地球上诸多限制的影响,例如极端天气和地震。此外,月球为数据所有权提供了一个完全中立的场所。事实上,2025年2月26日,SpaceX公司发射了一枚猎鹰9号火箭,搭载了Intuitive Machines的“雅典娜”(Athena)月球着陆器 [5]。雅典娜着陆器上搭载了一台由Lonestar Holdings开发的名为“自由”(Freedom)的小型数据中心。尽管雅典娜着陆器未能完全直立着陆,但“自由”数据中心在着陆前成功进行了数据操作。更令人欣喜的是,尽管雅典娜着陆器坠入了一个陨石坑,但“自由”数据中心依然幸存,并成功展示了在月球部署数据中心的可行性 [6]。
2. 真实案例研究:带有精确预测区间的湿度预测
鉴于天气预报对数据中心的重要性,本文利用了来自Kaggle的真实世界数据集,其中包含德里(印度)的每日气候测量数据。印度拥有蓬勃发展的数据中心产业。根据DataCenters.com的数据 [7],德里目前拥有30个数据中心,并且德里的一家开发商计划投资20亿美元,进一步扩大印度数据中心的发展 [8]。
该数据包含温度、湿度、风速和大气压力测量值。本文使用了一个训练集来训练模型,并使用一个测试集来评估模型性能。Kaggle数据及其许可信息的链接可在本文脚注中找到。
尽管温度、风速和压力都会影响冷却需求,但本文重点关注湿度,因为它在蒸发冷却和水消耗中扮演着重要角色。此外,湿度的变化速度通常快于温度,因此,它是进行预测建模的一个非常有意义的目标。
研究从AutoARIMA等传统方法开始,然后转向Facebook的Prophet等更灵活的模型以及XGBoost,最后探索了深度学习模型。以下是本文中使用的完整预测方法列表:
- AutoARIMA
- Prophet
- NeuralProphet
- Random Forest (随机森林)
- XGBoost
- Mixture of Experts (专家混合模型)
- N-BEATS
在研究过程中,本文对模型的准确性、可解释性和部署可行性进行了比较——这并非纯粹的学术探讨,而是为了回答一个实际问题:哪种预测工具能够提供可靠、可操作的气候预测,从而帮助数据中心优化冷却、降低能源成本并节约水资源?
此外,每个预测图都将包含一个预测区间,而不仅仅是一条单一的预测线。单一的预测线可能具有误导性,因为它暗示着对未来某天的湿度水平“了如指掌”。鉴于天气总是充满不确定性,运营人员需要的不只是一条单一的预测。预测区间提供了一个可能的湿度值范围,反映了模型的局限性和自然变异性。
置信区间告知的是平均预测值。预测区间则更宽泛——它们涵盖了实际湿度读数可能出现的范围。对于运营人员来说,这种差异至关重要:低估范围会增加过热风险;高估范围则可能导致不必要的开支。
评估预测区间的一个好方法是观察其覆盖率。 对于95%的置信区间,预期大约100个点中有95个会落入其中。如果只有86个点落入,则表明模型过于自信。共形预测(Conformal prediction) 通过调整范围,使覆盖率与预期值保持一致。
共形预测通过分析模型过去的误差(残差 = 实际值 − 预测值),找出典型误差大小(这些残差的分位数),并将其添加到每个新预测的周围,从而创建一个以所需概率覆盖真实值的区间。
以下是计算预测区间的核心算法:
- 创建校准集。
- 计算残差:
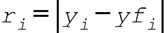
其中,方程右侧的第一项是实际观测值,第二项是同一时间点的模型预测值。
- 找到残差的分位数:
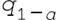
其中 alpha 是显著性水平,例如 0.05。
- 为新预测形成共形区间:
时间 t 的区间等于:
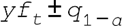
3. 数据与预测方法(附代码)
本文讨论的所有预测方法的代码都可以在Github上找到,目录链接位于文章末尾。在讨论预测方法之前,先来看看所使用的数据。图1显示了训练数据,图2显示了测试数据。如图1所示,训练数据表现出稳定、平稳的特性。然而,图2却呈现出不同的情况:测试期打破了这种稳定性,呈现出明显的下降趋势。这种鲜明对比使得预测的挑战性更高。
预计基于结构的AutoARIMA等方法以及随机森林等传统机器学习方法,将难以捕捉这种下降趋势,因为它们不具备时间感知能力。另一方面,深度学习预测方法能够理解测试序列与训练数据中相似的季节性部分相对应,因此更有能力捕捉这种下降趋势。
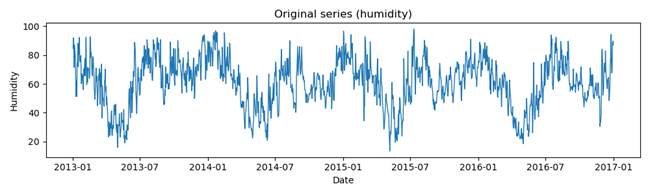
图1. 湿度训练数据
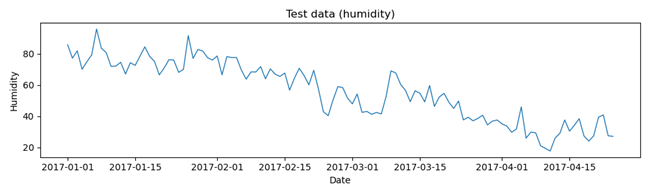
图2. 湿度测试数据
3. A. AutoARIMA 预测
ARIMA(自回归整合移动平均)模型结合了三个要素:
- AR 项用于捕捉过去值的记忆效应
- MA 项用于解释过去的预测误差
- 差分(“I”)用于去除趋势,使时间序列平稳。
3. A. 1. AutoARIMA 测试数据预测
传统上,分析师在拟合模型之前必须测试平稳性并决定应用多少差分。这是一个困难且容易出错的过程。AutoARIMA 通过在底层运行统计测试来减轻这一负担。它会自动决定差分程度,并搜索各种AR和MA组合,根据信息准则选择最佳拟合模型。简而言之,用户可以向其提供原始的非平稳数据,它将自动完成“侦探”工作——使其既强大又简单。
图3显示了AutoARIMA的预测(橙色虚线)和预测区间(黄色阴影区域)。ARIMA能够追踪短期波动,但无法捕捉较长的下降趋势;因此,预测结果变成了一条稳定的直线。这是一个典型的局限性:ARIMA可以捕捉局部自相关,但无法捕捉不断演变的动态。预测区间的扩大是合理的——它们反映了随着时间推移不确定性的增加。
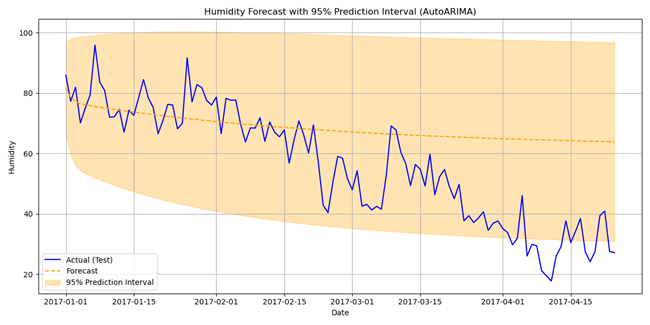
图3. AutoARIMA对测试数据的预测,带有预测区间。
3. A. 2. AutoARIMA 的准确性与预测区间的覆盖率
| MSE | RMSE | MAE |
|---|---|---|
| 398.19 | 19.95 | 15.37 |
表1. AutoARIMA的误差
在表1中,报告了三种不同的误差:MSE、RMSE和MAE,以提供模型准确性的完整视图。RMSE和MAE最易于理解,因为它们与目标变量使用相同的单位。RMSE更侧重于较大的误差,而MAE则表示误差的平均大小。同时报告了MSE,尽管它不那么直观,但常用于模型比较。
关于预测区间,这里没有应用共形预测,因为ARIMA本身已经返回了基于模型的95%预测区间。这些区间是根据ARIMA的统计假设推导出来的,而非模型无关的共形预测框架。然而,不使用共形预测导致预测区间的覆盖率并不完美(85.96%)。
3. A. 3. AutoARIMA 的可解释性
AutoARIMA的一个吸引人之处在于它能轻易地“看到”模型正在做什么。图4描绘了偏自相关函数(PACF),它计算平稳时间序列与其滞后值之间的偏相关性。该图显示,今天的湿度仍然“记住”昨天和前几天的情况,相关性随时间逐渐减弱。这种持久的记忆正是ARIMA构建预测的基础。
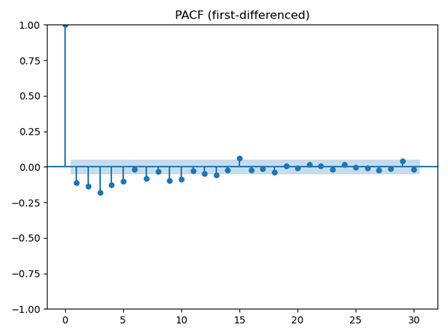
图4. PACF图
此外,还运行了KPSS检验,证实训练数据确实是平稳的。
3. A. 4. 部署模式
AutoARIMA易于部署:一旦给定时间序列,它会自动选择阶数并拟合,无需手动调优。其轻量级的计算开销使其适用于批量预测,甚至可以部署在资源有限的边缘设备上。然而,其简单性也意味着它更适合稳定的环境,而非结构发生突然变化的场景。
3. B. Prophet 预测
本节将讨论Prophet,这是一个由Facebook(现Meta)开发的开源预测库。Prophet将时间序列视为三个关键部分的加性总和:趋势、季节性以及节假日或特殊事件:
- 趋势:趋势通过灵活的方式建模,可以是可在变点处弯曲的直线,也可以是快速增长随后趋于平稳的饱和增长曲线。这类似于数据中心的冷却需求,它随工作负载增长而增加,但最终在系统达到容量后趋于平稳。
- 季节性:通过平滑的傅里叶项捕捉,因此每周或每年的循环模式会自动学习。
- 节假日或事件:可以作为回归变量添加,以解释一次性的峰值。
因此,可以看出Prophet具有非常方便的加性结构。这使得Prophet易于理解,并且对混乱的真实世界数据具有鲁棒性。
下面的代码片段1展示了如何训练和拟合Prophet模型并将其用于预测测试数据。请注意,Prophet预测返回yhat_lower和yhat_upper,它们是预测区间的上下限,并将预测区间设置为95%(代码第1行)。因此,与上面的AutoARIMA一样,预测区间不是从共形预测中推导出来的。
#Train and Fit the Prophet Model
model = Prophet(interval_width=0.95)
model.fit(train_df)
#Forecast on Test Data
future = test_df[['ds']].copy()
forecast = model.predict(future)
cols = ['ds', 'yhat', 'yhat_lower', 'yhat_upper']
forecast_sub = forecast[cols]
y_true = test_df['y'].to_numpy()
yhat = forecast['yhat'].to_numpy()
yhat_lower = forecast['yhat_lower'].to_numpy()
yhat_upper = forecast['yhat_upper'].to_numpy()
代码片段1. 使用Prophet进行训练和预测
3. B. 1. Prophet 测试数据预测
图5显示了Prophet对测试数据的预测(橙色线)和预测区间(蓝色阴影区域)。与AutoARIMA相比,可以看出Prophet的预测很好地捕捉了数据的下降趋势。
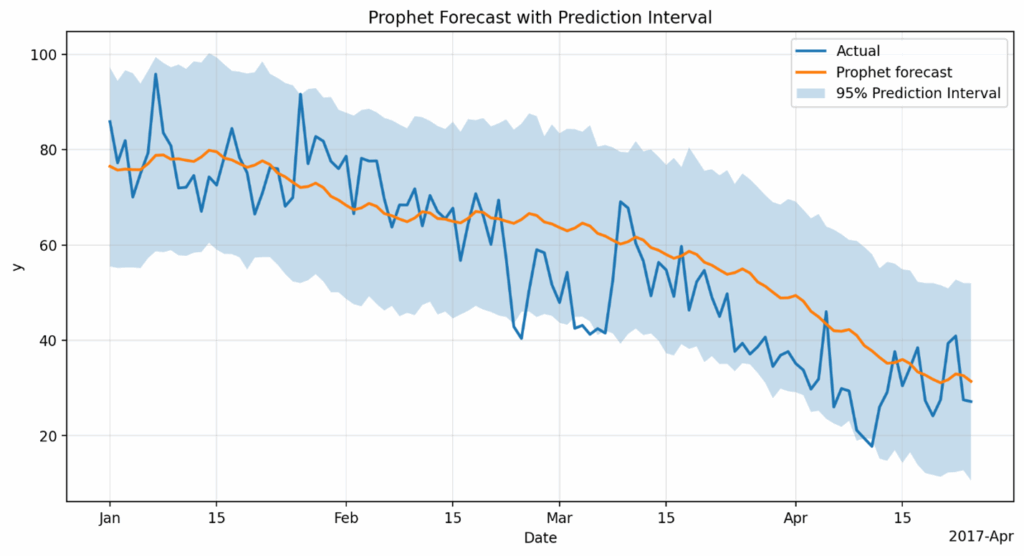
图5. Prophet对测试数据的预测,带有预测区间。
3. B. 2. Prophet 准确性与预测区间覆盖率
| MSE | RMSE | MAE |
|---|---|---|
| 105.26 | 10.25 | 8.28 |
表2. Prophet的误差。
与AutoARIMA相比,Prophet的预测改进也可以从上面的表2所示的误差中看出。
如前所述,预测区间并非使用共形预测推导而来。然而,与AutoARIMA相比,预测区间的覆盖率表现要好得多:93.86%。
3. B. 3. Prophet 可解释性
如前所述,Prophet具有透明的加性结构:它将预测分解为趋势、平滑季节性以及可选的节假日/回归效应,因此组件图精确地展示了每个部分对yhat的贡献,以及每个驱动因素如何影响预测。
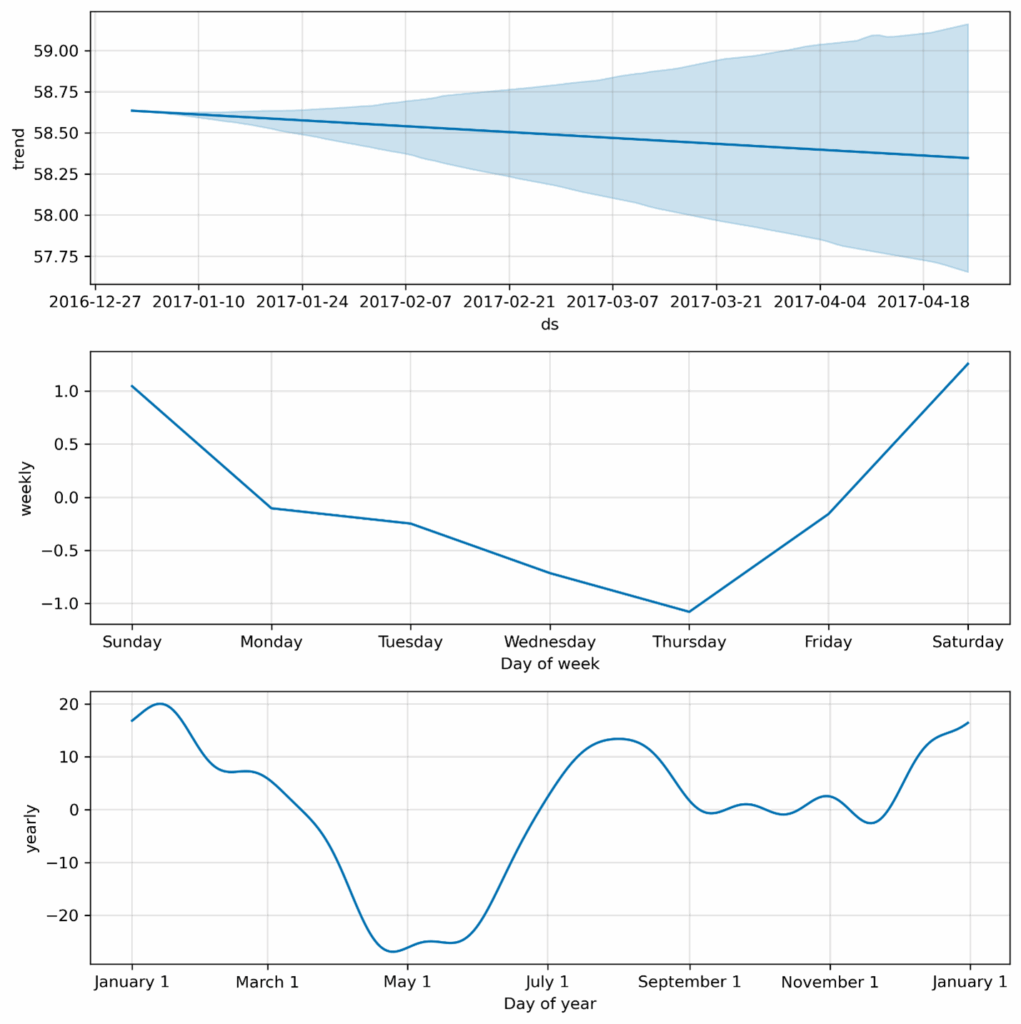
图6. Prophet预测组件。
上面的图6显示了Prophet的预测组件:随时间缓慢下降的趋势(顶部),每周循环中周末湿度较高而周中较干燥(中部),以及具有潮湿冬季、春季下降、夏季和秋季再次上升的年度循环(底部)。
3. B. 4. Prophet 部署模式
Prophet部署简单,在标准CPU上高效运行,并且可以大规模使用或部署在边缘设备上,使其非常适合需要快速、可解释预测的业务应用。
3. C. 使用 NeuralProphet 进行预测
NeuralProphet是Prophet的神经网络扩展版本。它保留了相同的核心结构(趋势 + 季节性 + 事件),但增加了:
- 一个前馈神经网络,用于捕捉更复杂的非线性模式。
- 支持滞后回归变量和自回归(可以直接使用过去的值,类似于AR模型)。
- 能够更灵活地学习多重季节性和高阶交互。
Prophet具有统计性和加性结构的优点,这带来了透明性和快速预测。NeuralProphet在此框架上进行构建,并引入了深度学习。NeuralProphet可以捕捉非线性和自回归效应,但这种额外的灵活性也使其更难解释。
下面的代码片段2显示,模型中使用了季节性来利用湿度的季节性模式。
model = NeuralProphet(
seasonality_mode='additive',
yearly_seasonality=False,
weekly_seasonality=False,
daily_seasonality=False,
n_changepoints=10,
quantiles=[0.025, 0.975] # For 95% prediction interval
)
# Add custom seasonality (~6 months)
model.add_seasonality(name='six_month', period=180, fourier_order=5)
model.fit(train, freq='D', progress='bar')
future=model.make_future_dataframe(train,periods=len(test), n_historic_predictions=len(train))
forecast = model.predict(future)
代码片段2. 使用NeuralProphet进行训练和预测
3. C. 1. NeuralProphet 测试数据预测
图7显示了NeuralProphet的预测(绿色虚线)和预测区间(浅绿色阴影区域)。与Prophet类似,NeuralProphet的预测也很好地捕捉了数据的下降趋势。
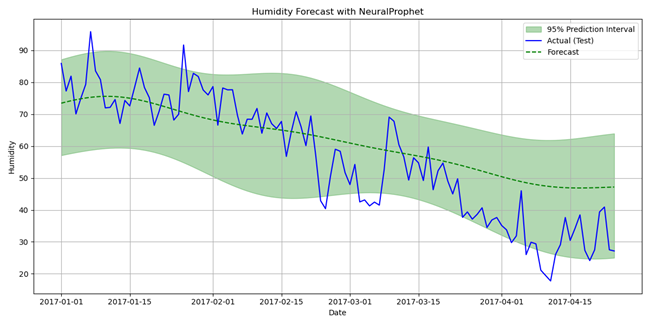
图7. NeuralProphet对测试数据的预测,带有预测区间。
3. C. 2. NeuralProphet 准确性与预测区间覆盖率
| MSE | RMSE | MAE |
|---|---|---|
| 145.31 | 12.05 | 9.64 |
表3. NeuralProphet的误差。
值得注意的是,尽管进行了神经网络增强并添加了季节性,NeuralProphet的误差略高于Prophet。NeuralProphet增加了更多的“活动部件”,但这并不总是转化为更好的预测。在有限或混乱的数据上,其额外的灵活性实际上可能会适得其反,而Prophet更简单的设置通常能使预测更稳定,准确性更高一些。
关于预测区间,它是使用NeuralProphet返回的极限变量yhat1 2.5和yhat1 97.5绘制的。95%预测区间的覆盖率为83.33%。这个值较低,但这是预料之中的,因为它不是使用共形预测计算的。
3. C. 3. NeuralProphet 可解释性
图8中的三个面板分别显示:
- 面板1. 趋势: 显示学习到的基线水平以及分段线性趋势中斜率变化的位置(变点)。
- 面板2.趋势变化率: 条形/峰值表示在每个变点处趋势斜率的跳变幅度(正值表示增长加快,负值表示减速/下降)。
- 面板3.季节性: 季节性成分的周期性形状/强度。
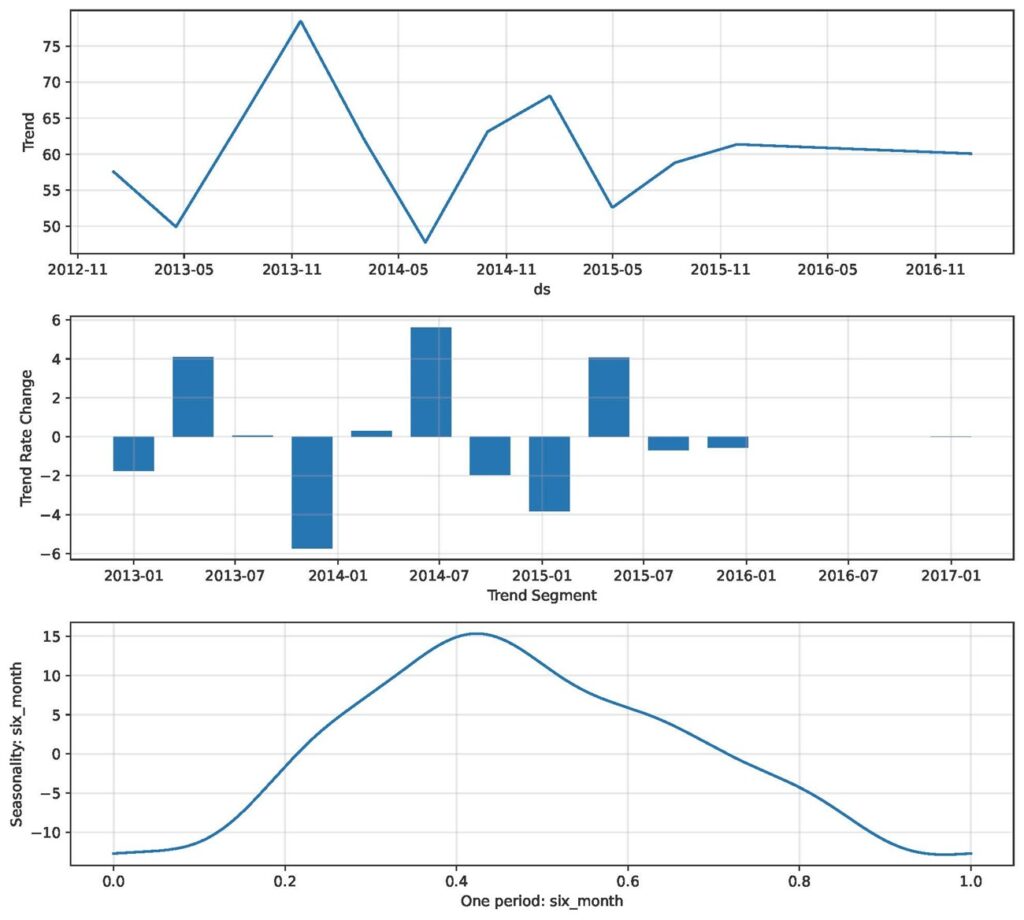
图8. 这三个面板显示了模型估算的趋势基线、趋势变化率和6个月季节性。这些突出显示了NeuralProphet如何检测斜率变化和整体变化动态。
3. C. 4. NeuralProphet 部署模式
NeuralProphet在CPU上运行良好,可用于定时任务或小型API。虽然它比Prophet更重,但对于大多数容器化或批处理部署仍然实用,并且经过一些设置后,也可以在树莓派等边缘设备上运行。
3. D. Random Forest (随机森林) 预测
Random Forest是一种机器学习技术,也可以用于预测。其实现方式是将过去的值和外部因素转化为特征。它的工作原理是:首先,在随机选择的数据子集上构建多棵决策树。然后,它对这些树的结果进行平均。这有助于避免过拟合并捕捉非线性模式。
3. D. 1. Random Forest 预测
下面的图9显示了Random Forest的预测(橙色线)和预测区间(蓝色阴影区域)。可以看出,Random Forest的表现不尽如人意。这发生是因为Random Forest并没有真正“理解”时间。它不是遵循数据的自然序列,而是将滞后值视为普通的特征。这使得模型善于捕捉某些非线性模式,但在识别更长期的趋势或随时间推移的变化方面表现较弱。结果是预测看起来过于平滑且准确性较低,这解释了较高的MSE。
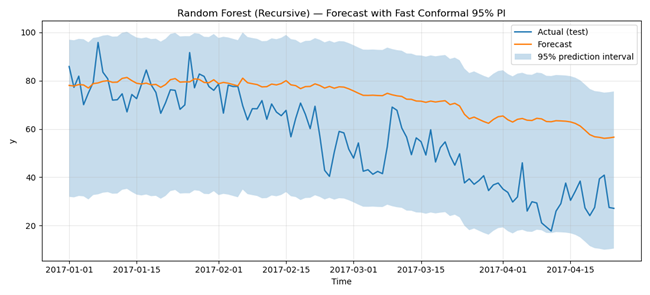
图9. Random Forest对测试数据的预测,带有预测区间。
3. D. 2. Random Forest 准确性与预测区间
| MSE | RMSE | MAE |
|---|---|---|
| 448.77 | 21.18 | 17.6 |
表4. 随机森林误差
表4中所示的高误差值也清楚地表明了Random Forest的糟糕性能。
关于预测区间,这是第一个使用共形预测来计算预测区间的预测技术。
预测区间的覆盖率估计达到了惊人的100%。
3. D. 3. Random Forest 可解释性
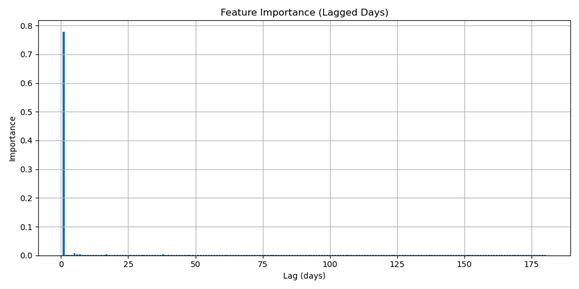
图10. Random Forest 滞后重要性
Random Forest通过对其预测中使用的特征的重要性进行排序来提供一定的可解释性。在时间序列预测中,这通常意味着检查目标变量的哪些滞后值对模型的预测贡献最大。图10中的特征重要性图显示,最近的滞后(滞后一天)占据主导地位,几乎承载了80%的预测权重,而所有更长的滞后几乎没有贡献。这表明Random Forest主要依赖于最近的观测值进行预测,平滑了长期依赖关系。虽然这种可解释性有助于理解模型“关注”什么,但它也突显了为什么Random Forest在捕捉更广泛的时间动态方面可能不如更适合序列结构的方法。
3. D.4. Random Forest 部署模式
Random Forest模型部署起来相对轻量,因为它们由一组决策树组成,不需要特殊的硬件或复杂的运行时环境。它们可以高效地导出并在标准服务器、嵌入式系统甚至资源有限的边缘设备上运行,使其适用于资源受限的实时应用。然而,当使用大量树时,其内存占用可能会增加,因此在边缘环境中可以应用紧凑版本或树剪枝技术。
3. E. XGBoost 预测
XGBoost是一种增强算法,它逐个构建树,其中每棵新树都纠正前一棵树的错误。在预测中,它被提供了滞后值、滚动平均值和外部变量等特征,使其能够学习时间模式和变量之间的关系。它表现出色是因为它结合了强大的正则化功能,使其能够比简单方法更有效地处理大型复杂数据集。但是,像Random Forests一样,它不能自然地处理时间顺序,因此它的成功在很大程度上取决于时间特征的设计质量。
3. E. 1. XGBoost 测试数据预测
图11显示了XGBoost的预测(橙色线)和预测区间(蓝色阴影区域)。可以看出,预测紧密跟随湿度信号,因此在预测湿度方面非常成功。这也可以通过下面表5中显示的相对较小的误差得到证实,特别是与Random Forest相比。
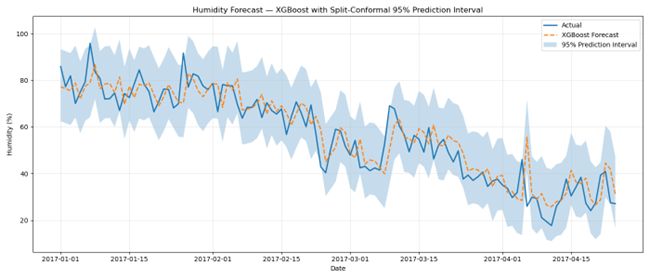
图11. XGBoost对测试数据的预测。
XGBoost按顺序构建树,这是其强大之处的来源。如前所述,每棵新树都会纠正前一棵树的错误。这种增强过程与强大的正则化相结合。这种方法可以捕捉快速变化,处理复杂模式,并且仍然保持可靠。这通常使其预测比Random Forest的预测更接近真实。
3. E. 2. XGBoost 预测准确性与预测区间覆盖率
| MSE | RMSE | MAE |
|---|---|---|
| 57.46 | 7.58 | 5.69 |
表5. XGBoost预测误差。
在这里,也使用了共形预测来计算预测区间。因此,预测区间的覆盖率很高:94.74%。
3. E. 3. XGBoost 预测可解释性
XGBoost尽管复杂,但与深度学习模型相比,其可解释性仍然相当高。它提供特征重要性分数,显示哪些滞后值或外部变量驱动了预测。可以像Random Forest一样查看特征重要性图。为了更深入的了解,SHAP值展示了每个因素如何影响单个预测。这既提供了整体情况,也提供了逐个案例的洞察。
下面的图12显示了一个特征的权重,即它在分割中使用的频率。
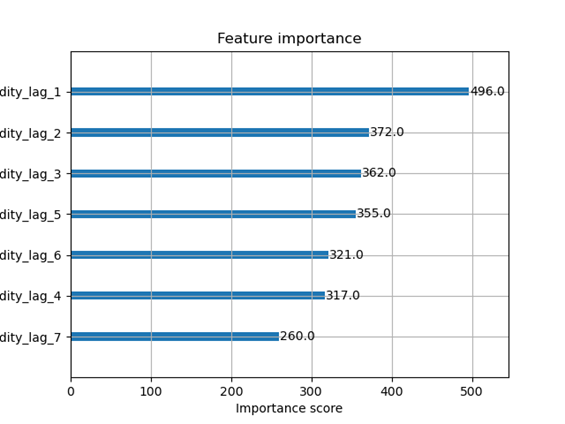
图12. XGBoost滞后重要性。
下面的系列显示了每个滞后的增益,即使用滞后时平均改进量。
{‘humiditylag1’: 3431.917724609375, ‘humiditylag2’: 100.19515228271484, ‘humiditylag3’: 130.51077270507812, ‘humiditylag4’: 118.07515716552734, ‘humiditylag5’: 155.8759307861328, ‘humiditylag6’: 152.50379943847656, ‘humiditylag7’: 139.58169555664062}
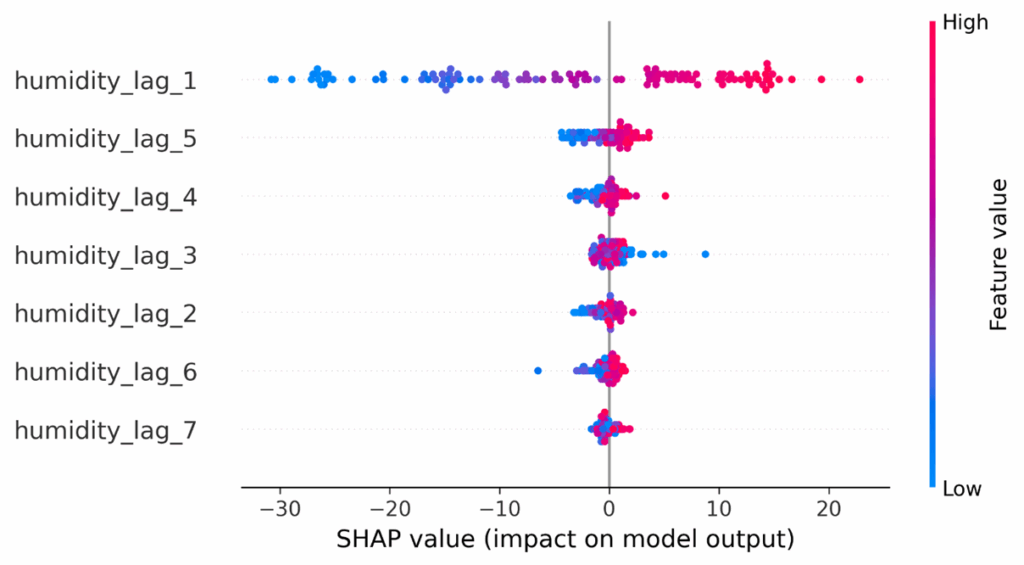
图13. SHAP值用于XGBoost滞后。
图13中的SHAP摘要图显示,humidity_lag_1是迄今为止最具影响力的特征,高湿度近期值推动预测上升,低湿度近期值则拉低预测。后续滞后(2-7)只扮演次要角色,表明模型主要依赖最近的观测值进行预测。
3. E. 4. XGBoost 部署模式
XGBoost同样易于跨平台部署,从云服务到嵌入式系统。它相对于Random Forest的主要优势在于效率:模型通常更小,推理速度更快。这使得模型适用于实时使用。它对多种语言和平台的支持使其易于在各种设置中实现。
3. F. Mixture of Experts (MoE) 预测
MoE方法结合了多个专业模型(“专家”),每个模型都经过调整以捕捉数据的不同方面,并辅以一个门控网络,用于确定每个专家在最终预测中的权重。
在代码片段3中,可以看到关键词AutoGluon和Chronos。对此进行解释:本文使用Hugging Face模型并通过AutoGluon集成实现了专家混合模型,其中Chronos作为其中一个专家。Chronos是一个使用Transformer构建的时间序列预测模型家族。AutoGluon是一个有用的AutoML框架,可以处理表格、文本、图像和时间序列数据。专家混合模型只是其众多利用模型集成提升性能的策略之一。
from autogluon.timeseries import TimeSeriesDataFrame, TimeSeriesPredictor
MODEL_REPO = "autogluon/chronos-bolt-small"
LOCAL_MODEL_DIR = "models/chronos-bolt-small
predictor_roll = TimeSeriesPredictor(
prediction_length=1,
target="humidity",
freq=FREQ,
eval_metric="MSE",
verbosity=1
)
predictor_roll.fit(train_data=train_tsd, hyperparameters=hyperparams, time_limit=None)
代码片段3:拟合Autogluon模型TimeSeriesPredictor
在上面的代码片段3中,预测器被称为predictor_roll,因为MoE预测以滚动方式生成预测:每个预测值都会反馈回模型以预测下一步。这种方法反映了时间序列数据的顺序性质。它还允许门控网络在预测范围内的每个点动态调整其所依赖的专家。滚动预测也揭示了误差如何随时间累积。通过这种方式,可以获得更真实的多步性能视图。
3. F. 1. MOE 测试数据预测
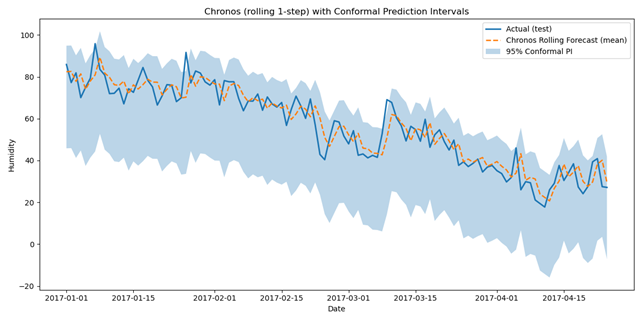
图14. MOE测试数据预测和预测区间。
如上图14所示,MoE表现极其出色,并紧密跟随实际测试数据。如下表6所示,MoE实现了最佳的准确性,并且整体误差最小。
3. F. 2. MOE 预测准确性与预测区间覆盖率
| MSE | RMSE | MAE |
|---|---|---|
| 45.52 | 6.75 | 5.18 |
表6. 专家混合模型预测误差。
95%预测区间的覆盖率非常出色(97.37%),因为使用了共形预测。
3. F. 3. MOE 预测可解释性
有几种方法可以深入了解MoE的工作原理:
- 门控网络权重:通过检查门控网络的输出,可以看到每个预测中哪个(或哪些)专家获得了最大的权重。这揭示了在何时以及为何某个专家更受信任。
- 专家专长:每个专家都可以单独分析——例如,一个可能捕捉短期波动,而另一个处理长期季节性趋势。并排查看它们的预测有助于解释集成模型的行为。
- 特征归因(SHAP/特征重要性):如果专家本身是可解释的模型(如决策树),可以计算它们的特征重要性。即使对于神经网络专家,也可以使用SHAP或集成梯度来理解特征如何影响决策。
因此,虽然MoE不像Random Forest或XGBoost那样“开箱即用”的可解释,但通过分析何时以及为何选择了哪个专家,仍然可以打开这个黑箱。
3. F. 4. MoE 部署模式
部署专家混合模型比决策树集成模型更具挑战性。原因在于它既涉及专家模型,也涉及门控网络。在数据中心、服务器或云端,实现相对简单,因为PyTorch和TensorFlow等现代框架可以轻松处理编排。然而,对于边缘设备,部署则困难得多。具体的挑战在于MoE的复杂性和规模。因此,通常需要进行模型剪枝、量化或限制活跃专家的数量以保持推理的轻量化。AutoML框架(如AutoGluon)通过封装整个MoE管道来简化部署。Hugging Face网站也托管了大型MoE模型,可以帮助扩展到生产级AI系统。
3. G. N-BEATS 预测
N-BEATS [9] 是一种深度学习模型,用于时间序列预测,由堆叠的完全连接层组成,这些层被分组为块。每个块输出一个预测和一个回溯(backcast),其中回溯从输入中移除,以便下一个块可以专注于剩余部分。通过连接这些块,模型逐渐完善其预测并捕捉复杂模式。在本文的实现中,使用了滑动窗口设置:模型检查固定窗口的过去观测值(以及平均温度等外部驱动因素),并学习同时预测多个未来点。然后窗口在数据上一步步向前滑动,为模型提供许多重叠的训练样本,并帮助其推广到未见的预测范围。
在本文中,N-BEATS是使用N-BEATSx实现的,它是原始N-BEATS架构的扩展,包含了外部驱动因素。N-BEATS和N-BEATSx是NeuralForecast库 [10] 的一部分,该库提供了多种神经网络预测模型。如代码片段4所示,N-BEATS是使用工厂函数(make_model)设置的,这允许定义预测horizon变量并添加平均温度(meantemp)作为额外输入。包含meantemp背后的想法很简单:模型不仅从目标序列的过去值中学习,还从这个关键的外部因素中学习。
def make_model(horizon):
return NBEATSx(
input_size=INPUT_SIZE,
h=horizon,
max_steps=MAX_STEPS,
learning_rate=LR,
stack_types=['seasonality','trend'],
n_blocks=[3,3],
futr_exog_list=['meantemp'],
random_seed=SEED,
# early_stop_patience=10, # optional
)
# Fit model on train_main
model_cal = make_model(horizon=CAL_SIZE)
nf_cal = NeuralForecast(models=[model_cal], freq='D')
代码片段4:N-BEATS模型创建与拟合。
3. G. 1. N-BEATS 测试数据预测
图15显示了N-BEATS预测模型(橙色线)和预测区间(蓝色区域)。可以看出,预测能够跟随数据的下降趋势,但停留于数据线之上,占据了相当一部分数据范围。
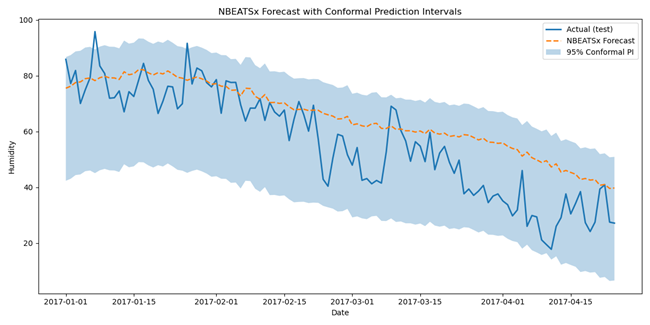
图15. N-BEATS对测试数据的预测和预测区间。
3. G. 2. N-BEATS 准确性与预测区间覆盖率
| MSE | RMSE | MAE |
|---|---|---|
| 166.76 | 12.91 | 10.32 |
表7. N-BEATS预测误差。
对于N-BEATS,使用了共形预测,因此预测区间的覆盖率非常出色:98.25%。
3. G. 3. N-BEATS 可解释性
在实验中,使用了通用形式的N-BEATS,它将模型视为一个黑箱预测器。然而,N-BEATS还提供了另一种具有“可解释块”的架构,该架构明确地对趋势和季节性成分进行建模。这意味着该网络不仅能生成准确的预测,还能将时间序列分解为人类可读的部分,从而更容易理解预测的驱动因素。
3. G. 4. N-BEATS 部署模式
由于N-BEATS完全由前馈层构建,因此与其他深度学习模型相比,它相对轻量。这使得它不仅易于部署在服务器上,也易于部署在边缘设备上,可以在没有重型硬件要求的情况下实时提供多步预测。
结论
本文比较了多种预测方法——从AutoARIMA和Prophet等经典基线模型,到XGBoost等机器学习方法,再到N-BEATS和专家混合模型等深度学习架构。较简单的模型提供了透明度和易于部署的优势,但在捕捉湿度序列的复杂性方面表现不足。相比之下,现代深度学习和基于集成的方法显著提高了准确性,其中专家混合模型实现了最低的误差(MSE = 45)。
下面是均方误差的汇总:
- AutoARIMA MSE = 398.19
- Prophet MSE = 105.26
- NeuralProphet MSE = 145.31
- Random Forest MSE = 448.77
- XGBoost MSE = 57.46
- Mixture of Experts MSE = 45.52
- N-BEATS MSE = 166.76
除了准确性,本文还为每种预测方法计算了预测区间,并展示了如何使用共形预测来计算精确的预测区间。每种预测方法的共形预测代码都可以在Github上的Jupyter Notebooks中找到。预测区间很重要,因为它们提供了对预测不确定性的现实感知。
对于每种预测方法,本文还探讨了其可解释性和部署模式。对于AutoARIMA和Prophet等模型,可解释性直接来源于它们的结构。AutoARIMA展示了过去值和误差如何影响当前,而Prophet则将时间序列分解为趋势和季节性等组件,这些组件可以被绘制和检查。N-BEATS或专家混合模型等深度学习模型更像黑箱。然而,在它们的情况下,可以使用SHAP或误差分析等工具来获取洞察。
部署同样重要:XGBoost等轻量级模型可以在边缘设备上高效运行。大型深度学习模型可以利用AutoGluon等框架来简化其训练。一个巨大的好处是这些模型可以本地部署,从而避免API限制。
总而言之,研究结果表明,可靠的湿度预测对于数据中心的日常运营既可行又实用。通过采用这些方法,数据中心运营者可以预测能源需求高峰并优化冷却调度。通过这种方式,他们可以减少能源消耗和水资源使用。鉴于AI电力需求持续增长,预测湿度等环境驱动因素的能力至关重要,因为这可以使数字基础设施更具韧性和可持续性。
感谢阅读!
文章的完整代码可在以下链接找到:
https://github.com/theomitsa/Humidity_forecasting
参考文献
[1] J. O’ Donnell, and C. Crownhart, We Did the Math on AI’s Energy Footprint. Here’s The Story You Haven’t Heard (2025), MIT Technology Review.
[2] Staff writers, Inside the Relentless Race for AI Capacity (2025), Financial Times, https://ig.ft.com/ai-data-centres/
[3] P. Li, et al, Making AI Less Thirsty: Uncovering and Addressing the Water Footprint of AI Models (2025), Communications of the ACM, https://cacm.acm.org/sustainability-and-computing/making-ai-less-thirsty/
[4] Jackson Mechanical Service Blog, Managing Humidity Levels: A Key Factor For Data Center Efficiency and Uptime (2025), https://www.jmsokc.com/blog/managing-humidity-levels-a-key-factor-for-data-center-efficiency-and-uptime/#:~:text=Inadequate%20management%20of%20humidity%20within,together%20might%20precipitate%20revenue%20declines.
[5] D. Genkina, Is It Lunacy to Put a Data Center on the Moon? (2025), IEEE Spectrum.
[6] R. Burkett, Lunar Data Center Intact Despite Lunar Lander’s Botched Landing, St. Pete Company Says (2025), https://www.fox13news.com/news/lunar-data-center-intact-despite-lunar-landers-botched-landing-st-pete-company-says
[7] Data Centers in Delhi, https://www.datacenters.com/locations/india/delhi/delhi
[8] Staff writers, Delhi Developer to Invest $2 Billion on India Darta Centre Boom (2025), Economic Times of India Times, https://economictimes.indiatimes.com/tech/technology/delhi-developer-to-invest-2-billion-on-india-data-centre-boom/articleshow/122156065.cms?from=mdr
[9] B. N. Oreshkin et al., N-BEATS, Neural Basis Expansion for Interpretable Time Series Forecasting (2019), https://arxiv.org/abs/1905.10437
[10] NeuralForecast Library, https://github.com/Nixtla/neuralforecast?tab=readme-ov-file
脚注:
- 除非另有说明,所有图片/图表均由作者提供。
- 本文用于预测的数据链接:https://www.kaggle.com/datasets/sumanthvrao/daily-climate-time-series-data/data
- 数据许可:数据采用知识共享许可协议:CC0 1.0。数据许可链接:https://creativecommons.org/publicdomain/zero/1.0/

![图 1. MobileNetV3-Large (左) 和 MobileNetV3-Small (右) 架构 [3]。](https://accesspath-com-1252517293.cos.ap-nanjing.myqcloud.com/2025/11/20251103071837376.png)



