视觉语言模型(Vision Language Models, VLM)作为强大的AI工具,能够直接以图像而非传统大型语言模型(LLM)所依赖的文本作为输入。这极大地拓展了应用的可能性,因为这意味着可以直接处理文档的视觉内容,无需先通过光学字符识别(OCR)提取文本,再将其输入到LLM。
本文将深入探讨如何将视觉语言模型应用于处理超长文档理解任务。这些任务可能涉及超过100页的巨型文档,或是包含大量图表、插画等密集信息的复杂文档。文章将详细讨论在应用VLM时需要考虑的关键因素,以及它们能胜任哪些类型的任务。
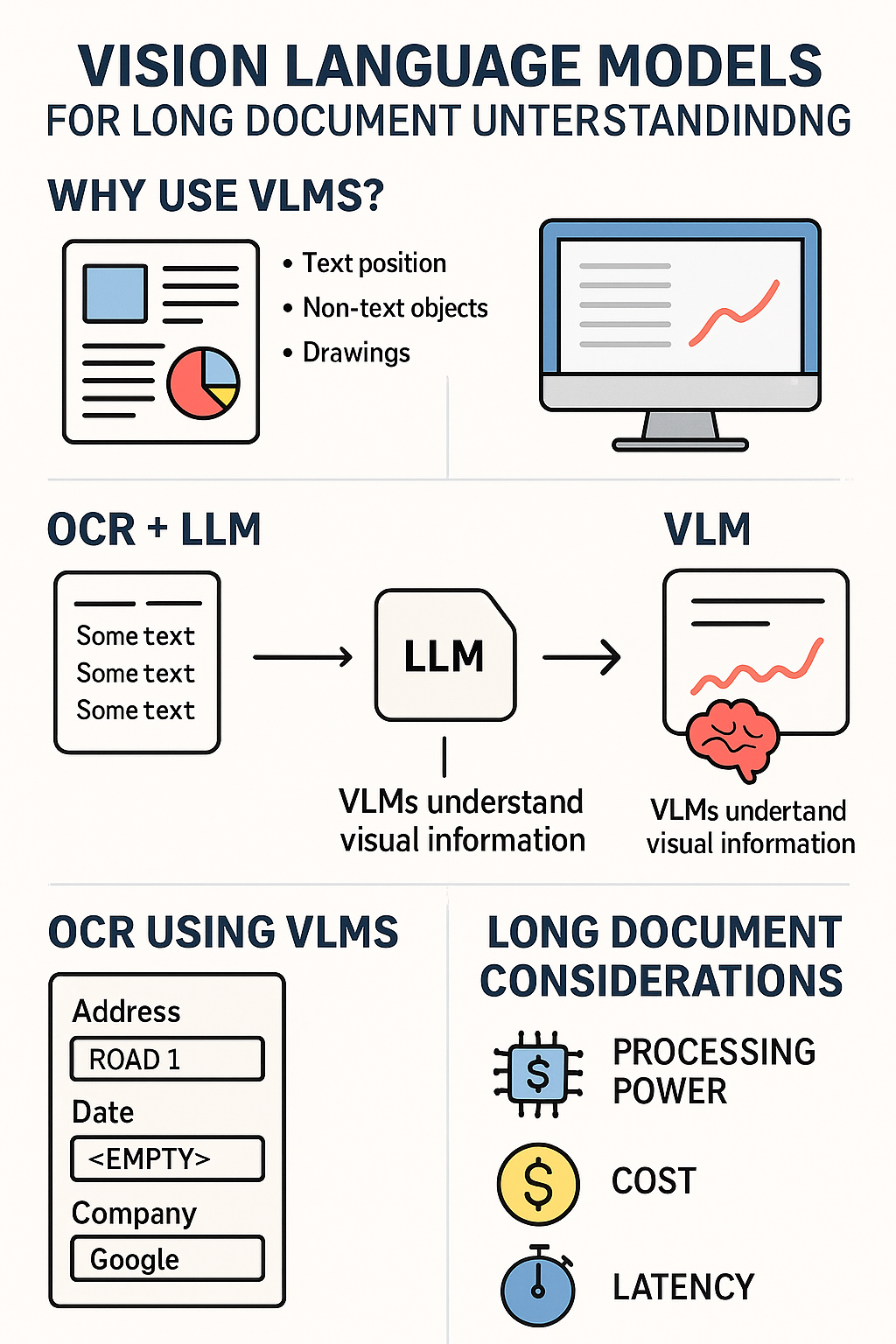
这张信息图概括了本文的主要内容。将介绍VLM为何如此重要,以及如何将其应用于处理长文档。例如,VLM可以用于实现更高级的OCR功能,将更多文档信息融入到提取的文本中。此外,VLM还能直接处理文档图像,但此时需综合考量所需的处理能力、成本与延迟。图片由ChatGPT生成。
为何我们需要视觉语言模型?
在之前的文章中,已多次讨论视觉语言模型,并强调了它们对于理解某些文档内容的关键作用。之所以需要VLM,主要原因在于文档中的许多信息,其理解离不开视觉输入。
VLM的替代方案通常是先使用OCR,再结合LLM。然而,这种方法的局限性在于,它仅能从文档中提取文本,而无法包含关键的视觉信息,例如:
- 不同文本块之间的相对位置关系
- 非文本信息(本质上是除字母以外的所有元素,如符号、图纸或图表)
- 文本相对于其他视觉信息的位置
这些视觉信息对于真正理解文档往往至关重要。因此,直接使用VLM,将图像作为输入,从而能够同时解析视觉信息,通常会带来更好的效果。
对于超长文档而言,应用VLM曾是一项挑战,因为表示视觉信息需要大量的标记(tokens)。处理数百页的文档曾是巨大的难题。然而,随着VLM技术近年来的诸多进步,模型的性能持续提升,它们在将视觉信息压缩成合理上下文长度方面表现越来越好,这使得将VLM应用于长文档理解任务变得可行且高效。
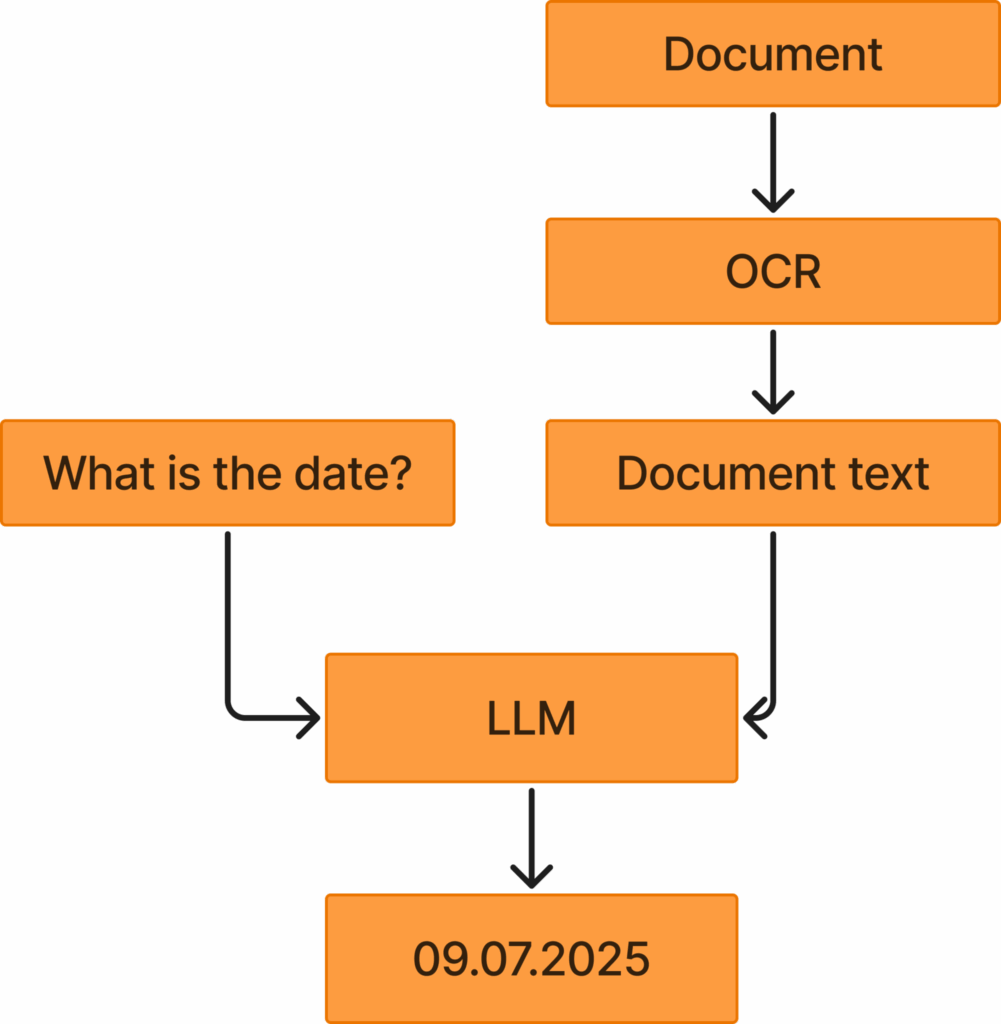
此图展示了OCR与LLM结合的应用方式。用户首先获取文档,然后应用OCR来提取文档文本。接着,将此文本连同用户查询一起输入到LLM中,LLM根据文档文本回应问题。如果改用VLM,则可以完全跳过OCR步骤,直接从文档图像中回答用户问题。图片由作者提供。
基于VLM的OCR技术
为了处理长文档并仍能包含视觉信息,一个有效的选项是利用VLM来执行OCR。传统的OCR技术,例如Tesseract,通常只能直接从文档中提取文本及其边界框。然而,VLM也经过训练来执行OCR任务,并且能够实现更高级的文本提取,例如:
- 提取Markdown格式的文本
- 解释纯粹的视觉信息(例如,如果有一张图纸,VLM可以生成文本来描述这张图纸的内容)
- 补充缺失的信息(例如,如果有一个标注“日期”的方框,后面是空白字段,可以指示VLM OCR提取为“日期 <空>”)
近期,Deepseek发布了一款强大的基于VLM的OCR模型,该模型近期受到了广泛关注和青睐,使得VLM在OCR领域的应用越来越普及。
Markdown格式提取
Markdown格式的提取功能非常强大,因为它允许模型提取带有格式的文本。这使得模型能够:
- 提供清晰的标题和副标题结构
- 准确地表示表格内容
- 突出显示粗体文本
通过这种方式,模型能够提取更具代表性的文本,更准确地反映文档的原始文本内容。如果在此基础上再应用LLM处理这些格式化文本,LLM的性能将远优于处理通过传统OCR提取的纯文本。
LLM在处理Markdown等格式化文本时的表现,优于处理传统OCR提取的纯文本。
解释视觉信息
VLM OCR的另一个用途是解释视觉信息。例如,如果有一张没有任何文字的图纸,传统的OCR由于仅训练用于提取字符,将无法提取任何信息。然而,利用VLM,可以生成文本来解释图像的视觉内容。
想象一个包含以下内容的文档:
这是文档的引言文本
<一张显示埃菲尔铁塔的图片>
这是文档的结论
如果应用传统的OCR技术,例如Tesseract,将得到以下输出:
这是文档的引言文本
这是文档的结论
这显然存在问题,因为它遗漏了关于显示埃菲尔铁塔图片的信息。相比之下,应使用VLM,它将输出类似以下内容:
这是文档的引言文本
<图片>
这张图片描绘了白天的埃菲尔铁塔
</图片>
这是文档的结论
如果LLM处理第一个文本,它当然不知道文档包含埃菲尔铁塔的图片。然而,如果LLM处理通过VLM提取的第二个文本,它在回答关于文档的问题时将自然表现得更好。
补充缺失信息
还可以通过提示VLM在信息缺失时输出相应内容。为了更好地理解这一概念,请看下图:
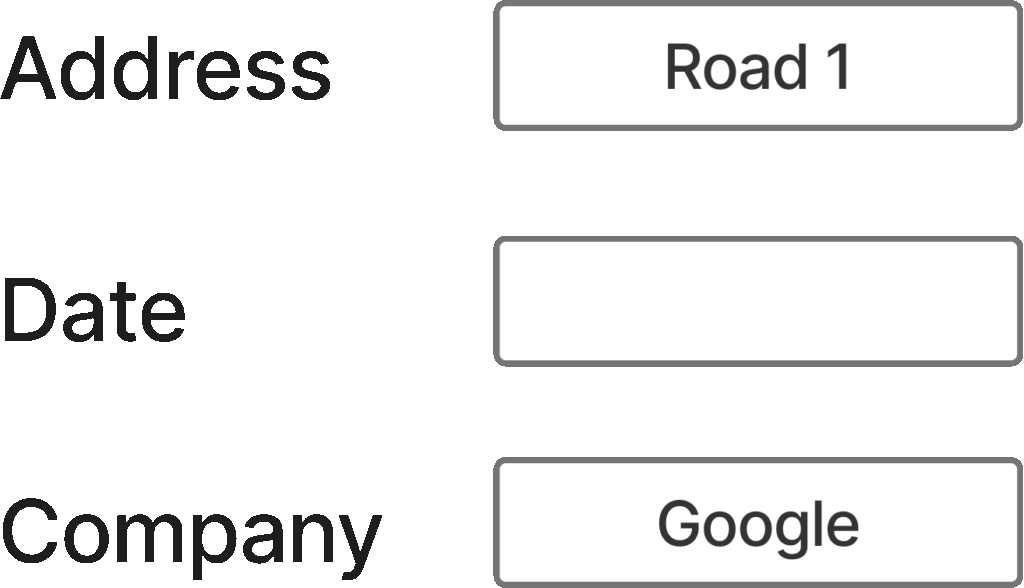
此图展示了文档中信息表示的一个典型示例。图片由作者提供。
如果对这张图片应用传统的OCR,将得到:
地址 1号路
日期
公司 谷歌
然而,如果使用VLM,并且进行适当的指令,它能够输出更具代表性的内容:
地址 1号路
日期 <空>
公司 谷歌
这种输出方式提供了更多信息,因为它告知任何下游模型“日期”字段是空的。如果未能提供此信息,后续将无法判断日期是简单缺失、OCR未能提取,还是其他原因。
然而,基于VLM的OCR在某些方面仍然面临传统OCR的困境,因为它并未直接处理视觉信息。俗话说“一图胜千言”,这在处理文档中的视觉信息时常常成立。确实,VLM可以为图纸提供文本描述作为OCR输出,但这种文本描述永远无法像图纸本身那样具有丰富的描述性。因此,在许多情况下,直接使用VLM处理文档更为优越,这将在接下来的章节中详细讨论。
开源与闭源模型对比
市面上有许多视觉语言模型可供选择。可以关注HuggingFace VLM排行榜,以了解任何新发布的高性能模型。根据该排行榜,如果希望通过API使用闭源模型,Gemini 2.5 Pro或GPT-5是值得推荐的选择。根据经验,这些模型在长文档理解和处理复杂文档方面表现出色。
然而,基于隐私、成本或对应用程序拥有更多控制权等考虑,也可能倾向于使用开源模型。在这种情况下,SenseNova-V6-5-Pro目前位居排行榜首位。尽管尚未亲自尝试此模型,但对Qwen 3 VL的使用经验良好。Qwen团队还发布了一个针对长文档理解的特定指南,值得参考。
VLM在长文档中的应用
本节将讨论将VLM应用于长文档时需要考虑的因素。
处理能力考量
如果运行开源模型,主要考量之一是模型规模与运行时间。这通常需要访问高性能GPU,在大多数情况下至少需要一块A100。幸运的是,A100目前普及率较高,且在许多云服务提供商处成本相对合理(通常每小时1.5至2美元)。然而,还必须考虑可接受的延迟。运行VLM需要大量的处理,必须综合考虑以下因素:
- 处理单个请求可接受的最长时间
- 所需的图像分辨率
- 需要处理的页面数量
例如,如果是一个实时聊天应用,就需要快速处理;但如果只是在后台进行批处理,则可以允许更长的处理时间。
图像分辨率也是一个重要的考量因素。如果需要能够阅读文档中的文本,就需要高分辨率图像,通常超过2048×2048,但这自然也取决于文档内容。例如,包含小文本的详细图纸可能需要更高的分辨率。提高分辨率会显著增加处理时间,这是一个必须认真考虑的因素。应该努力在满足所有任务需求的前提下,采用尽可能低的分辨率。此外,页面数量也需要类似地考量。增加页面数量通常是为了获取文档中的所有信息。然而,通常最重要的信息包含在文档的早期部分,因此,有时仅处理前10页也能解决问题。
基于答案的层级处理
为了降低所需的处理能力,可以尝试从简入手,仅在未能获得预期答案时才逐步升级到更复杂的处理。例如,可以先只处理文档的前10页,看看是否能够妥善解决手头的任务,例如从文档中提取特定信息。只有当无法提取所需信息时,才开始处理更多的页面。同样的理念也可以应用于图像分辨率,从较低分辨率的图像开始,如果需要,再逐步提高分辨率。
这种分层处理方法可以有效降低所需的处理能力,因为大多数任务仅通过处理前10页或使用较低分辨率的图像就能解决。只有在必要时,才继续处理更多图像或更高分辨率的图像。
成本考量
在使用VLM时,成本是一个重要的考量因素。在处理大量文档后发现,与仅使用文本(LLM)相比,使用图像(VLM)通常会导致标记数量增加约10倍。由于在长文档任务中,输入标记数量往往是成本的主要驱动因素,因此使用VLM通常会显著增加成本。值得注意的是,对于OCR任务,输入标记多于输出标记的说法不适用,因为OCR在输出图像中所有文本时自然会产生大量输出标记。
因此,在使用VLM时,最大限度地利用缓存标记至关重要。关于这一主题,在最近关于优化LLM成本和延迟的文章中进行了深入讨论。
总结
本文探讨了如何将视觉语言模型(VLM)应用于超长文档,以应对复杂的文档理解任务。文章讨论了VLM为何如此重要,以及在长文档中使用VLM的方法。例如,VLM可用于实现更复杂的OCR,或直接应用于长文档,但在此过程中需注意处理能力、成本和延迟等方面的考量。VLM的重要性日益凸显,Deepseek OCR的近期发布进一步证明了这一点。因此,文档理解领域的VLM应用是一个值得深入研究的话题,建议学习如何将VLM应用于文档处理应用程序。