

本系列文章致力于为读者提供精选的AI论文推荐。自该系列推出以来,已发布过四期([1], [2], [3], [4]),深受读者欢迎。沉寂一段时间后,通过恢复这一广受好评的系列,无疑是回归写作的最佳方式。
对于初次接触的读者,这是一份充满独到见解与延伸思考的论文清单,旨在帮助大家全面了解AI领域的最新动态。这份列表并非专注于最新的SOTA模型,而是提供对未来几年AI发展趋势的深刻洞察,并回顾过去可能被忽视的重要发现。其核心目标是协助读者批判性地思考AI的现状。
本次共推荐十篇论文,每篇都附有对其核心贡献的简要描述,并明确阐述了其阅读价值。此外,每篇论文还设有一个专门的“延伸阅读”部分,引导读者探索更多相关主题。
回顾2022年的一篇文章,当时曾提出“我们需要的不是更大的模型,而是解决方案”以及“不要期望这里会推荐GPT的胡言乱语”。那时,作者坚信未来仍会持相同观点,认为新的GPT模型不过是更大、略微改进但缺乏突破性的产物。然而,事实证明,ChatGPT自发布以来,确实激发了许多创新解决方案的涌现,无疑是计算机科学领域的一个重要转折点。
需要指出的是,大部分AI研究工作集中在计算机视觉领域,因此可能存在许多关于强化学习、图神经网络、音频处理等方面的优秀论文未被涵盖。欢迎读者分享任何认为值得关注的论文。
现在,让我们深入探索!
#1 DataPerf:以数据为中心的AI基准
Mazumder, Mark, et al. “Dataperf: Benchmarks for data-centric ai development.” arXiv preprint arXiv:2207.10062 (2022).
从2021年到2023年,吴恩达教授(Andrew Ng)持续倡导“以数据为中心的AI”理念:即将研究重心从在静态数据集上改进模型,转向在保持模型静态或基本不变的情况下改进数据集本身。用他的话说,当前以模型为中心的研究哲学忽视了数据的基础性重要作用。
在实践中,增加数据集规模、纠正错误标注的条目以及删除无效输入,往往比增大模型规模、增加层数或延长训练时间,更能有效提升模型性能。
2022年,研究者提出了DataPerf,这是一个旨在促进以数据为中心AI发展的基准测试,涵盖了语音、视觉、调试、数据采集和对抗性问题等任务。这项倡议旨在推广数据感知方法,并努力弥合许多公司的“数据部门”与学术界之间的鸿沟。
阅读理由 1: 大多数专注于特定领域的公司最终都会开发内部数据集。然而,关于如何妥善或更好地进行数据开发的研究却异常稀少,这令人深思。
阅读理由 2: 反思一下:如今有多少论文能带来比现有最佳技术(SOTA)2%的显著提升?为了达到模型准确率2%的提升,您又需要增加多少额外数据呢?
阅读理由 3: 在未来的职业生涯中,或许会不断思考:如果当初不选择方案X,而是投入更多精力收集数据,结果会怎样?
阅读理由 4: 如果读者身处学术界,受限于某个特定的数据集,正努力争取比SOTA提升0.1%的微小进步,请知晓研究的范畴远不止于此。
延伸阅读: 2021年,Deeplearning.AI主办了一场以数据为中心的AI竞赛,其获胜者的方案此处可查。此后,其他学者也对该主题进行了大量研究,例如2023年的《以数据为中心的人工智能:一项综述》(Data-centric Artificial Intelligence: A Survey)。此外,如果您偏爱视频讲座,吴恩达教授在YouTube上也有许多关于该主题的精彩演讲(Andrew Ng on YouTube),大力倡导这一理念。
#2 GPT-3 / LLMs:大语言模型的少样本学习能力
Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877–1901.
这篇发表于NeurIPS的论文向世界介绍了GPT-3。作为OpenAI的第三代模型,它在几乎所有方面都只是一个规模更大的GPT-2,拥有多达116倍的参数量,并在50倍的数据上进行了训练。其最大的发现并非仅仅是“更优异”,而是如何通过精心设计的提示词(prompt)能够显著提升其在多项任务上的表现。
传统的机器学习模型通常被视为可预测的函数:给定相同的输入,它们总是产生相同的输出。然而,当前的大型语言模型(LLMs)却能以多种不同方式提出并回答相同的问题——措辞在其中扮演着至关重要的角色。
阅读理由 1: 此前,我们讨论了在演进数据集的同时保持模型静态。而对于大型语言模型(LLMs),我们可以通过演进所提出的问题来实现性能提升。
阅读理由 2: GPT-3的问世催生了提示工程(prompt engineering)这一全新领域。此后,我们看到了许多研究者提出了如思维链(Chain-of-Thought, CoT)和检索增强生成(Retrieval-Augmented-Generation, RAG)等技术。
阅读理由 3: 掌握如何有效进行提示比了解如何训练或微调LLMs更为重要。尽管有人认为提示工程已过时,但这种观点似乎难以成立。试问:当您与上司、母亲或朋友交流时,是否会使用相同的措辞方式来表达请求?
阅读理由 4: 当Transformer模型首次出现时,大多数研究都集中在其训练/推理速度和规模上。而提示工程在自然语言处理领域是一个真正的新兴课题。
阅读理由 5: 有趣的是,这篇论文并没有真正提出任何新算法,它仅仅是一个观察性研究,却获得了6万次引用。
延伸阅读: 提示工程让人们联想到集成学习模型。过去,我们可能不会重复提示单个模型,而是训练多个较小的模型并聚合它们的输出。如今已有近三十年历史的AdaBoost论文是该领域的经典之作,阅读它能让您回溯到词嵌入概念出现之前。快进到2016年,XGBoost则是一个现代经典,目前已升级到v3版本。
#3 Flash Attention:快速且内存高效的精确注意力机制
Dao, Tri, et al. “FlashAttention: Fast and memory-efficient exact attention with io-awareness.” Advances in Neural Information Processing Systems 35 (2022): 16344–16359.
自2017年划时代的论文《Attention is All You Need》引入Transformer架构和注意力机制以来,许多研究团队致力于寻找一种比原始二次复杂度公式更快、更具扩展性的替代方案。尽管提出了多种方法,但至今没有一种真正超越原版工作,成为明确的继任者。
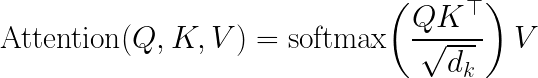
原始的注意力机制公式。Softmax项表示每个token对每个查询的重要性(对于N个token,有N²个注意力分数)。“变换”(Transformer名称的由来)是这个N²注意力图与N维V向量之间的乘法(很像旋转矩阵“变换”3D向量)。
在这项工作中,研究者并没有提出新的公式或对原始公式进行巧妙近似。相反,他们提出了一种快速的GPU实现,能够更好地利用复杂且多层次的GPU内存结构。这种方法显著提升了速度,同时对原始机制几乎没有任何性能上的折损。
阅读理由 1: 许多研究论文因仅仅是新的实现或“新颖性不足”而被拒绝。然而,有时这正是我们所需要的。
阅读理由 2: 研究实验室渴望成为“新注意力机制”的焦点,以至于任何新的注意力机制都很难获得足够的关注。而在这项工作中,研究者仅对已有的有效方案进行了改进。
阅读理由 3: 回顾来看,ResNet在当年对于卷积神经网络(CNNs)来说是开创性的,它提出了残差块。在随后的几年里,许多人提出了对其的增强方案,改变了残差块的理念。尽管付出了所有这些努力,大多数人最终还是坚持了最初的想法。在AI这样竞争激烈的研究领域,对于那些有众多“继任者”的提议,最好保持谨慎。
延伸阅读: 读者可以查阅Sik-Ho Tsang在Medium上整理的论文列表。每个部分都揭示了多年来各个领域的主要思想。令人遗憾的是,其中许多论文曾经看似开创性,如今却被完全遗忘。回到注意力机制,截至2025年,最受关注的注意力替代方案候选者是DeepSeek团队的稀疏注意力(Sparse Attention)。
#4 使用Posit训练神经网络
Raposo, Gonçalo, Pedro Tomás, and Nuno Roma. “Positnn: Training deep neural networks with mixed low-precision posit.” ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.
转向硬件和底层优化领域,AI训练中一些最重要(但却最不引人注目)的进展与浮点数处理息息相关。我们经历了从普通浮点数(floats)到半精度(halfs),再到8位甚至4位浮点数(FP4)的演变。如今驱动大型语言模型(LLMs)的算力,已是早期GPU的八倍有余。
未来的数字格式发展与矩阵乘法硬件密切相关。然而,这个领域远不止于简单地将位深度减半。例如,这篇论文探索了一种全新的数字格式——Posits,作为传统IEEE-754浮点数的潜在替代品。读者能否想象一个没有浮点数的未来?
阅读理由 1: 尽管新算法的广泛采用需要时间,但硬件每年都在持续改进。所有技术进步都会随着硬件的潮水而上涨。
阅读理由 2: 值得思考的是,如果没有过去十年GPU的诸多改进,我们今天在AI领域能走多远。举例来说,2012年AlexNet的作者们使用两块高端GTX 580 GPU,总计3 TFLOPs的算力,打破了所有ImageNet记录。而如今,一块中端GPU,例如RTX 5060,就能达到约19 TFLOPs的算力,是当年的6倍。
阅读理由 3: 有些技术如此普遍,以至于我们认为它们是理所当然的。然而,所有事物都可以且应该被改进;我们无需固守浮点数(甚至神经网络本身)。
延伸阅读: 既然提到了硬件,也值得探讨一下编程语言。如果您一直关注新闻,Python团队(尤其是Python的创始人)正专注于优化Python。然而,如今的“优化”似乎成了用Rust重写代码的代名词。最后,曾有一段时间人们对Mojo这款专注于AI/速度的Python超集寄予厚望,但如今已鲜有人提及。
#5 AdderNet:深度学习中真的需要乘法吗?
Chen, Hanting, et al. “AdderNet: Do we really need multiplications in deep learning?.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
如果我们可以完全不进行矩阵乘法呢?这篇论文另辟蹊径,展示了在没有矩阵乘法的情况下构建高效神经网络的可能性。其核心思想是用计算输入与滑动滤波器之间的L1差值来替代传统的卷积运算。
人们可以将这篇论文视为“平行宇宙”中的神经网络。在某个平行世界里,神经网络基于加法运算演进,而在此过程中,有人提出了一个基于乘法的模型;然而,由于所有工具和硬件都已深度优化大规模矩阵加减运算,因此该模型并未获得广泛关注。
阅读理由 1: 我们很容易忘记,除了卷积神经网络(CNNs)和Transformer,仍然有许多我们尚未发现的其他算法。这篇论文展示了基于加法的神经网络是可行的,这本身就非常酷。
阅读理由 2: 我们的许多硬件和云基础设施都是为矩阵乘法和神经网络量身定制的。新的模型是否仍能与之竞争?非神经网络模型是否有可能卷土重来?
延伸阅读: 许多读者可能不熟悉在神经网络占据主导地位之前存在的技术。大多数人可能知道诸如线性回归、决策树和XGBoost等经典算法。在神经网络流行之前,支持向量机(Support Vector Machines, SVMs)曾风靡一时。如今已有一段时间未曾见到它们的身影。在这方面,一篇值得一读的有趣论文是《深度学习并非万能》(Deep Learning is Not All You Need)。
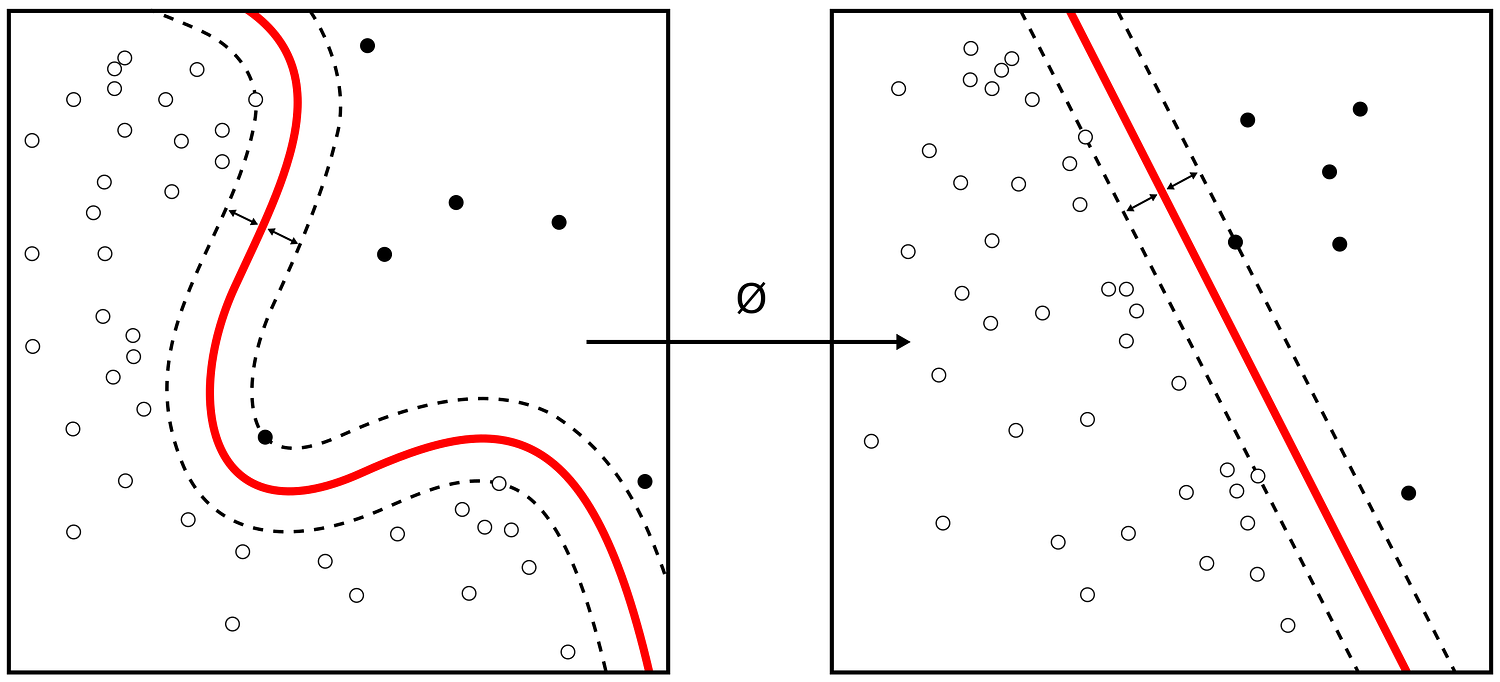
支持向量机通过找到最佳分隔线来分离两组点。通过使用核技巧(Kernel Trick),这些点被映射到更高维空间,从而可能找到更好的分离超平面,在保持线性公式的同时实现非线性决策边界。这是一个非常巧妙的解决方案,值得深入学习。来源。
#6 内插与外推之争
Balestriero, Randall, Jerome Pesenti, and Yann LeCun. “Learning in high dimension always amounts to extrapolation.” arXiv preprint arXiv:2110.09485 (2021).
曾几何时,一些人认为AI领域的知名学者都是富有远见卓识的预言家,或者对该领域未来发展有着极好的判断。然而,这篇论文及其随后的争论改变了这种看法。
早在2021年,Yann LeCun就推动了关于“内插与外推”的讨论,声称在高维空间中,如同所有神经网络一样,我们所称的“学习”实际上是数据外推。论文发表后,许多知名学者纷纷加入讨论,有些人认为这是无稽之谈,有些人坚持是内插,还有一些人则支持外推的观点。
如果读者从未听说过这场讨论,那恰好说明了其最终的“无意义性”。据观察(如果读者有不同看法,欢迎交流),这场争论并未促使任何公司改变发展方向,也未催生出新的“外推感知”模型,更没有引发任何相关的训练技术创新。它兴起又消逝。
阅读理由 1: 坦白说,读者可以跳过这一篇。提出它只是为了让讨论更完整。
阅读理由 2: 从纯粹的学术角度看,这被认为是对学习理论的一个有趣解读,而学习理论本身确实是一个引人入胜的课题。
延伸阅读: Yoshua Bengio、Geoffrey Hinton和Yann LeCun因其在深度学习基础方面的开创性工作,于2018年被授予图灵奖。回顾2023年前后,LeCun专注于自监督学习,Hinton关注胶囊网络(Capsule Networks),而Bengio则研究生成流网络(Generative Flow Networks)。到了2025年末,LeCun转向了世界模型(world models),而Hinton和Bengio则将重心放在AI安全上。如果读者正在重新评估自己的学术选择,请记住,即使是这些所谓的“教父级人物”也会调整研究方向。
#7 DINOv3 / 视觉基础模型
Siméoni, Oriane, et al. “DINOv3.” arXiv preprint arXiv:2508.10104 (2025).
尽管语言处理领域已经发展出适用于各种任务的通用大型模型(即基础模型),但图像处理领域仍在努力实现这一目标。DINOv3这篇论文展示了DINO模型的最新迭代,它是一个旨在成为视觉领域基础的自监督图像模型。
阅读理由 1: 相较于文本领域,自监督预训练在其他问题领域(尤其是完全在问题域内进行,而非借助文本描述)仍处于相对演进的阶段。
阅读理由 2: 即使工作主要涉及大型语言模型,拓展阅读范围也至关重要。
阅读理由 3: 语言模型在实现通用人工智能(AGI)的道路上能走多远是有限的。对于类人智能而言,视觉是至关重要的。
延伸阅读: 继续讨论视觉话题,了解YOLO和Segment-Anything模型(SAM)非常重要。前者是目标检测领域的经典(但也拥有适用于其他问题的版本),后者则专注于图像分割。至于图像生成,有趣的是,几年前我们都在谈论GANs(生成对抗网络),而如今许多人可能从未听说过它。曾有文章为GAN论文整理过类似的列表。
#8 小型语言模型是代理AI的未来
Belcak, Peter, et al. “Small Language Models are the Future of Agentic AI.” arXiv preprint arXiv:2506.02153 (2025).
“生成式AI”领域正迅速被重新定义为“代理式AI”。随着人们试图从中获利,大量风险投资被投入到运行庞大模型中。在这篇论文中,研究者提出,小型语言模型(在其定义中参数量小于10亿)是代理式AI未来发展的方向。
更具体地说,他们认为代理解决方案中执行的大多数子任务都是重复的、定义明确且非对话性的。因此,大型语言模型(LLMs)在这些场景下显得有些“大材小用”。如果结合微调,小型语言模型(SLMs)可以轻松成为专业化的代理,而LLMs则更擅长开放式任务。
阅读理由 1: 今天我们称之为“大型”的语言模型,明天可能就成为“小型”模型。了解小型语言模型有助于为未来做好准备。
阅读理由 2: 许多人声称当今的AI在很大程度上依赖于风险投资的补贴。在不久的将来,AI的成本可能会大幅上升。使用小型语言模型可能是许多企业的唯一选择。
阅读理由 3: 这篇论文非常易读。事实上,这可能是少有的如此明确阐述论点的论文。
延伸阅读: 小型模型是边缘AI/低延迟执行的唯一选择。当将AI应用于视频流时,模型和后处理需要在30帧/秒的视频流中于33毫秒内完成执行。在这种情况下,无法往返云端或批量处理帧。如今,有多种工具可用于在有限硬件上进行快速推理,例如英特尔的OpenVINO、NVIDIA的Tensor-RT,或TensorFlow-Lite。
#9 彩票假设(2019)
Frankle, Jonathan, and Michael Carbin.“The lottery ticket hypothesis: Finding sparse, trainable neural networks.”arXiv preprint arXiv:1803.03635 (2018).
作为对小型模型的后续讨论,一些研究者指出,我们很可能没有充分利用神经网络的参数。这就像“人类只使用了大脑的10%”这一说法应用于神经网络。在这类文献中,“彩票假设”无疑是引人入胜的论文之一。
Frankle等人发现,如果按照以下步骤操作:(1) 训练一个大型网络,(2) 剪枝所有低值的权重,(3) 将剪枝后的网络回溯到未经训练的初始状态,然后 (4) 重新训练;将获得一个性能更优的网络。换句话说,训练过程揭示了一个子网络,其初始随机参数恰好与解决问题相匹配——其余的都是“噪声”。通过仅利用这个子网络,我们甚至可以超越原始网络的性能。与基本的网络剪枝不同,这种方法能够提升结果。
阅读理由 #1: 我们习惯于认为“大模型更好但速度慢”,而“小模型性能差但速度快”。或许我们正是那些坚持使用大模型的“笨拙者”。
阅读理由 #2: 一个悬而未决的问题是,我们的参数被利用的程度有多低。同样,我们如何才能充分发挥权重的潜力?甚至,是否有可能衡量神经网络的学习潜力?
阅读理由 #3: 在训练之前,有多少人曾关注过模型参数的初始化方式?
延伸阅读: 尽管这篇论文发表于2018年,但关于该假设有一份2024年的综述。与之形成对比的是,《过参数化在机器学习中的作用——优点、缺点与不足(2024)》则讨论了过参数化才是真正驱动神经网络的因素。在实践层面,这份综述涵盖了知识蒸馏的主题,即利用一个大型网络来训练一个小型网络,使其性能尽可能接近大型网络。
#10 AlexNet(2012)
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton.“Imagenet classification with deep convolutional neural networks.”Advances in neural information processing systems. 2012.
如今我们所见的神经网络内容,其真正爆发性发展仅仅始于13年前,这令人难以置信。在此之前,神经网络在某种程度上介于一个笑话和一项失败的承诺之间。如果想要一个好的模型,人们通常会使用支持向量机(SVMs)或一堆手工设计的技巧。
2012年,研究者提出使用GPU训练一个大型卷积神经网络(CNN)来解决ImageNet挑战。出乎所有人意料的是,他们以约15%的Top-5错误率夺得第一名,而第二名使用最先进的图像处理技术,错误率高达约26%。
阅读理由 #1: 尽管我们大多数人都了解AlexNet的历史重要性,但并非所有人都清楚我们今天使用的哪些技术在当年就已经存在。读者可能会惊讶于论文中引入的许多概念(如Dropout和ReLU)是多么的熟悉。
阅读理由 #2: AlexNet提出的网络拥有6000万个权重,这在2012年的标准看来是“疯狂”的。而如今,万亿参数的大型语言模型(LLMs)已指日可待。阅读AlexNet论文能让我们对自那时以来的技术发展获得深刻洞察。
延伸阅读: 追溯ImageNet冠军的历史,读者可以阅读ZF Net、VGG、Inception-v1和ResNet的论文。其中ResNet实现了超人类的性能,解决了该挑战。此后,其他竞赛吸引了研究者的注意力。如今,ImageNet主要用于验证激进的新架构。
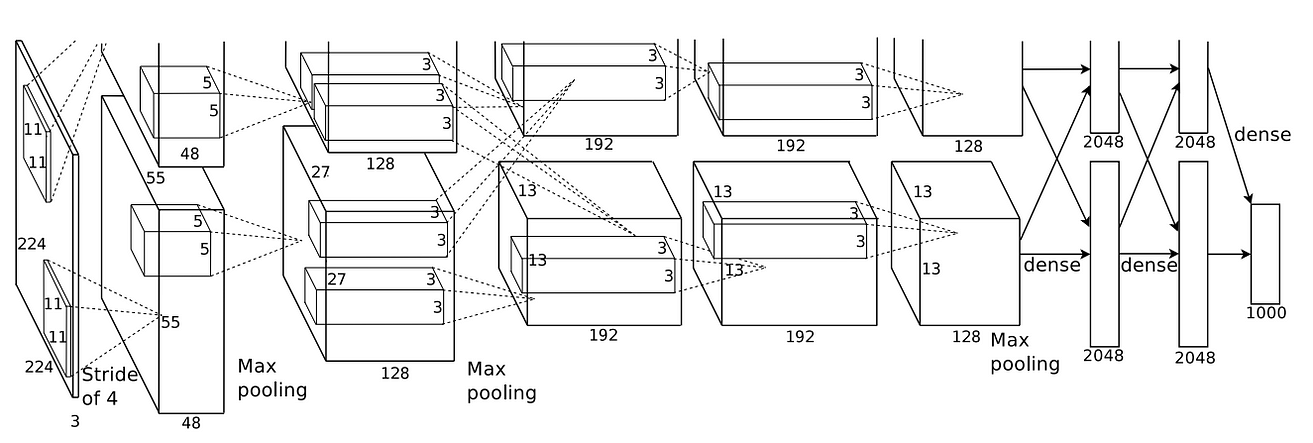
AlexNet结构图的原始描绘。上半部分和下半部分分别由GPU 1和GPU 2处理,是模型并行化的早期形式。来源:AlexNet论文





{kind=link}