非参数模型并非总能获得应有的重视。诸如 k-近邻 (k-NN) 和核密度估计器等方法有时被简单地视为过时或过于基础,但其真正的优势在于能够直接从数据中估计条件关系,而无需强加固定的函数形式。这种固有的灵活性使得它们具有良好的可解释性和强大的功能,尤其是在数据量有限或需要融入领域知识的场景中。
本文将探讨非参数方法如何为条件推断提供一个统一的基础,涵盖了回归、分类乃至合成数据生成等多个方面。以经典的 Iris 鸢尾花数据集为例,文章将演示如何实际估计条件分布,以及这些方法如何支持广泛的数据科学任务。
估计条件分布
核心思想非常直接:研究人员并非仅仅预测一个单一的数值或类别标签,而是估计在给定某些信息的情况下,一个变量所有可能的输出范围。换句话说,其关注点不仅仅是期望值,而是捕获在相似条件下可能出现的结果的完整概率分布。
为实现这一点,研究人员会关注那些与目标情境相近的数据点,即特征空间中条件变量接近查询点的数据。每个数据点都为估计值做出贡献,其影响力根据相似性进行加权:越接近查询点的数据点,其影响力越大;而较远的数据点,其权重则相应减小。通过聚合这些加权贡献,可以得到一个平滑的、数据驱动的估计,从而揭示目标变量在不同上下文中的表现。
这种方法使得研究能够超越简单的点预测,从而更深入地理解数据中的不确定性、变异性和内在结构。
连续目标:条件密度估计
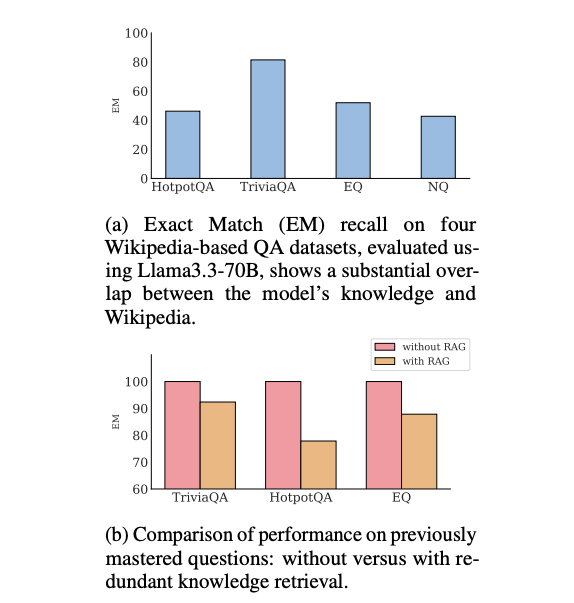
为了具体说明,可以从 Iris 鸢尾花数据集中选取两个连续变量:萼片长度 (x 1) 作为条件变量,花瓣长度 (y) 作为目标变量。对于 x 1 的每个值,可以考察其附近的数据点,并通过在这些点的 y 值上放置小的加权核来形成密度,权重反映了萼片长度上的接近程度。最终结果便是条件密度 p(y ∣ x 1) 的平滑估计。
图1展示了由此产生的条件分布。在 x 1 的每个值处,通过彩色图的垂直切片代表了 p(y ∣ x 1)。通过这个分布,可以计算均值或众数等统计量;也可以从中抽取随机值,这是合成数据生成的关键一步。图中还展示了众数回归曲线,该曲线穿过这些条件分布的峰值。与传统的最小二乘拟合不同,这条曲线直接来源于局部条件分布,能够自然地适应非线性、偏斜甚至多峰模式。
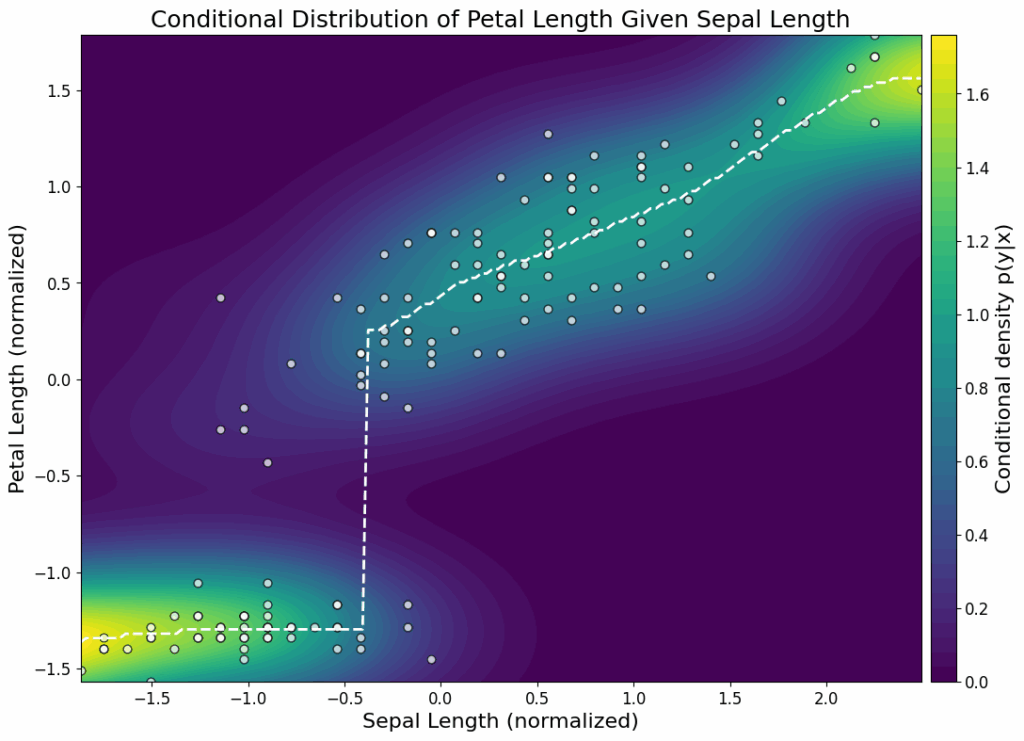
图1. Iris 数据集中,给定萼片长度条件下花瓣长度的条件分布和众数回归曲线。
如果存在多个条件变量怎么办?例如,假设需要估计 p(y∣ x 1, x 2)。
我们可以不将 (x 1,x 2) 视为单一的联合输入并应用二维核,而是按序构建这个分布:
p(y∣ x 1, x 2) ∝ p(y∣ x 2) p(_x_ 2∣ x 1),
这实际上假定了,一旦 x 2 已知,y 主要依赖于 x 2,而非直接依赖于 x 1。这种逐步方法能够渐进地捕获条件结构:首先建模预测变量之间的依赖关系,然后将这些依赖关系与目标变量关联起来。
相似性权重始终在相关条件变量的子空间中计算。例如,如果需要估计 p(_x_ 3∣ x 1, x 2),相似性将通过 x 1 和 x 2 来确定。这确保了条件分布能够精确地适应所选的预测变量。
分类目标:条件类别概率
当目标变量是分类变量时,我们也可以应用相同的条件估计原则。例如,假设需要根据鸢尾花的萼片长度 (x 1) 和花瓣长度 (x 2) 来预测其物种 y。对于每个类别 y = c,研究人员可以使用序贯估计来估计联合分布 p(x 1, x 2 | y = c)。然后,这些联合分布通过贝叶斯定理进行组合,以获得条件概率 p(y = c ∣ x 1, x 2),这些概率可用于分类或随机抽样。
图2中的面板1-3展示了每种物种的估计联合分布。基于这些分布,可以通过选择最可能出现物种进行分类,或根据估计的概率生成随机样本。第四个面板显示了预测的类别边界,这些边界呈现出平滑而非突兀的特征,反映了物种重叠区域的不确定性。
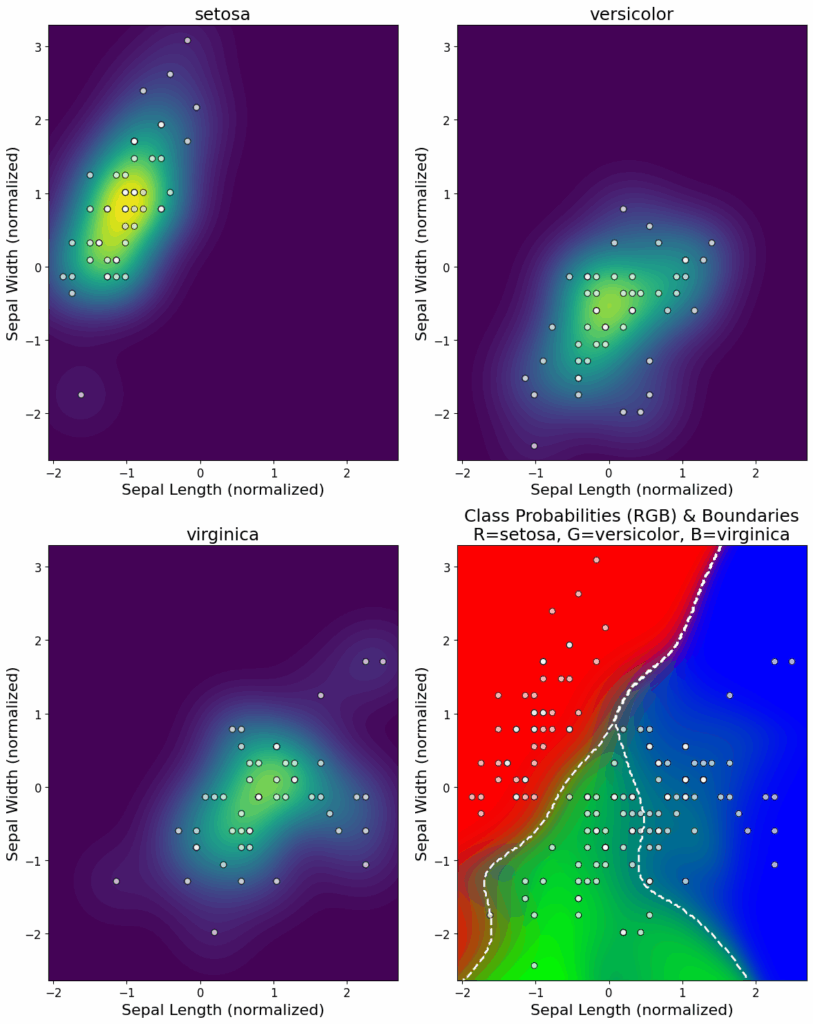
图2. Iris 数据集的类别概率图谱。面板1-3展示了山鸢尾 (Setosa)、变色鸢尾 (Versicolor) 和维吉尼亚鸢尾 (Virginica) 各物种的估计联合分布。面板4显示了预测的类别边界。
合成数据生成
非参数条件分布的功能远不止于支持回归或分类。它们还能够生成全新的数据集,同时保留原始数据的结构。在序贯方法中,研究人员根据每个变量前面的变量对其进行建模,然后从这些估计的条件分布中抽取数值来构建合成记录。重复这个过程,就能得到一个完整的合成数据集,该数据集能够保持所有属性之间的关系。
具体步骤如下:
- 从一个变量开始,并从其边际分布中进行抽样。
- 对于每个后续变量,在给定已抽样变量的条件下,估计其条件分布。
- 从这个条件分布中抽取一个值。
- 重复上述步骤,直到所有变量都已抽样,形成一个完整的合成记录。
图3展示了原始(左侧)和合成(右侧)Iris 鸢尾花数据集在原始测量空间中的情况。为了适应3D可视化,仅显示了四个连续属性中的三个。合成数据集与原始数据集的模式和关系高度吻合,这表明非参数条件分布能够有效捕捉多元结构。
图3. 原始与合成 Iris 数据在原始空间中的表示(显示了三个连续属性)。
尽管上述方法以小型、低维的 Iris 数据集为例进行阐述,但这种非参数框架能够自然地扩展到更大、更复杂的数据集,包括那些混合了数值型和分类变量的数据。通过逐步估计条件分布,它能够捕获许多特征之间丰富的关系,使其在现代数据科学任务中具有广泛的实用性。
处理混合属性
到目前为止,文章中的示例主要考虑了使用连续条件变量进行条件估计,尽管目标变量可以是连续的或分类的。在这些情况下,欧几里得距离作为相似性度量表现良好。然而,在实际应用中,常常需要对混合属性进行条件处理,这就需要一个合适的距离度量。对于这类数据集,可以使用如 Gower 距离等度量。只要有适当的相似性度量,非参数框架就能无缝应用于异构数据,保持其估计条件分布和生成真实合成样本的能力。
序贯方法的优势
序贯估计的另一种替代方案是,对所有条件变量的分布进行联合建模。这可以通过以数据点为中心的多维核函数来实现,或者通过混合模型(例如使用 N 个高斯分布来表示分布,其中 N 远小于数据点数量)来实现。虽然这种方法在低维数据中有效(例如适用于 Iris 数据集),但随着变量数量的增加,特别是当预测变量包含数值型和分类型时,它会迅速变得数据密集、计算成本高昂且稀疏。序贯方法通过逐步建模依赖关系,并且仅在相关子空间中计算相似性,从而规避了这些问题,显著提高了效率、可伸缩性和可解释性。
总结
非参数方法具有灵活性、可解释性和高效性,使其成为估计条件分布和生成合成数据的理想选择。通过关注条件空间中的局部邻域,它们能够直接从数据中捕获复杂的依赖关系,而无需依赖严格的参数假设。此外,还可以巧妙地融入领域知识,例如调整相似性度量或加权方案,以强调重要特征或已知关系。这使得模型在主要由数据驱动的同时,也能受到先验洞察的指导,从而产生更切合实际的结果。