在合成数据生成过程中,通常会为真实(或称“观测”)数据构建一个模型,然后利用该模型生成合成数据。这些观测数据往往来源于真实世界的经验,例如对鸢尾花物理特征的测量,或关于个人信用违约或患有某种疾病的详细信息。观测数据被认为是来自某个“父分布”——即真实的基础分布,观测数据只是该分布的一个随机样本。当然,这个父分布是未知的,需要通过模型进行估计。
然而,如果构建的模型能够生成被视为来自同一父分布的随机样本的合成数据,那么就取得了巨大成功:合成数据将拥有与观测数据相同的统计特性和模式(忠实度);在回归或分类等任务中,它将同样有用(实用性);而且,由于它是一个随机样本,因此不会存在识别观测数据的风险(隐私性)。但如何判断是否已经实现了这一难以捉摸的目标呢?
本系列文章的第一部分将通过一些简单的实验,以更好地理解问题并引出解决方案。第二部分将评估多种合成数据生成器在精选的知名数据集上的表现。
第一部分 — 简单实验
请思考以下两个数据集,并尝试回答这个问题:
这两个数据集是来自同一父分布的随机样本,还是其中一个通过施加微小的随机扰动从另一个派生而来的?
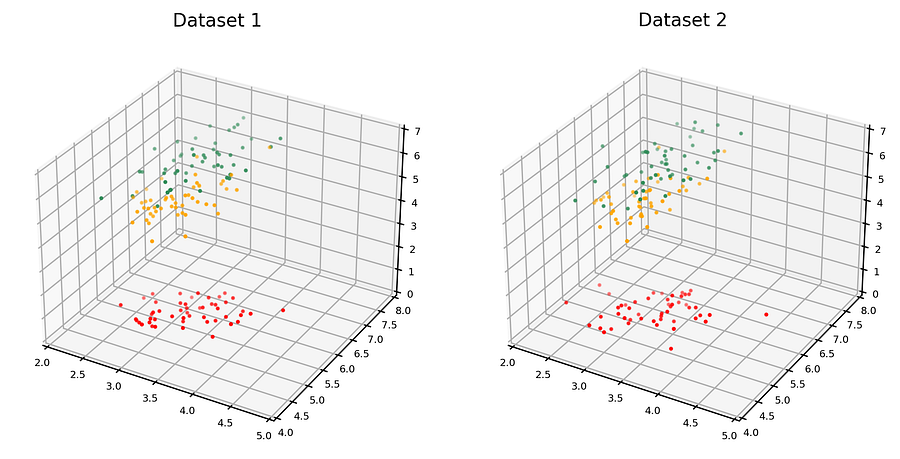
图1. 两个数据集。这两个数据集是来自同一父分布的随机样本,还是其中一个通过微小的随机扰动从另一个派生而来的?[图片由作者提供]
这两个数据集明显展现出相似的统计特性,例如边际分布和协方差。在一个分类任务中,如果分类器在一个数据集上训练,并在另一个数据集上进行测试,它们也会表现出相似的性能。
但是,如果将两个数据集的数据点绘制在同一张图上,情况又如何呢?如果数据集是来自同一父分布的随机样本,人们会直观地预期一个数据集的点会与另一个数据集的点交错分布,使得平均而言,一个集合中的点与其在同一集合中的最近邻点的距离(或“相似度”)与它们在另一个集合中的最近邻点的距离相同。然而,如果一个数据集是另一个数据集的轻微随机扰动,那么一个集合中的点将比它们在同一集合中的最近邻点更相似于它们在另一个集合中的最近邻点。这引出了以下的测试方法。
最大相似度测试
针对每个数据集,计算每个实例与其在同一数据集中的最近邻实例之间的相似度。这些被称为“最大集合内相似度”。如果数据集具有相同的分布特征,那么每个数据集的集合内相似度分布应该相似。接下来,计算一个数据集的每个实例与其在另一个数据集中的最近邻实例之间的相似度,这些被称为“最大跨集合相似度”。如果最大跨集合相似度的分布与最大集合内相似度的分布相同,那么这两个数据集就可以被视为来自同一父分布的随机样本。为了使测试有效,每个数据集应包含相同数量的样本。
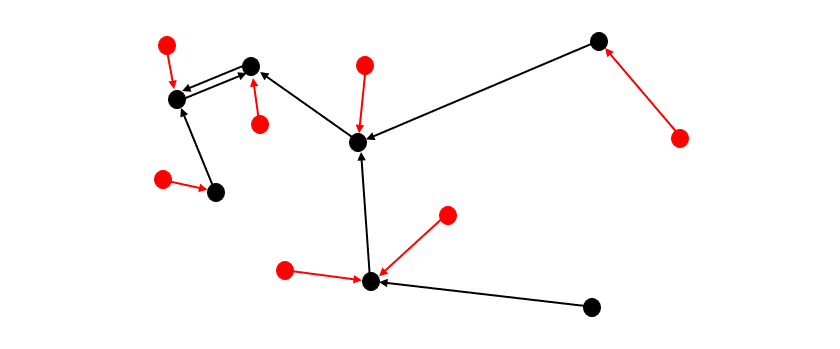
图2. 两个数据集:一个红色,一个黑色。黑色箭头表示每个黑点(尾部)与其最近的(或“最相似的”)黑点邻居(头部)之间的关系——这些对之间的相似度是黑色数据集的“最大集合内相似度”。红色箭头表示每个红点(尾部)与其最近的黑点邻居(头部)之间的关系——这些对之间的相似度是“最大跨集合相似度”。[图片由作者提供]
由于本文所处理的数据集都包含数值变量和类别变量的混合,因此需要一个能够适应这种情况的相似度度量。这里采用的是 Gower 相似度¹。
下面的表格和直方图展示了数据集1和数据集2的最大集合内相似度和最大跨集合相似度的均值和分布。

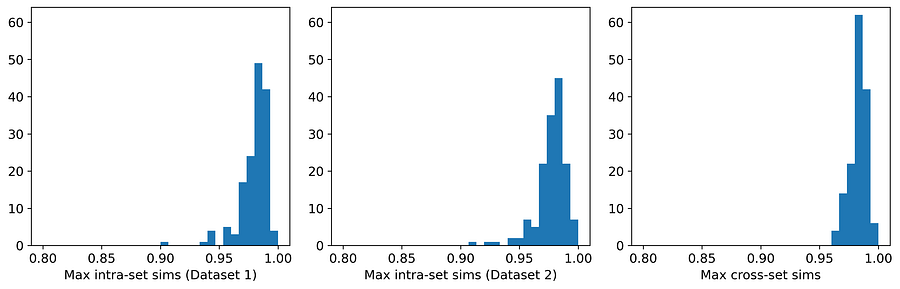
图3. 数据集1和数据集2的最大集合内与跨集合相似度分布。[图片由作者提供]
平均而言,一个数据集中的实例与其在另一个数据集中的最近邻实例的相似度,比它们与其在同一数据集中的最近邻实例的相似度更高。这表明这些数据集更可能是彼此的扰动,而非来自同一父分布的随机样本。事实上,它们确实是扰动!数据集1是由高斯混合模型生成的;数据集2则是通过从数据集1中选择(不放回)一个实例并施加微小的随机扰动而生成的。
最终,最大相似度测试将被用于比较合成数据集与观测数据集。合成数据点与观测数据点过于接近的最大风险是隐私泄露;即,能够通过合成数据集中的点来识别观测数据集中的点。值得注意的是,即使平均最大跨集合相似度仅比平均最大集合内相似度大0.3%,隐私泄露的风险也依然存在。
建模与合成
为了结束故事的第一部分,接下来将为一个数据集创建模型并使用该模型生成合成数据。随后,可以使用最大相似度测试来比较合成数据集和观测数据集。
图4左侧的数据集就是上文中的数据集1。右侧的数据集(数据集3)是合成数据集。(尽管分布被估计为高斯混合,但这并非此处重点)。
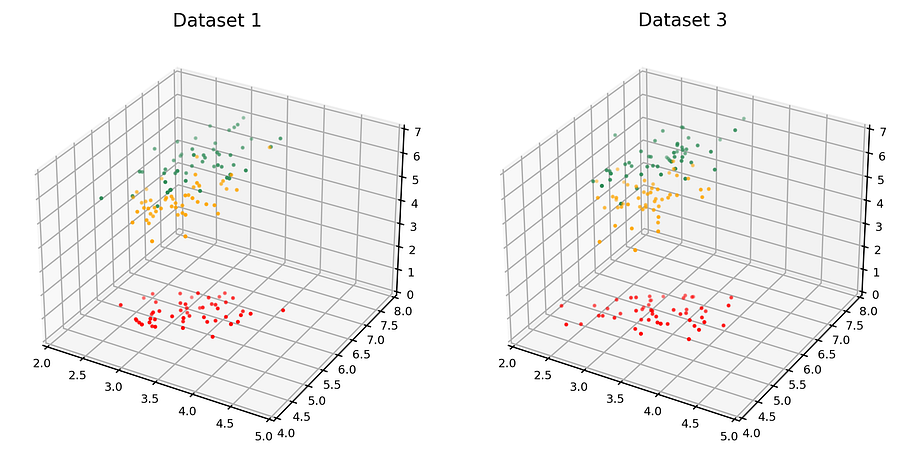
图4. 观测数据集(左)和合成数据集(右)。[图片由作者提供]
以下是平均相似度和直方图:

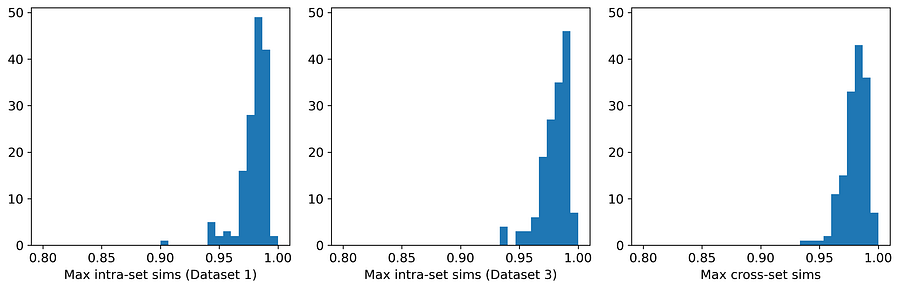
图5. 数据集1和数据集3的最大集合内与跨集合相似度分布。[图片由作者提供]
这三个平均值在三位有效数字内完全相同,并且三个直方图也非常相似。因此,根据最大相似度测试,这两个数据集都可以合理地被认为是来自同一父分布的随机样本。这次合成数据生成实验取得了成功,实现了忠实度、实用性和隐私性的三丰收。
第一部分实验中用于生成数据集、图表和直方图的 Python 代码已在 GitHub 仓库 提供。
第二部分 — 真实数据集,真实生成器
第一部分中使用的数据集较为简单,可以很容易地用高斯混合模型进行建模。然而,大多数真实世界的数据集要复杂得多。在故事的这一部分,将对一些流行的真实世界数据集应用几种合成数据生成器。主要关注点是比较观测数据集和合成数据集之间最大相似度的分布,以理解它们在多大程度上可以被视为来自同一父分布的随机样本。
这六个数据集均来自 UCI 仓库²,是几十年来在机器学习文献中广泛使用的流行数据集。它们都是混合类型数据集,之所以选择它们,是因为它们在类别和数值特征的平衡方面有所不同。
所选的六种生成器代表了合成数据生成领域的主要方法:基于 Copula、基于 GAN、基于 VAE 以及使用顺序插补的方法。CopulaGAN³、GaussianCopula、CTGAN³ 和 TVAE³ 均可从 Synthetic Data Vault 库⁴ 获取;synthpop⁵ 作为开源 R 包提供;而“UNCRi”指的是在 Unified Numeric/Categorical Representation and Inference (UNCRi) 框架⁶ 下开发的合成数据生成工具。所有生成器均使用其默认设置。
表1显示了每个生成器应用于每个数据集时,平均最大集合内相似度和最大跨集合相似度。红色高亮的条目表示隐私已受到损害(即,平均最大跨集合相似度超过了观测数据上的平均最大集合内相似度)。绿色高亮的条目表示具有最高平均最大跨集合相似度(不包括红色高亮的条目)。最后一列显示了执行“在合成数据上训练,在真实数据上测试”(TSTR)测试的结果,其中分类器或回归器在合成样本上训练,并在真实(观测)样本上测试。Boston Housing 数据集是一个回归任务,报告的是平均绝对误差(MAE);所有其他任务都是分类任务,报告的值是 ROC 曲线下面积(AUC)。
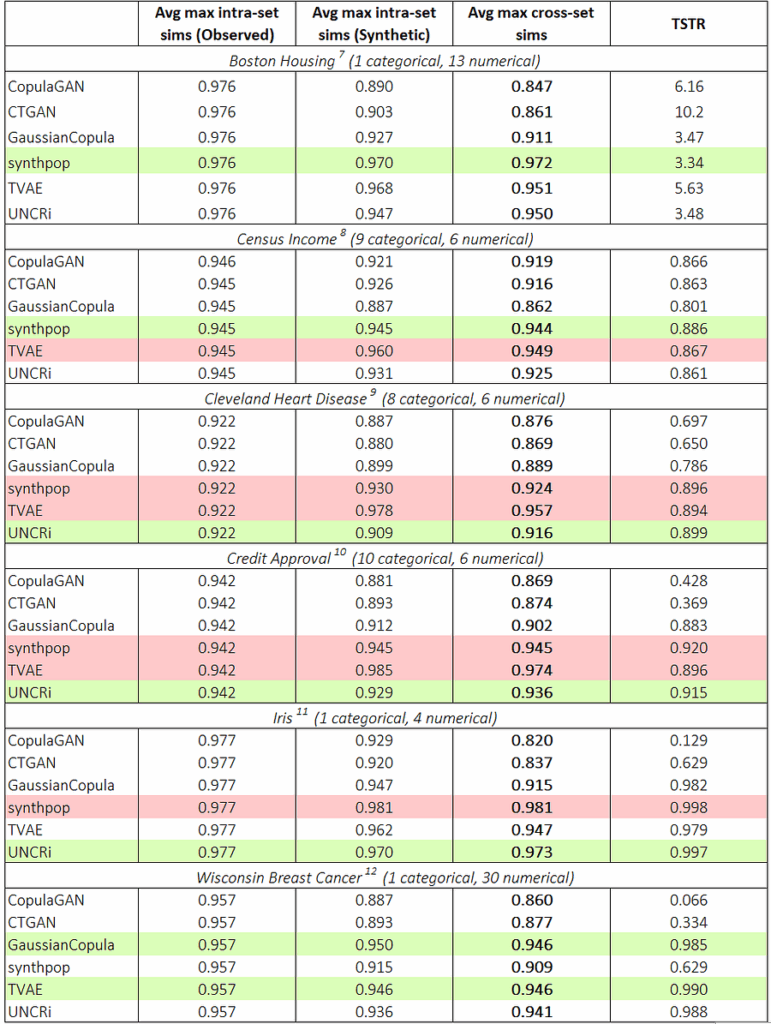
表1. 六种生成器在六个数据集上的平均最大相似度和TSTR结果。TSTR的值对于Boston Housing是MAE,对于所有其他数据集是AUC。[图片由作者提供]
下图显示了每个数据集的最大集合内相似度和最大跨集合相似度的分布,这些分布对应于在该数据集上获得最高平均最大跨集合相似度(不包括上述红色高亮部分)的生成器。
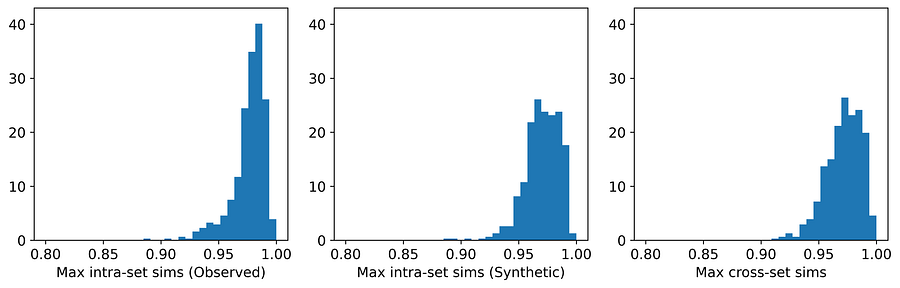
图6. synthpop 在 Boston Housing 数据集上的最大相似度分布。[图片由作者提供]
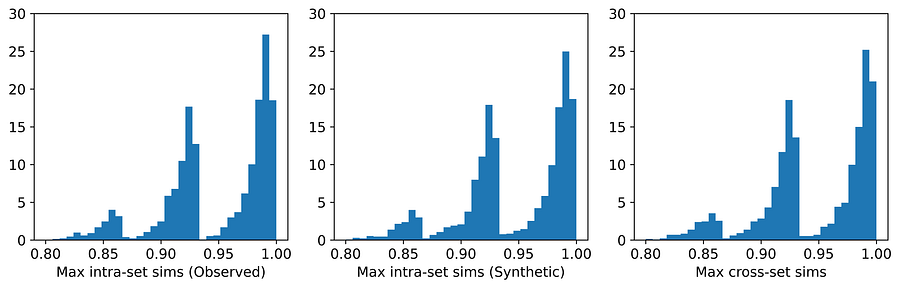
图7. synthpop 在 Census Income 数据集上的最大相似度分布。[图片由作者提供]
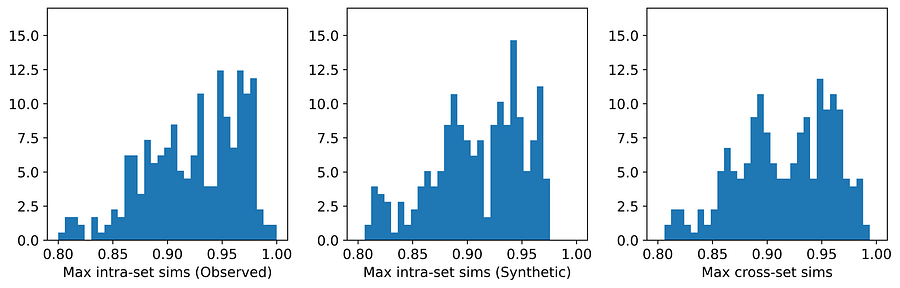
图8. UNCRi 在 Cleveland Heart Disease 数据集上的最大相似度分布。[图片由作者提供]
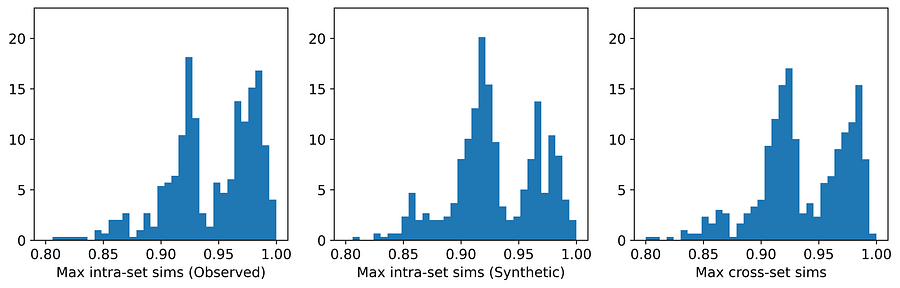
图9. UNCRi 在 Credit Approval 数据集上的最大相似度分布。[图片由作者提供]
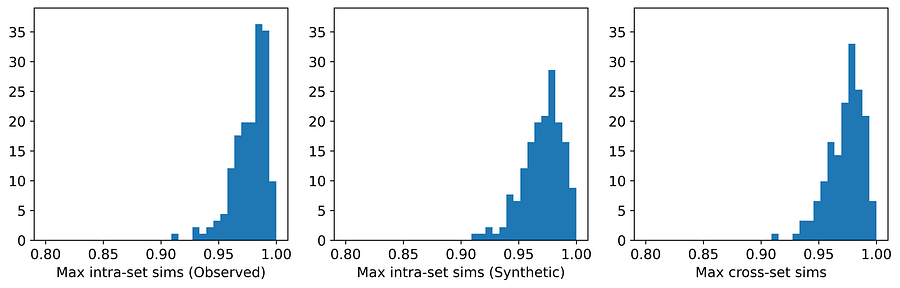
图10. UNCRi 在 Iris 数据集上的最大相似度分布。[图片由作者提供]
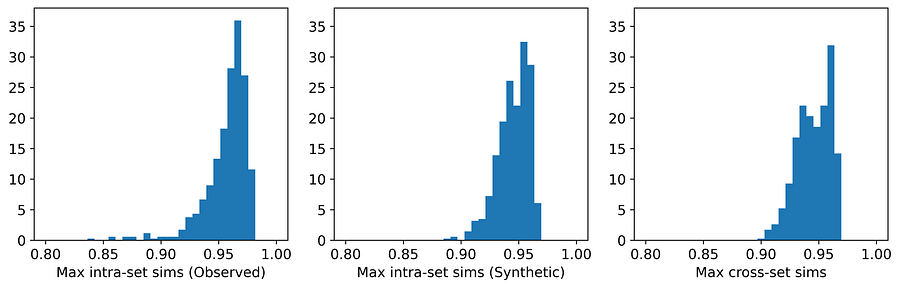
图11. TVAE 在 Wisconsin Breast Cancer 数据集上的平均相似度分布。[图片由作者提供]
从表格中可以看到,对于那些未泄露隐私的生成器,平均最大跨集合相似度与观测数据上的平均最大集合内相似度非常接近。直方图展示了这些最大相似度的分布,并且在大多数情况下,这些分布明显相似——对于像 Census Income 数据集这样的情况,相似度更是惊人。表格还显示,每个数据集上获得最高平均最大跨集合相似度(不包括红色高亮部分)的生成器,在 TSTR 测试中也表现最佳(同样不包括红色高亮部分)。因此,尽管无法声称已发现了“真实”的基础分布,但这些结果表明,每个数据集最有效的生成器都捕获了基础分布的关键特征。
隐私
七种生成器中,只有 synthpop 和 TVAE 两种出现了隐私问题。它们在六个数据集中的三个上都泄露了隐私。在两个特定案例中,即 TVAE 在 Cleveland Heart Disease 和 TVAE 在 Credit Approval 数据集上的表现,隐私泄露尤为严重。下方的 Credit Approval 数据集上 TVAE 的直方图显示,合成样本彼此之间以及与观测数据中最近邻样本之间的相似度过高。该模型未能很好地代表基础父分布。这可能是因为 Credit Approval 数据集中包含几个高度偏斜的数值特征。
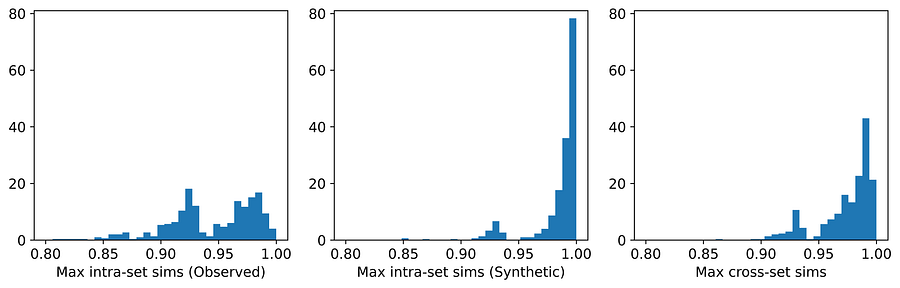
图12. TVAE 在 Credit Approval 数据集上的平均最大相似度分布。[图片由作者提供]
其他观察与评论
两种基于 GAN 的生成器——CopulaGAN 和 CTGAN——在性能上始终处于较差的行列。鉴于 GANs 巨大的受欢迎程度,这一点有些出人意料。
GaussianCopula 在除 Wisconsin Breast Cancer 之外的所有数据集上表现平平,在 Wisconsin Breast Cancer 数据集上则取得了与最高平均最大跨集合相似度持平的成绩。它在 Iris 数据集上表现不佳尤其令人惊讶,因为这是一个非常简单的数据集,可以很容易地使用高斯混合进行建模,并且预期会与基于 Copula 的方法非常匹配。
在所有数据集上表现最稳定且一致的生成器是 synthpop 和 UNCRi,两者都采用顺序插补方法。这意味着它们只需估计和抽样来自单变量条件分布(例如,P(x ₇|x ₁,x ₂, …)),这通常比建模和抽样来自多变量分布(例如,P(x ₁,x ₂,x ₃, …))要容易得多,而后者是 GANs 和 VAEs(隐式地)所做的。虽然 synthpop 使用决策树来估计分布(这也是 synthpop 容易过拟合的原因),但 UNCRi 生成器使用基于最近邻的方法来估计分布,并通过交叉验证程序优化超参数,从而防止过拟合。
结论
合成数据生成是一个新兴且不断发展的领域,虽然目前还没有标准的评估技术,但业界普遍认为评估应涵盖忠实度、实用性和隐私性。尽管这三者都很重要,但它们并非地位平等。例如,一个合成数据集可能在忠实度和实用性方面表现良好,但在隐私方面却失败了。这不能简单地视为“三项中两项通过”:如果合成样本与观测样本过于接近(从而未能通过隐私测试),则模型存在过拟合,使得忠实度和实用性测试变得毫无意义。一些合成数据生成软件供应商倾向于提出结合多项测试结果的单分数性能度量,这本质上是基于相同的“三项中两项通过”逻辑。
如果一个合成数据集可以被认为是与观测数据来自同一父分布的随机样本,那么它已经达到了最佳状态——实现了最大的忠实度、实用性和隐私性。最大相似度测试提供了一种衡量两个数据集在多大程度上可以被视为来自同一父分布的随机样本的方法。它基于一个简单直观的理念:如果观测数据集和合成数据集是来自同一父分布的随机样本,那么实例的分布应该使得合成实例平均而言与其最近的观测实例的相似度,与观测实例平均而言与其最近的观测实例的相似度相同。
本文提出以下单分数合成数据质量衡量指标:
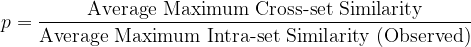
这个比值越接近1(但不超过1),合成数据的质量就越好。当然,它还应该辅以对直方图的合理性检查。