

无论如何,开发者在代码执行速度方面迟早会遇到瓶颈。如果曾用 Python 编写过计算密集型算法,例如字符串距离计算、矩阵运算或加密哈希,那么对这种瓶颈的体会会更加深刻。
确实,有时像 NumPy 这样的外部库可以提供帮助,但如果算法本身是固有序列化的,该怎么办?当需要对一个特定算法进行基准测试时,就遇到了这个问题,该算法旨在确定将一个字符串转换为另一个字符串所需的编辑次数。
尝试了纯 Python 实现,也尝试了利用 NumPy。随后,人们将目光投向了 C 语言——一种在大学时期学习过,但已近十五年未实际使用的语言。正是从那一刻起,事情变得有趣起来。
首先需要回答的问题是:“Python 能否调用 C 语言?”经过一番研究,答案很快明确:**可以**。实际上,有多种方法可以实现这一点,本文将探讨其中三种最常见的方法。
从易到难,将依次介绍以下三种方法:
- 子进程(subprocess)
- ctypes 库
- Python C 扩展(Python C extensions)
本文将用于测试的算法是**莱文斯坦距离(Levenshtein Distance, LD)**算法。两个词语之间的莱文斯坦距离是指将一个词语转换为另一个词语所需的最少单字符编辑(插入、删除或替换)次数。该算法以苏联数学家弗拉基米尔·莱文斯坦(Vladimir Levenshtein)的名字命名,他于 1965 年定义了这一度量标准。它在拼写检查器和光学字符识别系统等多种工具中都有广泛应用。
为了更清晰地说明其原理,以下是一些示例。
计算“book”和“black”这两个词之间的莱文斯坦距离。
- book → baok(将“o”替换为“a”)
- baok → back(将“o”替换为“c”)
- back → black(添加字母“l”)
因此,在这种情况下,莱文斯坦距离为三。
计算“superb”和“super”这两个词之间的莱文斯坦距离。
- superb → super(删除字母“b”)
在这种情况下,莱文斯坦距离仅为一。
本文将分别用 Python 和 C 语言实现莱文斯坦距离算法,然后设置基准测试,比较纯 Python 代码的运行时间与通过 Python 调用 C 代码的运行时间。
准备工作
由于是在 MS Windows 环境下进行操作,因此需要一种编译 C 程序的工具。最简便的方法是下载 Visual Studio 2022 的构建工具(Build Tools)。这使得在命令行中编译 C 程序成为可能。
要安装,首先访问主要的 Visual Studio 下载页面。在第二个界面上,会看到一个搜索框。在搜索字段中输入 “Build Tools”,然后点击搜索。搜索结果应显示一个类似以下截图的界面:
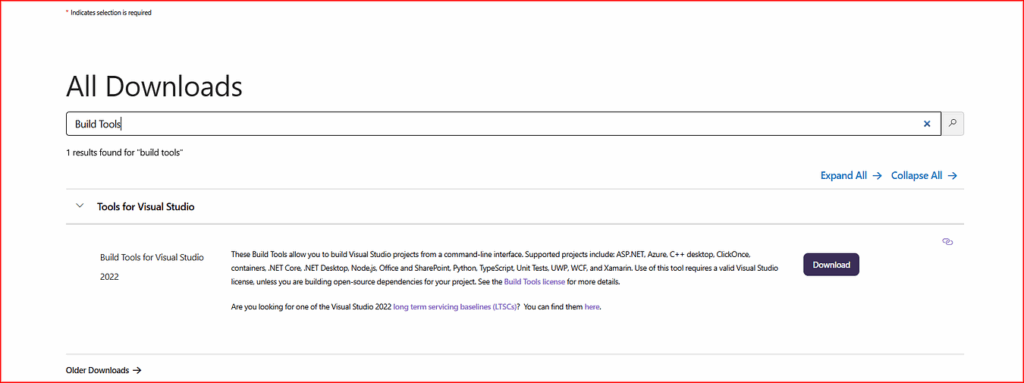
点击下载按钮并按照安装说明进行操作。安装完成后,在 DOS 终端窗口中,当点击小加号按钮打开新终端时,应该会看到一个选项,用于打开“Developer command prompt for VS 2022”(适用于 VS 2022 的开发人员命令提示符)。
大部分 Python 代码将在 Jupyter Notebook 中运行,因此建议读者搭建一个新的开发环境并安装 Jupyter。如果希望跟随本文进行操作,请现在完成此步骤。本文中使用 UV 工具进行此部分操作,但读者可以自由选择最熟悉的方法。
c:> uv init pythonc
c:> cd pythonc
c:> uv venv pythonc
c:> source pythonc/bin/activate
(pythonc) c:> uv pip install jupyter
C 语言实现莱文斯坦距离算法
根据调用方法的不同,C 语言实现的莱文斯坦距离算法版本会略有差异。以下是第一个示例中使用的版本,即通过子进程调用 C 可执行文件。
1/ 子进程(Subprocessing):lev_sub.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
static int levenshtein(const char* a, const char* b) {
size_t n = strlen(a), m = strlen(b);
if (n == 0) return (int)m;
if (m == 0) return (int)n;
int* prev = (int*)malloc((m + 1) * sizeof(int));
int* curr = (int*)malloc((m + 1) * sizeof(int));
if (!prev || !curr) { free(prev); free(curr); return -1; }
for (size_t j = 0; j <= m; ++j) prev[j] = (int)j;
for (size_t i = 1; i <= n; ++i) {
curr[0] = (int)i; char ca = a[i - 1];
for (size_t j = 1; j <= m; ++j) {
int cost = (ca == b[j - 1]) ? 0 : 1;
int del = prev[j] + 1, ins = curr[j - 1] + 1, sub = prev[j - 1] + cost;
int d = del < ins ? del : ins; curr[j] = d < sub ? d : sub;
}
int* tmp = prev; prev = curr; curr = tmp;
}
int ans = prev[m]; free(prev); free(curr); return ans;
}
int main(int argc, char** argv) {
if (argc != 3) { fprintf(stderr, "usage: %s <s1> <s2>
", argv[0]); return 2; }
int d = levenshtein(argv[1], argv[2]);
if (d < 0) return 1;
printf("%d
", d);
return 0;
}
要编译此文件,请启动一个新的适用于 VS Code 2022 的开发人员命令提示符,并输入以下命令以确保编译器针对 64 位架构进行优化。
(pythonc) c:> "%VSINSTALLDIR%VCAuxiliaryBuildvcvarsall.bat" x64
接下来,可以使用以下命令编译 C 代码。
(pythonc) c:> cl /O2 /Fe:lev_sub.exe lev_sub.c
这将创建一个可执行文件。
子进程代码的基准测试
在 Jupyter Notebook 中,输入以下代码。这些代码是所有基准测试的通用部分,用于生成长度为 N 的随机小写字符串,并计算将 string1 转换为 string2 所需的编辑次数。
# Sub-process benchmark
import time, random, string, subprocess
import numpy as np
EXE = r"lev_sub.exe"
def rnd_ascii(n):
return ''.join(random.choice(string.ascii_lowercase) for _ in range(n))
def lev_py(a: str, b: str) -> int:
n, m = len(a), len(b)
if n == 0: return m
if m == 0: return n
prev = list(range(m+1))
curr = [0]*(m+1)
for i, ca in enumerate(a, 1):
curr[0] = i
for j, cb in enumerate(b, 1):
cost = 0 if ca == cb else 1
curr[j] = min(prev[j] + 1, curr[j-1] + 1, prev[j-1] + cost)
prev, curr = curr, prev
return prev[m]
接下来是实际的基准测试代码和运行结果。为了运行 C 语言部分的代码,会启动一个子进程,执行之前编译好的 C 代码文件,并测量其运行时间,然后与纯 Python 方法进行比较。每个方法都会针对 2000 个和 4000 个随机词集各运行三次,并取其中最快的时间作为结果。
def lev_subprocess(a: str, b: str) -> int:
out = subprocess.check_output([EXE, a, b], text=True)
return int(out.strip())
def bench(fn, *args, repeat=3, warmup=1):
for _ in range(warmup): fn(*args)
best = float("inf"); out_best = None
for _ in range(repeat):
t0 = time.perf_counter(); out = fn(*args); dt = time.perf_counter() - t0
if dt < best: best, out_best = dt, out
return out_best, best
if __name__ == "__main__":
cases = [(2000,2000),(4000, 4000)]
print("Benchmark: Pythonvs C (subprocess)
")
for n, m in cases:
a, b = rnd_ascii(n), rnd_ascii(m)
py_out, py_t = bench(lev_py, a, b, repeat=3)
sp_out, sp_t = bench(lev_subprocess, a, b, repeat=3)
print(f"n={n} m={m}")
print(f" Python : {py_t:.3f}s -> {py_out}")
print(f" Subproc : {sp_t:.3f}s -> {sp_out}
")
以下是测试结果。
Benchmark: Python vs C (subprocess)
n=2000 m=2000
Python : 1.276s -> 1768
Subproc : 0.024s -> 1768
n=4000 m=4000
Python : 5.015s -> 3519
Subproc : 0.050s -> 3519
这表明 C 语言在运行时间方面相对于 Python 有了相当显著的提升。
2. ctypes 库:lev.c
ctypes 是一个内置于 Python 标准库中的**外部函数接口 (FFI)** 库。它允许开发者**直接从 Python** 加载和调用用 C 语言编写的共享库(Windows 上的 DLL、Linux 上的 `.so` 文件、macOS 上的 `.dylib` 文件)中的函数,而无需编写完整的 C 扩展模块。
首先,以下是利用 ctypes 实现的 C 语言版莱文斯坦距离算法。它与子进程示例中的 C 函数几乎相同,只是额外增加了一行代码,使得编译后的 DLL 能够被 Python 调用。
/*
* lev.c
*/
#include <stdlib.h>
#include <string.h>
/* below line includes this function in the
* DLL's export table so other programs can use it.
*/
__declspec(dllexport)
int levenshtein(const char* a, const char* b) {
size_t n = strlen(a), m = strlen(b);
if (n == 0) return (int)m;
if (m == 0) return (int)n;
int* prev = (int*)malloc((m + 1) * sizeof(int));
int* curr = (int*)malloc((m + 1) * sizeof(int));
if (!prev || !curr) { free(prev); free(curr); return -1; }
for (size_t j = 0; j <= m; ++j) prev[j] = (int)j;
for (size_t i = 1; i <= n; ++i) {
curr[0] = (int)i;
char ca = a[i - 1];
for (size_t j = 1; j <= m; ++j) {
int cost = (ca == b[j - 1]) ? 0 : 1;
int del = prev[j] + 1;
int ins = curr[j - 1] + 1;
int sub = prev[j - 1] + cost;
int d = del < ins ? del : ins;
curr[j] = d < sub ? d : sub;
}
int* tmp = prev; prev = curr; curr = tmp;
}
int ans = prev[m];
free(prev); free(curr);
return ans;
}
当使用 ctypes 在 Python 中调用 C 语言时,需要将 C 代码编译成动态链接库 (DLL) 而非可执行文件。以下是为此所需的构建命令。
(pythonc) c:> cl /O2 /LD lev.c /Fe:lev.dll
ctypes 代码的基准测试
在此代码片段中,省略了 lev_py 和 rnd_ascii 这两个 Python 函数,因为它们与上一个示例中的功能完全相同。请将以下代码输入到 Jupyter Notebook 中。
#ctypes benchmark
import time, random, string, ctypes
import numpy as np
DLL = r"lev.dll"
levdll = ctypes.CDLL(DLL)
levdll.levenshtein.argtypes = [ctypes.c_char_p, ctypes.c_char_p]
levdll.levenshtein.restype = ctypes.c_int
def lev_ctypes(a: str, b: str) -> int:
return int(levdll.levenshtein(a.encode('utf-8'), b.encode('utf-8')))
def bench(fn, *args, repeat=3, warmup=1):
for _ in range(warmup): fn(*args)
best = float("inf"); out_best = None
for _ in range(repeat):
t0 = time.perf_counter(); out = fn(*args); dt = time.perf_counter() - t0
if dt < best: best, out_best = dt, out
return out_best, best
if __name__ == "__main__":
cases = [(2000,2000),(4000, 4000)]
print("Benchmark: Python vs NumPy vs C (ctypes)
")
for n, m in cases:
a, b = rnd_ascii(n), rnd_ascii(m)
py_out, py_t = bench(lev_py, a, b, repeat=3)
ct_out, ct_t = bench(lev_ctypes, a, b, repeat=3)
print(f"n={n} m={m}")
print(f" Python : {py_t:.3f}s -> {py_out}")
print(f" ctypes : {ct_t:.3f}s -> {ct_out}
")
那么结果如何?
Benchmark: Python vs C (ctypes)
n=2000 m=2000
Python : 1.258s -> 1769
ctypes : 0.019s -> 1769
n=4000 m=4000
Python : 5.138s -> 3521
ctypes : 0.035s -> 3521
结果与第一个示例非常相似。
3/ Python C 扩展(Python C extensions):lev_cext.c
使用 Python C 扩展时,涉及的工作量会稍微多一些。首先,让我们来查看 C 代码。基本算法保持不变,只是需要添加更多的“脚手架”代码,以便能够从 Python 调用该代码。它利用 CPython 的 API (Python.h) 来解析 Python 参数,运行 C 代码,并将结果作为 Python 整数返回。
函数 levext_lev 充当一个封装器。它从 Python 中解析两个字符串参数 (PyArg_ParseTuple),调用 C 函数 **lev_impl** 计算距离,处理内存错误,并将结果作为 Python 整数返回 (PyLong_FromLong)。Methods 表将此函数注册为“levenshtein”,因此可以从 Python 代码中调用。最后,PyInit_levext 定义并初始化模块 **levext**,使其可以通过 import levext 命令在 Python 中导入。
#include <Python.h>
#include <string.h>
#include <stdlib.h>
static int lev_impl(const char* a, const char* b) {
size_t n = strlen(a), m = strlen(b);
if (n == 0) return (int)m;
if (m == 0) return (int)n;
int* prev = (int*)malloc((m + 1) * sizeof(int));
int* curr = (int*)malloc((m + 1) * sizeof(int));
if (!prev || !curr) { free(prev); free(curr); return -1; }
for (size_t j = 0; j <= m; ++j) prev[j] = (int)j;
for (size_t i = 1; i <= n; ++i) {
curr[0] = (int)i; char ca = a[i - 1];
for (size_t j = 1; j <= m; ++j) {
int cost = (ca == b[j - 1]) ? 0 : 1;
int del = prev[j] + 1, ins = curr[j - 1] + 1, sub = prev[j - 1] + cost;
int d = del < ins ? del : ins; curr[j] = d < sub ? d : sub;
}
int* tmp = prev; prev = curr; curr = tmp;
}
int ans = prev[m]; free(prev); free(curr); return ans;
}
static PyObject* levext_lev(PyObject* self, PyObject* args) {
const char *a, *b;
if (!PyArg_ParseTuple(args, "ss", &a, &b)) return NULL;
int d = lev_impl(a, b);
if (d < 0) { PyErr_SetString(PyExc_MemoryError, "alloc failed"); return NULL; }
return PyLong_FromLong(d);
}
static PyMethodDef Methods[] = {
{"levenshtein", levext_lev, METH_VARARGS, "Levenshtein distance"},
{NULL, NULL, 0, NULL}
};
static struct PyModuleDef mod = { PyModuleDef_HEAD_INIT, "levext", NULL, -1, Methods };
PyMODINIT_FUNC PyInit_levext(void) { return PyModule_Create(&mod); }
因为这次不是简单地构建一个可执行文件,而是构建一个原生的 Python 扩展模块,所以必须以不同的方式编译 C 代码。
这种类型的模块必须针对 Python 的头文件进行编译,并与 Python 的运行时环境正确链接,才能使其表现得像一个内置的 Python 模块。
为了实现这一点,需要创建一个名为 `setup.py` 的 Python 模块,它导入 `setuptools` 库来简化此过程。`setuptools` 自动化了以下任务:
- 查找 `Python.h` 正确的包含路径
- 传递正确的编译器和链接器标志
- 生成一个符合当前 Python 版本和平台命名约定的 `.pyd` 文件
如果手动使用 cl 编译器命令来完成这些,将会非常繁琐且容易出错,因为需要手动指定所有这些路径和标志。
以下是所需的代码。
from setuptools import setup, Extension
setup(
name="levext",
version="0.1.0",
ext_modules=[Extension("levext", ["lev_cext.c"], extra_compile_args=["/O2"])],
)
可以通过常规 Python 命令在命令行中运行它,如下所示。
(pythonc) c:> python setup.py build_ext --inplace
#output
running build_ext
copying buildlib.win-amd64-cpython-312levext.cp312-win_amd64.pyd ->
Python C 扩展代码的基准测试
现在,以下是调用 C 代码的 Python 实现。同样,本文省略了与之前示例中未作更改的两个 Python 辅助函数。
# c-ext benchmark
import time, random, string
import numpy as np
import levext # make sure levext.cp312-win_amd64.pyd is built & importable
def lev_extension(a: str, b: str) -> int:
return levext.levenshtein(a, b)
def bench(fn, *args, repeat=3, warmup=1):
for _ in range(warmup): fn(*args)
best = float("inf"); out_best = None
for _ in range(repeat):
t0 = time.perf_counter(); out = fn(*args); dt = time.perf_counter() - t0
if dt < best: best, out_best = dt, out
return out_best, best
if __name__ == "__main__":
cases = [(2000, 2000), (4000, 4000)]
print("Benchmark: Python vs NumPy vs C (C extension)
")
for n, m in cases:
a, b = rnd_ascii(n), rnd_ascii(m)
py_out, py_t = bench(lev_py, a, b, repeat=3)
ex_out, ex_t = bench(lev_extension, a, b, repeat=3)
print(f"n={n} m={m} ")
print(f" Python : {py_t:.3f}s -> {py_out}")
print(f" C ext : {ex_t:.3f}s -> {ex_out}
")
以下是输出结果。
Benchmark: Python vs C (C extension)
n=2000 m=2000
Python : 1.204s -> 1768
C ext : 0.010s -> 1768
n=4000 m=4000
Python : 5.039s -> 3526
C ext : 0.033s -> 3526
因此,这种方法获得了最快的测试结果。在上面的第二个测试用例中,C 语言版本显示出比纯 Python 快 150 倍以上。
这表现相当出色。
那么 NumPy 呢?
读者可能会疑惑为什么没有使用 NumPy。实际上,NumPy 在向量化数值数组操作方面表现出色,例如点积计算,但并非所有算法都能很好地映射到向量化。计算莱文斯坦距离是一个固有的序列化过程,因此 NumPy 在这种情况下帮助不大。在这种情况下,通过**子进程(subprocess)**、**ctypes)** 或**原生 C 扩展(native C extension)** 介入 C 语言,可以在保持 Python 可调用的同时,显著提升运行时速度。
附注:一些额外的测试表明,对于适合使用 NumPy 的代码,NumPy 的速度与调用的 C 代码同样快。这是意料之中的,因为 NumPy 底层使用了 C 语言,并经过多年的开发和优化。
总结
本文探讨了 Python 开发者如何通过将 C 代码集成到 Python 中,来克服计算密集型任务(例如计算**莱文斯坦距离**——一种字符串相似度算法)中的性能瓶颈。尽管 NumPy 等库可以加速向量化操作,但像莱文斯坦距离这样固有的序列化算法往往无法从 NumPy 的优化中受益。
为了解决这个问题,本文展示了**三种集成模式**,从最简单到最复杂,它们都允许从 Python 调用快速的 C 代码。
子进程(Subprocess)。将 C 代码编译成可执行文件(例如使用 gcc 或 Visual Studio Build Tools),然后使用 Python 的 `subprocess` 模块从 Python 中运行它。这种方法设置简单,并且与纯 Python 相比已经显示出巨大的速度提升。
ctypes 库。使用 ctypes 允许 Python 直接从 C 共享库中加载和调用函数,而无需编写完整的 Python 扩展模块。这使得将性能关键的 C 代码集成到 Python 中变得更加简单和快捷,避免了运行外部进程的开销,同时还能将大部分代码保留在 Python 中。
Python C 扩展。使用 CPython API (python.h) 编写一个完整的 C 语言 Python 扩展。这需要更多的设置工作,但提供了最快的性能和最流畅的集成,使得可以像调用原生 Python 函数一样调用 C 函数。
基准测试表明,C 语言实现的莱文斯坦算法运行速度比纯 Python 快 100 倍以上。虽然像 **NumPy** 这样的外部库在向量化数值操作方面表现出色,但对于莱文斯坦距离这类固有的序列化算法,它并不能显著提升性能,因此在这种情况下,C 语言集成是更好的选择。
如果在 Python 中遇到性能瓶颈,将繁重计算卸载到 C 语言可以提供巨大的速度提升,值得考虑。可以从简单的子进程方法开始,然后根据需求转向 ctypes 或完整的 C 扩展,以实现更紧密的集成和更优异的性能。




