

神经网络的学习方式一直被认为是相对固定的:训练模型、观察损失下降、每隔一个周期(epoch)保存检查点。这通常是标准的机器学习工作流程。然而,当研究人员将训练动态的监测频率从传统的周期级别提升到每5步进行一次时,许多关于神经网络训练的固有认知被颠覆了。
这项研究的起点源于一个核心问题:神经网络的容量在训练过程中是会随之扩展,还是从初始化开始就固定不变?直到2019年,人们普遍认为答案显而易见——既然参数数量是固定的,那么模型的容量也必然是固定的。然而,Ansuini等人在2019年发现了一个颠覆传统认知的现象:神经网络的有效表征维度(effective representational dimensionality)在训练过程中竟然会不断增加。这一发现随后在2024年由Yang等人进一步证实。
这一发现彻底改变了我们对神经网络的理解。如果学习空间在网络学习的同时不断扩展,我们又该如何从机制层面深入理解它究竟在执行什么任务?
高频训练检查点
在训练一个包含10,000步的深度神经网络(DNN)时,过去通常每隔100或200步设置一次检查点。以5步为间隔进行测量会产生大量记录,管理起来并不容易。然而,正是这些高频率的检查点,揭示了关于DNN学习方式的极其宝贵的信息。
高频检查点提供以下信息:
- 早期训练失误是否可以恢复(通常无法恢复)
- 为何某些架构有效,而另一些则失败
- 何时应进行可解释性分析(剧透:比我们想象的要早得多)
- 如何设计更好的训练方法
在一项应用研究项目中,研究人员以高分辨率监测了DNN的训练过程——每5步而非传统的100或500步。实验中采用了一个基础的多层感知机(MLP)架构,并使用了一个十年间持续使用的经典数据集。

图1. 实验设置。研究人员使用滚动统计量结合z-score分析来检测离散转换。
实验结果令人惊讶。深度神经网络,即便采用简单的架构,在训练过程中也会扩展其有效的参数空间。研究人员曾假设这一空间是由架构本身预先确定的。然而,实际情况是DNN会经历一系列离散的转换——小的跳跃式变化,从而增加其学习空间的有效维度。
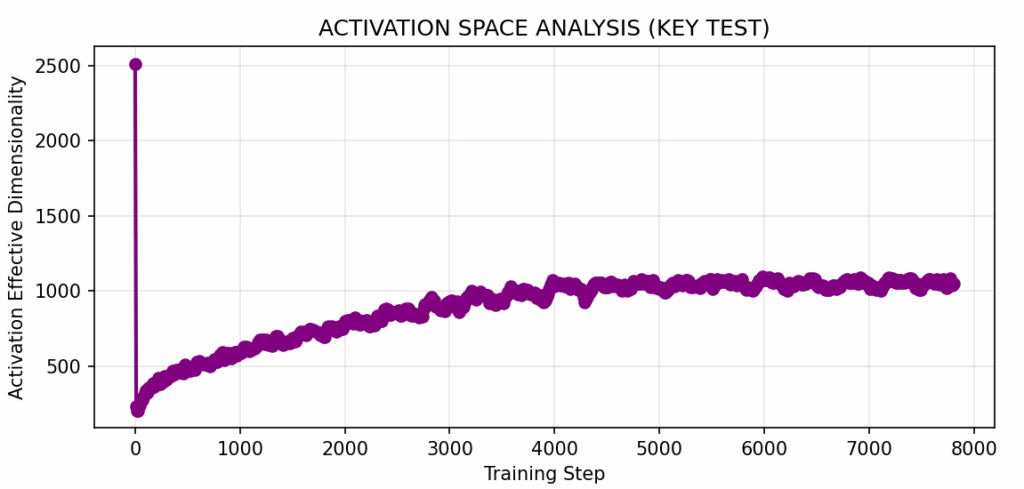
图2:训练过程中激活模式的有效维度,使用稳定秩测量。图中显示了三个明显的阶段:初始崩溃(0-300步),维度从2500下降到500;扩展阶段(300-5000步),维度上升到1000;以及稳定阶段(5000-8000步),维度趋于平稳。这表明0-2000步构成了一个性质独特的发育窗口。图片由作者提供。
图2展示了训练过程中激活层有效维度的监测结果。可以观察到,这些转变主要集中在训练的前25%阶段,并且在较大的检查点间隔(100-1000步)下往往被忽略。为了检测到大部分这些转变,研究人员需要采用高频率的检查点(每5步)。曲线还展示了一个有趣的现象:最初的“崩溃”阶段代表了损失函数景观的重构,其中随机初始化逐渐演变为与任务对齐的结构。随后,进入“扩展”阶段,维度逐渐增长。在2000至3000步之间,出现了一个“稳定”阶段,这反映了DNN架构容量的限制。
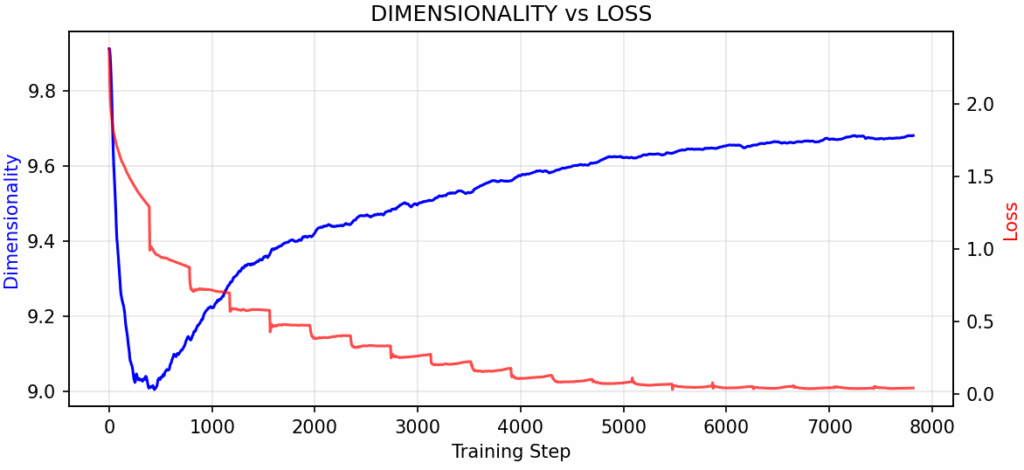
图3:表征维度(使用稳定秩测量)与损失呈强烈的负相关(ρ = -0.951),与梯度幅度呈中等程度的负相关(ρ = -0.701)。随着损失从2.0下降到接近零,维度从9.0扩展到9.6。与直觉相反,性能的提升与表征的扩展而非压缩相关。图片由作者提供。
这一发现彻底改变了我们对DNN训练、可解释性和架构设计的传统看法。
探索 vs 扩张
考虑以下两种情况,它们代表了神经网络学习的不同视角:
场景A:
固定容量(探索)
网络从一开始就拥有固定的表征容量。训练过程是在这个预设空间内探索不同的区域,如同在已有的地图上导航。早期训练仅仅意味着尚未找到最佳区域。
场景B:
扩展容量(创新)
网络以最小的容量启动。训练过程是创造表征结构的过程,如同在旅行中不断修建道路——每条道路都开启新的目的地。早期训练奠定了之后学习能力的基础。
究竟是哪一种情况呢?
这个问题之所以重要,是因为如果容量确实会扩展,那么早期的训练失误可能无法简单地通过“延长训练时间”来弥补。因此,模型的可解释性具有一个明确的“时间线”,特征是按顺序形成的。理解这一形成序列是关键。此外,架构设计似乎更多地关乎容量的扩展速度,而不仅仅是最终的容量大小。最终,存在着关键的学习期,一旦错过这些窗口,网络可能就失去了获得某些特定能力的机会。
何时需要高频监测检查点
扩张 vs 探索
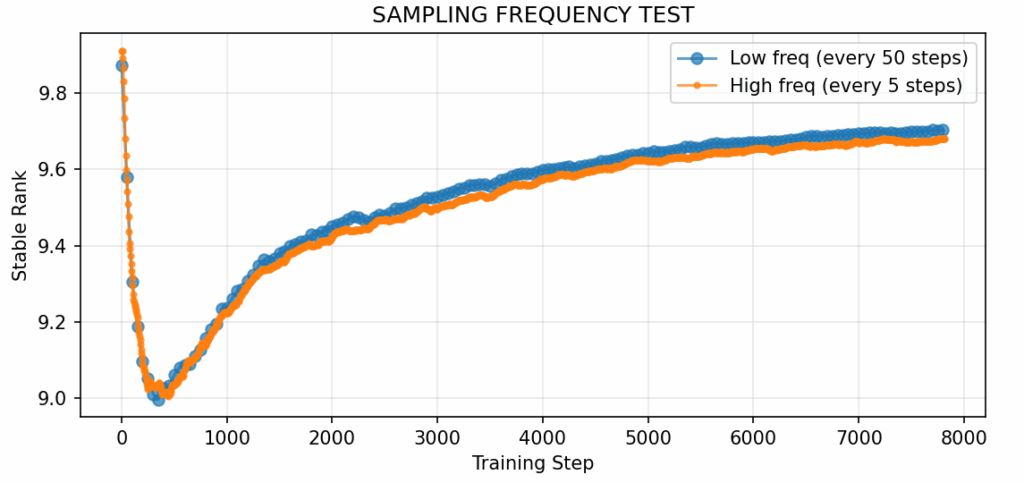
图4:图1所示实验中的高频采样与低频采样对比。研究人员使用滚动统计量结合z-score分析来检测离散转换。高频采样能够捕获粗粒度测量所遗漏的快速转换。此对比旨在测试时间分辨率是否影响可观察到的动态。图片由作者提供。
正如图2和图3所示,高频采样揭示了许多有趣的细节。研究人员可以识别出三个不同的阶段:
第一阶段:崩溃(0-300步) 网络从随机初始化状态进行重构。随着损失函数景观围绕任务重塑,维度急剧下降。这并非真正的学习,而是为学习做准备。
第二阶段:扩展(300-5,000步)
维度稳步攀升。这是容量的扩展阶段。网络正在构建表征结构。简单的特征促成复杂的特征,再进一步促成高阶特征。
第三阶段:稳定(5,000-8,000步) 增长趋于平稳。架构限制开始显现。网络在此阶段更多地是精炼已有的能力,而非构建新的容量。
这些图表揭示了学习过程是“扩展”而非“探索”:在第5,000步时,网络能够表征在第300步时尚无法实现的功能,因为这些功能在当时根本不存在。
容量扩展,参数不变

图5:激活空间与权重空间的比较。权重空间的维度几乎保持不变(9.72-9.79),在8000步中仅检测到一次“跳跃”。图片由作者提供。
激活空间与权重空间的对比表明,在高频采样下,两者遵循截然不同的动态。激活空间显示了大约85次离散的跳跃(包括高斯噪声),而权重空间仅显示1次。这是同一个网络在相同的训练运行中观察到的现象。这证实了尽管参数数量相同,但在第8000步时,网络能够计算出在第500步时无法实现的功能。这是容量扩展最清晰的证据。
深度神经网络通过在训练过程中生成新的参数空间选项来表示复杂的任务,从而实现创新。
转换迅速且集中在早期
研究表明,高频采样能够揭示出远超预期的更多转换。低频检查点几乎会遗漏所有这些关键转变。这些转换集中在训练的早期阶段:所有转换中的三分之二发生在最初的2,000步内,这仅占总训练时间的25%。这意味着,如果想要理解特征何时以及如何形成,需要在0-2,000步的窗口期内进行观察,而不是等到模型收敛之后。到第5,000步时,主要的故事线已经结束。
扩展与优化紧密耦合
如果再次回顾图3,可以看到随着损失的减少,维度反而会扩展。这表明网络在学习过程中并非变得更简单,而是变得更加复杂。维度与损失之间呈现出强烈的负相关(ρ = -0.951),与梯度幅度之间则呈现中等程度的负相关(ρ = -0.701)。这可能看似违反直觉:性能的提升竟然与表征的“扩展”而非“压缩”相关。人们通常预期网络在学习时会找到更简单、更紧凑的表征。然而,实际情况是它们扩展到更高维度的空间。
究其原因何在?
一个可能的解释是,复杂的任务需要复杂的表征。网络并非仅仅找到一个更简单的解释,而是构建出所需的表征变化,以便有效分离类别、识别模式并进行泛化。
实际应用部署
研究表明,这是一种理解和调试DNN训练的全新方式,适用于任何领域。
如果我们能知晓特征在训练过程中何时形成,就可以在它们“结晶”时进行分析,而不是在事后对一个黑箱进行逆向工程。
在实际部署场景中,可以实时追踪表征维度,检测何时发生扩展阶段,并在每个转换点运行可解释性分析。这能精确地告诉我们网络何时正在构建新的表征结构——以及何时已完成。这种测量方法与架构无关:无论您是在训练用于视觉的CNN、用于语言的Transformer、用于控制的强化学习(RL)智能体,还是用于跨领域任务的多模态模型,它都同样适用。
示例1:干预实验可以映射因果依赖关系。在特定时间窗口中断训练,并测量哪些下游能力会随之丧失。例如,如果在2,000-5,000步之间损坏数据会永久性地损害纹理识别能力,而同样的数据损坏在6,000步时却没有任何影响,那么您就找到了纹理特征何时结晶以及它们依赖于什么。这同样适用于视觉模型中的对象识别、语言模型中的句法结构或强化学习智能体中的状态判别。
示例2:对于生产部署而言,持续的维度监测可以在训练过程中及时发现表征问题,从而在问题尚可解决时进行干预。如果某些层停止扩展,则表明存在架构瓶颈。如果扩展变得不稳定,则表明存在不稳定性。如果早期层饱和而后期层未能扩展,则表明存在信息流问题。标准的损失曲线通常要等到为时已晚才会显示这些问题——而维度追踪则能立即将其显现。
示例3:架构设计的影响同样具有实际意义。在候选架构的训练初期(前5-10%)测量其扩展动态。优选那些具有清晰阶段转换和结构化自下而上发展的网络。这些网络不仅性能更优越,而且从根本上更具可解释性,因为特征是以清晰的顺序层级而非混乱的同步方式形成的。
未来展望
至此,研究已经确立了神经网络在训练过程中会扩展其表征空间,并且能够以高分辨率测量这些转换,这为可解释性和干预提供了新的方法。接下来自然而然的问题是:能否将此应用于您的实际工作中?
作者已将完整的测量基础设施作为开源项目发布。其中包含了针对多层感知机(MLP)、卷积神经网络(CNN)、残差网络(ResNet)、Transformer和Vision Transformer的经过验证的实现,并提供了用于自定义架构的钩子。
只需在训练循环中添加三行代码即可运行所有功能。
GitHub仓库提供了上述实验的模板:特征形成映射、干预协议、跨架构迁移预测和生产监控设置。测量方法已经过验证。现在重要的是您在将其应用于自身领域时能发现什么。
尝试使用:
pip install ndtracker
快速入门、说明和示例请查阅仓库:Neural Dimensionality Tracker (NDT)
代码已达到生产就绪水平,协议也已文档化。开放性问题等待您的探索。期待看到您在不同背景和架构下,通过高分辨率测量训练动态所获得的发现。
您可以分享您的结果,提交包含新发现的问题,或者如果这项工作改变了您对训练的看法,请为该仓库加星。请记住,可解释性时间线存在于所有神经网络架构中。





