

通常,深度学习模型被视为一个“黑箱”。大家普遍了解它能够从数据中学习,但其真正的学习机制究竟是怎样的,却常常令人费解。
本文将直接在Excel中构建一个微型卷积神经网络(CNN),旨在帮助读者一步步深入理解CNN在图像处理中的实际工作原理。
通过这种方式,读者可以直观地观察到CNN的每一个运算步骤,从而透彻理解构成“深度学习”基石的各项计算。
本文是关于在Excel中实现机器学习与深度学习算法系列文章的一部分。相关的Excel文件可通过以下Kofi链接获取。
1. 机器如何“看懂”图像?
1.1 图像中目标检测的两种主要方法
当尝试在图片中检测一个物体,例如一只猫时,主要有两种方法:确定性方法和机器学习方法。下面将通过识别图片中猫的例子来探讨这两种方法的运作方式。
确定性方法意味着需要手动编写规则。
例如,可以定义猫具有圆脸、两只三角形耳朵、一个身体、一条尾巴等特征。因此,开发者需要完成所有规则的定义工作。
随后,计算机运行这些预设规则,并给出一个相似度评分。

通过确定性方法检测图像中的猫 — 作者绘制
机器学习方法则意味着无需手动编写规则。
相反,通过向计算机提供大量包含猫的图片和不含猫的图片示例,机器将自主学习猫的特征。
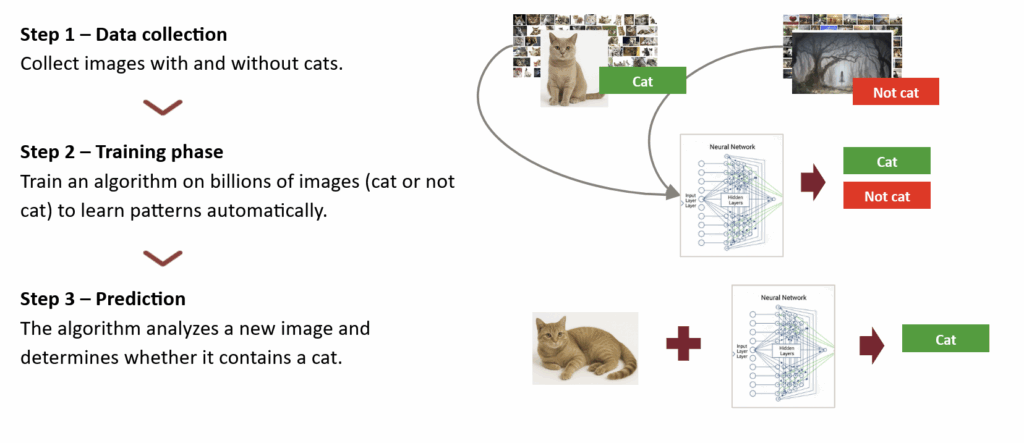
通过机器学习方法检测图像中的猫 — 作者绘制(猫咪由AI生成)
正是这一点,让事物变得有些神秘。
通常认为机器能自主学习规则,但关键在于其具体学习机制。
实际上,仍然需要明确指导机器如何创建这些规则。而且这些规则必须是可学习的。因此,核心问题是:如何定义将要使用的规则类型?
要理解如何定义规则,首先必须理解图像的本质。
1.2 理解图像的本质
虽然猫是一种复杂的形态,但我们可以选择一个简单明了的例子:识别MNIST数据集中的手写数字。
首先,图像究竟是什么?
数字图像可以被视为一个像素网格。每个像素都对应一个数字,表示其亮度,从0(白色)到255(黑色)。
在Excel中,可以使用一个表格来表示这个网格,其中每个单元格对应一个像素。

MNIST手写数字 — 图像来自MNIST数据集 https://en.wikipedia.org/wiki/MNIST_database (CC BY-SA 3.0)
手写数字的原始尺寸是28 x 28。但为简化起见,本文将使用一个10×10的表格。它足够小,便于快速计算,同时又足够大,能展示数字的整体形状。
因此,将对维度进行缩减。
例如,手写数字“1”在Excel中可以表示为一个如下所示的10×10网格。

图像是数字网格 — 作者绘制
1.3 深度学习之前:图像识别的传统机器学习方法
在使用CNN或任何深度学习方法之前,已能通过逻辑回归或决策树等传统机器学习算法识别简单图像。
在这种方法中,每个像素都成为一个特征。例如,一个10×10的图像有100个像素,因此有100个特征作为输入。
算法随后学习将像素值模式与“0”、“1”或“2”等标签关联起来。
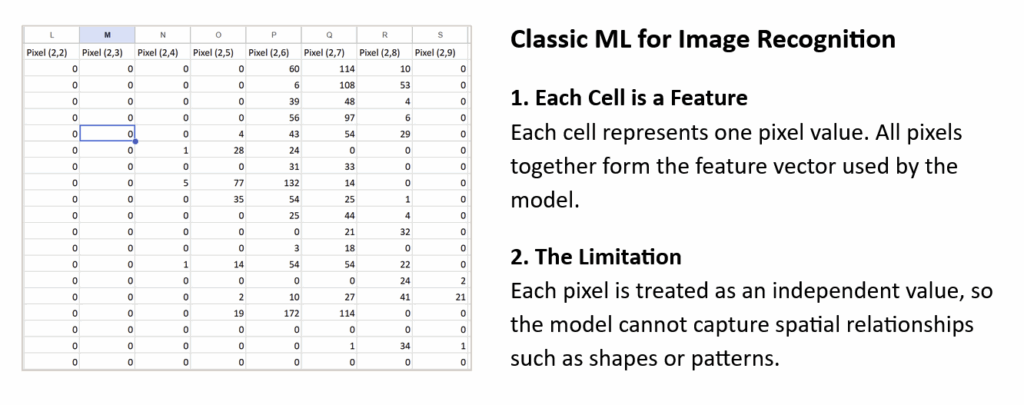
传统机器学习用于图像识别 — 作者绘制
事实上,通过这种简单的机器学习方法,逻辑回归就能取得相当不错的结果,准确率可达90%左右。
这表明传统模型能够从原始像素值中学习到有用的信息。
然而,它们存在一个主要局限性:将每个像素视为独立值,而未考虑其相邻像素。结果,它们无法理解像素间的空间关系。
因此,可以预见,对于复杂图像,其性能表现将不尽如人意。所以这种方法不具扩展性。
现在,如果读者已了解传统机器学习的工作原理,便会明白其中并无魔法。实际上,读者已经知道该怎么做:需要改进特征工程步骤,对特征进行转换,以从像素中提取更有意义的信息。
2. 在Excel中一步步构建CNN
2.1 从复杂CNN到Excel中的简化模型
谈及卷积神经网络时,常会见到非常深且复杂的架构,例如VGG-16。许多层、成千上万个参数以及无数次操作,使其看起来异常复杂,让人觉得不可能完全理解其工作原理。
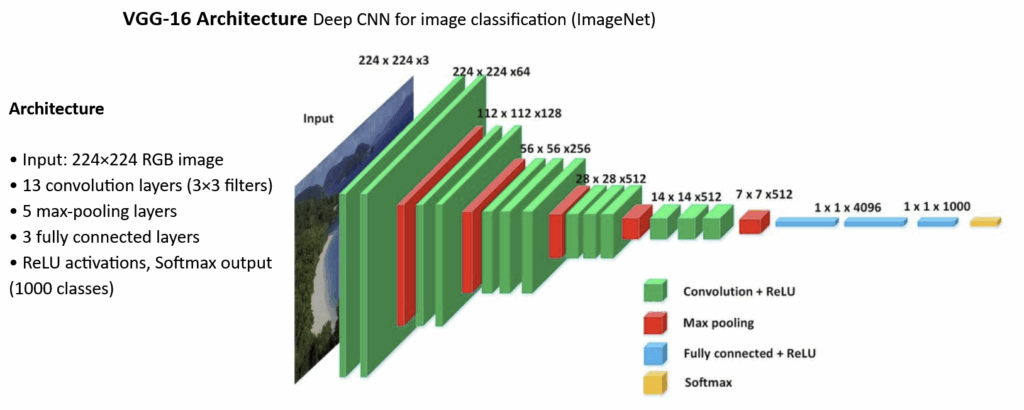
VGG16架构 — 作者绘制
这些层背后的核心思想是:逐步检测模式。
以手写数字为例,可以提出一个问题:最简单的CNN架构可能是什么样的?
首先,对于隐藏层,在构建所有层之前,先减少其数量。具体多少层?只设一层。没错:仅此一层。
至于滤波器(或称卷积核)的维度呢?在真实的CNN层中,通常使用3×3的滤波器来检测小尺寸模式。但此处将从大尺寸开始。
多大呢?10×10!
是的,为什么不呢?
这也意味着无需在图像上滑动滤波器。通过这种方式,可以直接比较输入图像与滤波器,观察它们匹配的程度。
这种简化的案例并非为了追求性能,而是为了清晰地展示原理。
它将逐步揭示CNN如何检测模式。
现在,需要定义滤波器的数量。可以设定为10个,这是最小值。为什么?因为有10个数字,所以至少需要10个滤波器。下一节将探讨如何找到它们。
在下图中,展示了这种最简单的CNN神经网络架构图:

最简化的CNN架构 — 作者绘制
2.2 训练滤波器(或自主设计)
在真实的CNN中,滤波器并非手动编写。它们是在训练过程中学习得到的。
神经网络会调整每个滤波器内部的数值,以检测最有助于识别图像的模式。
在本文的Excel简化示例中,将不进行滤波器的训练。
相反,将手动创建它们,以理解它们所代表的含义。
由于已知手写数字的形状,可以设计出与每个数字形态相似的滤波器。
例如,可以绘制一个与数字0形状匹配的滤波器,另一个与数字1匹配,以此类推。
另一种选择是取每个数字所有示例图像的平均值作为滤波器。
这样,每个滤波器将代表一个数字的“平均形状”。
这正是人类与机器之间界限再次显现之处。可以选择让机器自动发现这些滤波器,或者利用先验知识手动构建它们。
没错:机器不会定义操作的性质。是机器学习研究人员定义它们。机器只擅长执行循环,为这些定义的规则找到最优值。而在简单的情况下,人类总是优于机器。
因此,如果只需定义10个滤波器,可以直观地知道如何直接定义这10个数字,并了解这些滤波器的性质。当然,也有其他选项。
现在,要定义这些滤波器的数值,可以直接运用已知知识,也可以利用训练数据集。
下图展示了通过对每个手写数字的所有图像取平均值创建的10个滤波器。每个滤波器都呈现出定义数字的典型模式。

平均值作为滤波器 — 作者绘制
2.3 CNN如何检测模式
现在已经有了滤波器,接下来需要将输入图像与这些滤波器进行比较。
CNN中的核心操作被称为互相关(cross-correlation)。它是让计算机在图像中匹配模式的关键机制。
它通过两个简单步骤完成:
- 值相乘/点积: 提取输入图像中的每个像素,并将其与滤波器中相同位置的像素相乘。这意味着滤波器“查看”图像的每个像素,并衡量其与滤波器中存储模式的相似程度。如果两个值都很大,结果也会很大。
- 结果相加/求和: 这些乘积随后被加在一起,生成一个单一的数字。这个数字表示输入图像与滤波器的匹配强度。
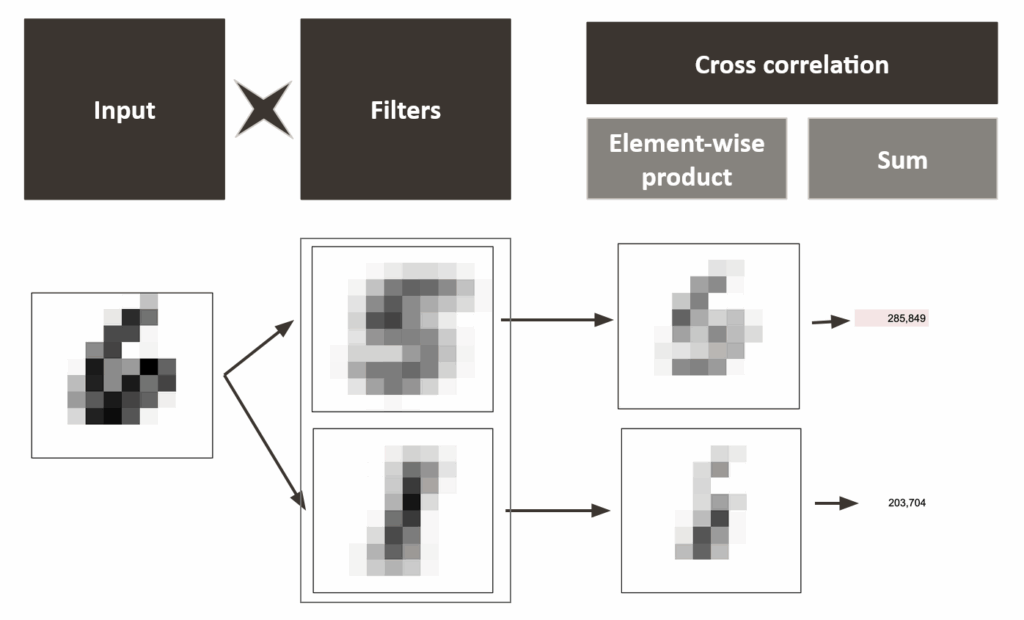
单张图像的互相关操作示例 — 作者绘制
在本文的简化架构中,滤波器与输入图像(10×10)具有相同的尺寸。
因此,滤波器无需在图像上移动。
相反,互相关操作仅应用一次,直接将整个图像与滤波器进行比较。
这个数字表示图像与滤波器内部模式的匹配程度。
如果滤波器类似于手写数字“5”的平均形状,那么较高的得分则意味着该图像很可能就是数字“5”。
通过对所有滤波器(每个数字一个)重复此操作,可以确定哪个模式提供了最高的匹配度。
2.4 在Excel中构建一个简单的CNN
现在可以从头到尾创建一个小型CNN,以实践方式观察整个过程的运作。
- 输入: 一个10×10的矩阵,代表待分类的图像。
- 滤波器: 定义十个10×10尺寸的滤波器,每个滤波器代表一个从0到9的手写数字的平均图像。这些滤波器充当每个数字的模式检测器。
- 互相关: 每个滤波器被应用于输入图像,生成一个单一的分数,衡量图像与该滤波器模式的匹配程度。
- 决策: 具有最高分数的滤波器给出预测的数字。在深度学习框架中,这一步通常由Softmax函数处理,该函数将所有分数转换为概率。
在本文的Excel简化版本中,直接取最大分数足以确定图像最可能代表哪个数字。
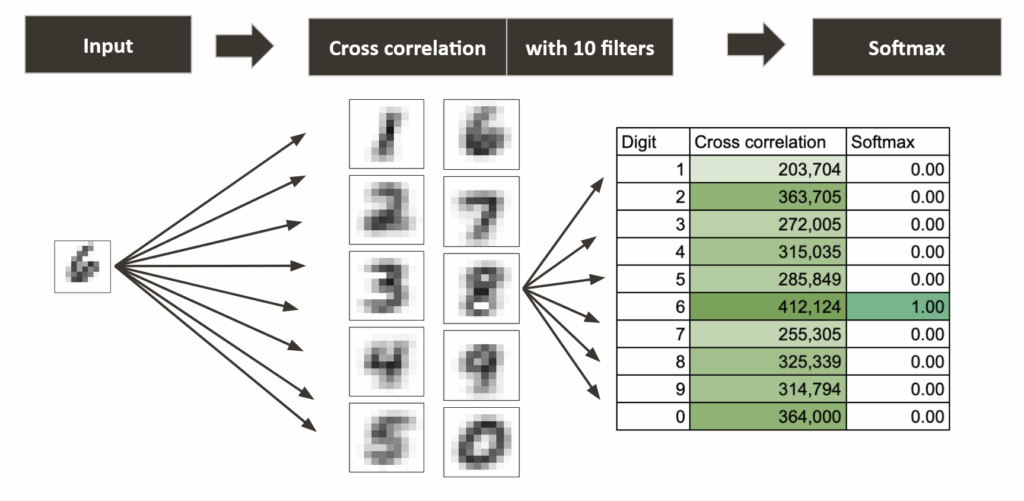
输入数字与十个平均数字滤波器的互相关操作。最高分数(经Softmax归一化)识别输入为“6” — 作者绘制
2.5 卷积还是互相关?
此时,读者可能会疑惑,既然描述的操作实际上是互相关,为何仍称之为卷积神经网络?
两者的区别微妙但简单:
- 卷积(Convolution)意味着在滤波器在图像上滑动之前,将其水平和垂直翻转。
- 互相关(Cross-correlation)意味着直接应用滤波器,不进行翻转。
欲了解更多信息,可以阅读相关文章。
由于某些历史原因,“卷积”一词沿用至今,尽管CNN中实际执行的操作是互相关。
正如所见,在大多数深度学习框架(如PyTorch或TensorFlow)中,执行“卷积”时实际使用的是互相关。

互相关与卷积 — 作者绘制
简而言之:
CNN在命名上是“卷积的”,但在实践中是“互相关的”。
3. 构建更复杂的CNN架构
3.1 使用小尺寸滤波器检测更精细的模式
在前面的例子中,使用了单个10×10的滤波器来将整个图像与一个模式进行比较。
这足以理解互相关的原理以及CNN如何检测图像与滤波器之间的相似性。
现在可以更进一步。
不再使用一个全局滤波器,而是使用几个较小的滤波器,每个尺寸为5×5。这些滤波器将着眼于图像的较小区域,检测局部细节而非整体形状。
以应用于手写数字的四个5×5滤波器为例。
输入图像可以被切割成4个较小的5×5像素部分,每个部分对应一个滤波器。
仍然可以使用所有数字的平均值作为初始滤波器。这样,每个滤波器将产生4个值,而非一个。
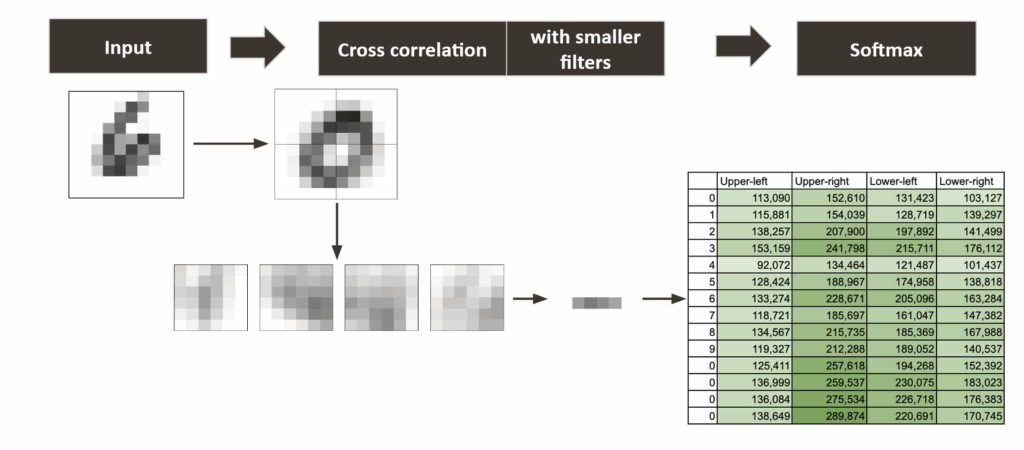
CNN中用于数字识别的小尺寸滤波器 — 作者绘制
最后,可以应用Softmax函数来获得最终预测。
但在这种简单情况下,也可以直接将所有值求和。
3.2 当数字不在图像中心时如何处理?
在之前的示例中,滤波器与图像的固定区域进行比较。一个直观的问题是,如果目标物体不在中心位置怎么办?是的,它可能出现在图像的任何位置。
解决方案实际上非常基础:只需在图像上滑动滤波器。
再次举一个简单例子:输入图像的尺寸是10×14。高度不变,宽度为14。
所以滤波器仍然是10×10,它将水平滑动图像。然后,将得到5个互相关结果。
即使不确定图像中目标的位置,也无需担忧,因为可以简单地取这5个互相关结果中的最大值来解决问题。
这就是所谓的最大池化层。
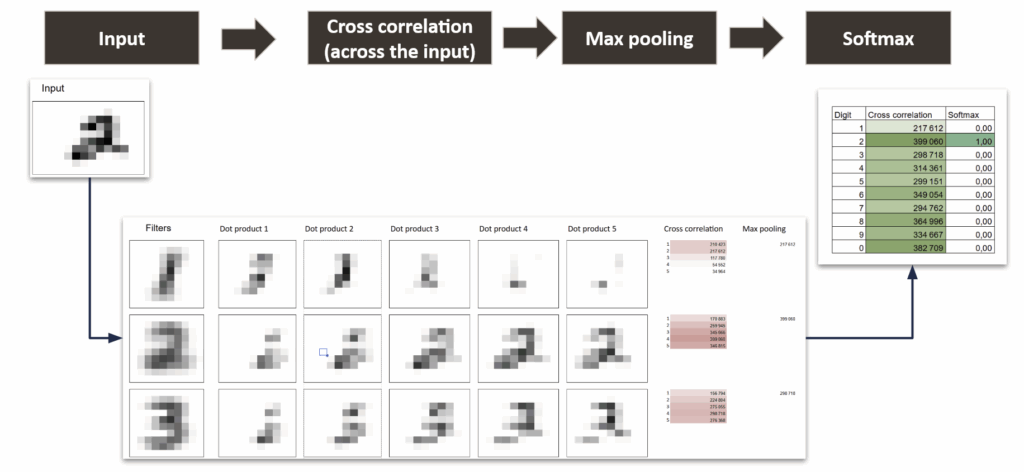
简单CNN中的最大池化 — 作者绘制
3.3 CNN中常用的其他操作
本文尝试解释了CNN中每个组件的用途。
最重要的组件是输入与滤波器之间的互相关。此外,还解释了小尺寸滤波器的作用,以及最大池化如何处理图像中可能出现在任何位置的目标。
CNN中还常用其他步骤,例如连续使用多个层或应用非线性激活函数。
这些步骤使模型更具灵活性、更鲁棒,并能够学习更丰富的模式。
它们具体为何有用?
将这个问题留给读者作为思考练习。
既然读者已理解核心思想,可以尝试思考这些步骤如何进一步提升CNN的能力,并尝试在Excel中构建具体的示例。
总结
在Excel中模拟CNN是一个有趣且实用的方法,它能直观地展示机器如何识别图像。
通过处理小型矩阵和简单的滤波器,可以深入理解CNN的核心工作步骤。




