

早在计算机与人工智能诞生之前,人类就已建立起系统推演行为的制度体系——法庭。法律系统是人类最古老的推理引擎之一,它将事实与证据作为输入,以法律条文作为推理规则,最终输出判决结果。然而法律条文从人类文明伊始就在持续演进。最早的成文法《汉谟拉比法典》(约公元前1750年)首次尝试将道德与社会推理形式化为明确的符号规则。其魅力在于清晰统一,却也因僵化而难以适应情境。数个世纪后,以“多诺霍诉史蒂文森案(1932)”为代表的普通法传统引入了相反哲学:基于先例经验的推理。当今法律体系通常是二者的结合,只是各国比例有所不同。
与法律体系中的融合形成鲜明对比的是,人工智能领域的符号主义与连接主义这对范式却难以统一。后者主导了近年人工智能的发展浪潮,通过海量数据与算力隐式学习,将知识编码于神经网络参数中。这一方向在基准性能上已被证明极为有效。那么,人工智能系统是否真的需要符号组件?
符号系统 vs 神经网络:信息压缩的视角
要回答这个问题,需从计算视角审视两类系统。符号系统与神经网络均可视为信息压缩机器——它们将世界的复杂性压缩为紧凑表征,以支持推理、预测与控制。但二者通过截然不同的机制实现压缩,体现了对“理解”本质的相反哲学。
本质上,两类范式可视为作用于原始现实的滤波器。给定输入X,每个系统学习或定义变换H(⋅),得到压缩表征Y=H(X),保留其认为有意义的信息并舍弃其余。但滤波形态迥异:符号系统类似高通滤波器,提取世界尖锐的规则轮廓而忽略平滑梯度;神经网络则近似低通滤波器,平滑局部波动以捕捉全局结构。差异不在于所见,而在于所忘。
符号系统通过离散化实现压缩。它将连续经验切分为离散类别、关系与规则:法律条文、语法体系或知识本体。每个符号作为清晰边界,在预定义框架内进行操作。此过程类似将噪声信号投影至人为设计的基向量空间——例如由“实体”“关系”等概念张成的空间。知识图谱处理句子“UIUC是一所非凡的大学,我热爱它”时,可能仅保留(UIUC,属于,机构),舍弃模式外所有信息。结果获得清晰度与可组合性,却牺牲了灵活性:本体框架之外的意义尽数消散。
神经网络则通过平滑实现压缩。它们放弃离散类别,转向平滑流形,使邻近输入产生相似激活(现代大语言模型中通常受利普希茨常数约束)。其不将数据映射至预设坐标,而是学习编码相关性的隐式几何。在此视角下,世界非规则集合,而是梯度场。这使得神经表征具有卓越适应性:能对未见示例进行插值、类比与泛化。但赋予灵活性的平滑性也导致不透明:信息相互纠缠,语义分布式呈现,可解释性消弭于泛化过程中。
| 特性 | 符号系统 | 神经网络 |
| — | — | — |
| 保留信息 | 离散的、模式定义的事实 | 频繁的、连续的统计模式 |
| 抽象来源 | 人为定义的本体 | 数据驱动的流形 |
| 鲁棒性 | 规则边缘脆弱 | 局部鲁棒但全局模糊 |
| 错误模式 | 事实遗漏(覆盖缺口) | 事实平滑(幻觉产生) |
| 可解释性 | 高 | 低 |
从信息压缩视角可总结二者差异:“神经网络是世界模糊的图像,符号系统则是缺失碎片的高清图片。”这揭示了神经符号系统作为妥协艺术的价值:通过不同尺度的协作,结合神经网络提供的全局低分辨率主干与符号组件供给的高分辨率局部细节,汲取两类范式的知识。
可扩展性挑战
尽管为神经网络添加符号组件极具吸引力,可扩展性仍是基础模型时代的重要障碍。传统神经符号系统依赖专家定义的本体/模式/符号集,假设其能覆盖所有输入情况。这对领域特定系统尚可接受,但无法应用于开放域系统——后者需要专家构建数万亿符号及其关系。
自然转向全数据驱动方案:不依赖人工构建本体,让模型从内部激活中归纳自身“符号”。稀疏自编码器是该思想的典型代表。通过将隐藏状态分解为大量稀疏特征,它们似乎提供了神经概念词典:每个特征对特定模式激活,通常可人工解读,并表现为可开关的离散单元。初看这完美解决了专家瓶颈:符号集不再需要设计,而是通过学习获得。
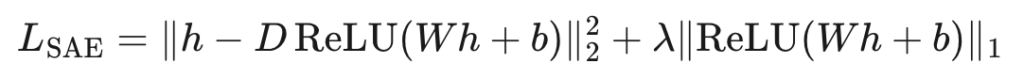
其中D称为字典矩阵,每列存储一个语义概念;第一项为隐藏状态h的重构损失,第二项为鼓励代码中神经元最小激活的稀疏惩罚项。
然而纯SAE方法存在两个根本问题。首先是计算瓶颈:将SAE作为实时符号层需每个隐藏状态与巨大字典矩阵相乘,即使代码稀疏仍须支付稠密计算成本,使其无法在基础模型尺度部署。其次是概念缺陷:SAE特征类似符号表征,但并非符号系统——缺乏显式形式语言、组合算子与可执行规则。它们揭示模型潜在空间中的概念存在,但未说明如何推理。
这并非意味应完全抛弃SAE——它们提供的是原料而非成品。不要求SAE直接成为符号系统,可将其视为模型内部概念空间与既有符号制品间的桥梁。在知识图谱、本体、规则库、分类体系等符号制品中,推理可按定义执行。基于大模型隐藏状态训练的高质量SAE成为共享“概念坐标系”:不同符号系统可通过其符号与SAE特征的关联实现对齐。
相较于简单并列查询符号系统,该方法具备多重优势。首先支持跨系统符号合并与别名识别:若不同形式主义的两个符号反复激活几乎相同的SAE特征集,可证明它们对应相同神经概念并进行链接。其次促进跨系统关系发现:在人工设计中相距遥远但在SAE空间中紧密相邻的符号,指示了未编码的桥梁。第三,SAE激活提供模型中心的显著性度量:在神经概念空间无明确对应物的符号可考虑剪枝,而无匹配符号的强SAE特征则揭示当前抽象体系的共同盲点。
关键在于此SAE用法仍保持可扩展性。昂贵SAE离线训练,符号系统本身无需扩展至基础模型规模。推理时神经网络在连续潜在空间承担重负荷,符号制品仅在需要显式结构与可问责性的节点塑造、约束或审计行为。SAE通过将所有异构符号视图锚定至模型的学习概念图,使得比较、合并与改进无需构建庞杂的专家设计符号副本。
何时SAE能成为符号桥梁?
上述图景默认SAE“足够好”以充当有意义坐标系。实际需要哪些特性?无需完美,亦无需SAE在所有维度超越人类符号系统,而是需要若干更务实但关键的性质:
– 语义连续性:表达相同底层概念的输入应在稀疏代码中诱导相似支持模式——相同SAE特征子集应保持激活,而非在轻微改写或语境变化下闪烁。
– 部分可解释性:无需理解每个特征,但需相当比例特征可被稳定描述,以便在概念层面进行合并与调试。
– 行为相关性:SAE发现的特征必须实际影响模型输出——对其干预或条件化应系统性地改变或预测模型决策。
– 容量与基础:SAE仅能重构基模型已存在的结构。基模型本身需足够庞大且训练充分,使其隐藏状态编码多样非平凡抽象集。同时SAE需足够维度与过完备性:若代码空间过小,许多不同概念将被迫共享特征,导致纠缠与不稳定表征。
语义连续性
在纯函数逼近层面,使用ReLU或GELU激活的深度神经网络实现利普希茨连续映射:输入微小扰动不会导致输出逻辑的任意跳跃。但此类连续性与稀疏自编码器需求截然不同。对基模型而言,少量神经元开关可被下游层与冗余性吸收;只要最终逻辑平滑变化即可满足。
在SAE中,关注点不再是平滑输出——而是将稀疏代码在残差流上的重构支持模式视为原符号对象。“概念”与特定代码子集激活相关联。这使得几何结构更为脆弱:若底层表征的微小变化使SAE层预激活跨越ReLU阈值,代码中神经元将突然开关,从符号视角看概念即出现或消失。无下游网络可平均此效应,代码本身即目标表征。
SAE构建中的稀疏惩罚加剧此问题。标准SAE目标结合重构损失与激活的ℓ1惩罚,显式鼓励多数神经元值接近零。结果许多有用神经元仍处于激活边界附近:需要时略高于零,不需要时略低于零——此现象称为SAE中的“激活收缩”。这对支持模式层级的语义连续性有害:输入的微小扰动可改变非零神经元,即使底层语义几乎未变。因此基模型的利普希茨连续性不能自动保证SAE空间中稳定非零代码子集,支持层级稳定性需作为独立设计目标明确评估。
部分可解释性
SAE定义过完备字典存储从数据学习特征。仅需字典条目子集为可解释特征。即使对该子集,特征含义仅需近似准确。将既有符号对齐至SAE空间时,依赖的是SAE层激活模式:在符号“启用”语境下探测模型,记录生成稀疏代码,使用聚合代码作为该符号的嵌入。不同系统中嵌入相近的符号可被链接或合并,无需为每个特征分配人类可读语义。
可解释特征则扮演更聚焦角色:在此激活几何内部提供人类可理解的锚点。若某特征具合理准确描述,所有重度加载该特征的符号继承共享语义提示,使得合并后的符号空间更易检查、调试与组织。换言之,无需完美命名字典。需要的是足够容量以使重要概念获得自身方向,以及相当规模、行为相关的特征子集,其近似含义足够稳定以充当锚点。其余过完备代码可作为匿名背景存在;即使未被命名,仍贡献于SAE空间中的距离与聚类。
通过反事实验证行为相关性
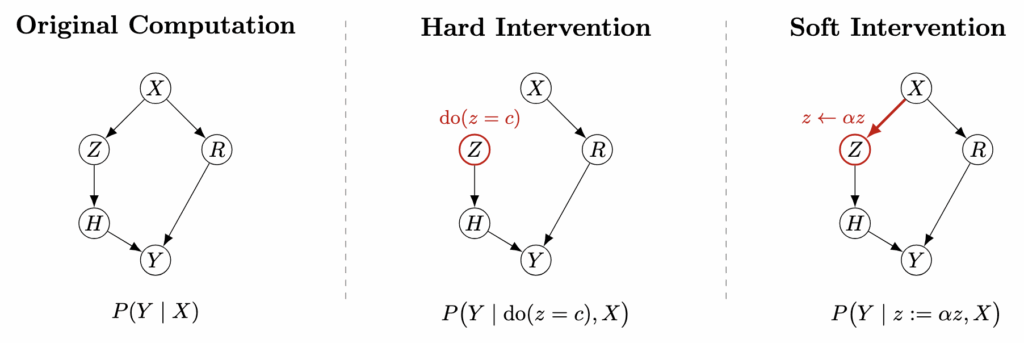
作为桥梁组成部分的特征,仅当实际影响模型行为时才有价值——不仅与数据模式相关。从因果角度,关注特征是否位于网络计算从输入到输出的因果路径上:若在固定其他变量前提下扰动特征,模型行为是否按其预期含义改变?
形式上,改变特征类似于因果意义上的干预,即重写该内部变量并重新计算。但不同于经典因果推理建模,无需珍珠的do-演算识别干预后概率。神经网络是完全可观测与可干预系统,可直接对内部节点执行干预并观察新输出。在此意义上,神经网络允许实施现实社会或经济系统中不可能的理想化干预。
对SAE特征干预概念类似但实现不同。通常不知特征空间中任意值的含义,故上述硬干预可能无意义。取而代之的是放大或抑制既有特征幅度,此行为更接近软干预:结构图保持不变,但特征有效影响被修改。由于SAE将隐藏激活重构为少量语义特征线性组合,可改变这些特征系数以实施有意义的局部干预,而不影响其他特征。
符号系统压缩作为对齐过程
现在换种视角。神经网络将世界压缩为高度抽象的连续流形,符号系统则将其压缩至人为定义的语义空间,其坐标轴可评判系统行为。由此观之,将信息压缩至符号空间是对齐过程,其中混乱的高维世界被投影至反映人类概念、兴趣与价值观的空间。
当引入“注意义务”“暴力威胁”或“受保护属性”等符号时,不仅是发明标签。此压缩过程同时完成三件事:
– 选择系统必须关注的世界方面。
– 创建共享词汇表,使不同利益相关者能在争议与审计中可靠指向相同事物。
– 将这些符号转为承诺点:一旦写入,即可被引用、质疑与重新解释,但不能悄然抹除。
相较之下,纯神经压缩完全存于模型内部。其潜在轴未命名,几何结构私有,内容可能随训练数据或微调目标改变。此类表征极善泛化,却难作为责任载体。单独在此空间中,难以说明系统对任何人负有义务,或应视哪些区别为不变。换言之,神经压缩服务于预测,符号压缩服务于与人类规范框架的对齐。
一旦将符号系统视为对齐映射而非规则列表,其与可问责性的联系便直接显现。要求“模型不得基于受保护属性歧视”或“模型须应用注意义务标准”,即是坚持某些符号区别以稳定方式反映于其内部概念空间——且能够定位、探测并在必要时修正这些反映。这种可问责性通常值得追求,即便以部分模型能力为代价。
从隐秘法到共享符号
《左传》记载晋国叔向致信郑国子产:“刑不可知,则威不可测。”数个世纪中,统治阶层通过秘而不宣维持秩序,认为恐惧在理解终止处滋生。公元前536年子产打破传统,铸刑书于青铜鼎公之于众,成为古代中国历史里程碑。现今人工智能系统面临相似问题:谁将成为下一位子产?
参考文献
- Bloom, J., Elhage, N., Nanda, N., Heimersheim, S., & Ngo, R. (2024). Scaling monosemanticity: Sparse autoencoders and language models. Anthropic.
- Garcez, A. d’Avila, Gori, M., Lamb, L. C., Serafini, L., Spranger, M., & Tran, S. N. (2019). Neural-symbolic computing: An effective methodology for principled integration of machine learning and reasoning. FLAIRS Conference Proceedings, 32, 1–6.
- Gao, L., Dupré la Tour, T., Tillman, H., Goh, G., Troll, R., Radford, A., Sutskever, I., Leike, J., & Wu, J. (2024). Scaling and evaluating sparse autoencoders.
- Bartlett, P. L., Foster, D. J., & Telgarsky, M. (2017). Spectrally-normalized margin bounds for neural networks. Advances in Neural Information Processing Systems, 30, 6241–6250.
- Chiang, T. (2023, February 9). ChatGPT is a blurry JPEG of the Web. The New Yorker.
- Pearl, J. (2009). Causality: Models, reasoning, and inference (2nd ed.). Cambridge University Press.
- Donoghue v Stevenson [1932] AC 562 (HL).





