

向量数据库确实解决了一个实际问题,并且在许多情况下,它们是RAG系统的正确选择。但关键在于:仅仅因为使用了嵌入向量,并不意味着就一定需要一个向量数据库。
目前存在一种日益明显的趋势,即每个RAG实现都从接入一个向量数据库开始。对于大规模、持久化的知识库而言,这或许合理,但这并非总是最高效的路径,尤其是在应用场景更具动态性或对时间更敏感的情况下。
在Planck,嵌入向量被用于增强基于大语言模型的系统。然而,在一个实际应用中,选择避免使用向量数据库,转而采用一个简单的键值存储,结果证明后者是更合适的选择。
在深入探讨该案例之前,可以通过一个简化的通用场景来解释其原因。
示例场景
设想一个简单的RAG风格系统。用户上传几个文本文件,可能是报告或会议记录。这些文件被分割成块,为每个块生成嵌入向量,并利用这些嵌入向量来回答问题。用户在接下来的几分钟内提出少量问题,然后离开。此时,文件及其嵌入向量都已无用,可以安全丢弃。
换言之,数据是临时性的,用户只会提出少量问题,并且希望尽可能快地得到答案。
现在请稍作停顿并自问:
这些嵌入向量应该存储在哪里?
大多数人的直觉反应是:“我有嵌入向量,所以我需要一个向量数据库”。但请稍作思考,看看这个抽象概念背后实际发生了什么。当向向量数据库发送嵌入向量时,它并非仅仅是“存储”它们。它会构建一个索引以加速相似性搜索。索引构建工作正是许多神奇效果的来源,也是大量成本所在。
对于一个长期存在、大规模的知识库,这种权衡完全合理:只需支付一次索引构建成本(或在数据变更时增量支付),然后将其分摊到数百万次查询中。但在上述示例场景中,情况并非如此。恰恰相反:系统需要不断添加小型、一次性的嵌入向量批次,每个批次只回答极少量的查询,然后丢弃所有内容。
因此,真正的问题不是“我应该使用向量数据库吗?”,而是“索引构建工作是否值得?”要回答这个问题,可以参考一个简单的基准测试。
基准测试:无索引检索 vs. 索引检索

图片由 Julia Fiander 发布于 Unsplash
本节内容技术性较强。将涉及Python代码并解释底层算法。如果具体的实现细节与您无关,可以跳过直接阅读 结果 部分。
需要比较两种系统:
- 无索引:完全不构建索引,仅将嵌入向量保存在内存中并直接扫描。
- 向量数据库:预先支付索引构建成本,以使每次查询更快。
首先,考虑“无向量数据库”的方法。当查询到来时,计算查询嵌入向量与所有存储嵌入向量之间的相似度,然后选择top-k个最相似的。这本质上就是没有任何索引的K-最近邻算法。
import numpy as np
def run_knn(embeddings: np.ndarray, query_embedding: np.ndarray, top_k: int) -> np.ndarray:
sims = embeddings @ query_embedding
return sims.argsort()[-top_k:][::-1]
该代码使用点积作为余弦相似度的代理(假设向量已归一化),并对分数进行排序以找到最佳匹配。它实际上就是扫描所有向量并挑选最接近的那些。
现在,看看向量数据库通常做什么。在底层,大多数向量数据库依赖于一个近似最近邻索引。ANN方法牺牲一点精度以大幅提升搜索速度,而HNSW是其中最广泛使用的算法之一。将使用hnswlib库来模拟索引行为。
import numpy as np
import hnswlib
def create_hnsw_index(embeddings: np.ndarray, num_dims: int) -> hnswlib.Index:
index = hnswlib.Index(space='cosine', dim=num_dims)
index.init_index(max_elements=embeddings.shape[0])
index.add_items(embeddings)
return index
def query_hnsw(index: hnswlib.Index, query_embedding: np.ndarray, top_k: int) -> np.ndarray:
labels, distances = index.knn_query(query_embedding, k=top_k)
return labels[0]
为了看清权衡点,可以生成一些随机嵌入向量,将其归一化,并测量每个步骤所需的时间:
import time
import numpy as np
import hnswlib
from tqdm import tqdm
def run_benchmark(num_embeddings: int, num_dims: int, top_k: int, num_iterations: int) -> None:
print(f"Benchmarking with {num_embeddings} embeddings of dimension {num_dims}, retrieving top-{top_k} nearest neighbors.")
knn_times: list[float] = []
index_times: list[float] = []
hnsw_query_times: list[float] = []
for _ in tqdm(range(num_iterations), desc="Running benchmark"):
embeddings = np.random.rand(num_embeddings, num_dims).astype('float32')
embeddings = embeddings / np.linalg.norm(embeddings, axis=1, keepdims=True)
query_embedding = np.random.rand(num_dims).astype('float32')
query_embedding = query_embedding / np.linalg.norm(query_embedding)
start_time = time.time()
run_knn(embeddings, query_embedding, top_k)
knn_times.append((time.time() - start_time) * 1e3)
start_time = time.time()
vector_db_index = create_hnsw_index(embeddings, num_dims)
index_times.append((time.time() - start_time) * 1e3)
start_time = time.time()
query_hnsw(vector_db_index, query_embedding, top_k)
hnsw_query_times.append((time.time() - start_time) * 1e3)
print(f"BENCHMARK RESULTS (averaged over {num_iterations} iterations)")
print(f"[Naive KNN] Average search time without indexing: {np.mean(knn_times):.2f} ms")
print(f"[HNSW Index] Average index construction time: {np.mean(index_times):.2f} ms")
print(f"[HNSW Index] Average query time with indexing: {np.mean(hnsw_query_times):.2f} ms")
run_benchmark(num_embeddings=50000, num_dims=1536, top_k=5, num_iterations=20)
结果
在此示例中,使用了50,000个维度为1,536的嵌入向量(与OpenAI的text-embedding-3-small匹配),并检索top-5个最近邻。具体结果会因配置不同而异,但所关注的核心模式是相同的。
建议使用您自己的数据运行此基准测试,这是了解权衡在您特定用例中如何体现的最佳方式。
平均而言,朴素的KNN搜索每次查询耗时24.54毫秒。为相同嵌入向量构建HNSW索引大约需要277秒。一旦索引构建完成,每次查询耗时约0.47毫秒。
由此可以估算盈亏平衡点。朴素KNN与索引查询之间的时间差为每次查询24.07毫秒。这意味着需要11,510次查询,每次查询节省的时间才能补偿构建索引所花费的时间。
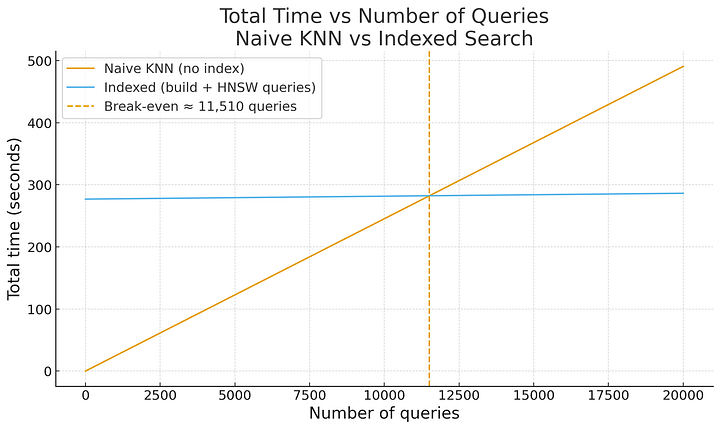
使用基准测试代码生成:比较朴素KNN与索引搜索效率的图表
此外,即使嵌入向量数量和top-k值不同,盈亏平衡点也保持在数千次查询,并且处于一个相当窄的范围内。不会出现仅需几十次查询索引就开始产生回报的情况。
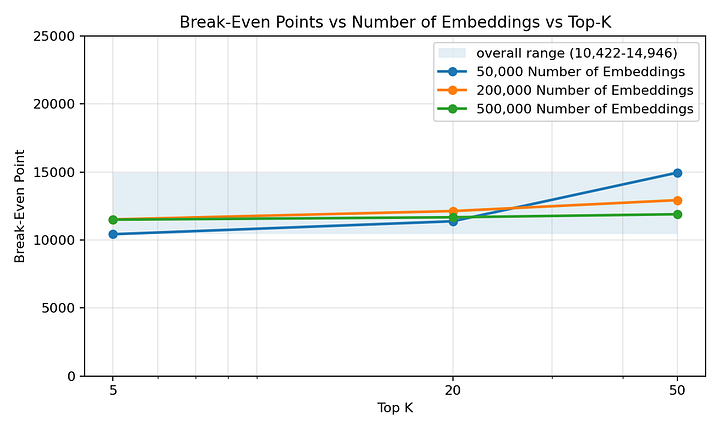
使用基准测试代码生成:展示不同嵌入向量数量和top-k设置下盈亏平衡点的图表
现在将其与示例场景进行比较。用户上传一小批文件并提出几个问题,而不是数千个。系统永远达不到索引产生回报的点。相反,索引步骤只会延迟系统回答第一个问题的时间,并增加操作复杂性。
对于这种短生命周期、按用户划分的上下文,简单的内存KNN方法不仅更易于实现和操作,而且端到端速度也更快。
如果内存存储不可行,无论是由于系统是分布式的,还是需要将用户状态保留几分钟,都可以使用像Redis这样的键值存储。可以将用户请求的唯一标识符存储为键,并将所有嵌入向量存储为值。
这提供了一种轻量级、低复杂度的解决方案,非常适合短生命周期、低查询量上下文的用例。
实际案例:为何选择键值存储

图片由 Gavin Allanwood 发布于 Unsplash
在Planck,系统需要回答关于企业的保险相关问题。一个典型的请求始于企业名称和地址,然后检索关于该特定企业的实时数据,包括其在线状态、注册信息和其他公开记录。这些数据构成上下文,并利用大语言模型和算法基于此回答问题。
关键在于,每次收到请求时,都会生成全新的上下文。系统不会复用现有数据,数据是按需获取的,并且最多只保持几分钟的相关性。
如果回想之前的基准测试,这种模式应该已经触发“这不是向量数据库用例”的直觉。
每次收到请求时,都会为短生命周期数据生成新的嵌入向量,这些数据可能只被查询几百次。在向量数据库中为这些嵌入向量建立索引会增加不必要的延迟。相比之下,使用Redis,可以立即存储嵌入向量,并在应用程序代码中运行快速的相似性搜索,几乎没有索引延迟。
这就是选择Redis而非向量数据库的原因。虽然向量数据库擅长处理大量嵌入向量并支持快速的最近邻查询,但它们引入了索引开销,而在该案例中,这种开销并不值得。
结论
如果需要存储数百万个嵌入向量,并支持跨共享语料库的高查询负载,那么向量数据库会是更合适的选择。确实,存在一些真正需要并受益于向量数据库的用例。
但仅仅因为使用了嵌入向量或正在构建RAG系统,并不意味着就应该默认选择向量数据库。
每种数据库技术都有其优势和权衡。最佳选择始于对数据和用例的深刻理解,而不是盲目追随趋势。




