

在构建RAG系统时,工程师常直接将原始JSON嵌入向量数据库。但实践表明,这种做法会导致显著的性能下降。现代嵌入模型基于BERT架构(即Transformer的编码器部分),其训练数据以无结构文本为主,核心目标是捕捉语义信息。尽管通用嵌入模型能提供强大的检索能力,但JSON结构数据与其训练范式存在本质冲突——直接将JSON嵌入向量空间会导致效果远低于最优水平。
技术原理分析
分词机制的局限
嵌入处理的第一步是分词,现代模型采用Byte-Pair Encoding或WordPiece算法,这些针对自然语言优化的方法在处理JSON时会遭遇挑战。以"usd":10,为例,系统不会将其识别为键值对,而是拆分为:
- 标点符号:引号
"、冒号:、逗号, - 独立标记:
usd和10
这导致数据信噪比骤降。自然语言中90%以上标记承载语义信息,而JSON中约25%的标记被花括号、引号等结构符号占据,形成语义干扰。
注意力机制失效
Transformer的核心优势在于注意力机制能动态评估标记关联性。在自然语言句子商品价格为10美元或9欧元中,模型基于海量训练数据可轻松建立10与价格的语义关联。但在原始JSON格式中:
"price":{
"usd":10,
"eur":9,
}模型无法理解符号背后的逻辑关系,关键语义关联被语法结构掩盖。
均值池化的数学损失
生成最终嵌入向量的最后步骤是均值池化操作,其数学表达式为所有标记向量的算术平均:
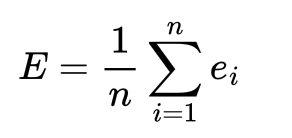
当25%的标记为无语义的符号时,最终向量会被拉离真实的语义中心。用户用自然语言查询时,噪声标记导致查询向量与数据向量的距离扩大,直接降低召回精准度。
解决方案:结构化数据扁平化
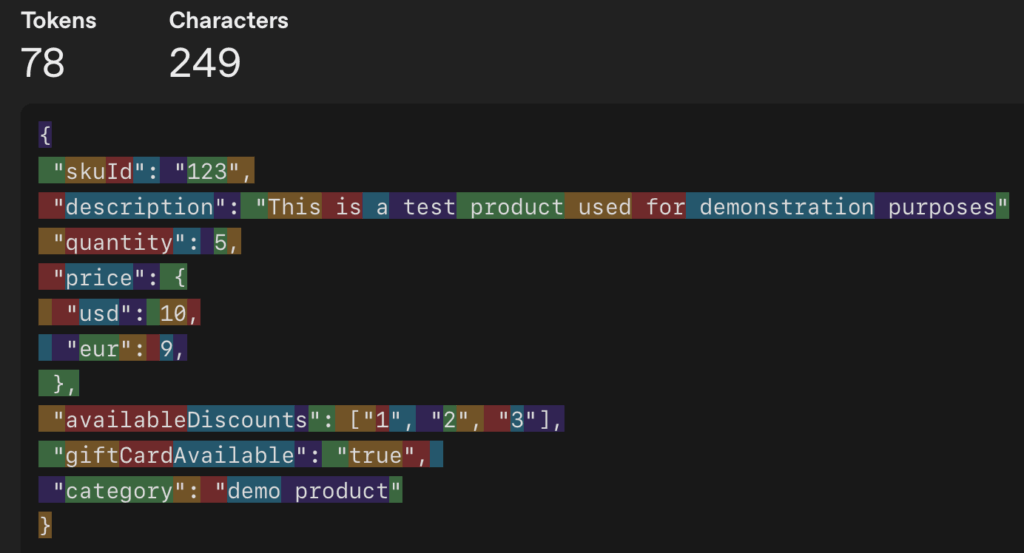
通过将JSON转换为自然语言格式可解决上述问题。以商品数据对象为例:
{
"skuId":"123",
"description":"演示用测试商品",
"quantity":5,
"price":{"usd":10,"eur":9},
"availableDiscounts":["1","2","3"]
}
设计转换模板重建自然语言表述:
SKU为{skuId}的商品描述:{description}
库存数量:{quantity}
价格:{price.usd}美元/{price.eur}欧元
可用折扣ID:{availableDiscounts}转换后文本的分词结果:
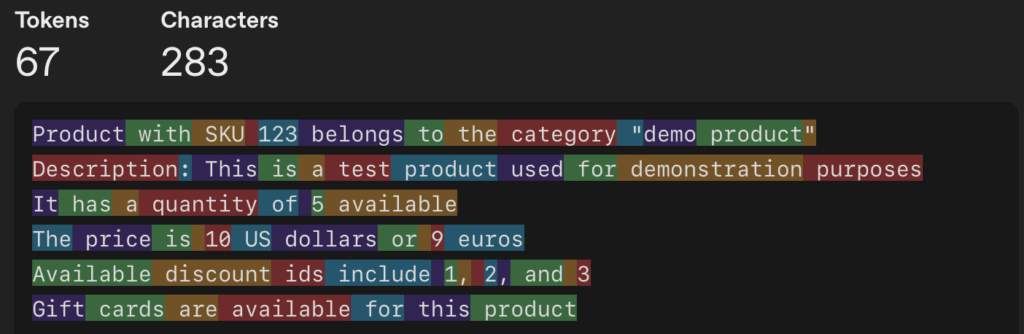
不仅总标记数减少14%,语义密度提升37%,关键数据关系的可辨识度显著增强。
实验验证
在亚马逊ESCI数据集(含3,809款商品和5,000条查询)上,使用all-MiniLM-L6-v2嵌入模型进行对照实验:
- 构建双FAISS索引:原始JSON格式 vs 扁平化文本
- 核心指标对比:
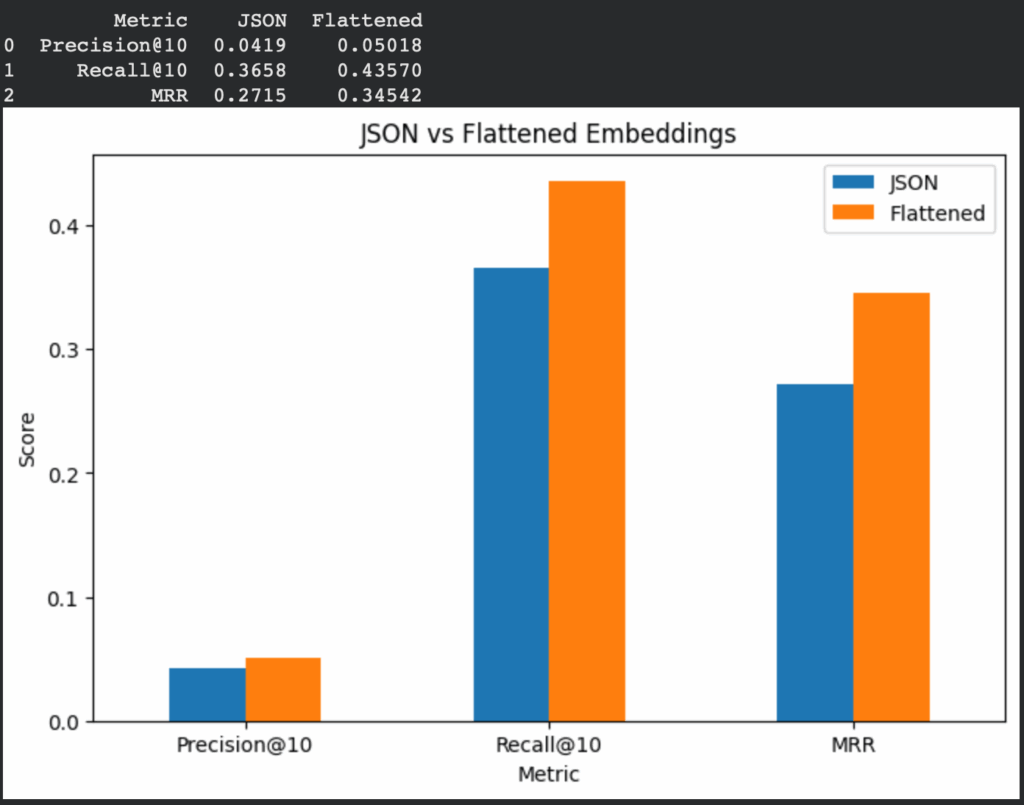
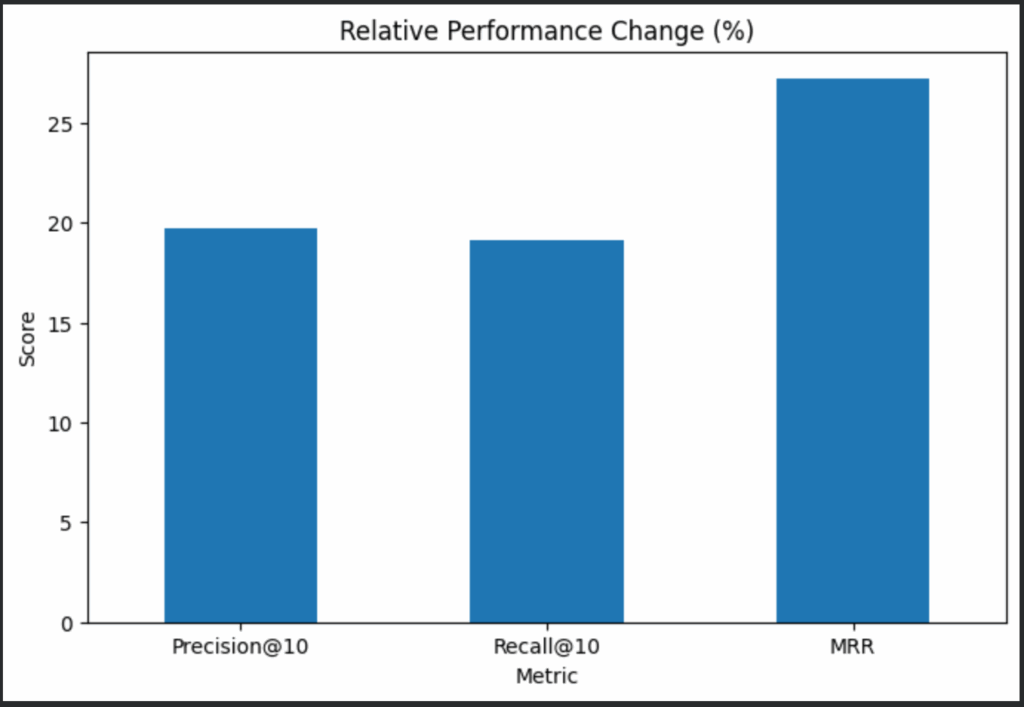
实验结果:扁平化处理后,Recall@10提升19.1%,MRR提升27.2%。证明结构化预处理可使检索系统达到峰值性能。
参考文献
[1] 完整实验代码:Colab Notebook
[2] all-MiniLM-L6-v2模型:HuggingFace链接
[3] 亚马逊ESCI数据集:原始数据源





