

Cerebras Systems,其 CS-2 AI 训练计算机拥有全球最大的单芯片,宣布其计算机新增的内存系统将神经网络的训练规模提升了 100 倍以上,达到 120 万亿个参数。此外,该公司还提出了两种方案,通过连接多达 192 个系统以及有效处理神经网络中的“稀疏性”来加速训练。Cerebras 的联合创始人兼首席硬件架构师 Sean Lie 在 IEEE Hot Chips 33 大会上详细介绍了这项技术。
这些进展源于四项技术的结合——权重流、MemoryX、SwarmX 和可选稀疏性。前两种技术将 CS-2 可训练的神经网络规模扩展了两个数量级,并标志着 Cerebras 计算机运行方式的转变。
CS-2 旨在快速训练大型神经网络。节省时间的主要原因在于芯片足够大,可以将整个网络(主要由称为权重和激活的参数集组成)存储在芯片上。其他系统会浪费时间和能量,因为它们必须不断地从 DRAM 中加载网络的一部分到芯片上,然后将其存储起来,为下一部分腾出空间。
凭借 40GB 的片上 SRAM,计算机的处理器 WSE2 可以容纳当今所有常见神经网络,即使是最庞大的网络。但这些网络正在快速增长,仅在过去几年就增长了 1000 倍,现在已经接近 1 万亿个参数。因此,即使是晶圆大小的芯片也开始不堪重负。
要理解解决方案,首先需要了解训练过程中发生的事情。训练包括将神经网络将从中学习的数据流式传输进来,并衡量网络的准确率。这种差异用于计算“梯度”——每个权重需要调整多少才能使网络更准确。该梯度通过网络层层反向传播。然后重复整个过程,直到网络达到所需的准确率。在 Cerebras 的原始方案中,只有训练数据被流式传输到芯片上。权重和激活保持在原位,梯度在芯片内传播。
“新的方法是将所有激活保持在原位,并将 [权重] 参数输入,”Feldman 解释道。该公司为 CS-2 构建了一个名为 MemoryX 的硬件附加组件,该组件将权重存储在 DRAM 和 Flash 的混合体中,并将它们流式传输到 WSE2,在那里它们与存储在处理器芯片上的激活值交互。然后将梯度信号发送到 MemoryX 单位以调整权重。该公司表示,通过权重流和 MemoryX,单个 CS-2 现在可以训练具有多达 120 万亿个参数的神经网络。
Feldman 说,他和他的联合创始人早在 2015 年创立公司时就看到了对权重流的需求。“我们从一开始就知道我们需要两种方法,”他说。然而,“我们可能低估了世界进入超大参数规模的速度。”Cerebras 从 2019 年初开始为权重流增加工程资源。
Cerebras 在 Hot Chips 上发布的另外两项技术旨在加速训练过程。SwarmX 是一种硬件,它扩展了 WSE2 的片上高带宽网络,使其能够包含多达 192 个 CS-2。构建计算机集群来训练大型 AI 网络充满了困难,因为网络必须在多个处理器之间分割。Feldman 说,结果往往无法很好地扩展。也就是说,将集群中的计算机数量增加一倍通常不会使训练速度增加一倍。
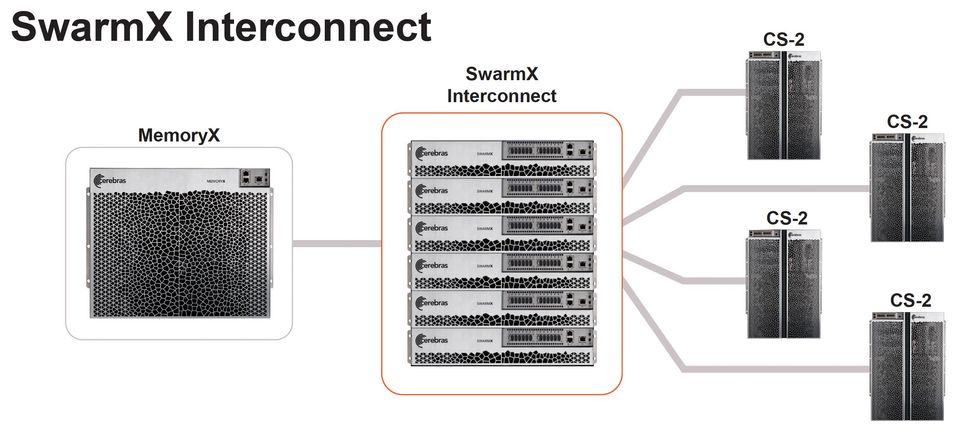
Cerebras 的 MemoryX 系统为 CS-2 中的神经网络训练提供权重并对其进行操作。SwarmX 网络允许多达 192 个 CS-2 在同一个网络上协同工作。Cerebras
“我们终于解决了最紧迫的问题之一:如何让构建集群变得像切蛋糕一样容易,”Feldman 说。
由于单个 WSE2 可以容纳网络中的所有激活,因此 Cerebras 可以提出一种方案,将计算机数量增加一倍确实可以使训练速度增加一倍。首先,将代表神经网络的一整套激活复制到每个 CS-2 上。(为简单起见,我们假设你只有两台 AI 计算机。)然后将同一组权重流式传输到两台计算机。但是训练数据被分成两半,一半数据发送到每个 CS-2。使用一半的数据,计算梯度需要一半的时间。每个 CS-2 将得到不同的梯度,但这些梯度可以组合起来更新 MemoryX 中的权重。然后将新的权重流式传输到两个 CS-2,就像之前一样,重复该过程,直到你得到一个准确的网络,在这种情况下,所需时间是使用一台计算机的一半。
Cerebras 在一个由“数千万个 [AI] 内核”组成的机器集群上进行了这项工作,Feldman 说。每个内核有 850,000 个,这应该相当于至少 20 个 CS-2。该公司模拟了 192 台机器的全部效果,显示出线性改进,一直到 120 万亿个参数的网络。

神经网络权重流向由 SwarmX 系统连接的 CS-2 计算机。训练数据被分割并传递给 CS-2,CS-2 计算反向传播梯度,这些梯度被组合并传递给 MemoryX。Cerebras
Lie 在 Hot Chips 上报告的最后一项创新被称为稀疏性。这是一种在不影响网络准确率的情况下减少训练运行中涉及的参数数量的方法。稀疏性是 AI 研究中的一个巨大领域,但对于 CS-2 来说,它在很大程度上涉及到永远不会乘以零。任何这样的努力都是浪费时间和精力,因为结果将始终为零。“如果你不做愚蠢的事情,它就会花费更少的时间,”他说。
Feldman 说,WSE2 内核架构旨在比其他处理器在更细粒度的级别上发现这些机会。他打了个比喻,就像一个堆满了箱子的托盘。大多数系统只能在托盘级别处理稀疏性。如果托盘上的所有箱子都是空的,就可以安全地将其扔掉。但 WSE2 的设计是在箱子级别工作的。
据该公司称,这四项创新的结合应该让 Cerebras 计算机在神经网络方面保持领先地位,即使神经网络的连接数量增长到脑级——大约 100 万亿个参数。




