

机器学习领域一直在寻求一个标准化的衡量体系,而 MLPerf 推出的 Inference v1.0 正是这一努力的里程碑。这场盛大的竞赛,如同一场 AI 界的奥运会,吸引了 1994 个 AI 系统参与,他们使用一组标准化的神经网络,在统一的条件下,比拼着谁家的 AI 模型能更快地处理新数据。此外,MLPerf 还设立了能效测试,吸引了 850 个参赛者。
这场竞赛是 MLPerf 及其母组织 MLCommons 经过多次试运行,最终确立了最佳测量标准后,正式推出的首个版本。而在这场首届正式比赛中,一如既往,英伟达成为了最大的赢家。
参赛者们使用各种软件和系统,规模从树莓派到超级计算机不等,这些系统搭载了来自 AMD、Arm、Centaur Technology、Edgecortix、英特尔、英伟达、高通和赛灵思等公司的处理器和加速芯片。参赛者来自 17 家机构,包括阿里巴巴、Centaur、戴尔、富士通、技嘉、惠普、Krai、联想、Moblint、Neuchips 和超微等。
尽管参赛者阵容如此多元,但大多数系统都使用英伟达 GPU 来加速其 AI 功能。其他 AI 加速器也参与了竞赛,其中最引人注目的是高通的 AI 100 和 Edgecortix 的 DNA。然而,在众多 AI 加速器初创公司中,只有 Edgecortix 参与了竞赛。而英特尔则选择展示其 CPU 的性能,并没有推出其斥资 20 亿美元收购的 AI 硬件初创公司 Habana 的产品。
在深入了解谁家的 AI 模型速度最快之前,我们需要先了解这些基准测试的工作原理。MLPerf 与著名的超级计算机排行榜 Top500 不同,Top500 只需要一个数值就能告诉你大部分信息。而 MLPerf 认为,机器学习的需求太过多样化,无法用像每瓦特兆次运算这样的指标来衡量,而这正是 AI 加速器研究中经常使用的指标。
首先,系统需要在六个神经网络上进行测试,参赛者可以选择参加其中一个或多个测试。
- BERT,全称 Bi-directional Encoder Representation from Transformers,是一种自然语言处理 AI,由谷歌贡献。给定一个问题输入,BERT 会预测一个合适的答案。
- DLRM,全称 Deep Learning Recommendation Model,是一种推荐系统,经过训练可以优化点击率。它被用于推荐在线购物商品,以及对搜索结果和社交媒体内容进行排名。Facebook 是 DLRM 代码的主要贡献者。
- 3D U-Net 用于医疗影像系统,可以识别 MRI 扫描中哪些 3D 体素是肿瘤的一部分,哪些是健康组织。它是在一个脑肿瘤数据集上进行训练的。
- RNN-T,全称 Recurrent Neural Network Transducer,是一种语音识别模型。给定一段语音输入,它会预测相应的文本。
- ResNet 是图像分类算法的鼻祖。本轮比赛使用的是 ResNet-50 版本 1.5。
- SSD,全称 Single Shot Detector,可以识别图像中的多个物体。这是自动驾驶汽车用来识别重要物体(如其他汽车)的技术。本轮比赛使用的是 MobileNet 版本 1 或 ResNet-34,具体取决于系统的规模。
参赛者被分为两类:运行在数据中心的系统和运行在“边缘”的系统(例如,在商店中、嵌入在安全摄像头中等等)。
数据中心参赛者在两种条件下进行测试。第一种情况称为“离线”,所有数据都存储在一个数据库中,系统可以尽可能快地读取数据。第二种情况更接近数据中心的真实情况,数据以突发的方式到达,系统必须能够快速准确地完成工作,以便处理下一批数据。
边缘参赛者也需要处理离线场景。但他们还需要处理单流数据测试(例如,对于语言处理,处理单个对话)和多流数据测试(例如,自动驾驶汽车需要处理来自多个摄像头的多流数据)。
看懂了吗?没有?别担心,英伟达用一张图总结了所有内容:
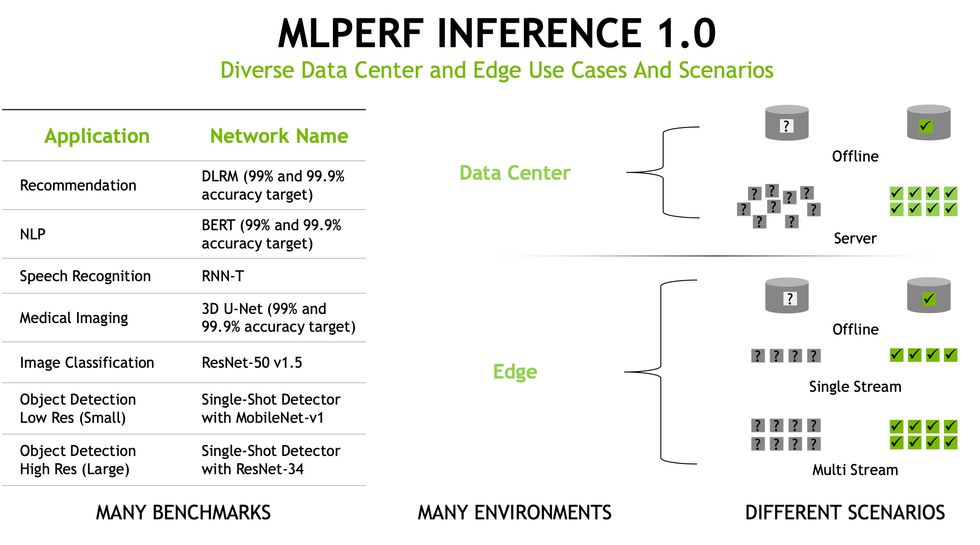
图片:NVIDIA
最后,能效测试通过测量墙上插座的功耗来进行,并对 10 分钟的功耗进行平均,以消除处理器调整电压和频率导致的功耗波动。
以下是每个类别中的最佳成绩:
速度最快
数据中心(市售系统,按服务器条件排名)
| 图像分类 | 目标检测 | 医学影像 | 语音转文本 | 自然语言处理 | 推荐 | |
|---|---|---|---|---|---|---|
| 提交者 | 浪潮 | 戴尔EMC | 英伟达 | 戴尔EMC | 戴尔EMC | 浪潮 |
| 系统名称 | NF5488A5 | Dell EMC DSS 8440 (10x A100-PCIe-40GB) | NVIDIA DGX-A100 (8x A100-SXM-80GB, TensorRT) | Dell EMC DSS 8440 (10x A100-PCIe-40GB) | Dell EMC DSS 8440 (10x A100-PCIe-40GB) | NF5488A5 |
| 处理器 | AMD EPYC 7742 | Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz | AMD EPYC 7742 | Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz | Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz | AMD EPYC 7742 |
| 处理器数量 | 2 | 2 | 2 | 2 | 2 | 2 |
| 加速器 | NVIDIA A100-SXM-80GB | NVIDIA A100-PCIe-40GB | NVIDIA A100-SXM-80GB | NVIDIA A100-PCIe-40GB | NVIDIA A100-PCIe-40GB | NVIDIA A100-SXM-80GB |
| 加速器数量 | 8 | 10 | 8 | 10 | 10 | 8 |
| 服务器查询/秒 | 271,246 | 8,265 | 479.65 | 107,987 | 26,749 | 2,432,860 |
| 离线样本/秒 | 307,252 | 7,612 | 479.65 | 107,269 | 29,265 | 2,455,010 |
边缘(市售系统,按单流延迟排名)
| 图像分类 | 目标检测(小) | 目标检测(大) | 医学影像 | 语音转文本 | 自然语言处理 | |
|---|---|---|---|---|---|---|
| 提交者 | 英伟达 | 英伟达 | 英伟达 | 英伟达 | 英伟达 | 英伟达 |
| 系统名称 | NVIDIA DGX-A100 (1x A100-SXM-80GB, TensorRT, Triton) | NVIDIA DGX-A100 (1x A100-SXM-80GB, TensorRT, Triton) | NVIDIA DGX-A100 (1x A100-SXM-80GB, TensorRT, Triton) | NVIDIA DGX-A100 (1x A100-SXM-80GB, TensorRT) | NVIDIA DGX-A100 (1x A100-SXM-80GB, TensorRT) | NVIDIA DGX-A100 (1x A100-SXM-80GB, TensorRT) |
| 处理器 | AMD EPYC 7742 | AMD EPYC 7742 | AMD EPYC 7742 | AMD EPYC 7742 | AMD EPYC 7742 | AMD EPYC 7742 |
| 处理器数量 | 2 | 2 | 2 | 2 | 2 | 2 |
| 加速器 | NVIDIA A100-SXM-80GB | NVIDIA A100-SXM-80GB | NVIDIA A100-SXM-80GB | NVIDIA A100-SXM-80GB | NVIDIA A100-SXM-80GB | NVIDIA A100-SXM-80GB |
| 加速器数量 | 1 | 1 | 1 | 1 | 1 | 1 |
| 单流延迟(毫秒) | 0.431369 | 0.25581 | 1.686353 | 19.919082 | 22.585203 | 1.708807 |
| 多流(流数) | 1344 | 1920 | 56 | |||
| 离线样本/秒 | 38011.6 | 50926.6 | 985.518 | 60.6073 | 14007.6 | 3601.96 |
能效最高
数据中心
| 图像分类 | 目标检测 | 医学影像 | 语音转文本 | 自然语言处理 | 推荐 | |
|---|---|---|---|---|---|---|
| 提交者 | 高通 | 高通 | 英伟达 | 英伟达 | 英伟达 | 英伟达 |
| 系统名称 | Gigabyte R282-Z93 5x QAIC100 | Gigabyte R282-Z93 5x QAIC100 | Gigabyte G482-Z54 (8x A100-PCIe, MaxQ, TensorRT) | NVIDIA DGX Station A100 (4x A100-SXM-80GB, MaxQ, TensorRT) | NVIDIA DGX Station A100 (4x A100-SXM-80GB, MaxQ, TensorRT) | NVIDIA DGX Station A100 (4x A100-SXM-80GB, MaxQ, TensorRT) |
| 处理器 | AMD EPYC 7282 16-Core Processor | AMD EPYC 7282 16-Core Processor | AMD EPYC 7742 | AMD EPYC 7742 | AMD EPYC 7742 | AMD EPYC 7742 |
| 处理器数量 | 2 | 2 | 2 | 1 | 1 | 1 |
| 加速器 | QUALCOMM Cloud AI 100 PCIe HHHL | QUALCOMM Cloud AI 100 PCIe HHHL | NVIDIA A100-PCIe-40GB | NVIDIA A100-SXM-80GB | NVIDIA A100-SXM-80GB | NVIDIA A100-SXM-80GB |
| 加速器数量 | 5 | 5 | 8 | 4 | 4 | 4 |
| 服务器查询/秒 | 78,502 | 1557 | 372 | 43,389 | 10,203 | 890,334 |
| 系统功耗(瓦特) | 534 | 548 | 2261 | 1314 | 1302 | 1342 |
| 查询/焦耳 | 147.06 | 2.83 | 0.16 | 33.03 | 7.83 | 663.61 |
边缘(市售系统,按单流延迟排名)
| 图像分类 | 目标检测(小) | 目标检测(大) | 医学影像 | 语音转文本 | 自然语言处理 | |
|---|---|---|---|---|---|---|
| 提交者 | 高通 | 英伟达 | 高通 | 英伟达 | 英伟达 | 英伟达 |
| 系统名称 | AI Development Kit | NVIDIA Jetson Xavier NX (MaxQ, TensorRT) | AI Development Kit | NVIDIA Jetson Xavier NX (MaxQ, TensorRT) | NVIDIA Jetson Xavier NX (MaxQ, TensorRT) | NVIDIA Jetson Xavier NX (MaxQ, TensorRT) |
| 处理器 | Qualcomm Snapdragon 865 | NVIDIA Carmel (ARMv8.2) | Qualcomm Snapdragon 865 | NVIDIA Carmel (ARMv8.2) | NVIDIA Carmel (ARMv8.2) | NVIDIA Carmel (ARMv8.2) |
| 处理器数量 | 1 | 1 | 1 | 1 | 1 | 1 |
| 加速器 | QUALCOMM Cloud AI 100 DM.2e | NVIDIA Xavier NX | QUALCOMM Cloud AI 100 DM.2 | NVIDIA Xavier NX | NVIDIA Xavier NX | NVIDIA Xavier NX |
| 加速器数量 | 1 | 1 | 1 | 1 | 1 | 1 |
| 单流延迟 | 0.85 | 1.67 | 30.44 | 819.08 | 372.37 | 57.54 |
| 系统能耗/流(焦耳) | 0.02 | 0.02 | 0.60 | 12.14 | 3.45 | 0.59 |
目前,AI 硬件初创公司仍然缺乏参赛者,尤其是在 MLCommons 的成员中,这一点令人感到惊讶。当询问一些初创公司时,他们通常会回答说,衡量其硬件性能的最佳方法是查看其硬件在潜在客户的特定神经网络上的运行情况,而不是查看其在基准测试中的表现。
当然,这似乎很合理,前提是这些初创公司能够首先吸引到潜在客户的关注。这也假设客户真正知道他们需要什么。
“如果你从未接触过 AI,你就不知道该期待什么;你不知道你想要达到的性能目标;你不知道你想要使用哪些 CPU、GPU 和加速器的组合,”戴尔科技集团 AI、高性能计算和数据分析产品经理 Armando Acosta 说。他表示,MLPerf “真正为客户提供了一个良好的基准线”。
由于作者的错误,之前版本中将一个混合比喻错误地标记为双关语。在 4 月 28 日,文章进行了更正,因为“目标检测(大)”和“目标检测(小)”的列标题被意外地互换了。




